





The latest release of Neo4j Data Importer introduces a new way to load more data sources without the need for pre-processing. By allowing you to apply simple filters to files we’re enabling loads in more scenarios, including:
- Generally keeping data relevant from only certain rows in a file while skipping the others
- Loading data from aggregate node lists and relationship lists where information on all nodes and all relationships is encapsulated in just two files. (Like from the Bloom export)
We’re going to take a quick look at how file filtering can help you with the latter example.
Consider the following subset of the Northwind data model showing Orders, the Products they contain, and the Shippers they are shipped by.
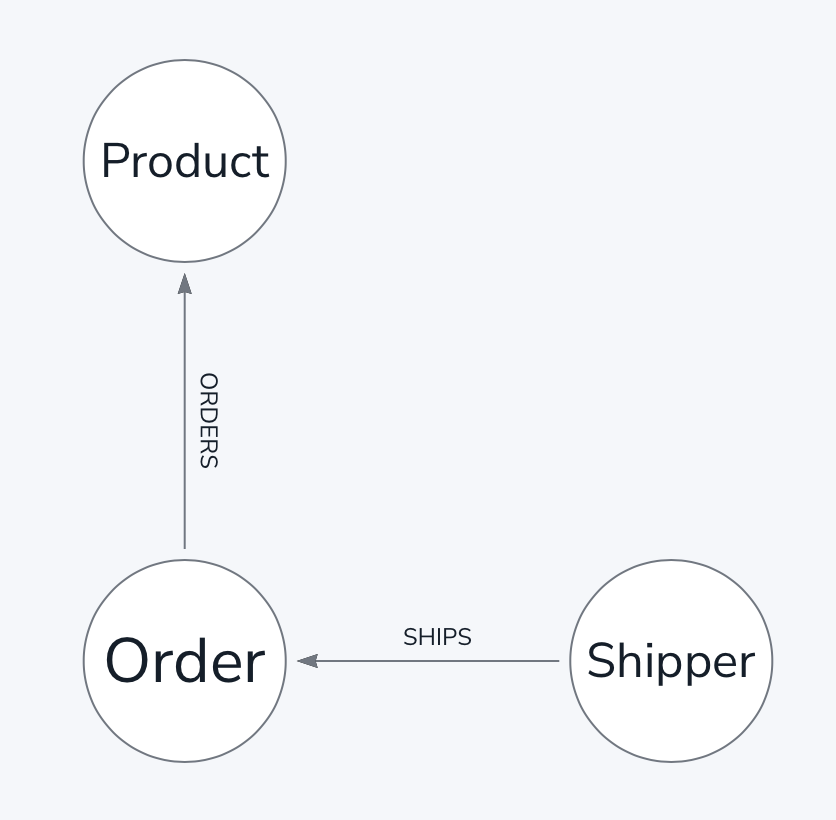
In the classic Northwind dataset, these are represented by different tables like Shippers.csv, Orders.csv, Products.csv, and Order-Details.csv. When extracting data from more graph-like sources, it is not uncommon to be provided with wide node lists and relationship lists that contain all the nodes and all the relationships in just two files.
Here’s what an example exported from our very own Neo4j Bloom looks like (but could equally apply to any other graph-like export):
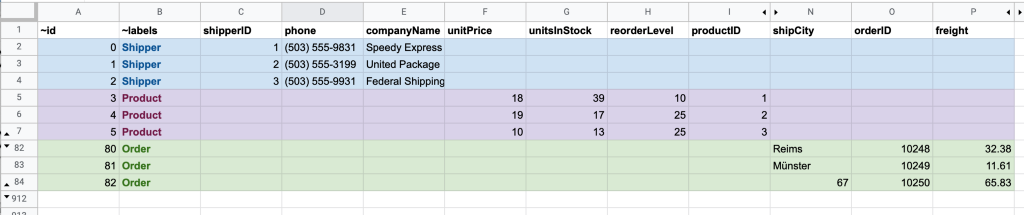
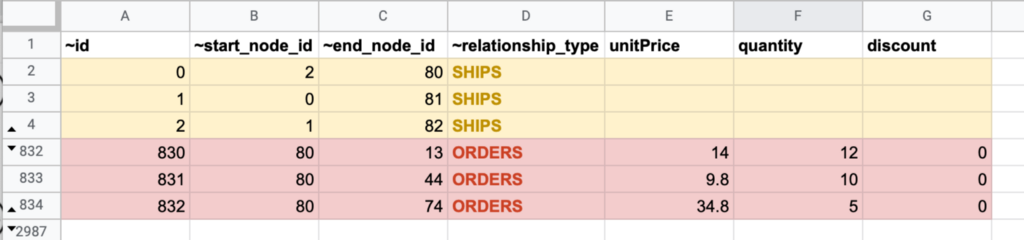
In the nodes file you’ll notice the node types are identified by the ~labels column and relationship types in the relationships file by the ~relationship_type column.
Before the file filtering feature, you needed to manually separate the nodes files into three files upfront, representing the three node types and the relationships file into two files representing the two relationship types.
With file filtering, now optionally available under the File dropdown in the Mapping Panel, you can apply include filters to keep rows only relevant to the Nodes or Relationships in your model.
Here’s an example of applying the file filter to the bloom-relationships-export.csv file to ensure it only keeps the rows where the ~relationship_type column has ORDERS values.
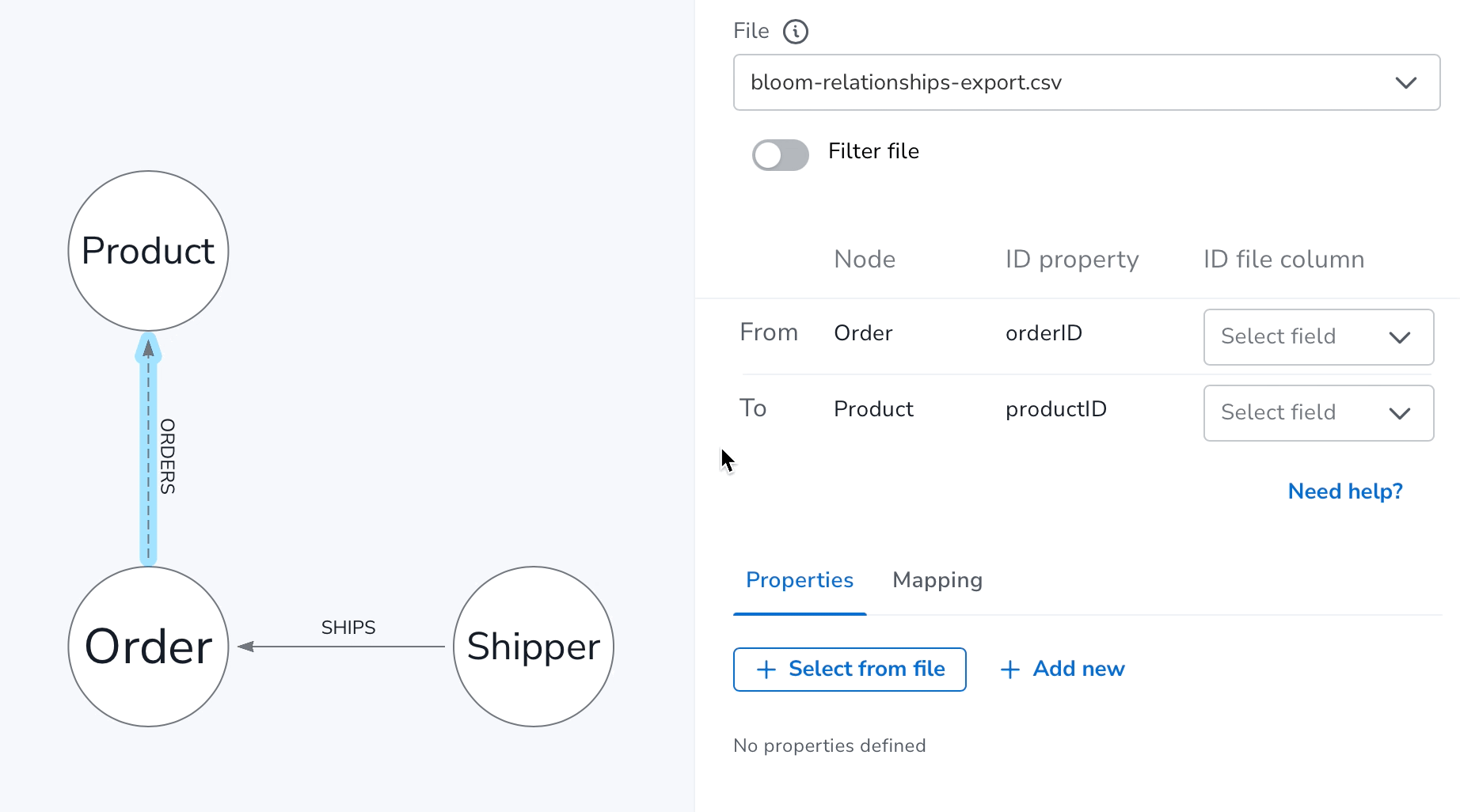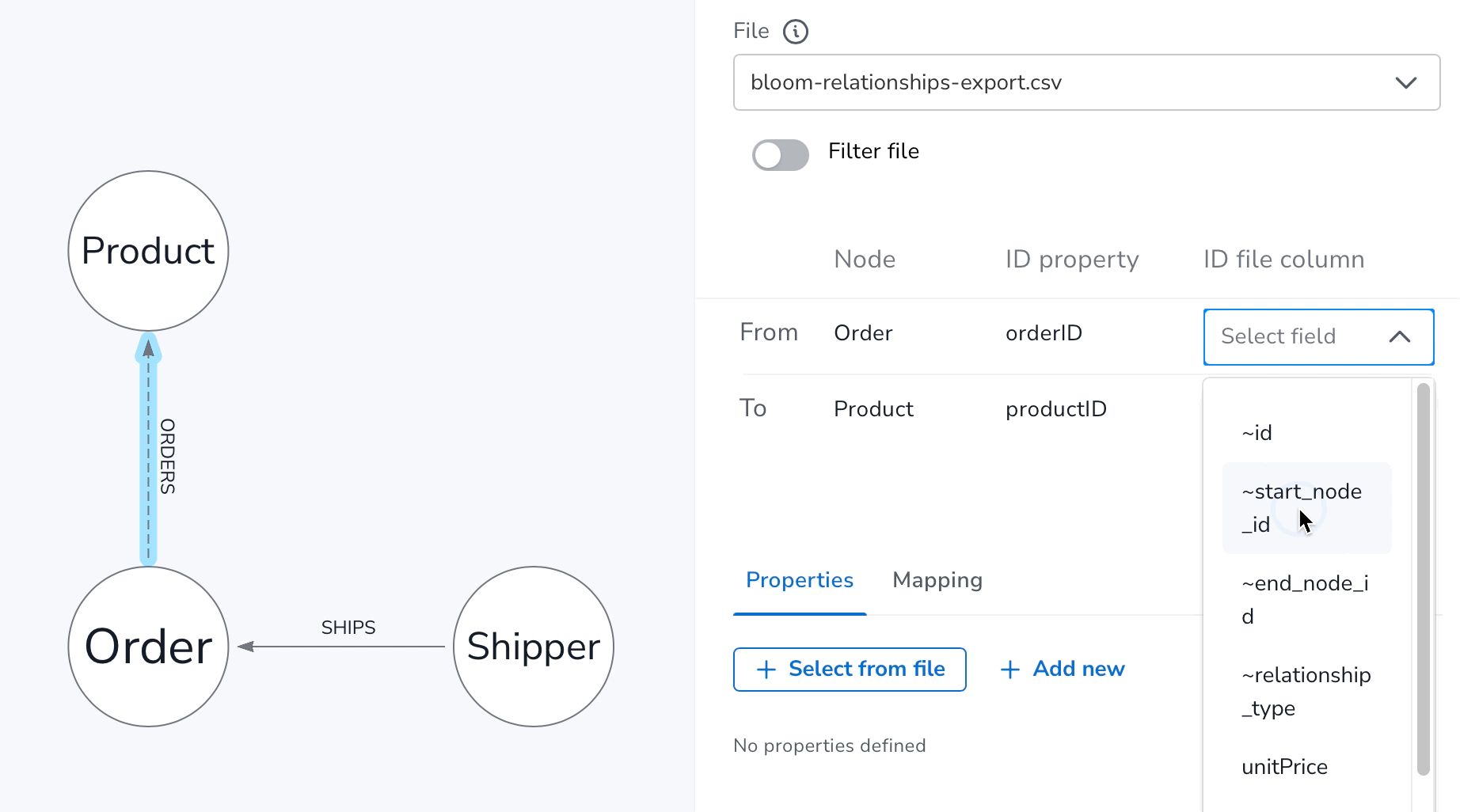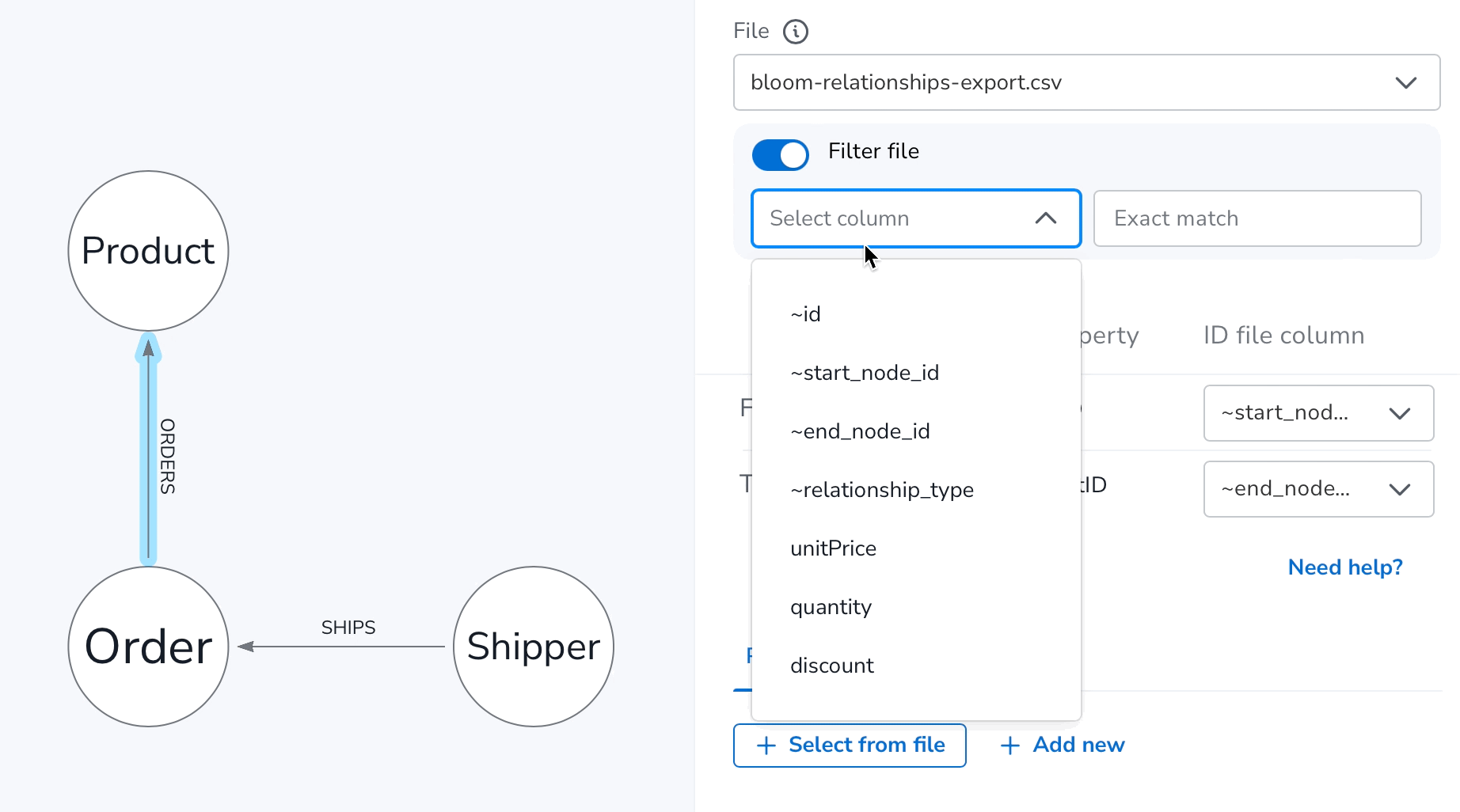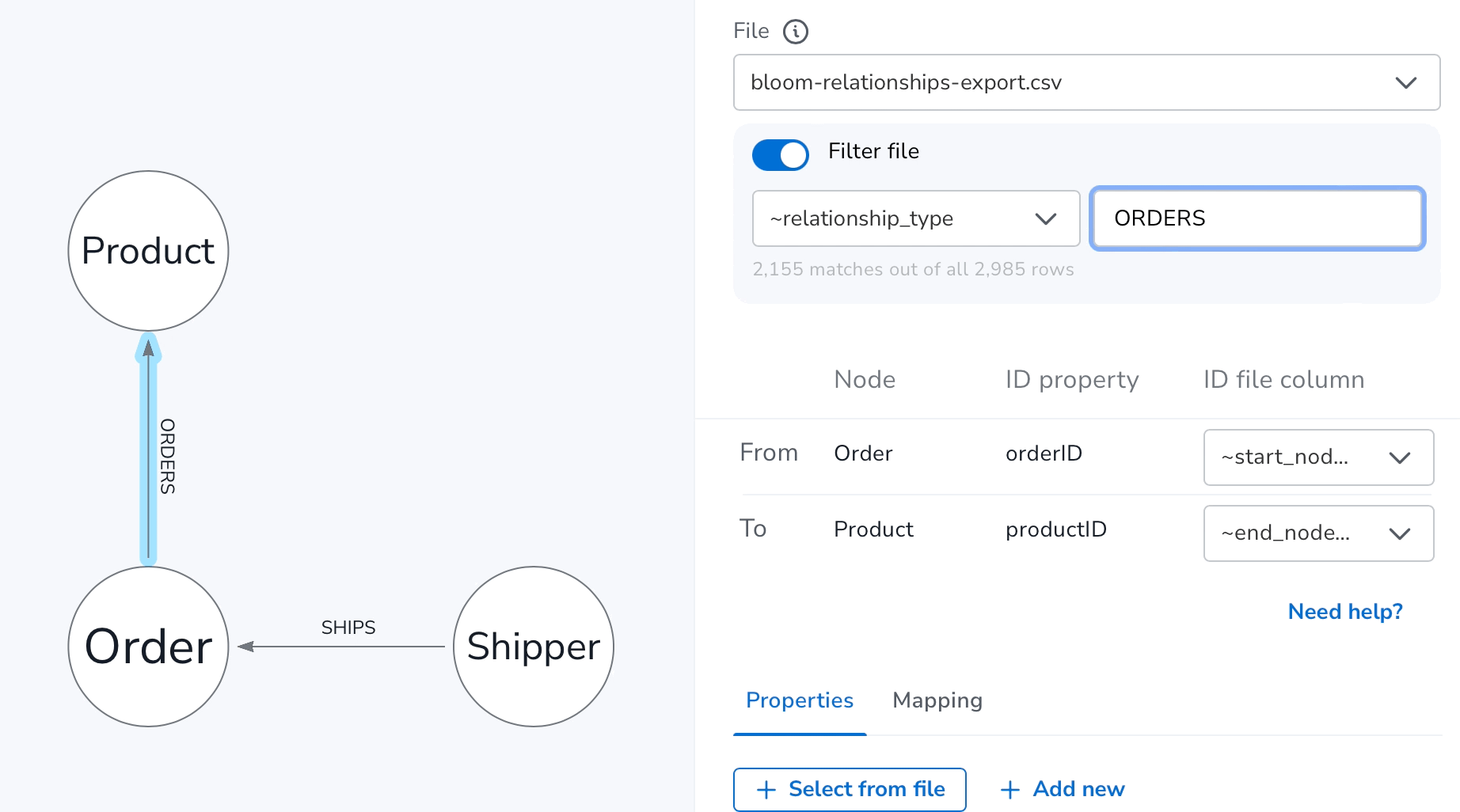
You’ll notice the filter when applied, gives you feedback as you type on how many matches were found. For performance reasons only the first 10,000 rows of any file are scanned, so even if you don’t see matches in this feedback, there may still be matches further down your file.
The same filtering principle applies for the nodes file, in this example mapping to the Product node and only keeping the rows in the bloom-nodes-export.csv file where values in the column ~labels equal Product.
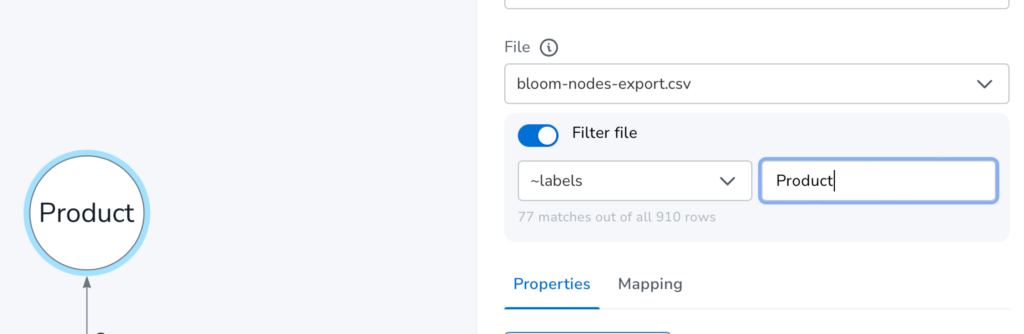
For now, file filtering supports exact string matches, but we’d love to hear your feedback on the utility of the filtering functionality and other things you’d like to see.
Data Importer is available in AuraDB Free and Professional — if you don’t have one already, get started with your free instance here.
Data Importer continues to be available as both a standalone app in Workspace and within the Import tab of Neo4j Workspace.
If you need to use Data Importer against a local dev Neo4j instance, you can continue to use the app hosted here (for non-certificate secured instances only).
That’s all for now.
As always, please head over to https://feedback.neo4j.com/data-importer to leave us your feedback.
Neo4j Data Importer — Introducing File Filtering was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Finding Hidden Bottlenecks in Flight Networks with Aura Graph Analytics on Databricks

Find Impactful Graph-Powered Insights in Databricks

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths

