Optimizing Cypher query using parameters

Back End Developer at CytoSMART
2 min read

I got a helpful email from Ron van Weverwijk pointing out that constructing a Cypher query every time does not give the best performance. I didn’t know at the time that this would also solve another problem. The problem is the Neo4j desktop app crashing after approximately 1500 requests.
In a previous blog, I used python to construct a query with a merge for every synonym I wanted to add.
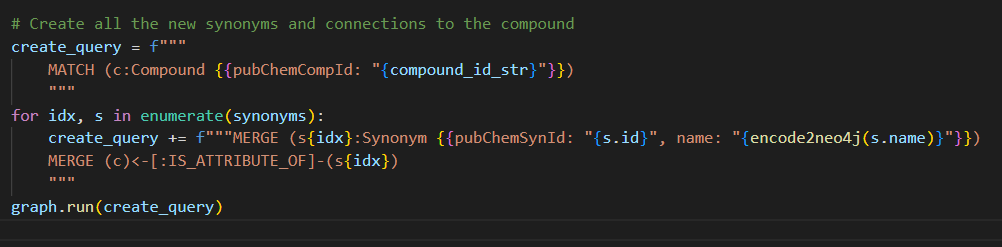
Every time a new query is sent to the Neo4j database, it needs to be transformed into an execution plan. But Neo4j caches the last 1000 queries for reuse, meaning if you send a query that is cached, the optimization can be skipped. This is why the advice is to make 1 query with parameters and reuse it every time.
For this, the Python for loop needs to be replaced with Cypher Unwind and the Python f-string with Cypher parameters. This gives us the following query.
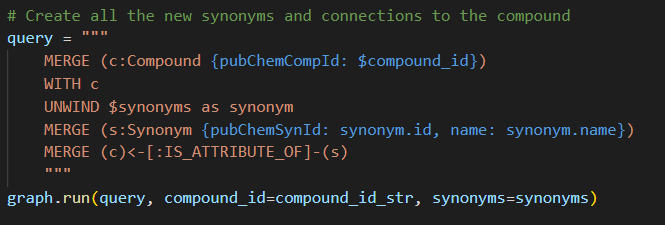
Measuring
I know better than to believe a stranger on the internet with advice or documentation. So I constructed some experiments to find out what benefits I got from rewriting it.
Effect of unwind
In a completely empty database, I created 1 compound with 16 synonyms in the same way as I did before and also with the new method. This is repeated a thousand times without emptying the database or restarting it. This means only the first time the query needs to be optimized, after that the cached query could be used.
Old method
median time: 0.001029s
mean time: 0.002305s
New method
median time: 0.001006s
mean time: 0.001609s
It seems the unwind and constructed perform the same in most cases but the constructed query has more extreme cases, resulting in similar medians but different means for the measured execution times.
Effect of caching
To test the effect of caching 999 unique compounds with synonyms are sent because 1 of the 1000 compounds did not work out the way I hoped…
The rest of the experiment is the same.
Old method
median time: 0.04199s
mean time: 0.19140s
New method
median time: 0.03316s
mean time: 0.03744s
Here we see a way clearer benefit. The new method will improve performance and thus will be implemented.
Result
The new method is a clear improvement, constructing a new query per request was a bad idea. Using the backend function with the new method on the more than 5000 requests that crashed with the old method, now it works. It still takes more than 5 hours, including scraping and cleaning the data.
Optimizing Cypher query by using parameters was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



