How to import Wikidata into Neo4j
| We’re assuming that you have read the Installation Guide and that you are familiar with the procedures. If you haven’t already done so, take a look at the read the Installation instructions and Getting Started Tutorial. |
In this guide, we will show you how to import Wikidata into Neo4j using the Wikidata Query Service. Specifically, this article will query the Wikidata Query Service using the SPARQL HTTP endpoint to retrieve information on Countries and Continents.
Graph Config
Before we can import RDF data into Neo4j, we first need to create a Graph Config to instruct Neosemantics on how to store the data. For this, we’ll need to call the n10s.graphconfig.init procedure with a map of parameters.
As with the Get Started Tutorial, we will use the mapping procedures in n10s to automatically rename the vocabulary terms used in the data retrieved from Wikidata when it is persisted into our Neo4j database.
Depending on the Graph Config, Neosemantics will treat multivalued properties in different ways (multivalued properties are a common feature in multilingual datasets like Wikidata, where we find multiple values for names, one for each available language: United Kingdom, Regno Unito, Royaume Uni, etc). By default, Neosemantics will assume properties are single valued and each new value for the same property on the same node will overwrite the previous value, but in some cases it may make sense to keep all the values. We can apply a configuration setting to store an array of these values in Neo4j.
CALL n10s.graphconfig.init({
handleVocabUris: 'MAP', (1)
handleMultival: 'ARRAY', (2)
keepLangTag: true, (3)
keepCustomDataTypes: true, (4)
applyNeo4jNaming: true (5)
})| 1 | Setting handleVocabUris to MAP instructs neosemantics to apply mappings to schema elements as they are added to the graph using the n10s.nsprefixes.add and n10s.mapping.add procedures |
| 2 | This setting ensures that multiple values are stored in Neo4j as an array, in this case we’re interested in the rdf:label of the element in multiple languages. |
| 3 | Keeping the language tag will mean that each translated property will be suffixed, eg: United Kingdom@en or Regno Unito@it |
| 4 | This setting ensures that any custom (user defined non- XML Schema) data types are also saved in Neo4j as a string, followed by their data type URI. |
| 5 | Apply Neo4j recommended naming to Graph Elements - All capital letters for relationship types, Upper Camel Case for labels, etc. |
Creating a Constraint
As we did in the tutorial, we need to ensure that there is a unique constraint on the URI property for nodes with a label of :Resource
CREATE CONSTRAINT n10s_unique_uri FOR (r:Resource)
REQUIRE r.uri IS UNIQUEBuiding a SPARQL query
In order to import the data into Neo4j, we will first need write a query to retrieve a list of triples from Wikidata. We will use SPARQL CONSTRUCT and SPARQL DESCRIBE for that. Our final RDF query will return information as triples of subject, predicate and object which use terms from several vocabularies/schemas. Both unique identifiers for things and vocabulary elements may be confusing at first because they are all numeric codes, but luckily the Wikidata Query Service comes with auto-completion and we can also browse the triples on Wikidata.org.
Wikipedia (mostly for human consumption) is linked to Wikidata (structured data for programatic use). If you navigate to a Wikipedia Entry, you will also see a Wikidata item link on the left hand navigation.
This can also be opened using a keyboard shortcut: Ctrl+Option+G on a Mac.
Take for example the United Kingdom wikipedia entry, this has a reference of Q145 on Wikidata.
The Wikidata entry displays a human readable table of all triples stored against the item, including names, population by year and life expectancy.
We can try the programatic access using the Wikidata Query Service to return all known tripples for the element using a DESCRIBE SPARQL query.
describe wd:Q145In total there are over 800,000 triples, so we should probably be more specific about the data that we are specifically interested in.
Under the Statements header, we can see that United Kingdom is lised as an instance of (wdt:P31) a Commonwealth realm, an island nation and most importantly a sovereign state - Q3624078.
We can use this triple pattern (something being an instance of a sovereign state) to identify all countries and bind them to a ?country variable.
SELECT *
WHERE {
?country wdt:P31 wd:Q3624078;
rdfs:label ?countryLabel.
BIND(LANG(?countryLabel) AS ?countryLabelLang)
}
LIMIT 10This query shows that the first subject returned by the query, wd:Q757 has labels in many languages.
| country | countryLabel | countryLabelLang |
|---|---|---|
wd:Q16 |
Kanada |
bi |
wd:Q16 |
Kanada |
bm |
wd:Q16 |
কানাডা |
bn |
wd:Q16 |
ཁ་ན་ཌ། |
bo |
wd:Q16 |
কানাডা |
bpy |
wd:Q16 |
Kanada |
bs |
wd:Q16 |
Канада |
bxr |
wd:Q16 |
Canada |
cbk-zam |
wd:Q16 |
Gă |
nā-dâi |
cdo |
wd:Q16 |
Канада |
The combination of configuration settings from the n10s.graphconfig.init call earlier will ensure that:
-
These values are stored in Neo4j as an array of strings (
handleMultival: 'ARRAY') -
These values will be stored with the language appended to the end of the string (
keepLangTag: true)
|
Alternatively, setting |
To demonstrate the ability to import a relationship from a predicate, we can add the continent property (wdt:P30) to the query. This property in RDF links a country to its continent.
Then we also add a property, the country’s population (wdt:P1082).
Wikidata has certain properties mesured at different points in time. Population is one of them. For the sake of brevity, we will not explain the intricacies of Wikidata’s model but we’ll just add filters to our query so that it only returns population counts after 2010 and also restrict the languages of each label to English, Arabic, Russian and Chinese. For more details, check Wikidata’s documentation and examples.
Here is the updated query:
SELECT *
WHERE {
?country wdt:P31 wd:Q3624078 ;
rdfs:label ?countryLabel .
filter(lang(?countryLabel) IN ("en", "ar", "ru", "zh")) . (1)
?country wdt:P30 ?continent .
?continent rdfs:label ?continentLabel .
filter(lang(?continentLabel) IN ("en", "ar", "ru", "zh")) . (1)
?country p:P1082 ?populationStatement .
?populationStatement ps:P1082 ?population;
pq:P585 ?date .
filter(?date > "2010-01-01"^^xsd:dateTime) (2)
}
LIMIT 10| 1 | Filter the language of the label to only include en, ar, ru and zh |
| 2 | Only include population counts after 1 January 2010 |
Then we can use the information from the WHERE clause to construct our triples ready for ingestion into Neo4j.
Constructing Triples
We’ve seen that SPARQL SELECT queries return tabular results, but we want to get RDF data instead. To instruct the Wikidata query service to return triples we can replace the SELECT section of the query with a CONSTRUCT clause.
The CONSTRUCT section defines how the data retrieved in the WHERE clause should be returned. So we can use this section to rename certain terms or even restructure the information as we wish.
The output of a SPARQL CONSTRUCT query is a stream of subject, predicate and object triples which together represent an RDF graph.
PREFIX neo: <neo4j://voc#> (1)
CONSTRUCT { (2)
?country a neo:Country . (3)
?country neo:countryName ?countryLabel . (4)
?country neo:inContinent ?continent . (5)
?continent neo:continentName ?continentLabel . (6)
?country neo:hasPopulationCount [ neo:count ?population ; neo:onDate ?date ] . (7)
?population a neo:PopulationCount
}
WHERE {
?country wdt:P31 wd:Q3624078 ;
rdfs:label ?countryLabel .
filter(lang(?countryLabel) IN ("en", "ar", "br", "zh")) .
?country wdt:P30 ?continent .
?continent rdfs:label ?continentLabel .
filter(lang(?continentLabel) IN ("en", "ar", "br", "zh")) .
?country p:P1082 ?populationStatement .
?populationStatement ps:P1082 ?population;
pq:P585 ?date .
filter(?date > "2010-01-01"^^xsd:dateTime)
}
LIMIT 10| 1 | This statement defines a neo4j:// namespace. We are going to define new terms (Country, continentName, etc) so we have to give them a fully qualified name in RDF. |
| 2 | The CONSTRUCT section of the query defines the triplets that we want to |
| 3 | We replace the wd:Q3624078 with neo:Country. Neosemantics will translate this statement into a :Country label on the country nodes |
| 4 | The country node will have a property of countryName (instead of rdf:label) with the element’s label |
| 5 | The country will have an inContinent relationship to it’s continent replacing p:P1082 |
| 6 | The continent will have a continentName property corresponding to ?continentLabel |
| 7 | For the population counts, create a triple to represent the relationship to a new node with properties for the date and the count |
| subject | predicate | object |
|---|---|---|
wd:Q16 |
rdf:type |
<neo4j://voc#Country> |
wd:Q16 |
<neo4j://voc#countryName> |
Canada |
wd:Q16 |
<neo4j://voc#inContinent> |
wd:Q49 |
wd:Q49 |
<neo4j://voc#continentName> |
أمريكا الشمالية |
b0 |
<neo4j://voc#count> |
35702707 |
b0 |
<neo4j://voc#onDate> |
1 January 2015 |
wd:Q16 |
<neo4j://voc#hasPopulationCount> |
b0 |
wd:Q16 |
<neo4j://voc#countryName> |
加拿大 |
Previewing the Data
To preview what the data will look like in Neo4j, we can use the n10s.rdf.preview.fetch procedure.
In the Getting Started guide, we used a static URI but we can query Wikidata’s APIs programatically by sending a GET request the following URL:
https://query.wikidata.org/sparql?query=<RDF>As the URL requires an encoded version of the query, we can use the APOC apoc.text.urlencode function to encode the SPARQL query above.
The endpoint also requires that we send an Accept header with the content type that we wish to consume, in this case Turtle.
Be sure to install the APOC plugin and restart Neo4j before proceeding any further.
If we run the query using the n10s.rdf.stream.fetch procedure, we can see the list of triples along with some additional metadata like the datatype and the language tag.
WITH 'PREFIX neo: <neo4j://voc#> (1)
CONSTRUCT { (2)
?country a neo:Country . (3)
?country neo:countryName ?countryLabel . (4)
?country neo:inContinent ?continent . (5)
?continent neo:continentName ?continentLabel . (6)
?country neo:hasPopulationCount [ neo:population ?population ; neo:onDate ?date ] . (7)
?population a neo:PopulationCount
}
WHERE {
?country wdt:P31 wd:Q3624078 ;
rdfs:label ?countryLabel .
filter(lang(?countryLabel) IN ("en", "ar", "br", "zh")) .
?country wdt:P30 ?continent .
?continent rdfs:label ?continentLabel .
filter(lang(?continentLabel) IN ("en", "ar", "br", "zh")) .
?country p:P1082 ?populationStatement .
?populationStatement ps:P1082 ?population;
pq:P585 ?date .
filter(?date > "2010-01-01"^^xsd:dateTime)
}
LIMIT 10' AS sparql
CALL n10s.rdf.stream.fetch(
'https://query.wikidata.org/sparql?query='+ apoc.text.urlencode(sparql),
'Turtle' ,
{ headerParams: { Accept: "application/x-turtle" } }
)
YIELD subject, predicate, object, isLiteral, literalType, literalLang
RETURN subject, predicate, object, isLiteral, literalType, literalLang| subject | predicate | object | isLiteral | literalType | literalLang |
|---|---|---|---|---|---|
"http://www.wikidata.org/entity/Q712" |
"http://www.w3.org/1999/02/22-rdf-syntax-ns#type" |
"neo4j://voc#Country" |
false |
null |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#countryName" |
"فيجي" |
true |
"http://www.w3.org/1999/02/22-rdf-syntax-ns#langString" |
"ar" |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#inContinent" |
"http://www.wikidata.org/entity/Q538" |
false |
null |
null |
"http://www.wikidata.org/entity/Q538" |
"neo4j://voc#continentName" |
"Oceania" |
true |
"http://www.w3.org/1999/02/22-rdf-syntax-ns#langString" |
"en" |
"genid-de0f637b17754c479bbee6732f96f4b1-b0" |
"neo4j://voc#population" |
"867921.0" |
true |
"http://www.w3.org/2001/XMLSchema#decimal" |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b0" |
"neo4j://voc#onDate" |
"2011-01-01T00:00:00Z" |
true |
"http://www.w3.org/2001/XMLSchema#dateTime" |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#hasPopulationCount" |
"genid-de0f637b17754c479bbee6732f96f4b1-b0" |
false |
null |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b1" |
"neo4j://voc#population" |
"874742.0" |
true |
"http://www.w3.org/2001/XMLSchema#decimal" |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b1" |
"neo4j://voc#onDate" |
"2012-01-01T00:00:00Z" |
true |
"http://www.w3.org/2001/XMLSchema#dateTime" |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#hasPopulationCount" |
"genid-de0f637b17754c479bbee6732f96f4b1-b1" |
false |
null |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b2" |
"neo4j://voc#population" |
"881065.0" |
true |
"http://www.w3.org/2001/XMLSchema#decimal" |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b2" |
"neo4j://voc#onDate" |
"2013-01-01T00:00:00Z" |
true |
"http://www.w3.org/2001/XMLSchema#dateTime" |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#hasPopulationCount" |
"genid-de0f637b17754c479bbee6732f96f4b1-b2" |
false |
null |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b3" |
"neo4j://voc#population" |
"915303.0" |
true |
"http://www.w3.org/2001/XMLSchema#decimal" |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b3" |
"neo4j://voc#onDate" |
"2016-07-01T00:00:00Z" |
true |
"http://www.w3.org/2001/XMLSchema#dateTime" |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#hasPopulationCount" |
"genid-de0f637b17754c479bbee6732f96f4b1-b3" |
false |
null |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b4" |
"neo4j://voc#population" |
"905502.0" |
true |
"http://www.w3.org/2001/XMLSchema#decimal" |
null |
"genid-de0f637b17754c479bbee6732f96f4b1-b4" |
"neo4j://voc#onDate" |
"2017-01-01T00:00:00Z" |
true |
"http://www.w3.org/2001/XMLSchema#dateTime" |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#hasPopulationCount" |
"genid-de0f637b17754c479bbee6732f96f4b1-b4" |
false |
null |
null |
"http://www.wikidata.org/entity/Q712" |
"neo4j://voc#countryName" |
"Fiji" |
true |
"http://www.w3.org/1999/02/22-rdf-syntax-ns#langString" |
"en" |
The fetch method is useful when we want to preview in neo4j the triples returned by an RDF source, in this case our SPARQL query on Wikidata, but also if we want to process them with cypher instead of delegating the import to neosemsntics.
We can also use the n10s.rdf.preview.fetch procedure in Neo4j Browser to preview the data as a graph.
WITH 'PREFIX neo: <neo4j://voc#> (1)
CONSTRUCT { (2)
?country a neo:Country . (3)
?country neo:countryName ?countryLabel . (4)
?country neo:inContinent ?continent . (5)
?continent neo:continentName ?continentLabel . (6)
?country neo:hasPopulationCount [ neo:population ?population ; neo:onDate ?date ] . (7)
?population a neo:PopulationCount
}
WHERE {
?country wdt:P31 wd:Q3624078 ;
rdfs:label ?countryLabel .
filter(lang(?countryLabel) IN ("en", "ar", "br", "zh")) .
?country wdt:P30 ?continent .
?continent rdfs:label ?continentLabel .
filter(lang(?continentLabel) IN ("en", "ar", "br", "zh")) .
?country p:P1082 ?populationStatement .
?populationStatement ps:P1082 ?population;
pq:P585 ?date .
filter(?date > "2010-01-01"^^xsd:dateTime)
}
LIMIT 10' AS sparql
CALL n10s.rdf.preview.fetch(
'https://query.wikidata.org/sparql?query='+ apoc.text.urlencode(sparql),
'Turtle' ,
{ headerParams: { Accept: "application/x-turtle" } }
)
YIELD nodes, relationships
RETURN nodes, relationshipsThe query will return a set of nodes connected together with relationships as defined in the CONSTRUCT portion of the query.
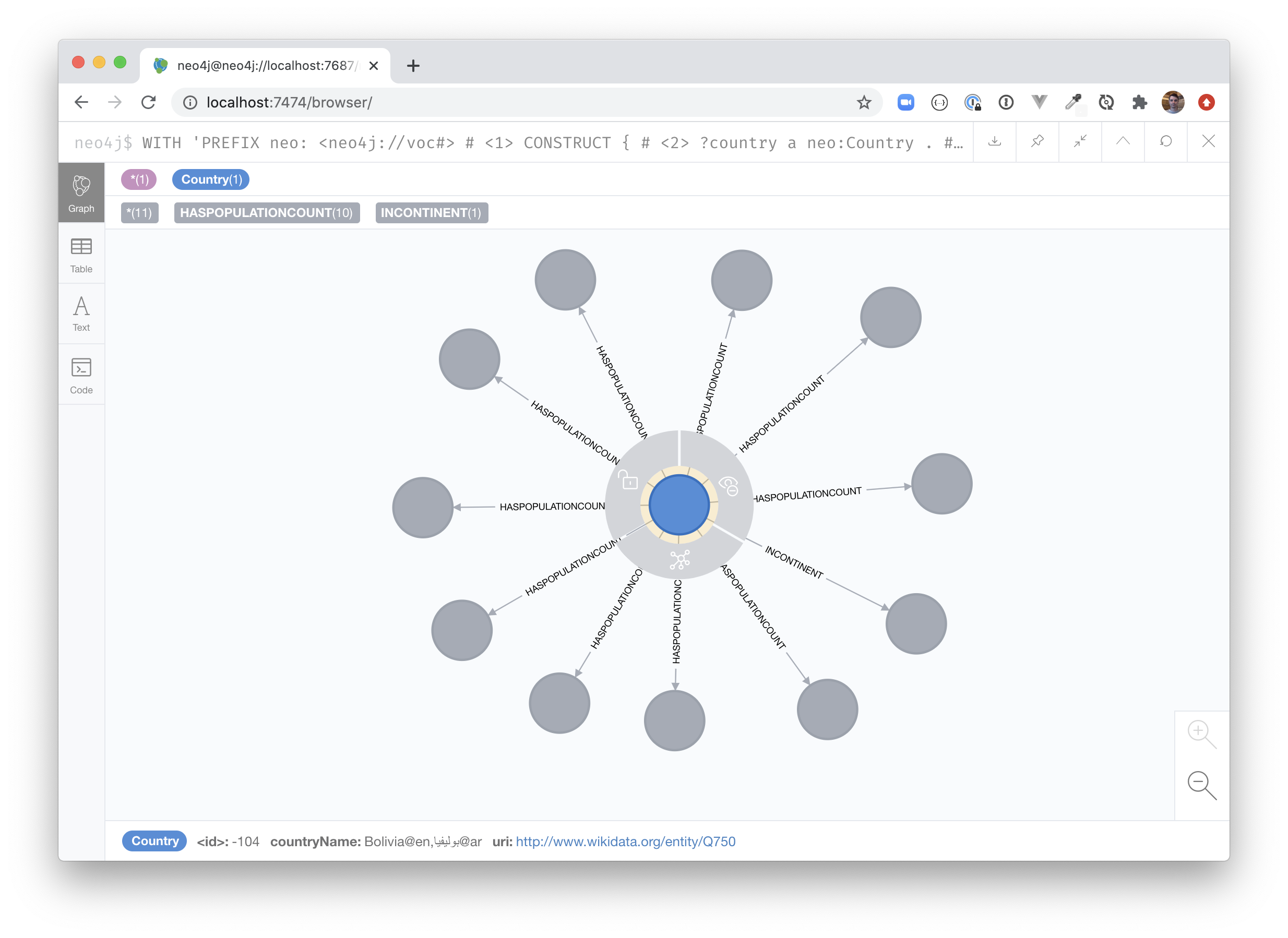
|
You can read more information on accessing Wikidata by reading their Data access page. |
Modifying the Input
Renaming Graph Elements using Mapping
Due to the applyNeo4jNaming config option being set to true, Neosemantics is converting the relationship types to uppercase.
In most cases this will be fine, but you may also prefer to create specific mappings for schema elements.
In the case of the preview above, converting the neo:inContinent schema element to uppercase is creating an unfortunate side-effect.
Instead of INCONTINENT, we can create a mapping to add an underscore to the name to make it more readable.
To do so, we first need to create a reference to the schema and prefix we’ve defined in the PREFIX section of the RDF query.
CALL n10s.nsprefixes.add('neo', 'neo4j://voc#')Once we have created the schema reference, we can create a mapping from the inContinent schema element to the IN_CONTINENT graph element.
CALL n10s.mapping.add(
'neo4j://voc#inContinent', (1)
'IN_CONTINENT' (2)
)| 1 | The Schema Element that should be renamed |
| 2 | The name of the relationship type that will be created |
Re-running the n10s.rdf.preview.fetch procedure above should now show that the unfortunately named relationship is now more readable.
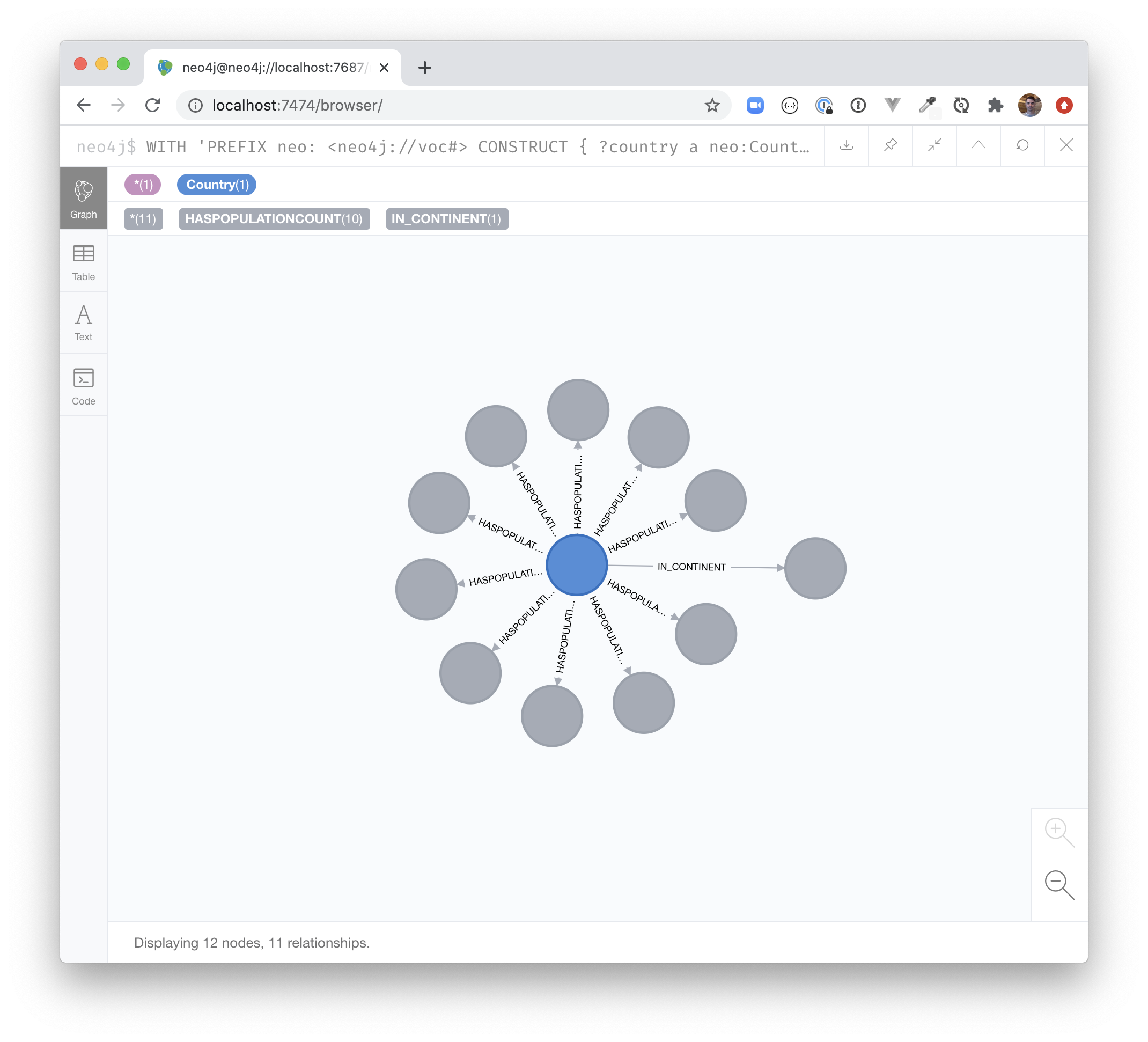
Handling Multiple Values
If we take a look at the node properties returned by the query, everything is currently being stored as arrays.
This is due to the handleMultival option being set to ARRAY.
If we take a look at the properties for the Country node, we can see that the countryName is stored as an array of strings.
This is fine because we want to preserve the international names of the countries.
{
"uri": "http://www.wikidata.org/entity/Q16",
"countryName": [
"Canada@en",
"加拿大@zh"
]
}However, for the Continent node, the onDate and population properties will only ever have a single value.
{
"onDate": [
"2016-01-01T00:00:00Z"
],
"uri": "genid-0db1342360a44f0f987e27cecb9d4b0a-b8",
"population": [
36155487.0
]
}Storing every value in an array will make things complicated to query.
Instead, we can be specific about which properties should be stored as an array by supplying an array of property keys to multivalPropList.
Once this option has been set, any properties that are not explicitly listed will be treated as if we had set handleMultival to OVERWRITE, setting the property to the final value.
To update a Graph Config you can run the n10s.graphconfig.set, providing a map of updated configuration options. This procedure will override the current configuration with the provided values and return a stream of all configuration options.
CALL n10s.graphconfig.set({
multivalPropList: ["neo4j://voc#countryName", "neo4j://voc#continentName"]
})Re-running the preview should now show that the population and onDate properties are now treated as single values:
{
"onDate": "2011-01-01T00:00:00Z",
"uri": "genid-f540b5c1a72c45e591d7bf818f2bf57b-b5",
"population": 33476688.0
}But the countryName property still holds an array of values:
{
"uri": "http://www.wikidata.org/entity/Q16",
"countryName": [
"Canada@en",
"加拿大@zh"
]
}Persisting the Data
Once you are happy with the preview, you can run the n10s.rdf.import.fetch procedure with the same parameters.
WITH 'PREFIX neo: <neo4j://voc#>
CONSTRUCT {
?country a neo:Country .
?country neo:countryName ?countryLabel .
?country neo:inContinent ?continent .
?continent neo:continentName ?continentLabel .
?country neo:hasPopulationCount [ neo:population ?population ; neo:onDate ?date ] .
?population a neo:PopulationCount
}
WHERE {
?country wdt:P31 wd:Q3624078 ;
rdfs:label ?countryLabel .
filter(lang(?countryLabel) IN ("en", "ar", "br", "zh")) .
?country wdt:P30 ?continent .
?continent rdfs:label ?continentLabel .
filter(lang(?continentLabel) IN ("en", "ar", "br", "zh")) .
?country p:P1082 ?populationStatement .
?populationStatement ps:P1082 ?population;
pq:P585 ?date .
filter(?date > "2010-01-01"^^xsd:dateTime)
}
' AS sparql
CALL n10s.rdf.import.fetch(
'https://query.wikidata.org/sparql?query='+ apoc.text.urlencode(sparql),
'Turtle' ,
{ headerParams: { Accept: "application/x-turtle" } }
)
YIELD terminationStatus, triplesLoaded, triplesParsed, namespaces, extraInfo
RETURN terminationStatus, triplesLoaded, triplesParsed, namespaces, extraInfoRemoving the limit should load and parse over 32,000 triples.
| terminationStatus | triplesLoaded | triplesParsed | namespaces | extraInfo |
|---|---|---|---|---|
"OK" |
32210 |
32210 |
null |
"" |
Handling Multilingual Properties
The config that we have provided ensures that the countryName property for each Country node is an array of values representing the country’s name in a specific language.
If we take a look at the array, each item is a string which starts containing the value, an @ symbol and then the language.
{
"uri": "http://www.wikidata.org/entity/Q902",
"countryName": [
"Bangladesh@en",
"بنغلاديش@ar",
"Bangladesh@br",
"孟加拉国@zh"
]
}Neosemantics provides a number of helper functions for extracting information from multilingual data:
-
n10s.rdf.getLangTag- Given a string, extract the language tag from the end of the string -
n10s.rdf.getLangValue(language, values)- Given a value or array of values, extract the value for a specific language.
Retrieving a Specific Language
To retrieve the value for a specific language you can use the n10s.rdf.getLangValue function.
This accepts two parameters; the language and an array of values.
If a string representing the language exists within the array of values it will be returned, otherwise the function will return null.
MATCH (c:Country)
RETURN c.countryName, n10s.rdf.getLangValue('en', c.countryName) AS englishName
ORDER BY c.countryName ASC
LIMIT 10| c.countryName | englishName |
|---|---|
["Albania@en", "ألبانيا@ar", "Albania@br", "阿尔巴尼亚@zh"] |
"Albania" |
["Andorra@en", "أندورا@ar", "Andorra@br", "安道尔@zh"] |
"Andorra" |
["Angola@en", "安哥拉@zh", "أنغولا@ar", "Angola@br"] |
"Angola" |
["Antigua ha Barbuda@br", "أنتيغوا وباربودا@ar", "Antigua and Barbuda@en", "安提瓜和巴布达@zh"] |
"Antigua and Barbuda" |
["Armenia@en", "أرمينيا@ar", "亞美尼亞@zh", "Armenia@br"] |
"Armenia" |
["Bahamas@br", "巴哈马@zh", "باهاماس@ar", "The Bahamas@en"] |
"The Bahamas" |
["Bahrain@en", "البحرين@ar", "巴林@zh", "Bahrein@br"] |
"Bahrain" |
["Bangladesh@en", "بنغلاديش@ar", "Bangladesh@br", "孟加拉国@zh"] |
"Bangladesh" |
["Belarus@br", "Belarus@en", "白俄罗斯@zh", "روسيا البيضاء@ar"] |
"Belarus" |
["Benin@br", "Benin@en", "贝宁@zh"] |
"Benin" |
Creating a Map using APOC
Using a Pattern Comprehension and a combination of the n10s.rdf.getLangTag and n10s.rdf.getLangValue functions
, you can extract a set of pairs of [language, value].
This can be passed to the apoc.map.fromPairs to create a map containing the language as the key and the value.
MATCH (c:Country {uri: "http://www.wikidata.org/entity/Q145"})
RETURN apoc.map.fromPairs( (3)
[ name IN c.countryName | (1)
[ n10s.rdf.getLangTag(name), n10s.rdf.getLangValue(n10s.rdf.getLangTag(name), name) ] (2)
]
) AS countryNames| 1 | Use a pattern comprehension to extract a temporary name variable from the countryName array |
| 2 | For each name, return a pair that includes the language tag (eg: en) and the value (eg: United Kingdom) |
| 3 | Pass that value to the apoc.map.fromPairs function which will convert the pairs into a map |
This will return the following output:
{
"br": "Rouantelezh-Unanet",
"en": "United Kingdom",
"ar": "المملكة المتحدة",
"zh": "英国"
}Conclusion
In this guide we have learned how to:
-
Use the Wikidata Query Service to retrieve data using an RDF query and imported the data into Neo4j.
-
Updated neosemantics configuration to store certain values as an array
-
Extract specific language data from an array using Neosemantics helper functions
If you have experienced any issues during this tutorial you may find the solution on the Troubleshooting page.
Glossary
- Neo4j Browser
-
Neo4j Browser is a User Interface for querying, visualization, and data interaction. If your database is running, it can usually be accessed over HTTP on port
:7474or:7473over HTTPS, eg. http://localhost:7474. - APOC
-
APOC is a library of procedures and functions that make your life as a Neo4j user easier.