
The Spark of Neo4j

Data Engineer, LARUS Business Automation
5 min read

Hear the story about how we at Larus, together with Neo4j, built the official Neo4j Connector for Apache Spark, and how we overcame some of the obstacles we found on our way.
What you’ll read in this article are experiences we had between the start of the project in July 2020 and the time of this writing, March 2021.
TL;DR If you just want to see how to use the connector API, jump down to the “Final Result” section, or check out our examples in the docs.
We wanted to give users an official library to avoid them to use custom “hacky” solutions, and to offer a continuous service, both from development and support points of view.
We decided to deprecate the old connector, in favour of a complete rewriting of the code using the new DataSource API V2 that enable us to leverage the multi-language support of Apache Spark. We also focused a lot on the documentation website, keeping the docs up to date is actually part of our backlog.
I also presented the story at the GraphRM meetup in Rome, if you rather want to watch the video:
Challenges
Getting to where we are now wasn’t really straightforward. We faced some problems and here’s a quick overview on how we dealt with them.
Lack of Documentation
Being DataSource API V2 relatively new, we couldn’t find so much official Databricks documentation (especially for Spark 3). Examples, videos, and tutorials were not going enough in-depth for what we have to do, so we had to find another way build things; the good old “look at the source code” mantra came handy in this case and we were able to figure out what we were doing wrong when the documentation was not enough.
Breaking Changes
We found breaking changes even between minor versions, and of course also between Spark 2.4 and Spark 3.0.

Unfortunately on Spark 3.0 the API were still marked as Evolving, so we were expecting breaking changes in the future.
Note: we didn’t find any breaking change on Spark 3.1, but that was the situation at the time we started the development.
Deal with Versions
Dealing with these breaking changes among the versions wasn’t easy. We couldn’t address all the Spark versions on the first release so we had to pick one.
Spark 2.3 was relatively old and would have been unsupported in the future. On the other hand Spark 3.0 was new, and not widely adopted; so we decided to start with Spark 2.4.
Finally after some month of coding we did out first pre-release on September 30th! 🎉

And just like that, a few hours later we got this.
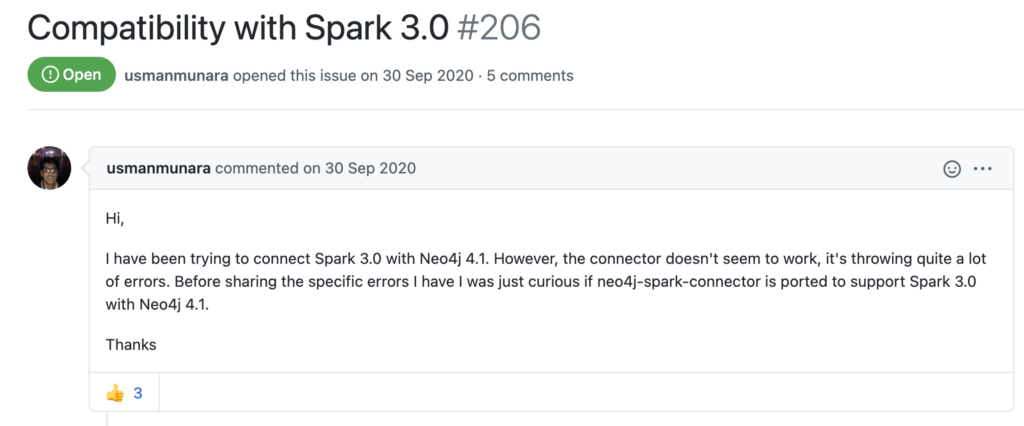
I have the feeling this would have happened anyway, regardless the initial version we chose.
Speaking of versions, we also needed to take care of different Scala versions supported by each Spark version:
- Spark 2.4 supports Scala 2.11 and Scala 2.12.
- Spark 3.0 supports Scala 2.12 and Scala 2.13, but dropped the support for Scala 2.11.
And we obviously need a JAR file for each combination!
To manage this version hell we used the Maven modules feature that allowed us to have common code among different Spark versions and to keep the development process agile and smooth.
neo4j-contrib/neo4j-spark-connector
As you can see on our repository we have 4 modules: 2 for each Spark version we support, one for the code shared between the versions, that’s basically the core of the connector, and one module for the test utilities. Should a breaking change be introduced in a future Spark release, we’ll just need to add another module. If you want to dive more into this process, take a look at this two pull requests: #282 and #283.
Neo4j vs Tables
The pain of integrating Spark and Neo4j is that Spark works with tables, and Neo4j doesn’t have anything similar to that, but instead nodes and relationships. We had to find solutions to a couple of problems here as well.
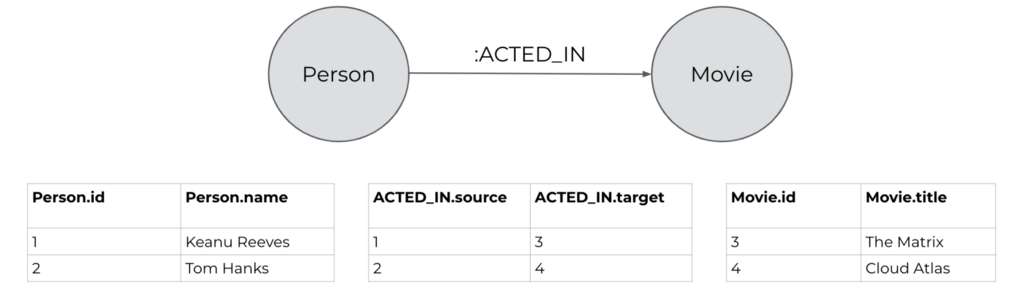
Tables or Labels?
To map a graph made of nodes and relationships into a table we created a column for each property of the nodes, and two columns for the relationship, that contain the source node ID and the target node ID. In this way we are able to represent nodes and relationship in a tabular way to work with the DataSource APIs.
Schema or Not Schema?
Tables have schema, Neo4j doesn’t. We had to find a way to extract a schema from a schema-less graph. For doing this, once we got the result from Neo4j, we flatten the results, and go through each property, extracting the type and eventually creating the schema of the result set.
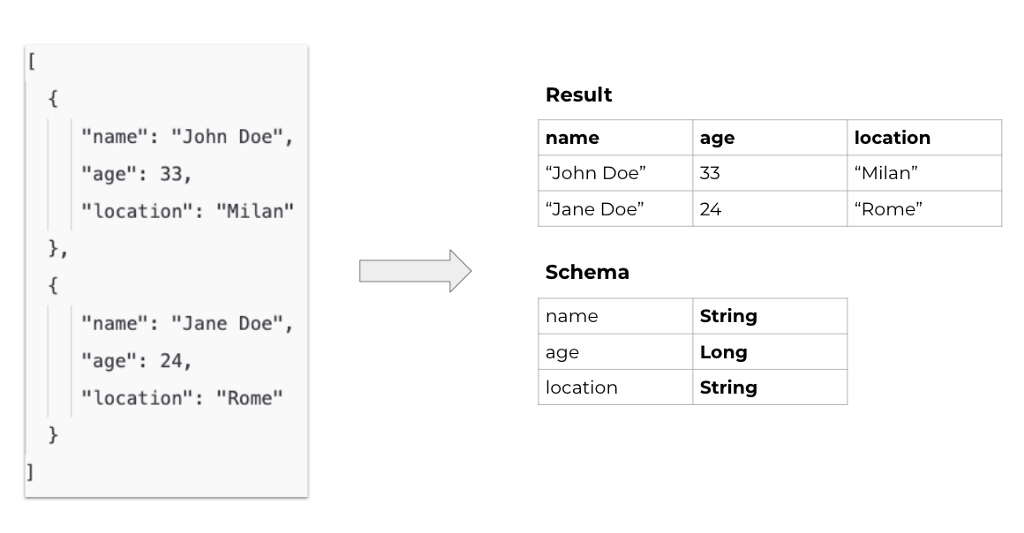
If a property doesn’t exist on all the nodes, it’s added with NULL value on the entries where it’s missing.
Can also happen that the same property has mixed types across nodes; in this case each value of that property is casted to a String, no matter the initial type.
Final Result — And How To Use It
Let’s quickly look at the API of the Neo4j Connector for Apache Spark
Here you can see how to read all the nodes that have the labels :Person:Admin using Scala, Python and R.

Other ways to read from (and write to) Neo4j are by using relationship-based or Cypher-query based APIs.


As said, here’s also an example on how to write a DataFrame to Neo4j that contains the people that made this connector happen:

You can find extensive examples in this repository that contains Apache Zeppelin notebooks you can play with!
utnaf/neo4j-connector-apache-spark-notebooks
Behind the scenes the connector uses the official Neo4j Java Driver, so you can connect with all the strategies allowed by the driver. The connector uses the options specified via the API to generate Cypher queries (kudos to Cypher DSL for making our life easier)
These examples only scratch the surface, these is much more to do with the Spark connector, so make sure to check the docs for more details.
We are not done yet! We will release the support for Spark 3.0 and Spark 3.1 soon! You can follow our roadmap on our Github Board.
We also managed to test the multi-language support for Scala, Java and Python (and soon R), you can read more about it in the article I wrote.
Testing polyglot libraries with GitHub Actions
The slides for my talk are also available here
I wish you a sparkling graph experience, please let us know via GitHub issues or Documentation feedback/edits if there are things that we can improve or that you need.
The Spark of Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English




