Refactoring Graphs
About this module
At the end of this module, you will be able to:
-
Create constraints that help with performance of node creation and queries.
-
Determine if a query can be improved.
-
Write Cypher code to refactor the data model in the graph.
-
Create indexes that will help with query performance.
-
Refactor a graph by creating intermediate nodes.
-
Refactor a graph by specializing relationships.
-
Perform batch processing to refactor a large graph.
| Because the code examples in this lesson modify the database, it is recommended that you do not execute them against your database as you will be doing so in the hands-on exercises. |
Evolving the model
After profiling queries and determining that they are not performing optimally, you must rethink your graph data model. You do so by examining how queries perform, especially with data at scale.
In the previous lesson, we saw that the query to retrieve the airports and flight information for flight number 1016 for airline WN ended up making two passes through the graph to perform the query. Our small database has only 100 flights in it, but it required over 4,000 db hits to perform the query.
To solve this problem, we introduce the intermediate node, Flight that is based upon the properties of the CONNECTED_TO relationship.
Here is how the model will evolve:
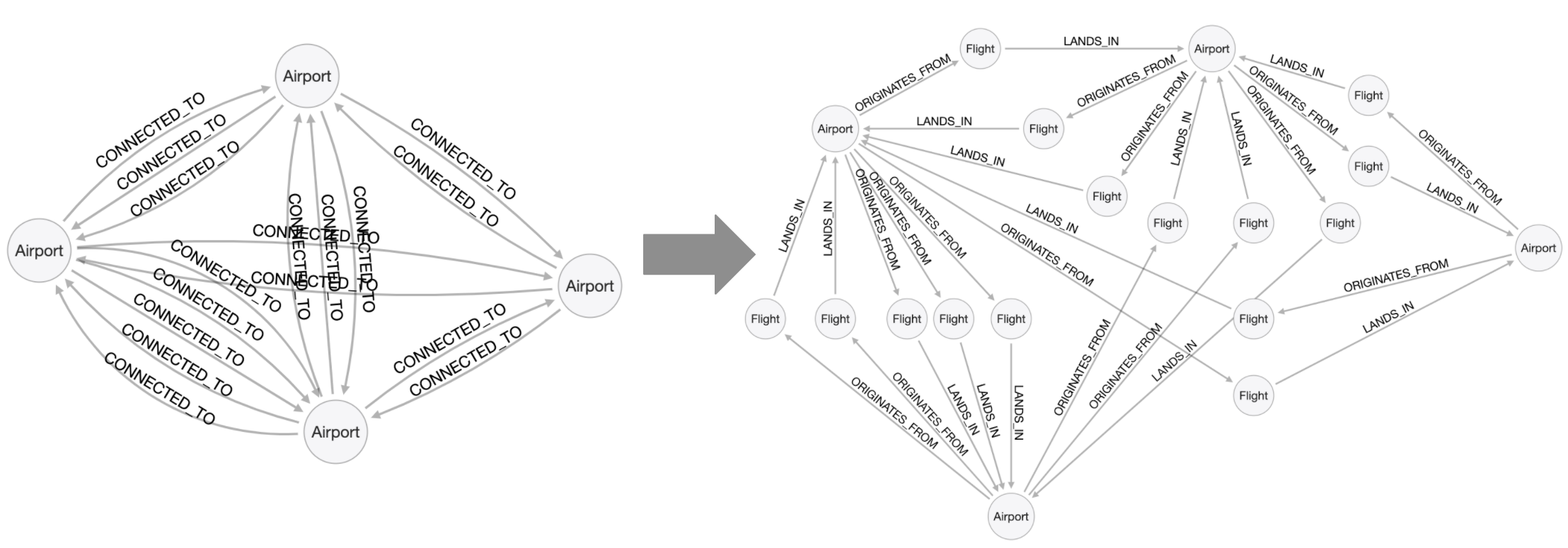
Refactoring steps
In most cases, you refactor the the implementation of the graph data model with these steps:
-
Create constraints as needed.
-
Execute the refactor:
-
MATCH the data you wish to move.
-
Create new nodes.
-
Create new relationships.
-
-
Create indexes as needed.
-
PROFILE all queries against the new model.
| If the new model performs well for all queries, delete the old model. Otherwise, leave both in place. |
Refactor details
Here are the details that show the CONNECTED_TO relationship properties and how they will be refactored as the Flight properties.
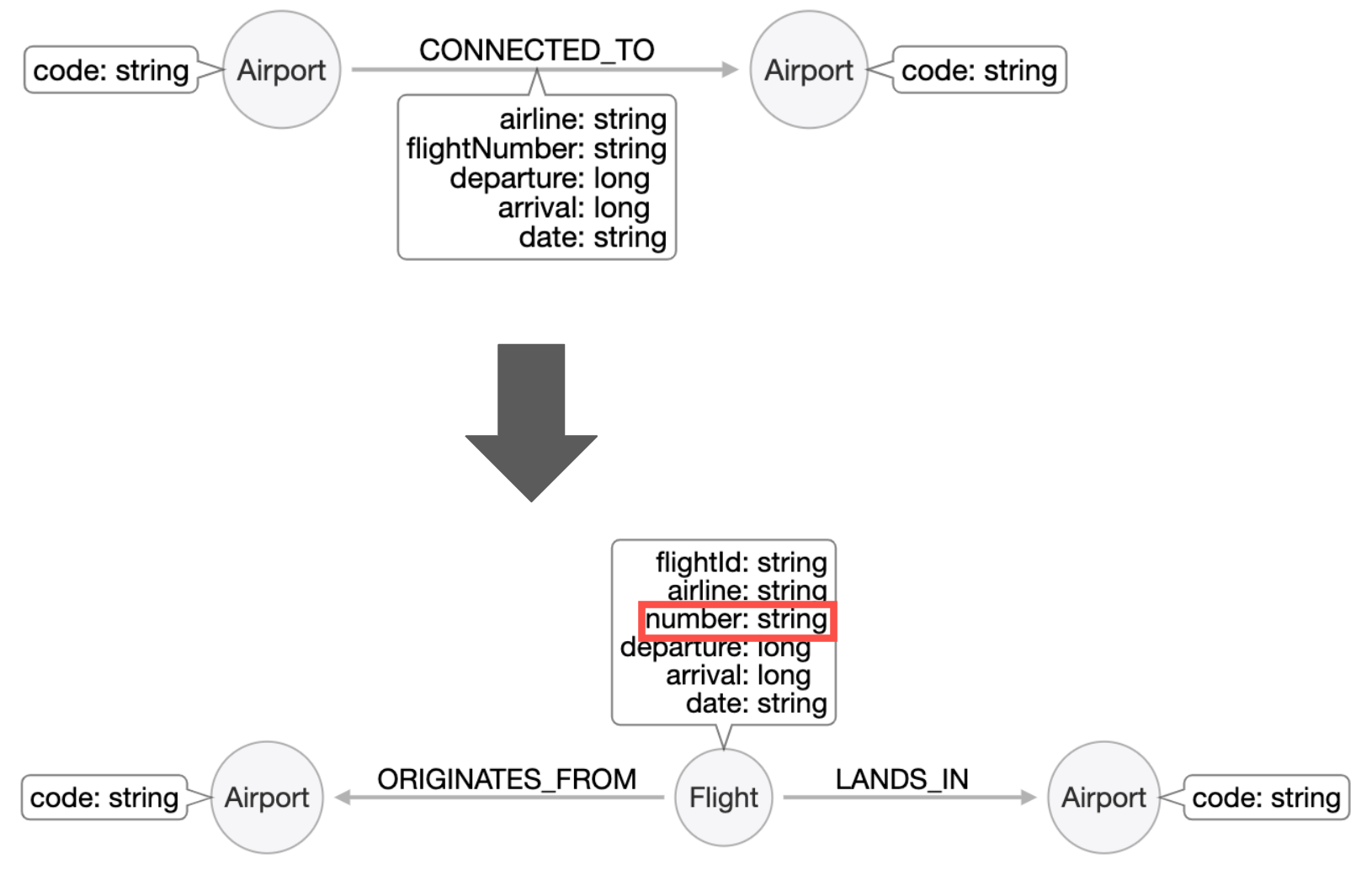
Notice that we will be adding a unique identifier for a Flight node, flightId.
Unique FlightId
Using a unique identifier for a flight enables us to quickly find a flight by its ID during a query. We create a uniqueness constraint for that property.
The flight number for a particular airline may not be unique, especially if we take into account the origin and destination airports. That is, the same flight number may be used for different from and to airports. In addition, we want to uniquely identify the date for the flight.
The Flight.flightId property will contain the following data which will be unique for all Flight nodes:
-
airline
-
flightNumber
-
code for the origin Airport
-
code for the destination Airport
-
date
Creating the constraint
Before we perform the refactoring of the existing graph, we add the uniqueness constraint:
CREATE CONSTRAINT Flight_flightId_constraint ON (f:Flight)
ASSERT f.flightId IS UNIQUERefactoring the graph
Here is the code to refactor the graph:
MATCH (origin:Airport)-[connection:CONNECTED_TO]->(destination:Airport)
MERGE (newFlight:Flight {flightId: connection.airline + connection.flightNumber +
'_' + connection.date + '_' + origin.code + '_' + destination.code })
ON CREATE SET newFlight.date = connection.date,
newFlight.airline = connection.airline,
newFlight.number = connection.flightNumber,
newFlight.departure = connection.departure,
newFlight.arrival = connection.arrival
MERGE (origin)<-[:ORIGINATES_FROM]-(newFlight)
MERGE (newFlight)-[:LANDS_IN]->(destination)This code looks scary at first, but it relies entirely on Cypher code you already know well.
It follows our refactoring steps:
-
Use
MATCHto fetch the data we wish to move. We are looking to move the CONNECTED_TO relationship data, so we create a query that will fetch every such relationship. -
Use
MERGEto create the new Flight nodes. As is always the best practice withMERGE, we only include the unique identifier, flightId in theMERGEstatement, where that property is a concatenation of many individually-non-unique things. All other Flight properties are set in a subsequentON CREATE SETclause, which maps 1:1 from the CONNECTED_TO properties. -
Use
MERGEto create the relationships connecting the new nodes. We need to do this twice, since Flights have both an ORIGINATES_FROM and LANDS_IN relationship.
Index for query performance
A very common qualifier for a query is the flight number. We want lookups of a Flight by its number to be fast. A flight number is not unique, but we want to be able to look up all flights with that number quickly.
You create the indexes after your have executed the refactoring code. This is because index maintenance is expensive and you do not want a large refactoring to take a long time to execute.
Creating the index
Here is the code to create the index on the flight number property:
CREATE INDEX Flight_number_index FOR (f:Flight) ON (f.number)Profiling the query
After you have refactored the graph, you then profile the query that you are hoping to improve.
Recall that the query is: What are the airports and flight information for flight number 1016 for airline WN?
Here is the original query:
PROFILE
MATCH (origin:Airport)-[connection:CONNECTED_TO]->(destination:Airport)
WHERE connection.airline = 'WN' AND connection.flightNumber = '1016'
RETURN origin.code, destination.code, connection.date, connection.departure, connection.arrivalWe must change the query to work with the new model as follows:
PROFILE
MATCH (origin)<-[:ORIGINATES_FROM]-(flight:Flight)-
[:LANDS_IN]->(destination)
WHERE flight.airline = 'WN' AND
flight.number = '1016' RETURN origin, destination, flight
Cleaning up the graph
If you are satisfied that the new model performs best for your queries, you can then clean up the graph to remove the CONNECTED_TO relationships. Relationships, especially those with properties take up unnecessary space in the graph.
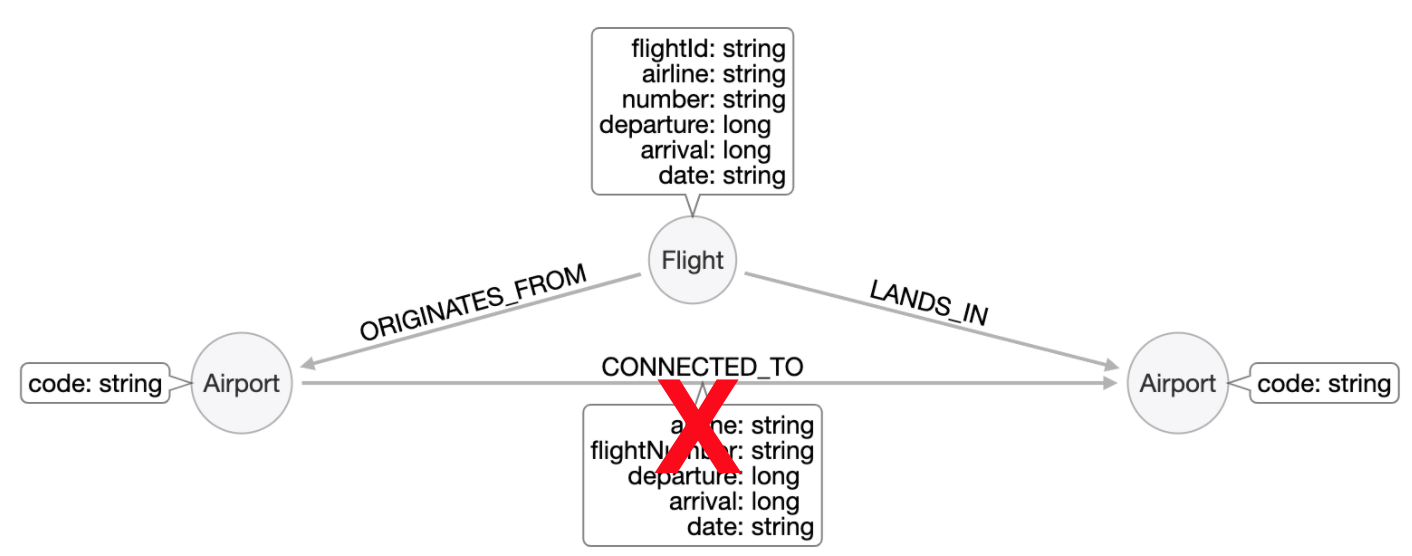
MATCH ()-[connection:CONNECTED_TO]->()
DELETE connectionExercise 4: Creating Flight nodes from CONNECTED_TO relationships
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-neo4j-modeling-exercises
and follow the instructions for Exercise 4.
| This exercise has 7 steps. Estimated time to complete: 30 minutes. |
Adding another domain question
We need to add another question for our application:
As a frequent traveller I want to find flights from <origin> to <destination> on <date> so that I can book my business flight.
For example:
Find all the flights going from Los Angeles (LAS) to Chicago Midway International (MDW) on the 3rd January, 2019.
Implementing the query
Here is the query:
MATCH (origin:Airport {code: 'LAS'})
<-[:ORIGINATES_FROM]-(flight:Flight)-[:LANDS_IN]->
(destination:Airport {code: 'MDW'})
WHERE flight.date = '2019-1-3'
RETURN origin, destination, flight| You will work with this query in the next exercise where you have loaded 10k nodes into the graph. |
Profiling the query
Here is the result of the profile on a graph that contains 10k nodes.
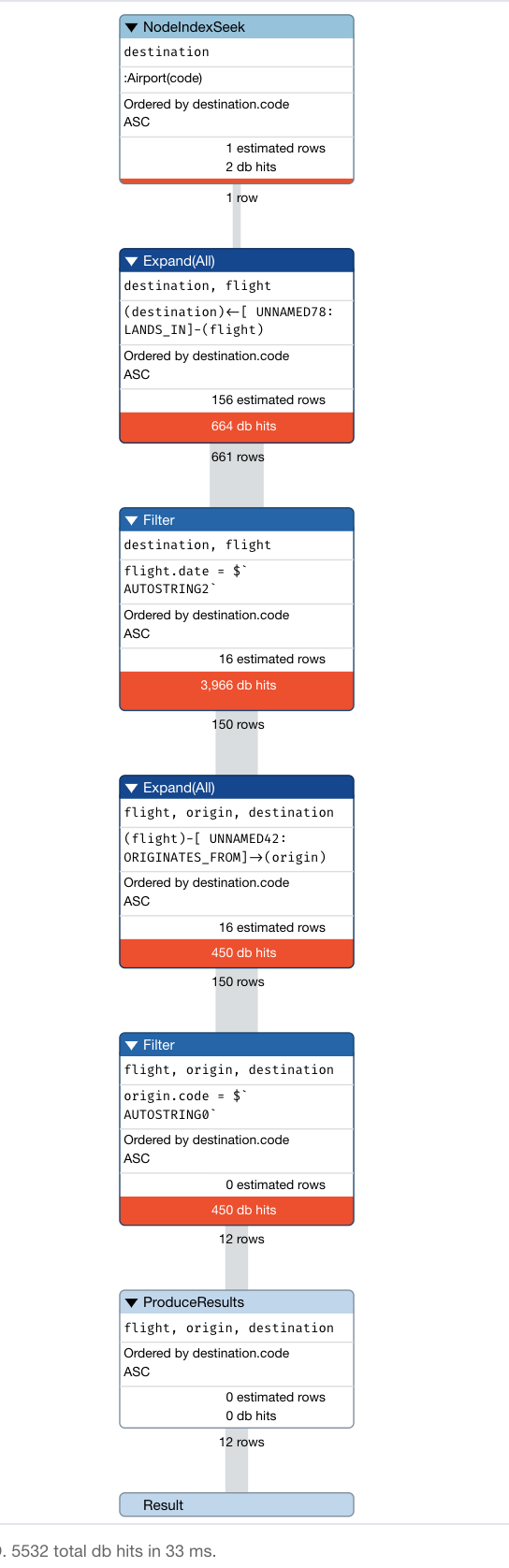
This query returns 12 flights.
5532 db hits which needs improvement. Adding an index to Flight on date does not improve the query.
Some stats about this graph:
-
64 airports
-
10000 flights
-
661 flights that land in MDW; 377 on 2019-1-3
-
1624 flights that originate from LAS; 426 on 2019-1-3
-
2367 flights on 2019-1-3
Searching for flights by day is a problem.
The query starts by using an index to find MDW but then has to traverse all incoming LANDS_IN relationships and check the Flight.date property on the other side. The more flights an airport has the more we will have to scan through, and since we are only working with 10,000 flights we must find a better way to model our data before importing any more data.
This is an opportunity to change the model.
Performing another refactor
We want to introduce AirportDay nodes so that we do not have to scan through all the flights going from an airport when we are only interested in a subset of them.
This is an instance where we do not want to remove the relationships between airports and flights because we need them for our first query "What are the airports and flight information for flight number 1016 for airline WN?".
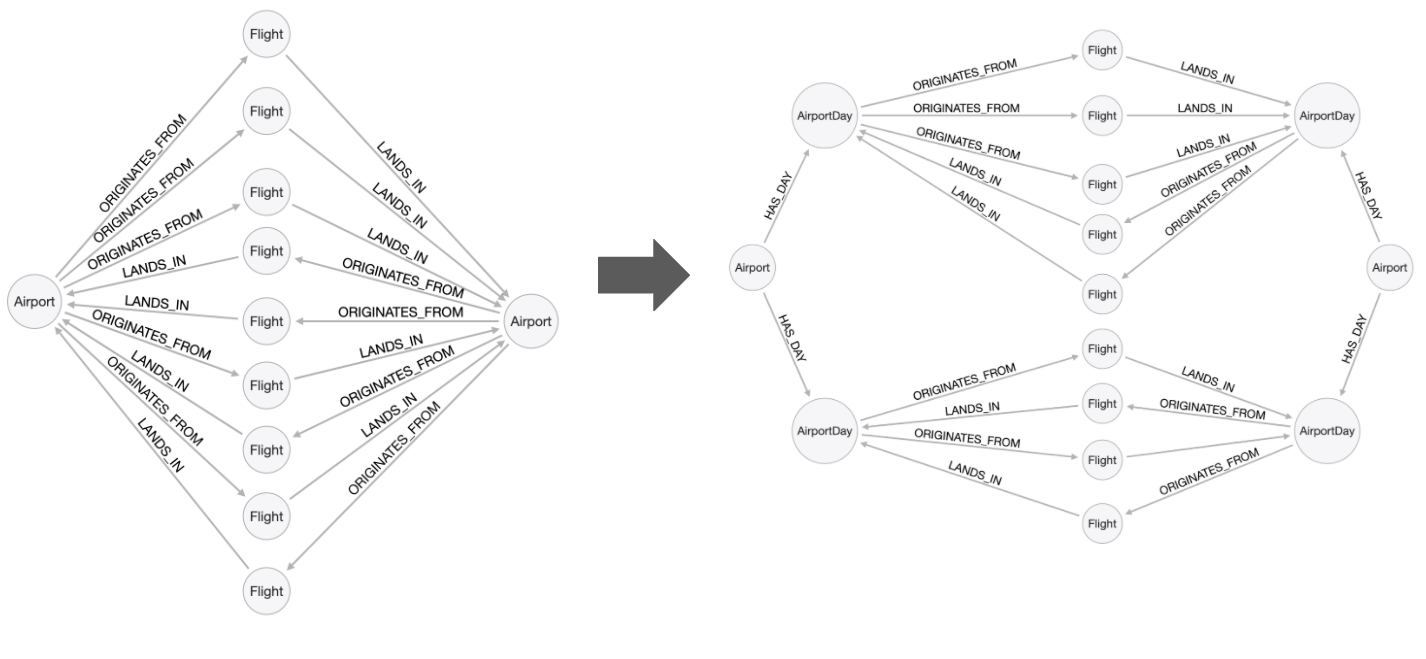
| You only pull out a node if you are going to query through it, otherwise a property will suffice. |
You must not be too aggressive with creating nodes from other nodes. If you pull out every single property and create nodes then you end up with an RDF model and lose the benefit of the property graph.
Refactor details
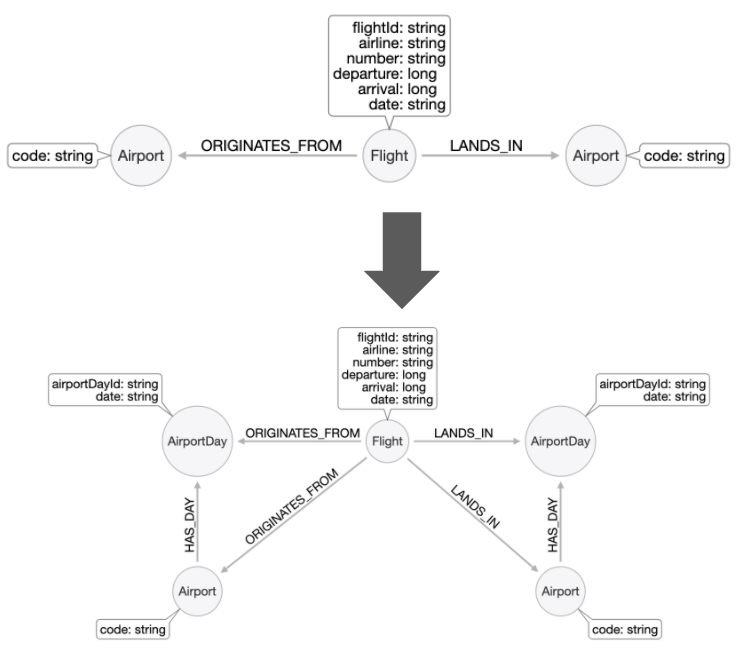
In this case we are adding the AirportDay node that will have date information. That way we do not have to go through the Flight nodes to find a date. Just like the Flight nodes, it will have a unique ID, AirportDay.airportDayId so that it can use it in the query.
CREATE CONSTRAINT AirportDay_airportDayId_constraint ON (a:AirportDay)
ASSERT a.airportDayId IS UNIQUEThen, you will want to:
-
MATCHthe data you want to move. -
Create the new AirportDay nodes.
-
Connect the new nodes to the existing graph.
Refactor implementation
MATCH (origin:Airport)<-[:ORIGINATES_FROM]-(flight:Flight)-
[:LANDS_IN]->(destination:Airport)
MERGE (originAirportDay:AirportDay {airportDayId: origin.code + '_' + flight.date})
SET originAirportDay.date = flight.date
MERGE (destinationAirportDay:AirportDay
{airportDayId: destination.code + '_' + flight.date})
SET destinationAirportDay.date = flight.date
MERGE (origin)-[:HAS_DAY]->(originAirportDay)
MERGE (flight)-[:ORIGINATES_FROM]->(originAirportDay)
MERGE (flight)-[:LANDS_IN]->(destinationAirportDay)
MERGE (destination)-[:HAS_DAY]->(destinationAirportDay)MERGE enables us to add a single AirportDay node per the airportDayId value and also ensure that only one relationship is created between a Flight and an AirportDay node.
Profile our first query
After a refactor, you must check that all queries perform OK. Here is our first query: What are the airports and flight information for flight number 1016 for airline WN?
PROFILE
MATCH (origin)<-[:ORIGINATES_FROM]-(flight:Flight)-
[:LANDS_IN]->(destination)
WHERE flight.airline = 'WN' AND
flight.number = '1016' RETURN origin, destination, flight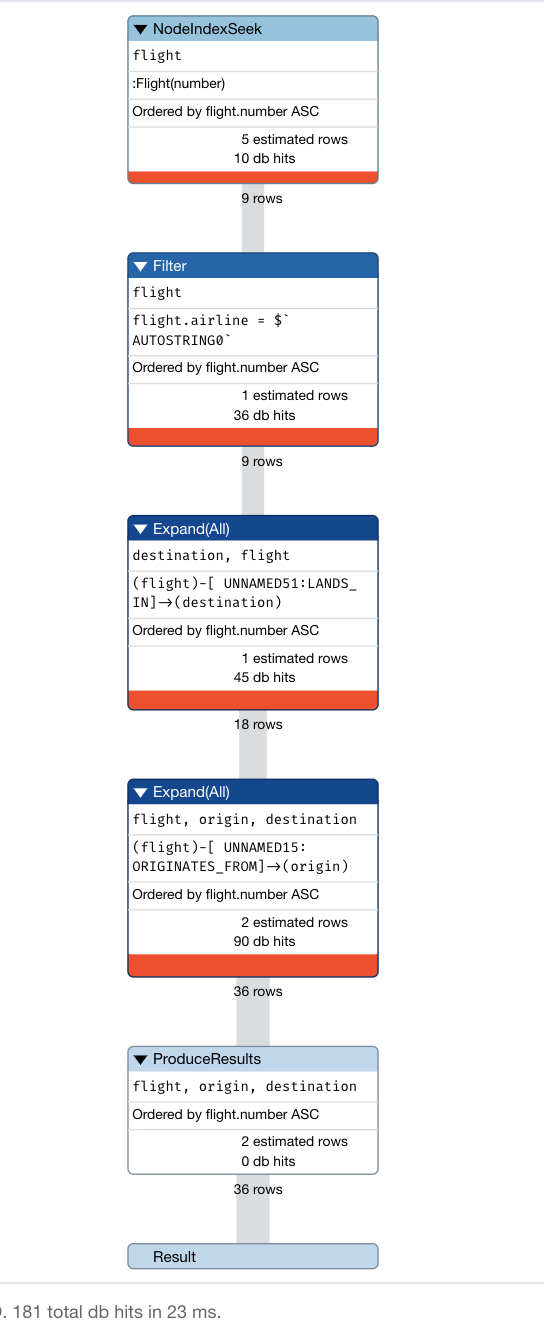
This query previously had 34 db hits, but now has 181. But, we added another 10K nodes to the graph so this is a reasonable outcome.
Profile our original second query
Then we want to profile our second query after the refactor: Find all the flights going from Los Angeles (LAS) to Chicago Midway International (MDW) on the 3rd January, 2019.
PROFILE MATCH (origin:Airport {code: 'LAS'})
<-[:ORIGINATES_FROM]-(flight:Flight)-
[:LANDS_IN]->
(destination:Airport {code: 'MDW'})
WHERE flight.date = '2019-1-3'
RETURN origin, destination, flight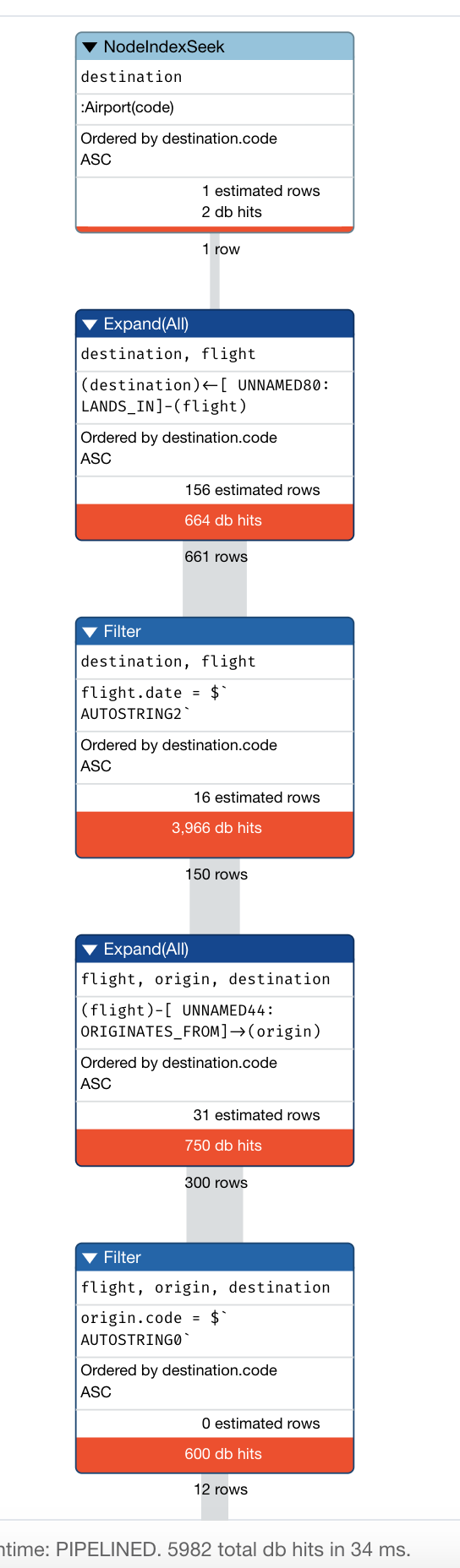
Here we see that the query has 5982 db hits, which is worse than the 5532 we had earlier before the refactor. This is because we need to incorporate the new model into the query.
Profile our revised second query
Here is a rewrite of the second query: Find all the flights going from Los Angeles (LAS) to Chicago Midway International (MDW) on the 3rd January, 2019. Due to the change in the model, we must rewrite the query as:
PROFILE MATCH (origin:Airport {code: 'LAS'})-
[:HAS_DAY]->(:AirportDay {date: '2019-1-3'})<-
[:ORIGINATES_FROM]-(flight:Flight),
(flight)-[:LANDS_IN]->
(:AirportDay {date: '2019-1-3'})<-
[:HAS_DAY]-(destination:Airport {code: 'MDW'})
RETURN origin, destination, flight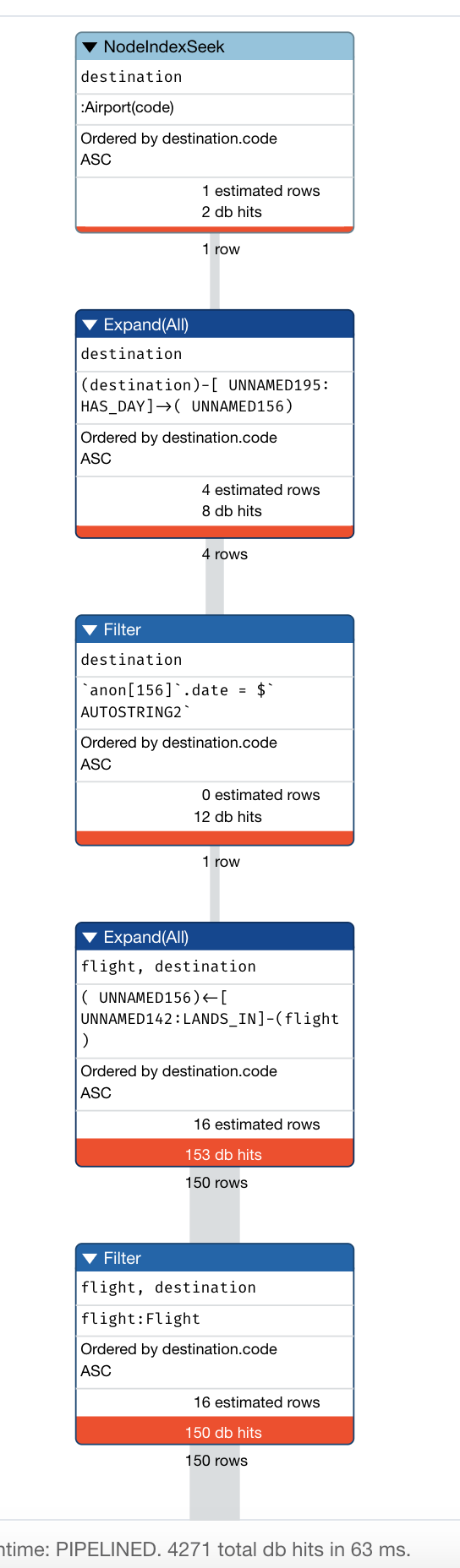
Here we see that the query has 4271 db hits, which is better than the 5532 we had earlier before the refactor. As the number of nodes and relationships grows in the graph, these performance differences will be significant.
What we have learned is that we have to change the model and the query.
Exercise 5: Creating the AirportDay node from the Airport and Flight nodes
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-neo4j-modeling-exercises
and follow the instructions for Exercise 5.
| This exercise has 7 steps. Estimated time to complete: 30 minutes. |
More questions for the model?
We now have a model that performs well for these questions:
-
What are the airports and flight information for flight number xx for airline yy?
-
Find all the flights going from xx to yy on the date zz.
What if we added this question: Which airport has the most incoming flights?
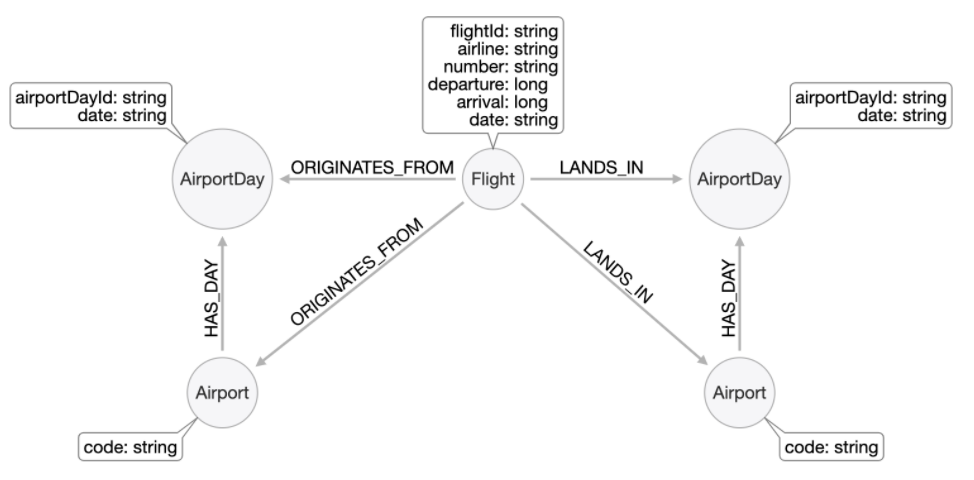
Our latest model serves our two questions very well. However, it does not do a good job with the new question. That is, we must leave the ORIGINATES_FROM and LANDS_IN relationships between Airport and Flight nodes in the graph. In this case, we leave both models in place, and use each one for the questions it is suited to.
Another question for the model
Suppose we added this question: What are the flights from LAS that arrive at MDW on 2019-1-3?
To answer this question with the current model our query would be:
PROFILE
MATCH (origin:Airport {code: 'LAS'})-[:HAS_DAY]->
(originDay:AirportDay),
(originDay)<-[:ORIGINATES_FROM]-(flight:Flight),
(flight)-[:LANDS_IN]->(destinationDay),
(destinationDay:AirportDay)<-[:HAS_DAY]-
(destination:Airport {code: 'MDW'})
WHERE originDay.date = '2019-1-3' AND
destinationDay.date = '2019-1-3'
RETURN flight.date, flight.number, flight.airline,
flight.departure, flight.arrival
ORDER BY flight.date, flight.departure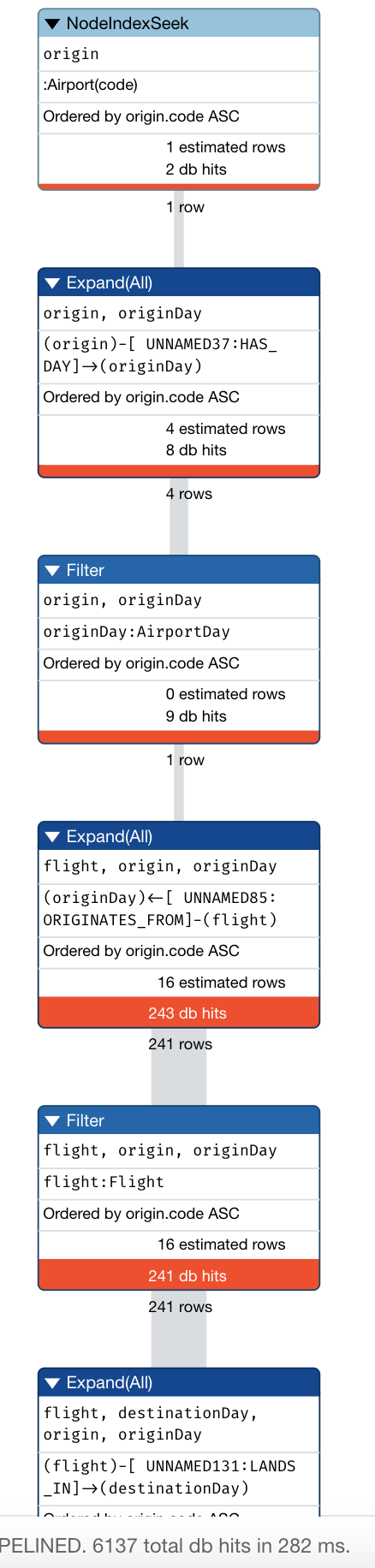
This query requires 6137 db hits with our current graph. It needs to traverse all the HAS_DAY relationships between the Airport and AirportDay nodes found.
Neo4j is optimized for searching by relationship types. As we add more data, the number of HAS_DAY relationships that we have to traverse increases.
If we have 10 years worth of data we have to traverse 3,650 relationships from the Airport to find the AirportDay that we are interested in.
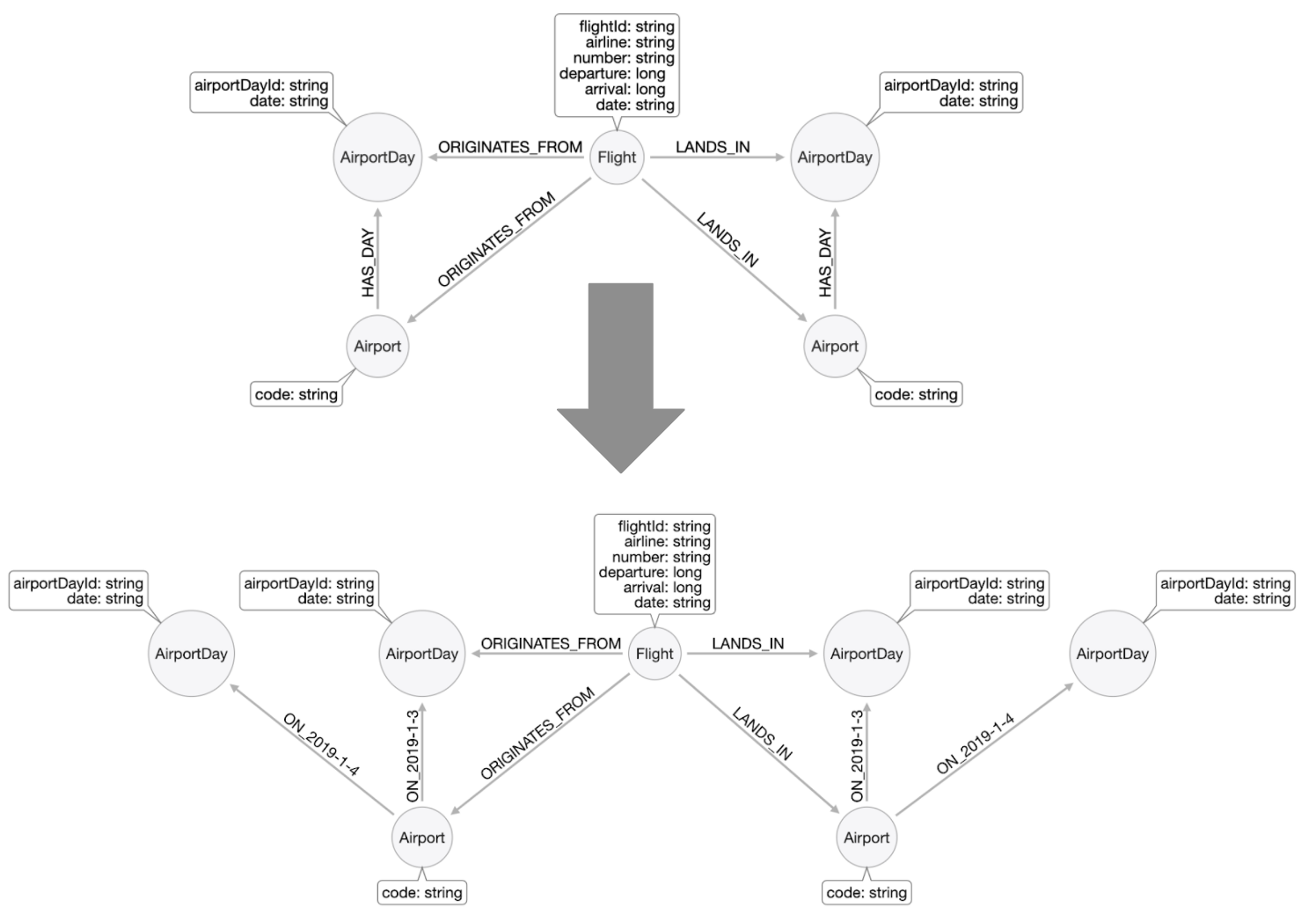
Refactoring for specific relationships
A best practice for graph data modeling is to make relationships more specific if that will help with query performance. Here we can modify the HAS_DAY relationship to be ON_2019-1-3, ON_2019_104, etc.
APOC to the rescue!
With APOC, you can create relationships based upon data in the graph.
Here is the syntax:
apoc.create.relationship(startNode(<relationship-variable>),
'<new-relationship-value>',
{<relationship-property list},
endNode(<relationship-variable>)
)
YIELD relGiven a relationship variable between two existing nodes, this procedure enables you to create a new, custom relationship that could be based upon property values. Calling this procedure where rel is returned enables you to either return the new relationship created or return a count of the number of relationships created in the graph.
Creating specialized relationships with APOC
Here is the code to transform the HAS_DAY relationships to specific relationships:
MATCH (origin:Airport)-[hasDay:HAS_DAY]->(ad:AirportDay)
CALL apoc.create.relationship(startNode(hasDay),
'ON_' + ad.date,
{},
endNode(hasDay) ) YIELD rel
RETURN COUNT(*)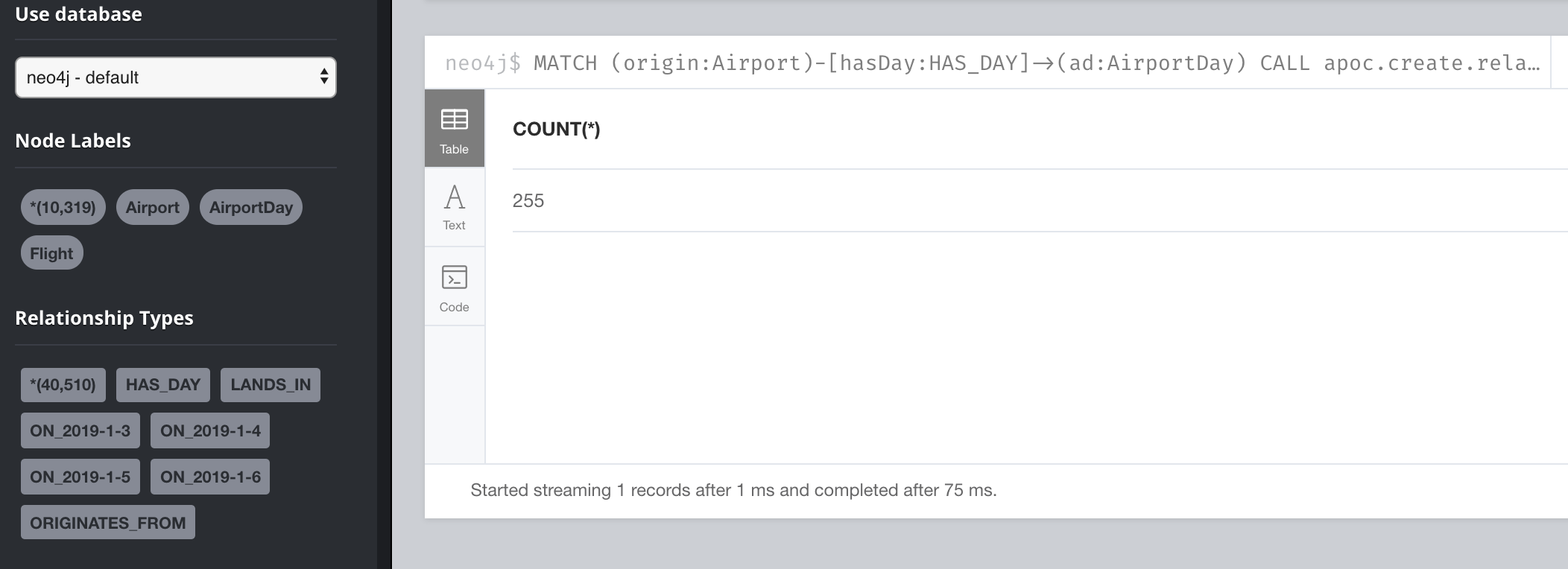
Does the query improve?
Since the model has changed, we need to rewrite the query:
PROFILE
MATCH (origin:Airport {code: 'LAS'})-[:`ON_2019-1-3`]->
(originDay:AirportDay),
(originDay)<-[:ORIGINATES_FROM]-(flight:Flight),
(flight)-[:LANDS_IN]->(destinationDay),
(destinationDay:AirportDay)<-[:`ON_2019-1-3`]
-(destination:Airport {code: 'MDW'})
RETURN flight.date, flight.number, flight.airline,
flight.departure, flight.arrival
ORDER BY flight.date, flight.departure
This query required 4108 db hits, where previously, it required 6137 hits. You can imagine that a fully-loaded graph with years of data could be vastly improved with this type of refactoring.
Of course, you must do due diligence and ensure that all of the previous queries still perform well.
Exercise 6: Creating specific relationships
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-neo4j-modeling-exercises
and follow the instructions for Exercise 6.
| This exercise has 2 steps. Estimated time to complete: 15 minutes. |
Refactoring large graphs
Suppose you scale the test data in your graph, or you have a large production graph and a new question must be added that requires a change to the model. Refactoring a large graph has its challenges due to the amount of memory required to perform the refactor.
Cypher keeps all transaction state in memory while running a query, which is fine most of the time.
When refactoring the graph, however, this state can get very large and may result in an OutOfMemory exception.
You must adapt your heap size to match, or operate in batches. For example increase these values for the server in the neo4j.conf file:
-
dbms.memory.heap.initial_size=2G (default is 512m)
-
dbms.memory.heap.max_size=2G (default is 1G)
Batching the refactoring process
Here is one way that you can control how much work is done for a refactoring:
-
Tag all the nodes we need to process with a temporary label (for example Process).
MATCH (f:Flight)
SET f:Process-
Iterate over a subset of nodes flagged with the temporary label (using
LIMIT):-
Execute the refactoring code.
-
Remove the temporary label from the nodes.
-
Return a count of how many rows were processed in the iteration.
-
-
Once the count reaches 0, then the refactoring is finished.
Example code for a batch
Here is code that will process all nodes with the label Process:
MATCH (flight:Process)
WITH flight LIMIT 500
MATCH (origin:Airport)<-[:ORIGINATES_FROM]-(flight)-[:LANDS_IN]->(destination:Airport)
MERGE (originAirportDay:AirportDay {airportDayId: origin.code + "_" + flight.date})
ON CREATE SET originAirportDay.date = flight.date
MERGE (destinationAirportDay:AirportDay {airportDayId: destination.code + "_" + flight.date})
ON CREATE SET destinationAirportDay.date = flight.date
MERGE (origin)-[:HAS_DAY]->(originAirportDay)
MERGE (originAirportDay)<-[:ORIGINATES_FROM]-(flight)
MERGE (flight)-[:LANDS_IN]->(destinationAirportDay)
MERGE (destination)-[:HAS_DAY]->(destinationAirportDay)
REMOVE flight:Process
RETURN count(*)You have previously used this refactoring code to create the AirportDay nodes and their relationships to Airport and Flight nodes.
This is a variation of the code we executed previously to create the AirportDay nodes from Flight nodes. The highlighted areas will be part of the iteration where we do batches of 500 flights at a time and once the creation of the AirportDay node is completed, we remove the Process label from the Flight node.
Batching with APOC
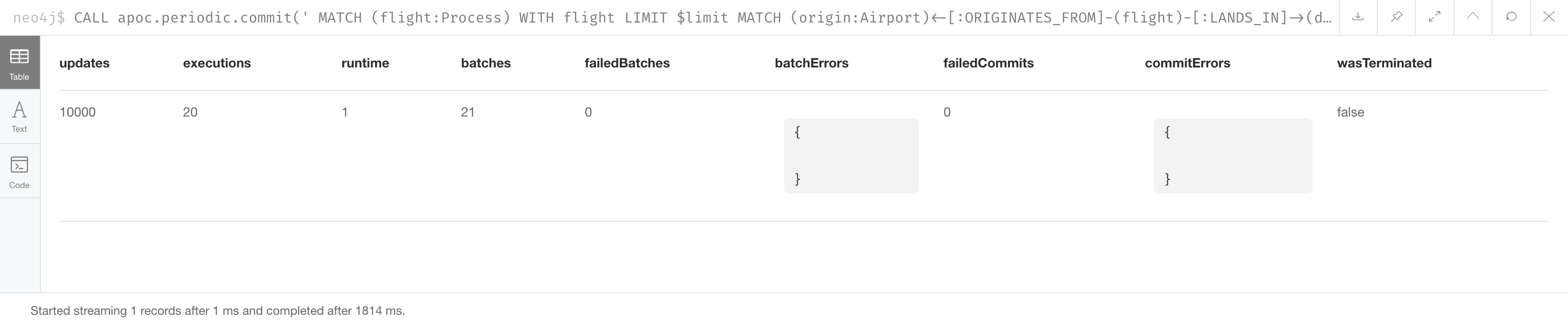
CALL apoc.periodic.commit('
MATCH (flight:Process)
WITH flight LIMIT $limit
MATCH (origin:Airport)<-[:ORIGINATES_FROM]-(flight)-[:LANDS_IN]->(destination:Airport)
MERGE (originAirportDay:AirportDay {airportDayId: origin.code + "_" + flight.date})
ON CREATE SET originAirportDay.date = flight.date
MERGE (destinationAirportDay:AirportDay {airportDayId: destination.code + "_" + flight.date})
ON CREATE SET destinationAirportDay.date = flight.date
MERGE (origin)-[:HAS_DAY]->(originAirportDay)
MERGE (originAirportDay)<-[:ORIGINATES_FROM]-(flight)
MERGE (flight)-[:LANDS_IN]->(destinationAirportDay)
MERGE (destination)-[:HAS_DAY]->(destinationAirportDay)
REMOVE flight:Process
RETURN count(*)
',{limit:500}
)Here we include the refactoring code for creating the AirportDay nodes/relationships in our call to apoc.periodic.commit() where we specify that the refactoring code will create 500 AirportDay nodes in a single transaction.
Exercise 7: Refactoring large graphs
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-neo4j-modeling-exercises
and follow the instructions for Exercise 7.
| This exercise has 8 steps. Estimated time to complete: 30 minutes. |
Check your understanding
Question 1
Suppose you want to create Person nodes in the graph, each with a unique value for the personID property . What must you do to ensure that nodes are unique?
Select the correct answers.
-
Test the existence of the Person node with the personID property value before you use
CREATEto create it. -
Create an existence constraint for the personID property of the Person node.
-
Use
MERGEto create the Person node with a unique property value specified for personID. -
Create a uniqueness constraint for the personID property of the Person node.
Summary
You can now:
-
Create constraints that help with performance of node creation and queries.
-
Determine if a query can be improved.
-
Write Cypher code to refactor the data model in the graph.
-
Create indexes that will help with query performance.
-
Refactor a graph by creating intermediate nodes.
-
Refactor a graph by specializing relationships.
-
Perform batch processing to refactor a large graph.
Need help? Ask in the Neo4j Community