







YouTube Transcripts Into Knowledge Graphs for RAG Applications

Consulting Engineer, Neo4j
11 min read

Introduction
This blog will explore how to scrape YouTube video transcripts into a knowledge graph for Retrieval Augmented Generation (RAG) applications. We will use Google Cloud Platform to store our initial transcripts, LangChain to create documents from the transcripts, and a Neo4j graph database to store the resulting documents. In this example, we will create a knowledge graph containing objective musical facts spoken by Anthony Fantano himself on a select few music genres.

Requirements
- A Google Cloud Platform Account
- Access to the GCP YouTube Data API v3
- A free Neo4j AuraDB instance
Set Up Services
We need to set up a few things first if you’re following along. Otherwise, feel free to skip past this part. The GitHub for this project can be found here: https://github.com/a-s-g93/fantano-knowledge-graph
GCP

For this project, you’ll at least need some familiarity with Google Cloud Platform (GCP). We’ll be using the provided storage buckets and the YouTube Data API. When using the storage options, you will need to link billing to your account. This project should easily remain within the free tier pricing, but please remember to delete the storage bucket and its contents and any other resources you may have created in the project after following along.
YouTube API Steps:
- Create a new project in GCP.
- Search for the YouTube Data API v3 and enable the API.
- You will be prompted to create credentials — Follow the link.
- Select public data.
- Select Next.
- Copy your new API key to a safe location and select Done.
Cloud Storage Steps:
- In the same GCP project…
- From the sidebar, navigate to Cloud Storage → Buckets.
- Create a new bucket and save the bucket name to a safe location.
Service Account Steps (Required for Cloud Storage):
- From the sidebar, navigate to IAM & Admin → Service Accounts.
- Select Create Service Account.
- Provide an appropriate name for your service account.
- Select Create and Continue.
- In Role, Select Storage Admin.
- Select Done.
- Select the Actions tab under the new service account and select manage keys.
- Select Add Key → Create New Key.
- Select JSON.
- Create and download the key to a safe location.
Neo4j

Neo4j is a native graph database that has recently added vector indices for vector index search. This allows us to combine the benefits of a vector database with those of a graph database.
Neo4j provides a free AuraDB instance to all new users that should be capable enough for our use case here.
Aura Steps:
- Follow this link to the Aura console.
- Create a free AuraDB instance (not AuraDS).
- Save the provided file containing your connection information in a safe location.
Note: Your Aura instance will be paused after 3 days of inactivity and eventually will be auto-deleted if you don’t access it.
Set Up Environment
In the project root directory, run the following from the command line:
python3 -m venv venv
While in your IDE, navigate to venv/bin/activate and open the file. At the bottom of the file, add the following lines. This information will be the files and keys you saved in the above steps.
This method works for Linux / MacOS. On Windows, edit the activate.* file that corresponds to your appropriate shell.
export NEO4J_USERNAME=”DB USERNAME”
export NEO4J_PASSWORD="DB PASSWORD"
export NEO4J_DATABASE="DB DATABASE"
export NEO4J_URI="DB_URI"
export YOUTUBE_API_KEY="key"
export GCP_SERVICE_ACCOUNT_KEY_PATH="/path/to/service_account_file/creds.json"
export GCP_BUCKET_NAME="your-video-name"
Once these variables are declared, save the file.
Data Model
The data model will follow a parent-child document structure where the full transcript is split into chunks of 512 characters (parents), and those chunks are further divided into chunks of size 140 (children). 512 is a standard chunk size, and 140 is a typical question size (Based on my experience with RAG applications).
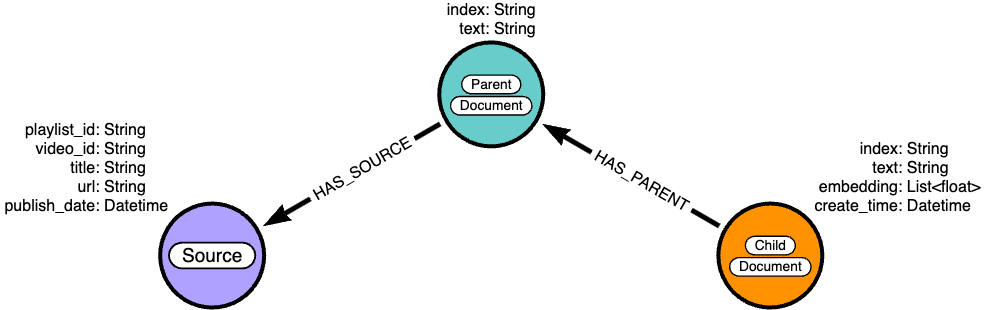
Retrieval Strategy
Only the child nodes will contain embeddings of their text and are targeted by the vector search algorithm. By embedding only the smaller child chunks, we are taking care to ensure that the embeddings of the chunks and questions have similar information granularity. This improves retrieval accuracy while still providing enough context to formulate a useful response. Once we find our top matches by similarity score, we can traverse the graph relationships to return the children nodes’ parents to the LLM.
Scraping Transcripts
Get Channel ID
In order to get our transcripts, we first need to retrieve the channel ID for The Needle Drop YouTube channel. We do this by searching with the YouTube API and taking the first channel that appears.
We format our search query as: the+needle+drop
If you are interested in scraping transcripts from your own YouTube channel, the channel ID can be found under Account → Advanced Settings → Channel ID.
def _get_channel_id() -> str:
address = f"https://www.googleapis.com/youtube/v3/search?q=the+needle+drop&key={os.environ.get('YOUTUBE_API_KEY')}&part=snippet"
req = requests.get(address)
data = req.json()
return data['items'][0]['snippet']['channelId']
Get Desired Playlist IDs
I’ve provided a JSON file in the repo that contains some playlist IDs. However, you may find other playlist IDs by doing the following:
- Navigate to the YouTube channel page of interest
- Navigate to the channel playlists page.
- Click on the desired playlist.
- In the address bar copy the ID following “list=”
e.g. https://www.youtube.com/watch?v=YGIKZALy2Gw&list=PLP4CSgl7K7opDaYNVTUg0Wa84shA_5sr8
- Add your playlist ID and the title to the resources/playlist_ids.json file as follows.
"electronic": "PLP4CSgl7K7ormBIO138tYonB949PHnNcP"
Get Video Info
We can now begin pulling the YouTube video information. Each API call returns a page with a max of 50 videos, so we need to use the “nextPageToken” value to find each successive page until we retrieve all the videos. We can do this with the following recursive method.
def scrape_video_info(self, next_page_token: str = None, total_results: int = -1, videos: List[str] = []) -> List[str]:
address = f"https://www.googleapis.com/youtube/v3/playlistItems?playlistId={self.playlist_id}&key={os.environ.get('YOUTUBE_API_KEY')}&part=snippet&maxResults=50"
if not next_page_token:
vid_req = requests.get(address)
else:
vid_req = requests.get(address+f'&pageToken={next_page_token}')
vids = vid_req.json()
if total_results == -1:
total_results = vids['pageInfo']['totalResults']
print('total results set: ', total_results)
videos += [{"id": x['snippet']['resourceId']['videoId'],
"title": x['snippet']['title'],
"publish_date": x['snippet']['publishedAt'][:10]} for x in vids['items']]
print("total results: ", total_results)
print("ids retrieved: ", len(videos), "n")
if "nextPageToken" not in vids.keys():
print("complete")
self._scraped_video_info = videos
return videos
self.scrape_video_info(next_page_token=vids['nextPageToken'], total_results=total_results, videos=videos)
Once we have retrieved all our videos, we can save the ids, titles, and publish dates as a CSV file in our GCP Storage bucket for safekeeping. This will also be useful to compare against if we decide to check back in and retrieve any new videos uploaded to the channel playlist.
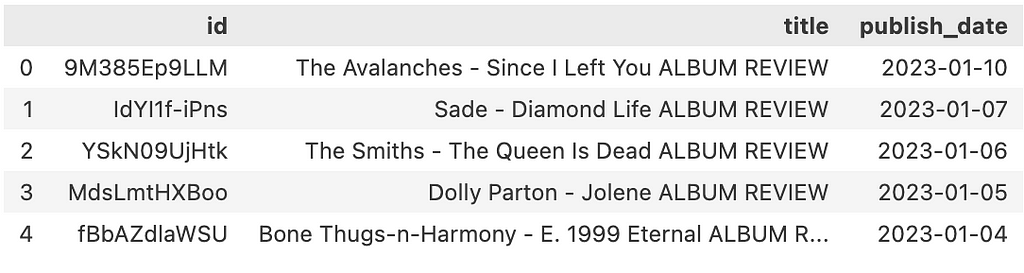
Get Video Transcripts
Now, in order to collect our transcripts, we will use the youtube_transcript_api library. First, we retrieve the recently created CSV file with all of our YouTube video information. Then, we can iterate over the rows and attempt to create a transcript for each video.
def _create_transcript(video_id: str) -> str:
raw_transcript = YouTubeTranscriptApi.get_transcript(video_id)
# instantiate the text formatter
formatter = TextFormatter()
# format the video into a string without timestamps, etc...
transcript_formatted = formatter.format_transcript(raw_transcript)
# replace newlines with a space
return transcript_formatted.replace("n", " ")
Sometimes, a transcript fails… From what I’ve seen, this can happen when a live video is scheduled to occur but hasn’t been recorded yet or closed captioning isn’t enabled. Each uploaded transcript is in JSON format, like the example below.
{
"video_id": "-80PEYVeI4E",
"title": "Godspeed You! Black Emperor- Lift Yr. Skinny Fists Like...",
"publish_date": "2014-07-23",
"transcript": "[Laughter] hi everyone Anthony fantano here the internet's..."
}
Chunking Transcripts
Chunking is the process of breaking text into more manageable pieces to be fed into LLMs. We’ll use LangChain’s TokenTextSplitter with the standard chunk size of 512 with an overlap of 64 tokens to process each transcript parent chunk. Then, we’ll use the RecursiveCharacterTextSplitter with a size of 140 to create the child chunks. We will also clean up some text by removing words such as “um” and “ah” from the transcripts.
Loading Transcripts
Once chunked, we can load the transcripts into our graph using the Neo4j Python driver and some Cypher. Before loading the transcript chunks, we need to create uniqueness constraints on Source and Document nodes. This ensures that we don’t accidentally load duplicate data.
CREATE CONSTRAINT source_url FOR (s:Source) REQUIRE s.url IS UNIQUE;
CREATE CONSTRAINT document_id FOR (d:Document) REQUIRE d.index IS UNIQUE;
We also must create an index on the embedding property of the Child nodes in order to use vector index search. This is done with the following query, where 96 is the embedding dimension of SpaCy embeddings.
CREATE VECTOR INDEX `text-embeddings`
FOR (n: Child) ON (n.embedding)
OPTIONS {indexConfig: {
`vector.dimensions`: 96,
`vector.similarity_function`: 'cosine'
}
}
The below code snippet iterates through the child documents and formats them into dictionaries to be loaded into the graph. Child documents contain metadata about their parent and source nodes. This is also where the embeddings for the Child nodes are generated. We are using SpaCy embeddings orchestrated by LangChain, which is a free embedding option. We then load the list of dictionaries into the graph.
result = []
for idx, bat in enumerate(batch_method(chunker.chunks_as_list, 20)):
new_nodes = prepare_new_nodes(data=bat, playlist_id=playlist_id, embedding_service=embed)
result+=new_nodes
print("total percent: ", str(round(((20*idx)+1) / playlist_total, 4)*100)[:4], "%", " batch", idx+1, end="r")
writer.load_nodes(data=result)
Below is the Cypher query used to load the data.
UNWIND $data AS param
MERGE (child:Document {index: param.child_index})
MERGE (parent:Document {index: param.parent_index})
MERGE (s:Source {url: param.url})
SET
child:Child,
child.create_time = datetime(),
child.text = param.transcript,
child.embedding = param.embedding,
parent:Parent,
parent.text = param.parent_transcript,
s.title = param.title,
s.playlist_id = param.playlist_id,
s.video_id = param.video_id,
s.publish_date = param.publish_date
MERGE (parent)-[:HAS_SOURCE]->(s)
MERGE (child)-[:HAS_PARENT]->(parent)
A Note on Embeddings
In this project, we are using SpaCy embeddings because they are a free alternative to more sophisticated options such as OpenAI or VertexAI. Our embeddings are only 96 dimensions, while OpenAI and VertexAI offer 1536 and 768-dimension embeddings, respectively. This results in significantly less meaning and context preservation in our embeddings. If you’d like to use a different embedding service in this project, you may change the __init__ method of the EmbeddingService class in tools/embedding.py, as well as the `vector.dimensions` parameter in the vector index appropriately.
def __init__(self) -> None:
"""
SpaCy embedding service.
"""
self.embedding_service = SpacyEmbeddings()
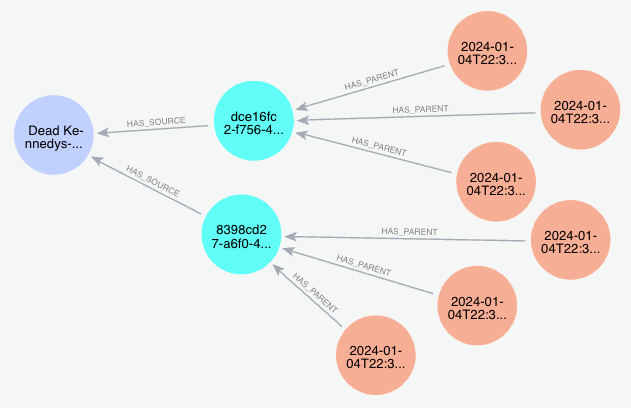
Graph
We can see an example path from the graph below. The purple node is the source video and contains information such as the video title and publish date, the blue nodes are the parent text chunks that will be returned upon vector search, and the orange nodes are the child text chunks that contain the embeddings to be matched against.
Conclusion & Next Steps
We have now constructed a simple knowledge graph that can be used for RAG applications. In the next blog, we will explore how to build a basic RAG application using this graph. The Github for this project can be found here: https://github.com/a-s-g93/fantano-knowledge-graph and will be updated as this project develops.
YouTube Transcripts Into Knowledge Graphs for RAG Applications was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles
A Knowledge Layer For Your Agentic Systems on Google Cloud



Architecting Graph-Based Agentic System: When a Regulator Asks “Why Was This Loan Approved?”