Introduction to the Neo4j LLM Knowledge Graph Builder

Senior Solutions Architect, Persistent Systems
11 min read

Bridge the gap and unlock hidden potential within your unstructured data
In today’s data-driven world, a vast ocean of information resides in unstructured formats like text documents, articles, emails, and social media posts. While these sources are rich with insights, extracting meaningful connections and relationships from them has been complex and time-consuming.
This blog post delves into the details of LLM Knowledge Graph Builder, exploring its functionality, benefits, and how it leverages the combined power of large language models (LLMs) and Neo4j graph databases to improve data analysis and knowledge discovery. Check out The Developer’s Guide:
How to Build a Knowledge Graph to get up to speed with knowledge graphs.
We’ll explore its capabilities based on publicly available information and infer its functionality based on the typical use cases of such tools. We also dive deeper than the official documentation and the public GitHub repository.
This is the first post of a multi-part series that covers:
- Overall functionality
- Architecture
- Knowledge graph extraction
- Graph visualization
- GraphRAG retrievers
The Challenge of Unstructured Data and the Rise of LLMs
Unstructured data lacks a predefined format, making it difficult for traditional databases to process and analyze effectively. Methods like keyword searching can be superficial, often missing the nuanced relationships and deeper meanings embedded within the text.
However, the advent of LLMs has changed the game. These AI models, trained on massive datasets of text and code, possess a new ability to understand natural language, extract entities, discern relationships, and even infer context and sentiment. LLMs can effectively “read” and comprehend unstructured text much like humans, opening up new data processing and analysis possibilities.
LLM Knowledge Graph Builder: Marrying LLMs with Graph Databases
Neo4j, as a graph database, excels at storing and querying interconnected data. It represents relationships as first-class citizens, making it ideal for exploring connections, patterns, and networks within data. The LLM Knowledge Graph Builder acts as the processing, visualization, and interaction tool, using the power of LLMs to extract structured information from unstructured text and then populate a Neo4j graph database with this newly discovered knowledge.
What Does Neo4j LLM Knowledge Graph Builder Do?
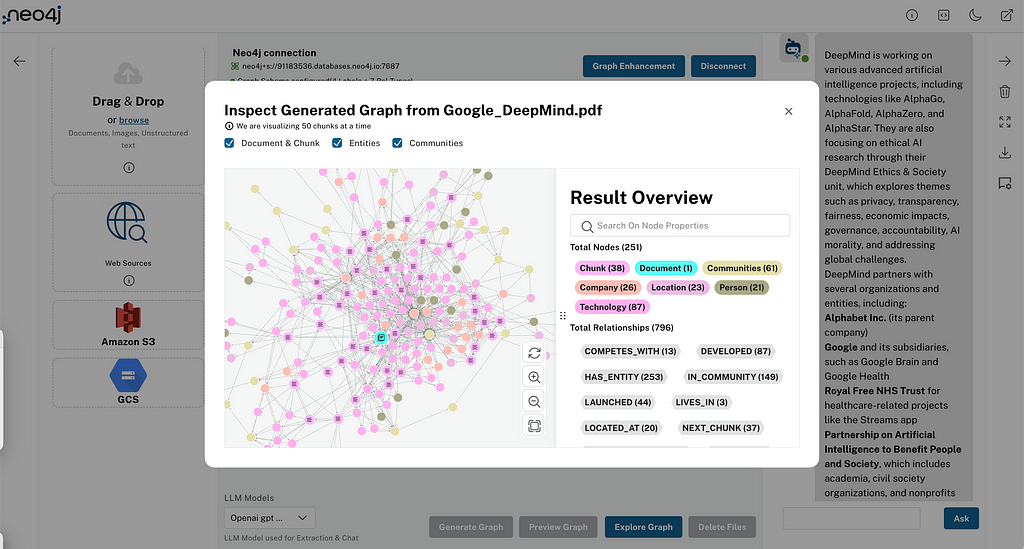
The LLM Knowledge Graph Builder is an online application for turning unstructured text into a knowledge graph. It provides a magical text-to-graph experience.

It uses LLMs like OpenAI, Gemini, Llama 3, Diffbot, Claude Sonnet, and Qwen to extract data from PDFs, documents, images, web pages, and YouTube transcripts.
The extraction turns the documents into a lexical graph of documents and chunks (with embeddings) and an entity graph with nodes and their relationships, stored in your Neo4j database. You can configure the extraction schema and apply clean-up operations after the extraction.
You can use different retrieval-augmented generation (RAG) approaches (GraphRAG, vector, Text2Cypher) to ask questions about your data and see how the extracted data constructs the answers.
The front end is a React application, and the back end is a Python FastAPI application running on Google Cloud Run, but you can deploy it locally using Docker Compose. It uses the llm-graph-transformer module that Neo4j contributed to LangChain and other LangChain integrations (e.g., for GraphRAG search). See the Features documentation for details.
Step-by-Step Instructions
- Open the LLM Knowledge Graph Builder.
- Connect to a Neo4j (Aura) instance.
- Provide your PDFs, documents, URLs, or S3/GCS buckets.
- Construct graph with the selected LLM.
- Visualize knowledge graph in the app.
- Chat with your data using GraphRAG.
- Open Neo4j Bloom for further visual exploration.
- Use the constructed knowledge graph in your applications.

How It Works
- Uploaded sources store as Document nodes in the graph.
- Document (types) are loaded with LangChain loaders.
- The content is split into Chunks.
- Chunks store in the graph and connect to the document and to each other for advanced RAG patterns.
- Highly similar chunks are connected with a SIMILAR relationship (with a weight attribute) to form a k-nearest neighbors graph.
- Embeddings compute and store in the chunks and vector index.
- The llm-graph-transformer or diffbot-graph-transformer extracts entities and relationships from the text.
- Entities and their relationships store in the graph and connect to the originating chunks.

Key Features
Data Ingestion
The application supports many data sources, including PDF documents, web pages, YouTube transcripts, and more. Users can upload these documents directly or provide URLs or links to S3/GCS buckets. This flexibility allows for the ingestion of diverse types of unstructured data.
Entity Recognition and Graph Construction
Using advanced LLMs such as OpenAI, Gemini, Diffbot, and others, the application identifies and extracts entities and relationships from the ingested text. These entities and relationships then convert into a graph format, using Neo4j’s graph capabilities. The graph consists of nodes representing entities and edges representing the relationships between them.
Configuration and Customization
Users can configure the extraction schema to tailor the graph construction process. This can be done by selecting a predefined schema, using an existing schema from a Neo4j database, or even allowing the LLM to suggest a schema based on the text provided. This level of customization ensures that the knowledge graph is structured in a way most relevant to the user’s needs.
Visualization and Interaction
The application provides an intuitive web interface for visualizing the generated knowledge graph. Users can see the entities, their relationships, and the documents from which the information was extracted. Additionally, you can explore the graph using Neo4j Bloom, a tool designed for visual exploration and interaction with graph data.
Technical Underpinnings
– Front and back end: The application uses a React front end and a Python FastAPI back end, running on Google Cloud Run. It can also be deployed locally using Docker Compose.
– LangChain integration: The application uses the llm-graph-transformer module contributed by Neo4j to LangChain, which facilitates text transformation into graph structures.
– Storage and querying: The knowledge graph is stored in a Neo4j database, efficiently handling complex data networks and provides powerful querying capabilities through Cypher, Neo4j’s declarative graph query language.
Using the RAG Chatbot
The GraphRAG chat is a key component of the LLM Knowledge Graph Builder, enabling users to interact with their knowledge graph through natural language queries.
Retrieval Process
When a user asks a question, the application uses the Neo4j vector index to retrieve the most relevant chunks of text and their connected entities up to a depth of two hops. Both the text and the graph context are combined.
The chat history is also summarized to enrich the context. All this information then sends to the selected LLM model in a custom prompt, which generates a response based on the provided context and elements.
Transparency and Explainability
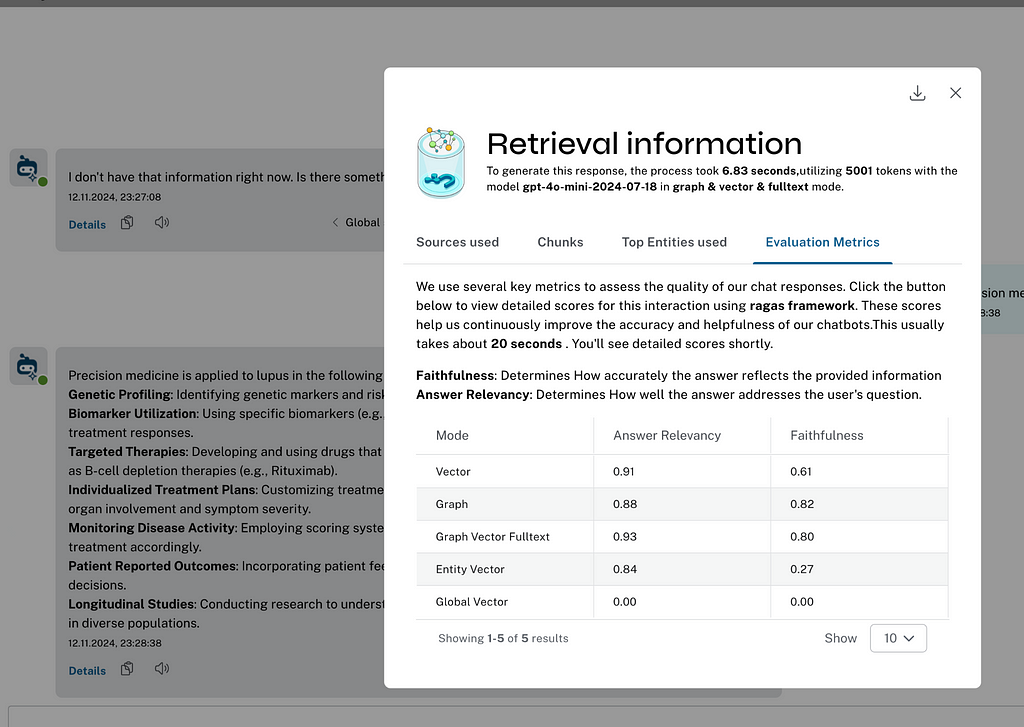
A standout feature of the LLM Knowledge Graph Builder is its ability to provide transparency into how the answers generate. Users can see the specific sections of documents, entities, and text chunks used to answer their questions, making the process more trustworthy and understandable. As part of that, there is also an evaluation mechanism using Ragas to validate the different answers.
Essentials of GraphRAG
Pair a knowledge graph with RAG for accurate, explainable GenAI. Get the authoritative guide from Manning.
GraphRAG Retrieval Approaches
The LLM Knowledge Graph Builder, integrated with the LangChain framework, offers several sophisticated retrievers crucial for enhancing the accuracy and functionality of RAG applications. Check out the types of retrievers and their functionalities below.
Graph Retriever
The Graph Retriever is a key component in the LLM Knowledge Graph Builder. It leverages the structured data stored in the Neo4j graph database to retrieve relevant information.
- Entity identification: The graph retriever starts by identifying relevant entities in the input, such as people, organizations, and locations. LLMs extract these entities from the text.
- Neighborhood retrieval: Once the entities are identified, the retriever uses Cypher queries to retrieve the neighborhood of these entities. This involves fetching the direct and indirect relationships of the identified nodes, which helps provide a more comprehensive context.
Hybrid Retriever
The Hybrid Retriever combines the strengths of unstructured and structured data retrieval.
Vector and full-text indexes: This retriever uses vector and full-text indexes to search through unstructured text data. It then combines this information with the data collected from the knowledge graph, ensuring a more robust retrieval process.
Neo4j Vector Retriever
This retriever uses the vector indexing capabilities of Neo4j to retrieve documents based on similarity scores.
Vector index: The Neo4jVector class allows for the creation of a retriever that uses a vector index stored in Neo4j. This retriever can search for documents based on similarity scores, with options to filter by specific document names and set score thresholds.
Customization: Users can adjust parameters such as search_k (the number of documents to retrieve) and score_threshold to fine-tune the retrieval process. This ensures that only the most relevant documents are retrieved and passed to the LLM.
Global Community and Local Entity Retrievers
Microsoft published the “From local to global — Query Focused Summarization GraphRAG” paper last year. Running a clustering algorithm identifies clusters of closely related entities, whose content is then summarized by an LLM into community summary nodes.
Those summaries are then used in global retrievers to answer general questions about the documents. In LLM Knowledge Graph Builder, we implemented it using the same clustering algorithm, if you’re connected to a Neo4j instance that has graph data science enabled (Aura Pro with GDS, AuraDS, Neo4j Sandbox, or self-hosted) — which we show on top of the app.
The extracted communities are visible in the graph visualization of your documents, too.

Both the local and the global retriever (like all the others) allow showing the retrieved contextual graph data (communities, entities, chunks) that went into generating the answer, supporting explainability.
Multiple Retrievers
As shown, you can select one or more retrievers that run in parallel to generate an answer to your question and switch between the answer results.
Retriever Evaluation
One reason for the parallel retriever evaluation was the addition of the ability to generate evaluation metrics across the retrievers and display them to the users.
We’re using the Ragas framework and will dive deeper into evaluation in a future blog post.
Deployment and Configuration
The Neo4j LLM Knowledge Graph Builder can be accessed online, or it can be deployed locally for more control and customization and to use local and other LLM models.
Online Application
Users can access the application directly from the Neo4j website, where they can connect to a Neo4j Aura instance and start building their knowledge graph without any local setup.
Local Deployment
For those who prefer local deployment, the application can be cloned from the GitHub repository (use the DEV branch for the latest version). The setup involves using Docker Compose to run both the front- and back-end components.
Detailed instructions for local deployment are available in the application’s documentation.
Summary
The Neo4j LLM Knowledge Graph Builder represents a significant step in leveraging the power of both LLMs and graph databases to unlock the vast potential hidden within unstructured data.
By automating transforming text into interconnected knowledge, organizations are empowered to gain deeper insights, make more informed decisions, and build intelligent applications that leverage the richness of unstructured information.
As LLMs continue to evolve and Neo4j’s graph database capabilities expand, we can expect LLM Knowledge Graph Builder and similar tools to play an increasingly crucial role in the future of data analysis and knowledge discovery.
To stay updated on the official release, documentation, and potential GitHub repository for the LLM Knowledge Graph Builder, keep an eye on Neo4j’s official website, blog, and social media channels.
Please use comments on this post, as well as GitHub issues to share feedback and let us know how we can improve the application.
You can also learn more about Building Knowledge Graphs with LLMs on GraphAcademy.
The combination of LLMs and graph databases is a powerful force, and Neo4j is strategically positioned to lead the way in this exciting new era of data-driven insights.
Introduction to the Neo4j LLM Knowledge Graph Builder was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
GraphRAG for Beginners
Build a GraphRAG application that can answer complex questions based on connected data. Learn the three major retrieval patterns.

Share Article



Explore
Related Articles


LLM Knowledge Graph Builder: From Zero to GraphRAG in Five Minutes