Traversal Framework Java API
TraversalDescription
TraversalDescription is the main interface used for defining and initializing traversals.
It is not meant to be implemented by users of the Traversal Framework, but it works as a means for the user to describe traversals.
TraversalDescription instances are immutable.
Their methods return a new TraversalDescription that is modified according to the object that the method was invoked on, with its arguments.
The method traverse() returns the result of the traversal defined in the TraversalDescription.
The Traverser object
The Traverser object is the result of invoking traverse() on TraversalDescription.
It represents a traversal positioned on the graph and a specification of the format of the result.
The actual traversal is performed lazily each time the next() method of the iterator of the Traverser is invoked.
The following is an example of Traverser using default values, that is, Uniqueness: NODE_GLOBAL, Expander: BOTH, and Branch Ordering: PREORDER_DEPTH_FIRST:
TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription();
}
Traverser traverser = td.traverse( startNode );
for ( Path path : traverser ) {
// Extend as needed
}Additionally, the Traverser features methods for reading the last relationships() and nodes() for each of the returned Paths and metadata().
It has convenience methods for finding the total number of returned paths, getNumberOfPathsReturned(), and the number of relationships traversed in getNumberOfRelationshipsTraversed().
Using relationships()
The method relationships() defines relationship types and, optionally, the relationship direction to be traversed.
By default, all relationships are traversed, regardless of their type.
However, if one or more relationships are added, then only the added types are traversed.
TraversalDescription td = transaction.traversalDescription()
.relationships(RelationshipType.withName("A"))
.relationships(RelationshipType.withName("B"), Direction.OUTGOING);
return td.traverse(startNode);Using Evaluators
An Evaluator takes the Path from the start node to the current node and decides whether the Path should be:
-
Included in the result.
-
Expanded for further evaluation.
Given Path, an evaluator can take one of four actions:
-
Evaluation.INCLUDE_AND_CONTINUE— Include the current node in the result and continue the traversal. -
Evaluation.INCLUDE_AND_PRUNE— Include the current node in the result, but do not continue the traversal. -
Evaluation.EXCLUDE_AND_CONTINUE— Exclude the current node from the result, but continue the traversal. -
Evaluation.EXCLUDE_AND_PRUNE— Exclude the current node from the result and do not continue the traversal.
|
As more than one evaluator can be added, different combinations might lead to unexpected outcomes. For this reason, keep in mind that:
|
Built-in Evaluators
The Traversal Framework provides several built-in evaluators:
| Evaluator | Description |
|---|---|
|
Includes and continues on all nodes. |
|
Includes only paths at the given depth, pruning everything else. |
|
Includes paths up to the given depth, pruning everything deeper. |
|
Includes paths from the given depth, ignoring those before and never prunes anything. |
|
Includes only the paths of depth equal to and between the 2 given depths. |
|
Allows the choice of which evaluation to take based on whether the last relationship matches one of the given ones. |
|
Only returns paths in which the final relationship matches the given ones. |
|
Allows the choice of which evaluation to take based on whether the last node matches one of the given nodes. |
|
Returns a path if all given nodes are contained within it. |
|
Returns a path if any of the given evaluators include the current path. |
|
Returns a path if one of the given nodes is at the given depth. |
Here is an example of how to use a built-in evaluator:
TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription()
.evaluator(Evaluators.atDepth(2));
}
td.traverse( startNode );Custom implementations of Evaluator
Now you can see an example of a custom implementation that includes only paths that end with a node of a certain label:
class LabelEvaluator implements Evaluator {
private final Label label;
private LabelEvaluator(Label label) {
this.label = label;
}
@Override
public Evaluation evaluate(Path path) {
if (path.endNode().hasLabel(label)) {
return Evaluation.INCLUDE_AND_CONTINUE;
} else {
return Evaluation.EXCLUDE_AND_CONTINUE;
}
}
}The following example features a combined evaluator, which returns all paths of length 2 that also have an end node with the label A:
TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription()
.evaluator(Evaluators.atDepth( 2 ))
.evaluator(new LabelEvaluator(Label.label("A")));
}
td.traverse( startNode );Uniqueness options
Although the default is NODE_GLOBAL, it is possible to set the rules for how positions can be revisited during a traversal by adjusting the levels of Uniqueness.
These are some of the available options:
-
NONE— Any node in the graph may be revisited. -
NODE_GLOBAL— No node in the entire graph may be visited more than once. This could potentially consume a lot of memory since it requires keeping an in-memory data structure remembering all the visited nodes. -
RELATIONSHIP_GLOBAL— No relationship in the entire graph may be visited more than once. Just likeNODE_GLOBAL, this could potentially use up a lot of memory. However, since graphs typically have a larger number of relationships than nodes, the memory overhead of thisUniquenesslevel could grow even quicker. -
NODE_PATH— A node may not occur previously in the path reaching up to it. -
RELATIONSHIP_PATH— A relationship may not occur previously in the path reaching up to it. -
NODE_RECENT— Similar toNODE_GLOBALwhen it comes to using a global collection of visited nodes each position is checked against. However, this Uniqueness level has a cap on how much memory it may consume in the form of a collection that only contains the most recently visited nodes. The size of this collection can be specified by providing a number as the second argument to theTraversalDescription.uniqueness()-methodalong with the Uniqueness level. -
RELATIONSHIP_RECENT— Works likeNODE_RECENT, but with relationships instead of nodes.
Here is an example of a traversal using a built-in Uniqueness constraint:
TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription();
.uniqueness( Uniqueness.RELATIONSHIP_GLOBAL )
}
td.traverse( startNode );BranchOrderingPolicy and BranchSelector
BranchOrderingPolicy is a factory for creating BranchSelectors to decide in what order branches are returned — that is, where a branch’s position is represented as Path from the start node to the current node.
The Traversal Framework provides a few basic ordering implementations based on the depth-first and breadth-first algorithms. These are:
-
BranchOrderingPolicies.PREORDER_DEPTH_FIRST— Traversing depth first, visiting each node before visiting its child nodes. -
BranchOrderingPolicies.POSTORDER_DEPTH_FIRST— Traversing depth first, visiting each node after visiting its child nodes. -
BranchOrderingPolicies.PREORDER_BREADTH_FIRST— Traversing breadth first, visiting each node before visiting its child nodes. -
BranchOrderingPolicies.POSTORDER_BREADTH_FIRST— Traversing breadth first, visiting each node after visiting its child nodes.
|
Keep in mind that breadth-first traversals have a higher memory overhead than depth-first traversals. |
The following example shows the result of BranchOrderingPolicy without any extra filter:
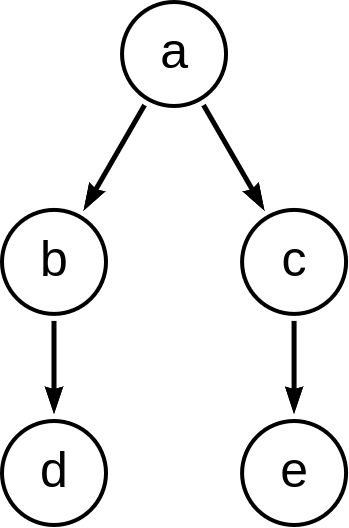
| Ordering policy | Order of the nodes in traversal |
|---|---|
|
a, b, d, c, e |
|
d, b, e, c, a |
|
a, b, c, d, e |
|
d, e, b, c, a |
Depth-first and breadth-first are common policies and can be accessed by the convenience methods breadthFirst() and depthFirst().
This is equivalent to setting the BranchOrderingPolicies.PREORDER_BREADTH_FIRST / BranchOrderingPolicies.PREORDER_DEPTH_FIRST policy.
depthFirst():TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription()
.depthFirst();
}
td.traverse( startNode );BranchOrderingPolicies.PREORDER_BREADTH_FIRST:TraversalDescription td;
try ( Transaction tx = graphDb.beginTx() ) {
td = tx.traversalDescription()
.order( BranchOrderingPolicies.PREORDER_BREADTH_FIRST );
}
td.traverse( startNode );Since BranchSelector carries state and hence needs to be uniquely instantiated for each traversal, it should be supplied to the TraversalDescription through a BranchOrderingPolicy interface, which is a factory of BranchSelector instances.
Even though a user of the Traversal Framework rarely needs to implement their own BranchSelector/ BranchOrderingPolicy, it is relevant to know that these parameters let graph algorithm implementors provide their own traversal orders.
Check the Neo4j Graph Algorithms package to see BestFirst order BranchSelector / BranchOrderingPolicy that is used in BestFirst search algorithms such as A* and Dijkstra.
Using PathExpander
The Traversal Framework uses PathExpander to discover the relationships that should be followed from a particular path to further branches in the traversal.
There are multiple ways of specifying PathExpander, such as:
-
The built-in
PathExpanderdefines some commonly usedPathExpanders. -
The
PathExpanderBuilderallows the combination of definitions. -
It is possible to write a custom
PathExpanderby implementing thePathExpanderinterface.
Built-in PathExpanders
The following path expanders are found in the class PathExpander and can be used to set a more specific PathExpander for the traversal:
-
allTypesAndDirections()— Expands all relationships in all directions (default). -
forType(relationshipType)— Expands only relationships of a specific type. -
forDirection(direction)— Expands only relationships in a specific direction. -
forTypeAndDirection(relationshipType, direction)— Expands only relationships of a given type and a given direction. -
forTypesAndDirections(relationshipType, direction, relationshipType, direction, …)— Expands only relationships of the given types and their specific direction. -
forConstantDirectionWithTypes(relationshipType, …)— Expands only relationships of the given types, if they continue in the direction of the first relationship.
Here is an example of how to set a custom relationship expander that only expands outgoing relationships with the type A:
TraversalDescription td = transaction.traversalDescription()
.expand(PathExpanders.forTypeAndDirection( RelationshipType.withName( "A" ), Direction.OUTGOING ));
td.traverse( startNode );PathExpanderBuilder
The PathExpanderBuilder allows the combination of different PathExpander definitions.
It provides a more fine-grained level of customization without the need to write PathExpander from scratch.
It also contains a set of static methods allowing the creation of PathExpander with the following methods:
-
empty()— Expands no relationships. -
emptyOrderedByType()— Expands no relationships and guarantees the order of how types will be expanded when any are added. -
allTypesAndDirections()— Expands all relationships in any direction. -
allTypes(Direction)— Expands all relationships in the given direction.
That PathExpander can then be further defined by the following methods:
-
add(relationshipType)— Expands relationships of the given type. -
add(relationshipType, direction)— Expands relationships of the given type and direction. -
remove(relationshipType)— Removes the expansion of relationships of the given type. -
addNodeFilter(filter)— Adds a filter based on nodes. -
addRelationshipFilter(filter)— Adds a filter based on relationships.
This is how it may look:
TraversalDescription td = transaction.traversalDescription()
.expand(PathExpanderBuilder.empty()
.add(RelationshipType.withName("E1"))
.build());
td.traverse( startNode );The following is an example of a custom PathExpander which tracks the weight of the path in its BranchState and only includes paths if the total weight is smaller than the given maximum weight:
class MaxWeightPathExpander implements PathExpander<Double>
{
private final double maxWeight;
public MaxWeightPathExpander( double maxWeight ) {
this.maxWeight = maxWeight;
}
@Override
public ResourceIterable<Relationship> expand( Path path, BranchState<Double> branchState )
{
if (path.lastRelationship() != null) {
branchState.setState( branchState.getState() + (double) path.lastRelationship().getProperty( "weight" ) );
}
ResourceIterable<Relationship> relationships = path.endNode().getRelationships( Direction.OUTGOING );
ArrayList<Relationship> filtered = new ArrayList<>();
for ( Relationship relationship : relationships ) {
if ( branchState.getState() + (double) relationship.getProperty( "weight" ) <= maxWeight ) {
filtered.add(relationship);
}
}
return ResourceIterable.of(filtered);
}
@Override
public PathExpander reverse()
{
throw new RuntimeException( "Not needed for the MonoDirectional Traversal Framework" );
}
}ResourceIterable.of is available starting from Neo4j 2026.03.
Here is an example of how to use the custom PathExpander and set the initial state:
TraversalDescription td = transaction.traversalDescription()
.expand( new MaxWeightPathExpander(5.0), InitialBranchState.DOUBLE_ZERO );
td.traverse( startNode );