


With winter officially behind us, we at Neo4j have been busy in the workshop sharpening our (Dev)Tools with meticulous precision to bring you the latest releases. In this release, we’ve got new features to further improve your data load experience in the new Neo4j Data Importer. Thank you to our wonderful users for all the feedback that we’ve received since its release in February. Without further ado, read on to find out more.
Improved “Empty ID” Handling
In previous releases of Data Importer, we treated empty string fields quite naively when it came to using them as IDs. If we saw an empty string in a file, we treated that as a unique identifier and created a node for it. If your data had many missing IDs, this could easily result in a supernode with the lonely-looking empty ID appearing in your graph.
To solve this (and since flat files don’t have a concept of null values) we now treat empty strings as null values when it comes to node IDs. We will filter out rows where the empty string is the ID for a node import — meaning we no longer create a node for those rows.
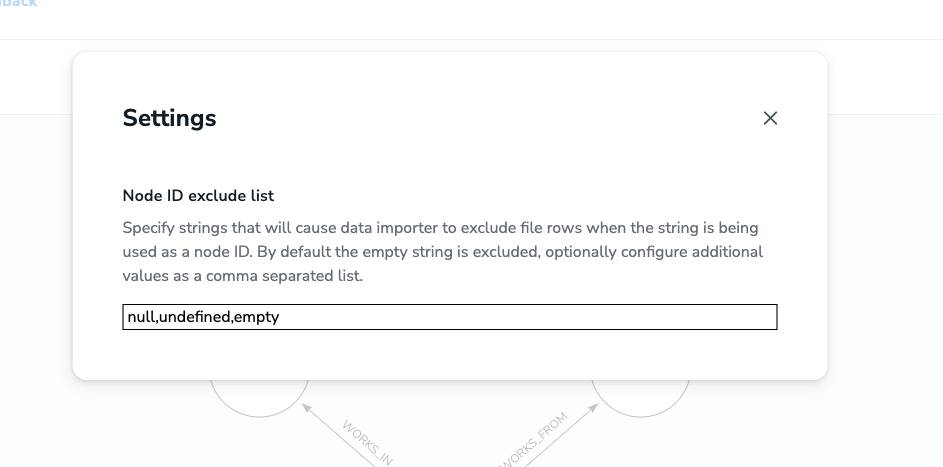
Additionally, we now provide a setting for your load configuration that allows you to specify other string values you’d like to be treated as nulls. This could be useful if, for example, you have actual string values like “null” or “undefined” in your ID columns. The setting is specific to your model/mapping and will be exported along with your configuration when you share it with others.
Improved Representation of Partial Mappings and Errors
A key part of using Data Importer is making sure you have your model and mapping correctly defined. For the most part, this means you need to ensure you have all the fields completed in the mapping part of the UI. While the previous version of Data Importer helped with this, it wasn’t always clear from the graph model what was partially mapped, and errors could be a bit “shouty,” painting the graph model red when you hadn’t quite got around to mapping something yet.
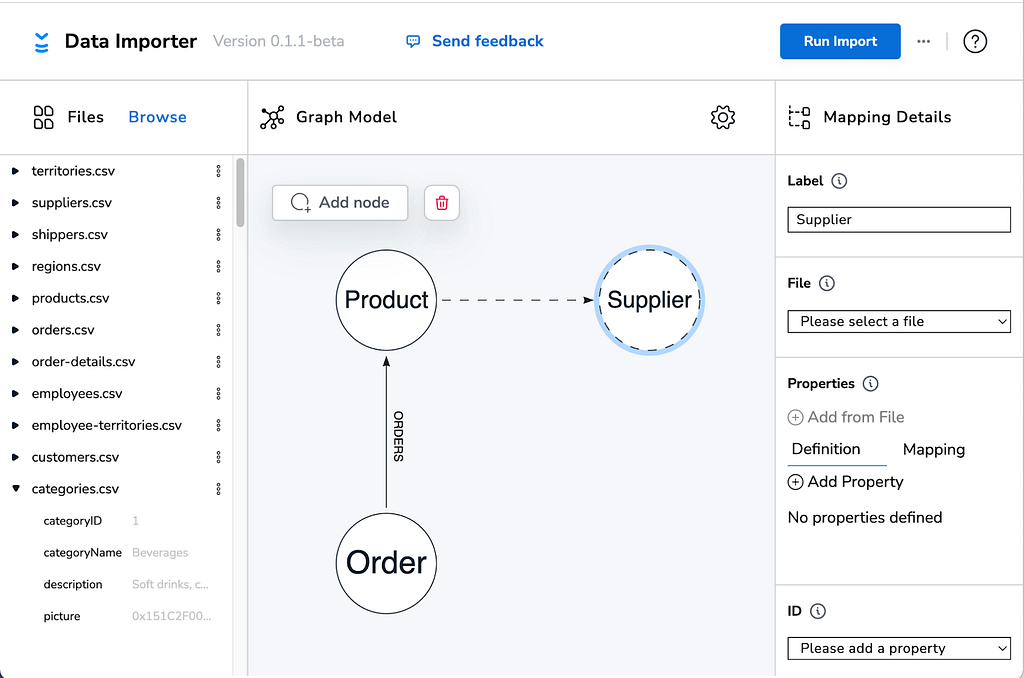
In the latest release, we now show nodes and relationships that you haven’t quite got around to fully mapping yet with a dashed line. So from now on, if you see a dashed line, it’s a good reminder that you haven’t yet provided all the required information.
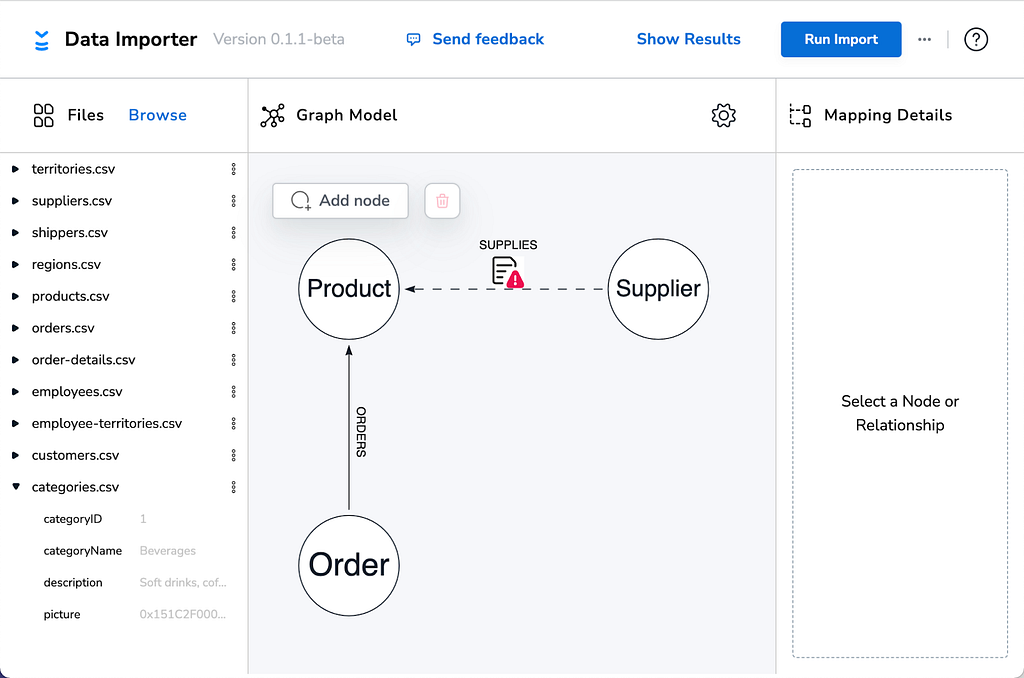
If you try to run an import with incomplete mappings, Data Importer will still remind you which parts of your model or mapping require your attention:
Other Improvements
We’ve also made a few small improvements to the way load progress is shown (it’s now in the form of a progress bar) and made some subtle changes to buttons and menus.
Loads that previously failed as a result of a type conversion failures on an id field (e.g. converting the string “Abc” to an Integer) will now behave similarly to properties with an empty string — meaning no nodes will be created where the property used as the ID fails type conversion. We’re considering improving reporting of occurrences like these in the load summary to help you better understand how Data Importer is reacting to sub-optimal data. Feel free to let us know more about what you’d like to see on our feedback page.
And Finally…
Patch releases of Neo4j Browser and Desktop also went out recently, addressing a number of bugs. We’ve also been busy working on some big things for the future, and while we can’t quite share full details just yet, rest assured that we’re working on things to make your developer experience smoother than ever. Stay tuned for more updates!
Start Uploading Your Data to Neo4j AuraDB — No Coding Required
🐇🌱🌦 Neo4j DevTools “It’s Finally Spring Here” Release 😅 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles




How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs

