Announcing Neo4j JDBC driver version 6

Senior Staff Software Engineer, Neo4j
12 min read

Neo4j has had a JDBC Driver for about 8 years in 2024, see our announcement in 2016 by my friend and colleague Michael Hunger.
This driver was developed and maintained by our valued partner LARUS over the last years. We thank you and appreciate your work on this.
We’re excited to announce the new version 6 of the Neo4j JDBC driver. This version lives in the same repository as the previous ones, but in a new home at the Neo4j organization on GitHub, acknowledging its state as an officially supported driver.
This new version, now maintained directly by Neo4j engineering, opens up exciting possibilities for integrating Neo4j with a wide variety of platforms and tools in the Java ecosystem.
But why did we invest in an additional driver for the Java ecosystem, when there’s already the common Neo4j driver for Java?
Why JDBC?
Data processing does not happen in isolation. Quite the contrary: While vendors (we included) are always happy to be in a position as the “source of truth” for anything, the reality is that you need to connect from and to a lot of different platforms. Platforms whose primary focus is on data movement (such as Fivetran, Informatica, and many others), as well as solutions integrated into various cloud platforms, are an integral part of many application systems these days. Customers want to use that tooling for getting data in and out of Neo4j with the aim to use graph technology to get new insights into deeply connected structures or further processing results from applied algorithms into tooling further down the stack.
JDBC was released with JDK 1.1 on February 19, 1997 — 27 years ago as of writing. While it looks quite different from younger APIs, it is still versatile, mostly well-thought-through, and (most important) might not connect with all the things, but a lot!
This includes:
- Client-side tooling like DBeaver, IntelliJ DataGrip, and many others,
- ETL tools such as KNime, Tableau, Apache NiFi, and related,
- Programming frameworks and libraries such as Springs JDBC Template and JDBI, and
- The aforementioned platforms in the future to come.
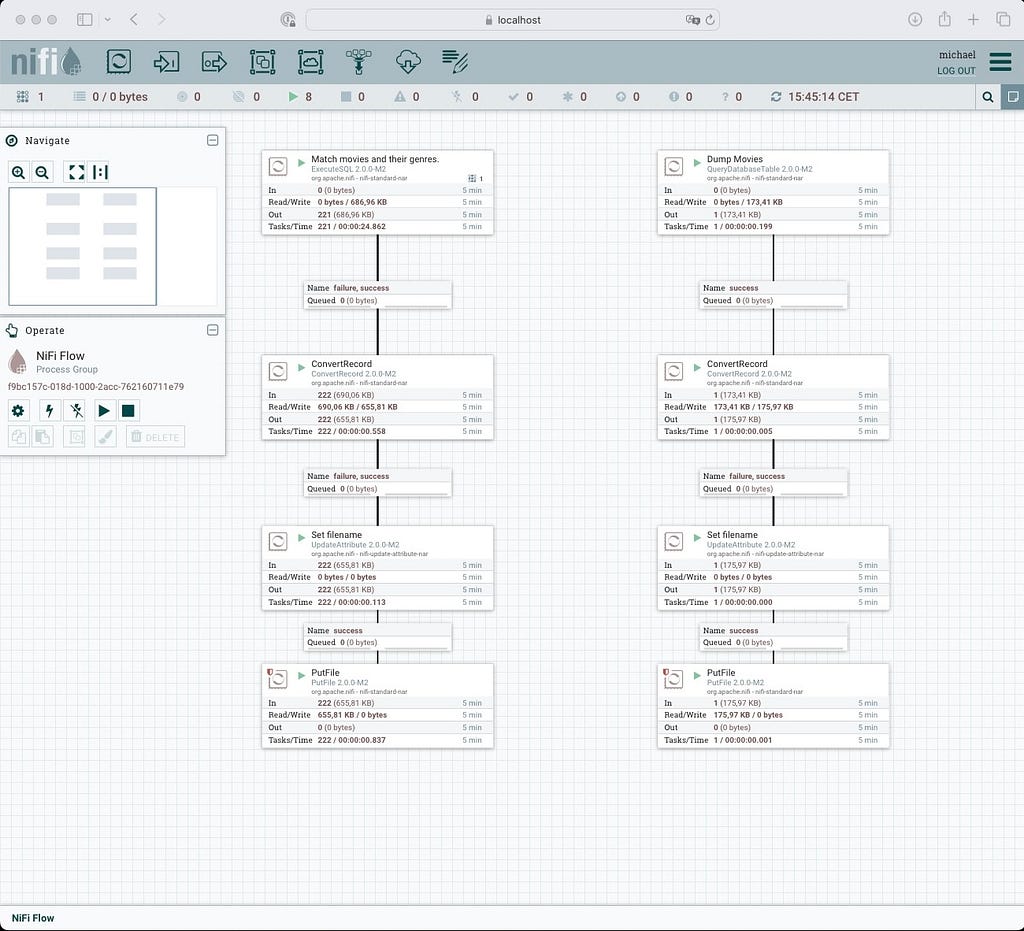
JDBC stands for Java Database Connectivity, not for “relational only,” so it is not as alien as it might seem at first glance. However, it is very close to the SQL standard, which includes terms such as catalogs and schemas, which do not yet map exactly what we can provide in Neo4j. Being mindful of that, JDBC and Neo4j work together just fine.
Nevertheless, many of the tools mentioned above, first and foremost the ETL tools, generate SQL for interacting with a store through JDBC. Neo4j, however, does only understand Cypher, and we need a solution for that.
As mentioned at the beginning, Neo4j does not only offer an opinionated, graph-oriented connector for Java, but also has a dedicated JDBC driver built on top of that. Let’s discuss the reasons for rewriting this.
Why rewrite the existing driver?
As much as greenfield projects are alluring, any rewrite in Software Engineering is a dangerous task and, potentially, a slippery slope into churning users. The good thing here is the goalpost of implementing the JDBC spec, so there’s a lot of guidance regarding how the outcome should actually behave.
The biggest difference between version 6 and prior versions of the Neo4j JDBC Driver (as well as any other JDBC driver for Neo4j that we are aware of) is the fact that it is not built on the common Java driver for Neo4j.
Why is this important? The common Neo4j Java driver is a great connector, designed as a “one-stop shop” solution, including connecting pooling, managed transactions, and automatic retries. Those are great features in isolation, but not when you build other drivers or connectors atop it, especially when they are meant to be pluggable — JDBC drivers are usually put into connection pools, which would double the pools.
This decision alone justified the rewrite for us for the actual network layer. But what about the rest?
Design goals
Our design goals have been built on three pillars:
- Implement the JDBC spec proper based on a dedicated version of Bolt, the Neo4j network protocol.
- Getting as much schema information out of Neo4j as possible, at the moment, without running any additional algorithms on the graph. Neo4j itself is not schema-free, but very schema-flexible, and we are faced essentially with two problems: Getting an accurate schema, and, if we have that, bending it into a much more rigid schema as enforced by the JDBC metadata API.
- Having a pluggable SQL translation architecture. The Neo4j JDBC Driver will assume Cypher by default and will pass those statements to the database, but will ship with a Service Provider Interface (SPI) for adding translators from “your input format” to Cypher.
Additionally, we want to see if we can focus more on good developer experience (DX) and empathy for the needs of downstream developers and users: How can we create a driver that behaves emphatically towards the user, and can we actually bend the JDBC API to that goal?
- Lenient on the config: As long as it is not contradictory, do the right thing.
- Chooses best defaults, putting less cognitive load on others.
- Try to behave as “good” as possible in the restrictions of JDBC, with no surprises (or as few as possible).
- Use the escape hatches from the core JDBC API to vendor-specific classes.
What’s in the box?
For the past 6 months, we worked in a small team of three engineers, with Stu Moore as PM and some helpful advice from colleagues and friends, and can ship the second milestone with the following features:
- Network connectivity is fully implemented, including support for read-only hints and full support for Neo4j AuraDB and any Neo4j 5 cluster solution, including SSL and authentication modes beyond username and password for all interactions over JDBC
- For metadata, we use available machinery in Neo4j 5 for querying labels, which we map to tables and then apply the best effort to get a view of the available properties and their types. We will broaden that in the future to support the relatively new type of constraints. We did not try to derive a full graph schema.
- We ship a default implementation of a translator that can parse many different SQL dialects and is able to translate them to existing Cypher constructs. The translator works for both read and write statements.
The driver is tested against and is fully compatible, running on GraalVM in native image mode.
The translator is pluggable for two reasons: We have not yet decided if the baseline for this new driver stays JDK 17 or might be lower. The implementation of the translator we have, however, is 17, and we can’t go lower there but are able to plugin a different one if needed.
The other reason is more important: A translation that fits one project might need to be different in another. Let’s see why.
SQL to Cypher translation
People who are following my work and also my private activities have most likely noticed that I have been doing a lot of SQL-related things in the last few months again. I never made a big secret out of the fact that I do like SQL, and Neo4j was well aware of my talks on that topic back when they hired me.
I’ve always made it very clear that I don’t believe a single moment in silver bullets: I don’t think that all problems are either analytical or graph problems. Sometimes you have one or the other, sometimes a combination thereof. You might agree with me on those topics or not. I am fine either way, but I think there’s always value in looking left and right occasionally, getting inspiration, and creating new value from it.
The SQL to Cypher translation we initially offer is built on long-standing relations with Lukas Eder and DataGeekery, the company behind https://www.jooq.org/. Earlier in 2023, we created a small proof of concept combining the parser from one query builder with another query builder inspired by the former, and that eventually landed in the new JDBC driver.
Here are a couple of things the translator is able to do. A multivalued insert like this:
INSERT INTO Person (first_name, team) VALUES
('Conor', 'Cypher composite'),
('Dmitriy', 'Drivers'),
('Gerrit', 'SDN-OGM'),
('Michael H.', 'The Hunger'),
('Michael S.', 'SDN-OGM'),
('Stu', 'PM')
will turn into:
UNWIND [
{first_name: 'Conor', team: 'Cypher composite'},
{first_name: 'Dmitriy', team: 'Drivers'},
{first_name: 'Gerrit', team: 'SDN-OGM'},
{first_name: 'Michael H.', team: 'The Hunger'},
{first_name: 'Michael S.', team: 'SDN-OGM'},
{first_name: 'Stu', team: 'PM'}]
AS properties
CREATE (person:`Person`)
SET people = properties
If you use a list parameter on a JDBC-prepared statement set to batching, it will execute a similar query. A select statement like the following:
SELECT p.name, r.role, m.* FROM Person p
NATURAL JOIN ACTED_IN r
NATURAL JOIN Movie m
will map quite naturally to a relation:
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie)
RETURN p.name, r.role,
elementId(m) AS element_id, m.title AS title, m.released AS released
A SELECT * FROM Movie query will actually use the available schema information to project all properties from the nodes, which is what most tooling actually expects (in contrast to a complex Node object). This feature will replace the flattening feature of previous versions. If you want to access the node, you can use either SELECT m FROM Movie m or switch back to Cypher — the node (or relationship or path objects) will all work.
All predicates will be pushed down into proper Cypher conditions and there is no in-memory graph evaluation.
While the latter examples are nice, they also demonstrate an opinionated approach to mapping tables, join tables, and join columns. This is not a research project, and we have been looking for a practicable approach that fits a lot, but not necessarily all, use cases.
This is where not only configuration comes into play, but the ability to swap out the translator completely or chain your custom translation into the flow. The driver does support all of that.
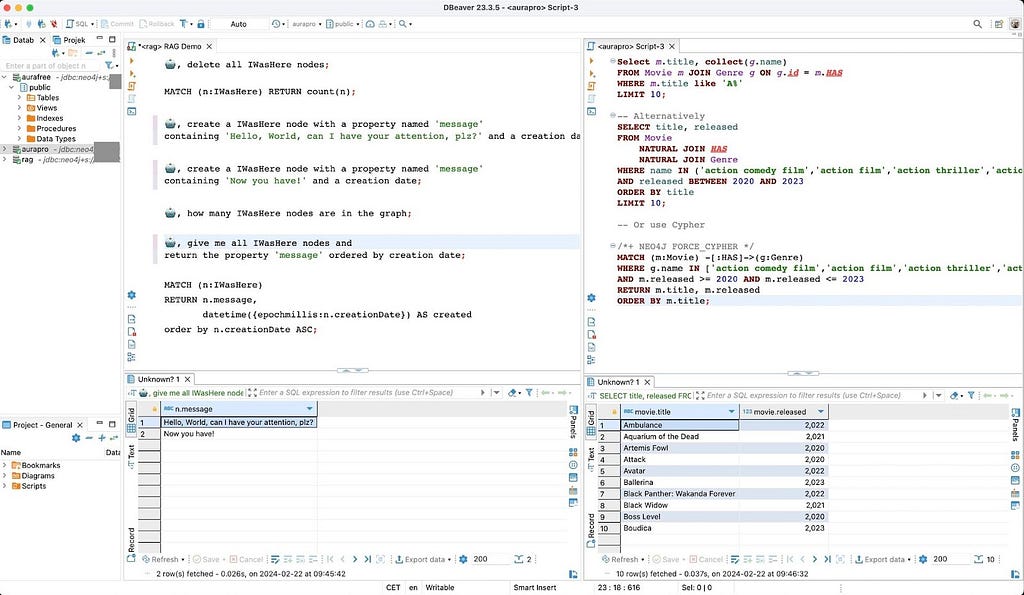
My team-mate Gerrit Meier created the JDBC RAG translator.
This implementation uses a ChatGPT, augmented by a graph made up from the Cypher manual, and will create queries that start with the robotor emoji into valid Cypher:
🤖, give me all IWasHere nodes and
return the property 'message' ordered by creation date
Using AI to translate natural language into a highly formalized query language is a nice use case for that technology. In our example, it will produce something like this:
MATCH (n:IWasHere)
RETURN n.message,
datetime({epochmillis:n.creationDate}) AS created
order by n.creationDate ASC
The results of the demo are shown here:
When to use this driver?
Let’s start with when NOT to use it:
- There is no need to switch if you have an existing application built on the common Java driver.
- The same applies to anything built on Spring Data Neo4j (SDN) and Neo4j-OGM. Both use the common Java driver under the hood in the most optimal way. Other object mapping frameworks created for relational databases are not optimized for Graph and will likely not work with the JDBC driver unless heavily augmented with custom queries.
- If there’s an existing, dedicated Neo4j option in an ETL tool, stick with it for the time being.
The new JDBC driver should be used for all applications and tooling that:
- Uses versions 4 or 5 of the Neo4j JDBC driver.
- Has new integrations with data movement platforms and ETL tools, especially in all cases that are “SQL only.”
- Has existing integrations that are (at the moment) read-only, but also need write capabilities.
- Don’t require extensive mapping capabilities but want to stick in a familiar environment — think Jakarta EE transactions, Spring JDBCTemplate and others.
What’s next?
With the publishing of this post, the second milestone (6.0.0-M02) will be published as well, with binaries on Maven Central and a packaged-up distribution on GitHub:
Release 6.0.0-M02 · neo4j/neo4j-jdbc
Until the final release, our documentation is published live on GitHub, as well.
We would appreciate feedback on the driver directly in the repository or other relevant channels.
Until then, a heartfelt thank you to the whole team, namely Stu, Dmitry, and Conor, for the great collaboration and excellent work, as well as our friends and partners in crime, Michael Hunger, Gerrit, and Lukas Eder.
Neo4j JDBC Driver Version 6 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



