Profiling Queries
About this module
At the end of this module, you will be able to:
-
Profile queries against the graph.
-
Determine if a query can be improved.
Workflow for profiling queries
Understanding the performance of the queries for your use cases is an important part of implementing a graph data model. Here is the workflow you will use:
-
Load data into the graph.
-
Create queries that answer the application questions.
-
Execute the queries against the data to see if they retrieve the correct information.
-
PROFILE the query execution.
-
Identify problems and weaknesses in the query execution.
-
Can the query be rewritten to perform better?
-
Do we need to refactor the graph?
-
-
If necessary, modify the graph data model and refactor the graph.
-
PROFILE the same type of query against the refactored graph.
| The new query will be different due to the change in the graph data model. |
Example: Profiling a query
Here is the code to profile a query that retrieves all connections that have a destination of LAS:
PROFILE
MATCH (origin:Airport)-[c:CONNECTED_TO]->(destination:Airport)
WHERE destination.code = 'LAS'
RETURN origin, destination, c LIMIT 10To profile a query, simply add PROFILE to the beginning of the Cypher statement.
This executes the query as normal, but gives a different output, which shows every step in the query execution plan, and how much each step cost.
With PROFILE, the main metric we consider is db hits.
Execution time is important, but that is generally a result of administrative factors, like bandwidth, memory, and traffic volume.
db hits, on the other hand, are entirely a function of the data model and query.
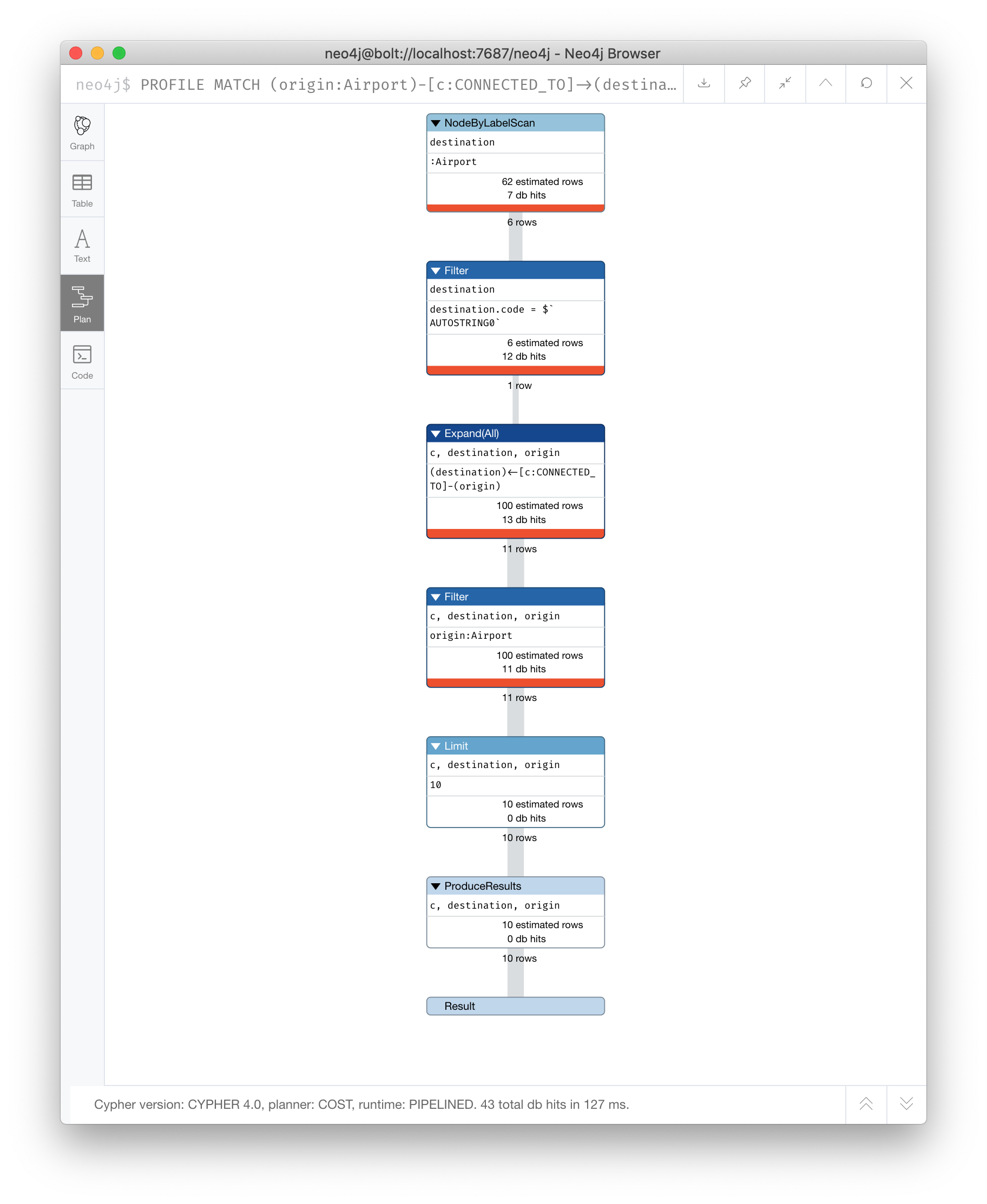
Analyzing the query profile - 1
The first step in any query is locating the anchor. In this case, Neo4j will anchor on the destination node set, because that one has a property filter while origin does not.
According to the PROFILE, the anchor was located by first locating all Airport nodes under the Airport label, then scanning to find the desired code property value.
This required 7 and 12 db hits respectively, and got us down to a single node—the perfect anchor set.
This label scan + property scan is much less efficient than an index lookup. We will observe that in a later exercise.
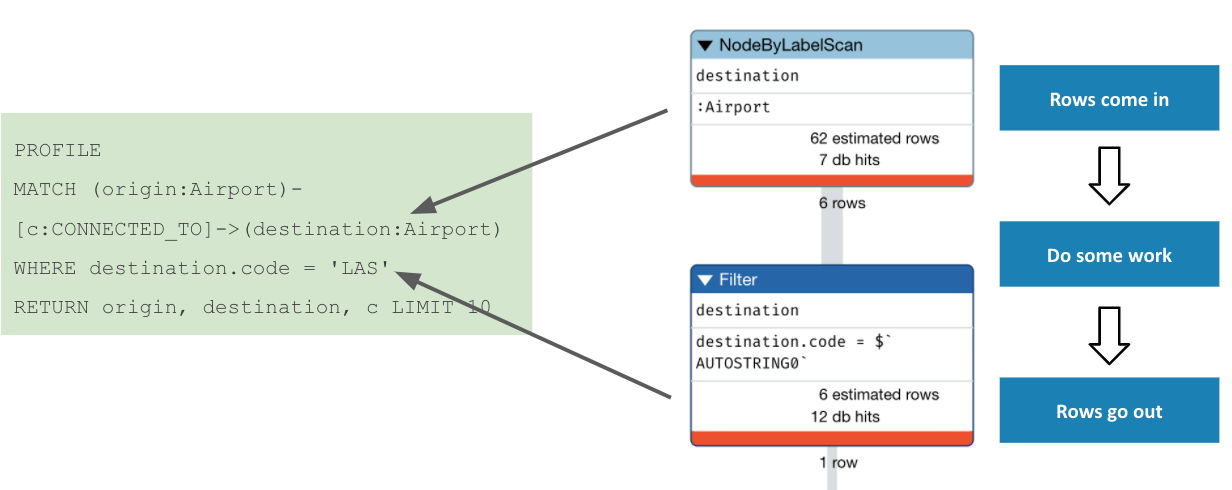
Analyzing the query profile - 2
With the anchor set identified, Neo4j then expanded along every incoming CONNECTED_TO relationship, finding 11 such paths with 13 and 11 db hits respectively.
Next, Neo4j checked which of those paths terminated at an origin node labeled Airport. Based on what we know about our model, it is no surprise that all 11 paths qualified. This is an example of providing an unnecessary filter. We could have dispensed with the Airport label on the origin set, and saved 11 db hits.
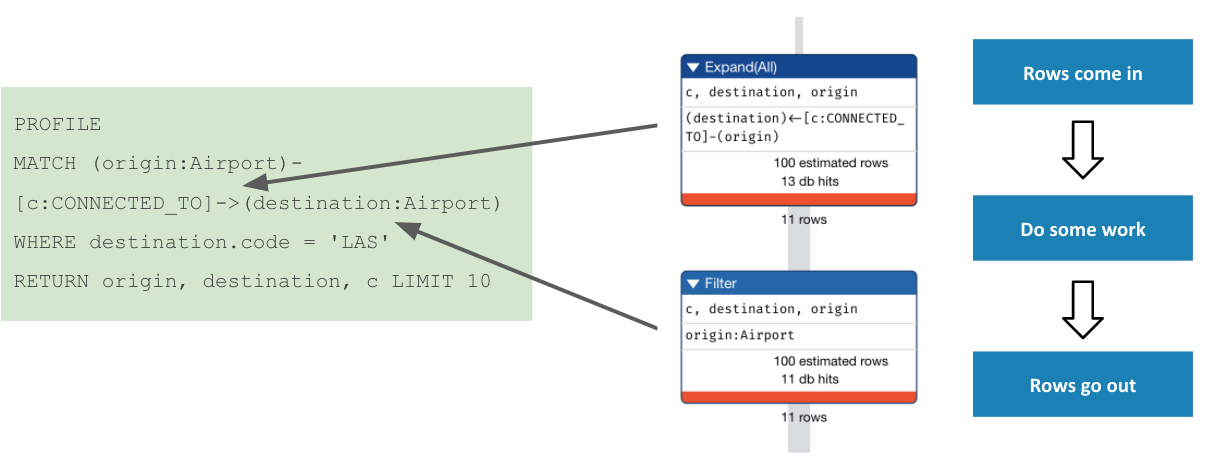
Analyzing the query profile - 3
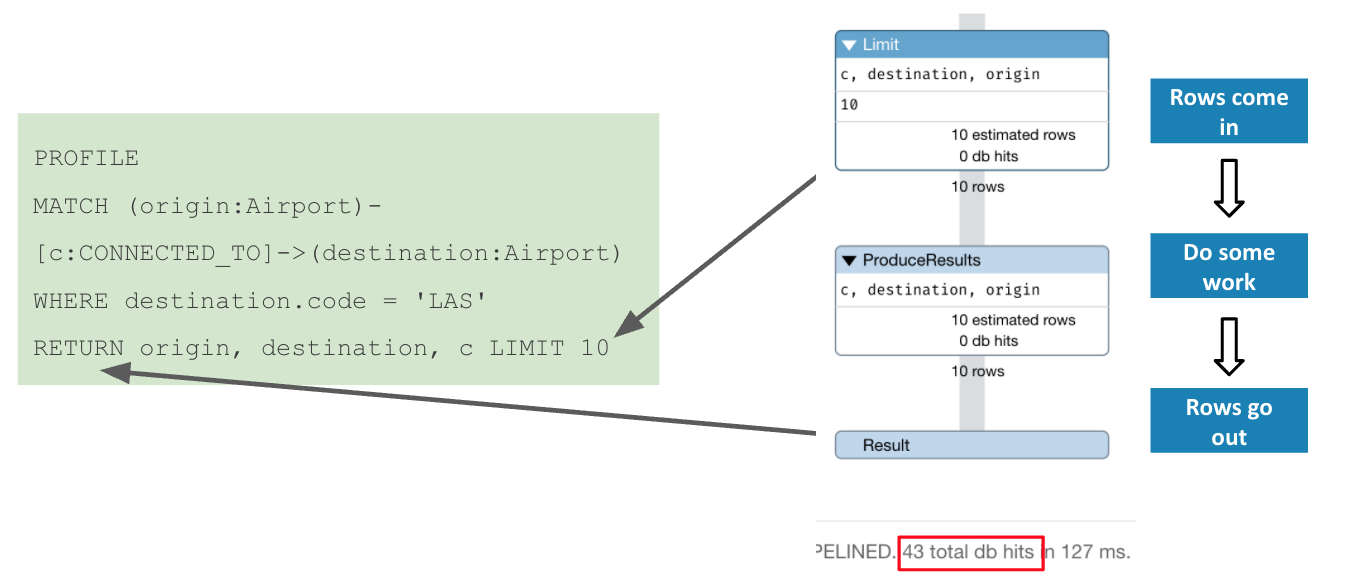
With traversal finished, Neo4j then returned the results, filtered by the LIMIT clause.
This operates entirely upon the objects already in memory, and so requires no db hits.
When all is said and done, you can see that total cost of this query was 43 db hits. We could have saved 11 by not filtering on Airport for the origin nodes. In addition, recall that identifying the anchor required 7+12 = 19 db hits. So our best opportunity for improving the performance of this query lies in finding a way to anchor more efficiently. PROFILE made that obvious, and we would have been unable to discover that by any other means.
Exercise 3: Profiling queries
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-neo4j-modeling-exercises
and follow the instructions for Exercise 3.
| This exercise has 2 steps. Estimated time to complete: 15 minutes. |
Do we need to change the model?
In the previous exercise, we asked this question:
What are the airports and flight information for flight number 1016 for airline WN?
This is our current model:
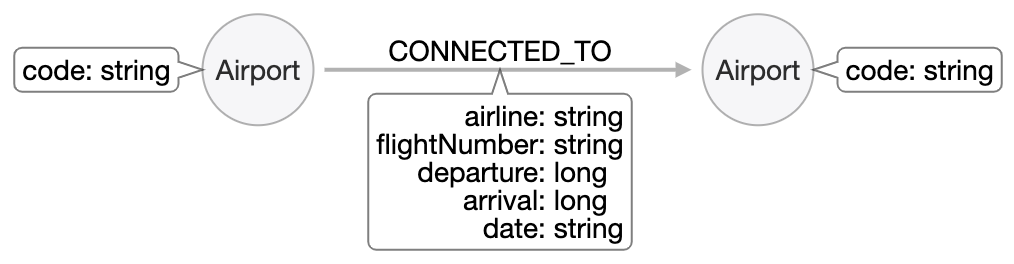
Here is the query:
PROFILE
MATCH (origin:Airport)-[connection:CONNECTED_TO]->(destination:Airport)
WHERE connection.airline = 'WN' AND connection.flightNumber = '1016'
RETURN origin.code, destination.code, connection.date, connection.departure, connection.arrivalHere is the profile for this query:

This query required 4382 db hits.
Recall that our dataset only has 100 flights in it. In other words, in order to answer this question, we needed to access the entire graph twice. Once to retrieve all airports and another time to retrieve the data in the pattern. The query executed reasonably quickly in terms of milliseconds, that is largely because the dataset is not large. Hence our insistence on using db hits as a measure—from that, we can tell that this query is grossly inefficient on this data model!
In the next lesson, we will implement a refactor to fix this.
Check your understanding
Question 1
What Cypher clause do you use to analyze the performance of a query?
Select the correct answer.
-
ANALYZE -
EXPLAIN -
PROFILE -
SHOW
Question 2
When a query executes, the execution plan uses what data structure to pass data from one step of the plan to the next?
Select the correct answer.
-
b-tree for the anchor node(s)
-
neo4j-object structure containing nodes visited
-
linked list of nodes visited
-
row containing node and relationship values
Question 3
What are some observations from the profile of a query that would indicate that the graph data model needs improvement, the graph needs an index, or the query needs to be rewritten?
Select the correct answers.
-
High number of db hits.
-
Increasing number of db hits as the query executes.
-
Seeing NodeByLabelScan as the first step of the query profile.
-
No rows returned after the first step.
Need help? Ask in the Neo4j Community