Introduction to Cypher
About this module
Cypher is the query language you use to retrieve data from the Neo4j Database, as well as create and update the data.
At the end of this module, you will write Cypher statements to:
-
Retrieve nodes from the graph.
-
Filter nodes retrieved using labels and property values of nodes.
-
Retrieve property values from nodes in the graph.
-
Filter nodes retrieved using relationships.
Throughout this training, you can refer to:
What is Cypher?
Cypher is a declarative query language that allows for expressive and efficient querying and updating of graph data. Cypher is a relatively simple and very powerful language. Complex database queries can easily be expressed through Cypher, allowing you to focus on your domain instead of getting lost in the syntax of database access.
Cypher is designed to be a human-friendly query language, suitable for both developers and other professionals. The guiding goal is to make the simple things easy, and the complex things possible.
Cypher is ASCII art
Optimized for being read by humans, Cypher’s construct uses English prose and iconography (called ASCII Art) to make queries more self-explanatory.
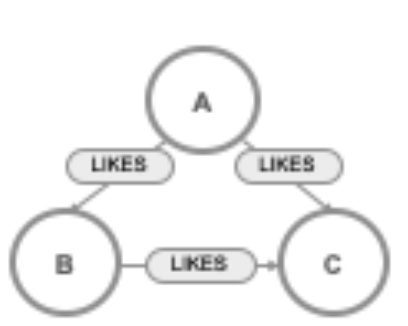
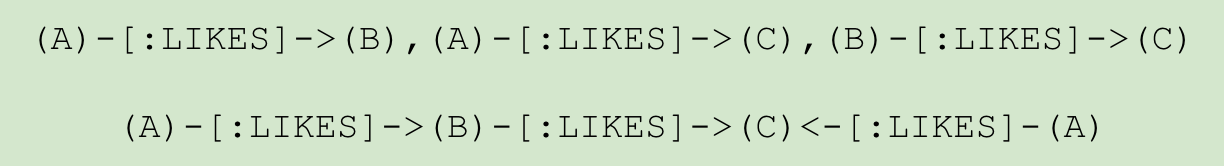
Cypher expresses what to retrieve, not how to retrieve it
Being a declarative language, Cypher focuses on the clarity of expressing what to retrieve from a graph, not on how to retrieve it. You can think of Cypher as mapping English language sentence structure to patterns in a graph. For example, the nouns are nodes of the graph, the verbs are the relationships in the graph, and the adjectives and adverbs are the properties.
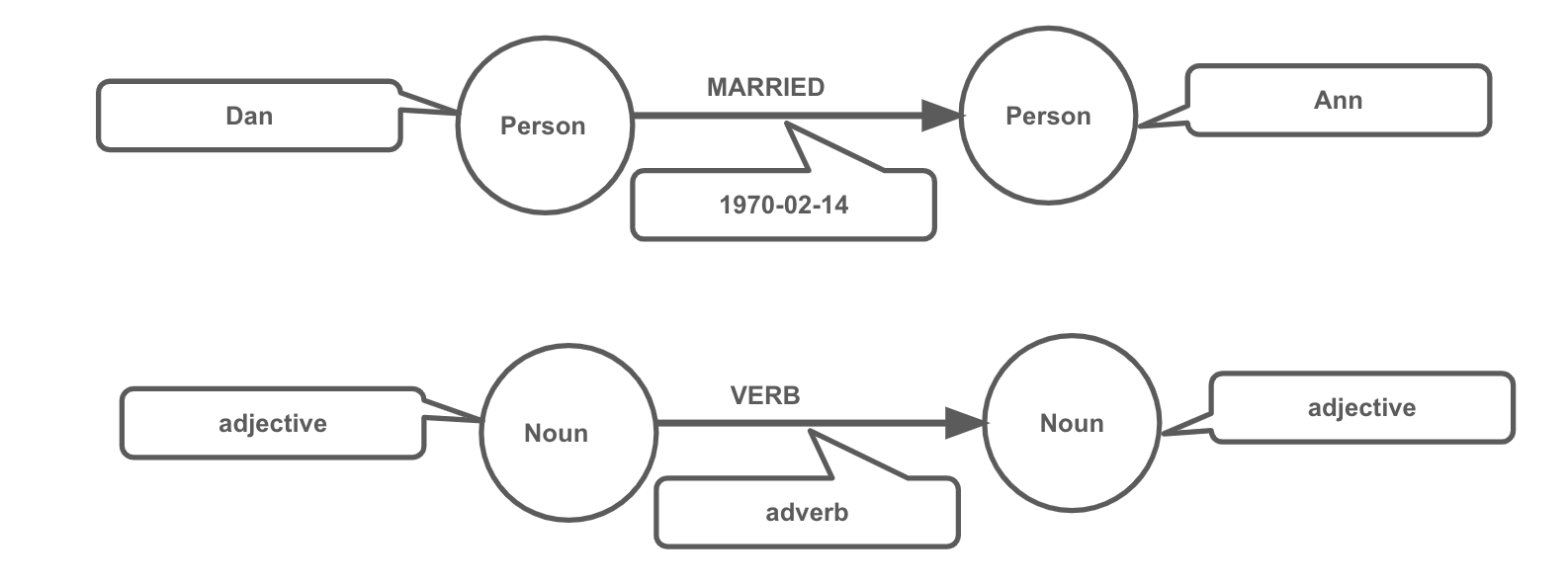
This is in contrast to imperative, programmatic APIs for database access. This approach makes query optimization an implementation detail instead of a burden on the developer, removing the requirement to update all traversals just because the physical database structure has changed.
Cypher is inspired by a number of different approaches and builds upon established practices for expressive querying.
Many of the Cypher keywords like WHERE and ORDER BY are inspired by SQL.
The pattern matching functionality of Cypher borrows concepts from SPARQL.
And some of the collection semantics have been borrowed from languages such as Haskell and Python.
The Cypher language has been made available to anyone to implement and use via openCypher (opencypher.org), allowing any database vendor, researcher or other interested party to reap the benefits of our years of effort and experience in developing a first class graph query language.
Node syntax
Cypher uses a pair of parentheses like (), (n) to represent a node, much like a circle on a whiteboard.
Here is the simplified syntax for specifying a node:
()
(<variable>)Notice that a node must have the parentheses.
When you specify (n) for a node, you are telling the query processor that for this query, use the variable n to represent nodes that will be processed later in the query for further query processing or for returning values from the query.
If you do not need to do anything with the node, you can skip the use of the variable.
This is called an anonymous node.
Recall that a node typically represents an entity in your domain.
Label syntax
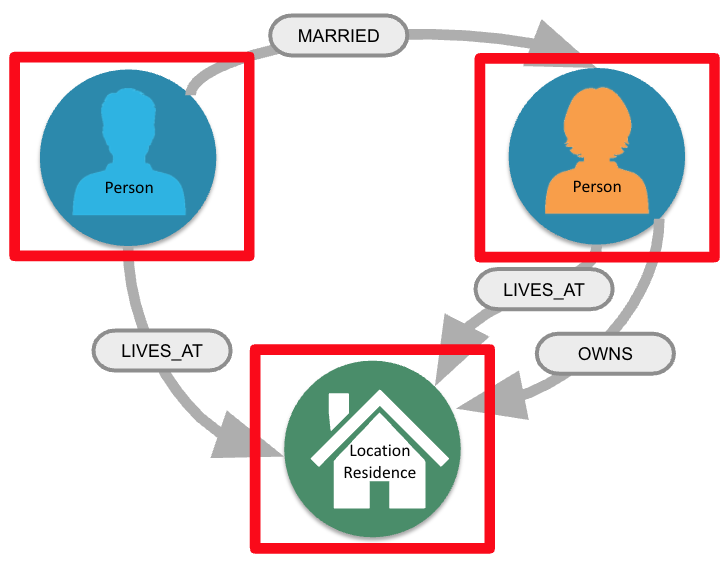
Nodes in a graph are typically labeled. Labels are used to group nodes and filter queries against the graph. That is, labels can be used to optimize queries.
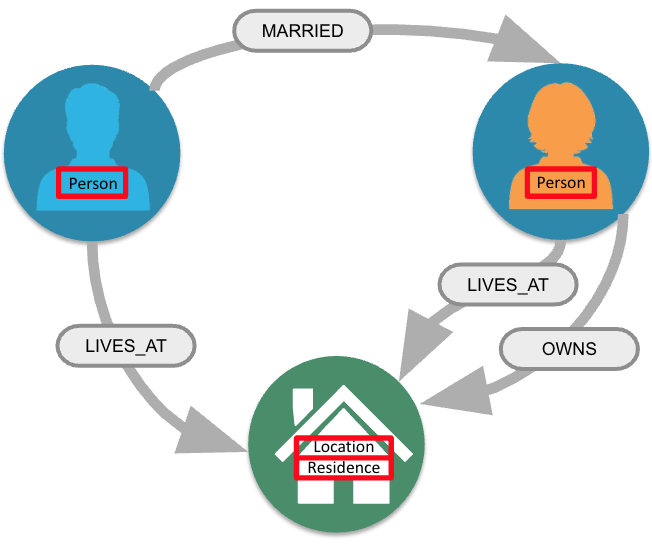
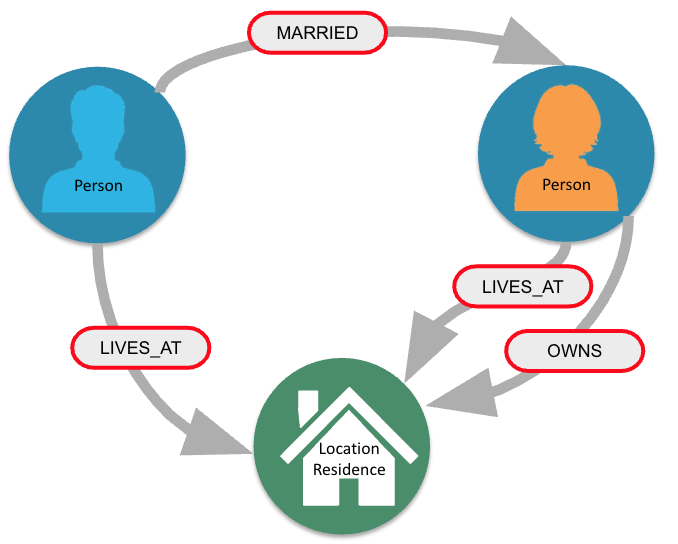
In this example, the node labels are Person, Location, and Residence.
Here are examples for specifying nodes with labels using the the above image:
(:Person)
(p:Person)
(:Location)
(l:Location)
(x:Residence)
(x:Location:Residence)Here we see nodes with variables and also anonymous nodes without variables. A node can be retrieved using one or more Labels.
In the Movie database you will be working with in this course, the nodes in this graph are labeled Movie or Person to represent two types of nodes.
Comments in Cypher
In Cypher, you can place a comment (starts with //) anywhere in your Cypher to specify that the rest of the line is interpreted as a comment.
// anonymous node not be referenced later in the query
()
// variable p, a reference to a node used later
(p)
// anonymous node of type Person
(:Person)
// p, a reference to a node of type Person
(p:Person)
// p, a reference to a node of types Actor and Director
(p:Actor:Director)Examining the data model
When you are first learning about the data (nodes, labels, etc.) in a graph, it is helpful to examine the data model of the graph.
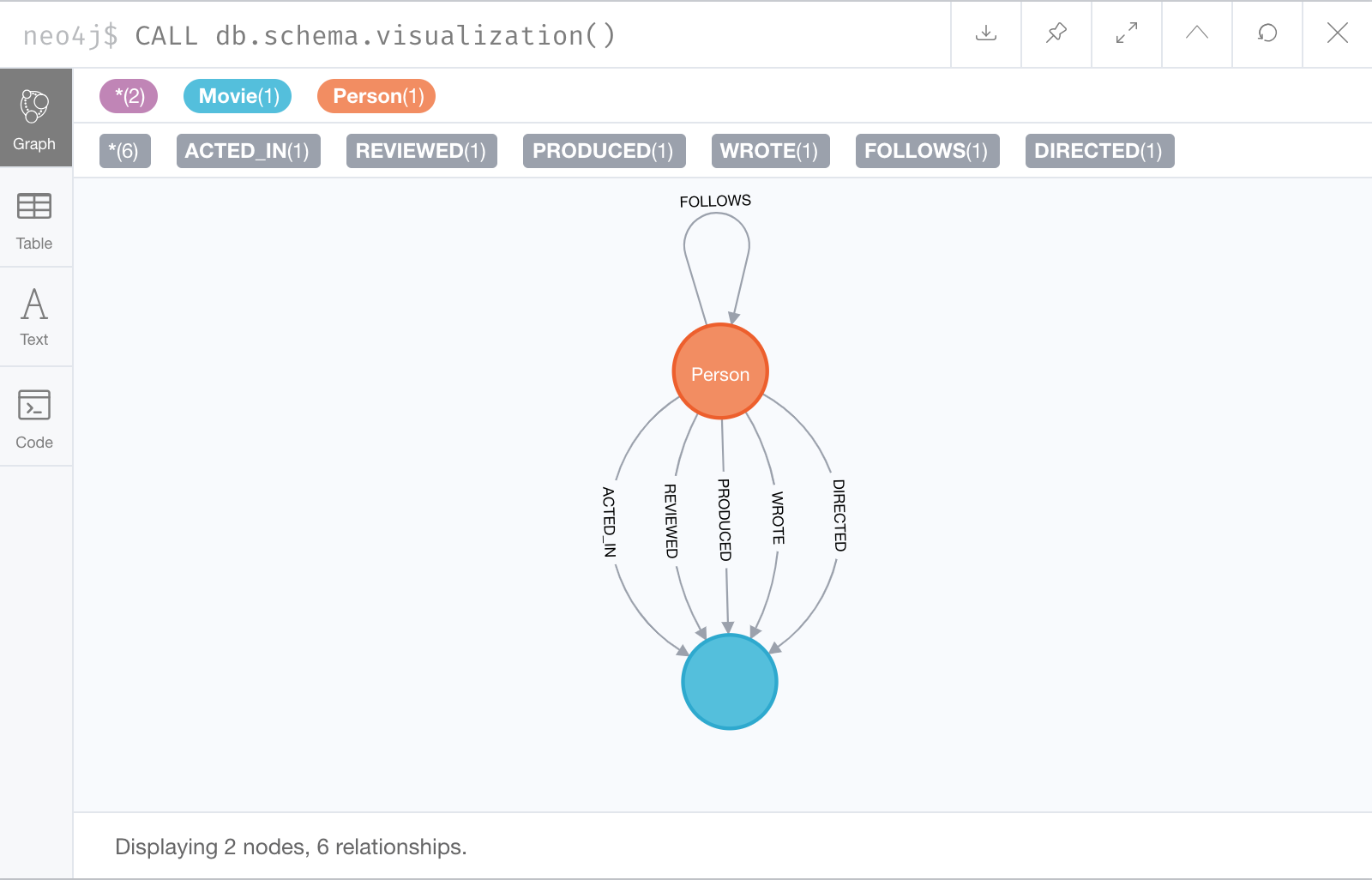
You do so by executing CALL db.schema.visualization(), which calls the Neo4j procedure that returns information about the nodes, labels, and relationships in the graph.
For example, when we run this procedure in our training environment, we see the following in the result pane. Here we see that the graph has 2 labels defined for nodes, Person and Movie. Each type of node is displayed in a different color. The relationships between nodes are also displayed, which you will learn about later in this module.
Syntax: Using MATCH and RETURN
The most widely used Cypher clause is MATCH.
The MATCH clause performs a pattern match against the data in the graph.
During the query processing, the graph engine traverses the graph to find all nodes that match the graph pattern.
As part of query, you can return nodes or data from the nodes using the RETURN clause.
The RETURN clause must be the last clause of a query to the graph.
In the course, Creating Nodes and Relationships in Neo4j 4.x, you will learn how to use MATCH to select nodes and data for updating the graph.
First, you will learn how to simply return nodes.
Syntax examples for a query:
MATCH (variable)
RETURN variableMATCH (variable:Label)
RETURN variableNotice that the Cypher keywords MATCH and RETURN are upper-case.
This coding convention is described in the Cypher Style Guide and will be used in this training.
This MATCH clause returns all nodes in the graph, where the optional Label is used to return a subgraph if the graph contains nodes of different types.
The variable must be specified here, otherwise the query will have nothing to return.
Example: Retrieve all Person nodes
MATCH (p:Person) // returns all Person nodes in the graph
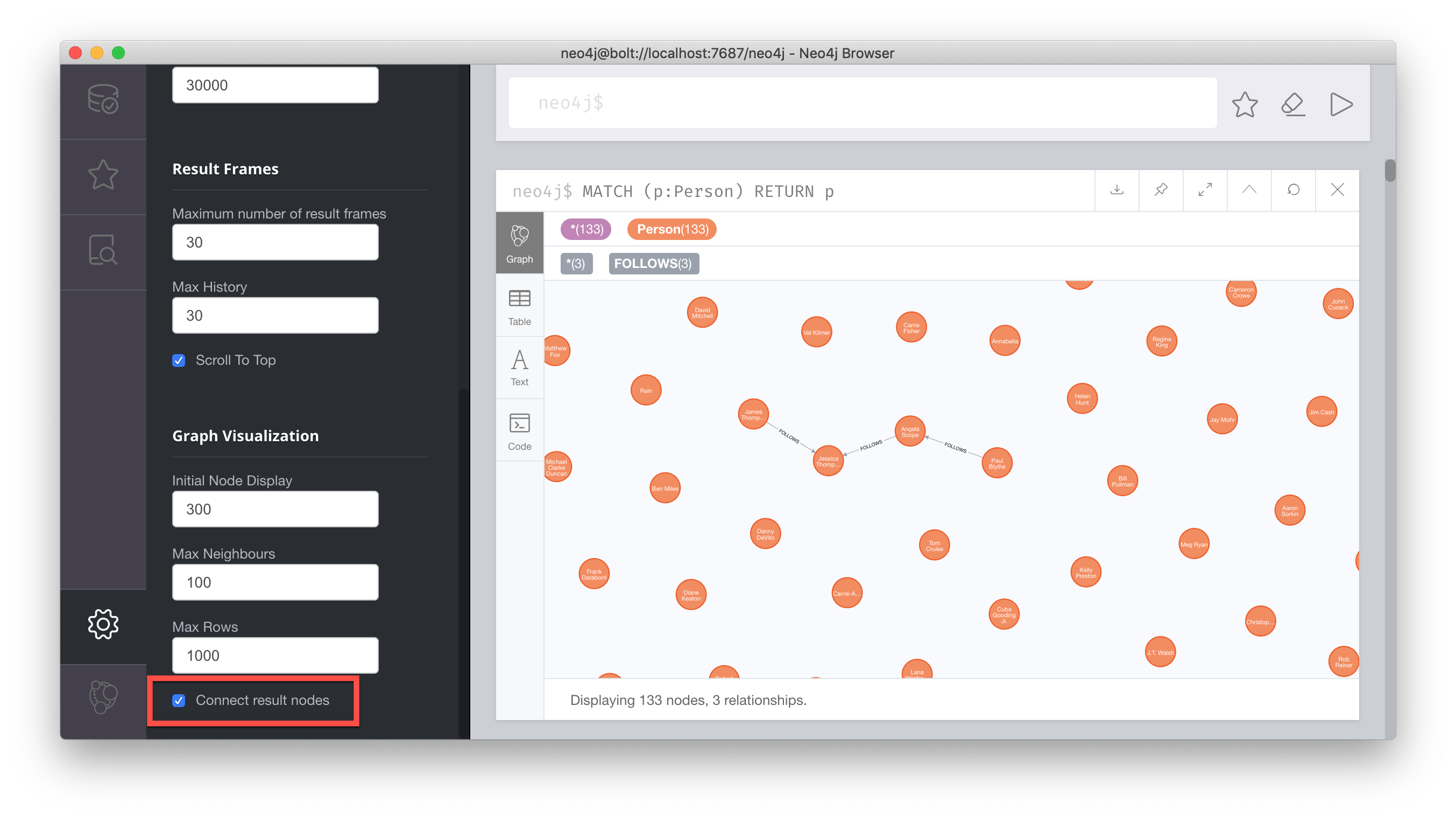
RETURN pWhen we execute the Cypher statement, MATCH (p:Person) RETURN p, the graph engine returns all nodes with the label Person.
The default view of the returned nodes are the nodes that were referenced by the variable p.
The result returned is:
When you specify a pattern for a MATCH clause, always specify a node label if possible. In doing so, the graph engine uses an index to retrieve the nodes which will perform better than not using a label for the MATCH.
|
One thing to notice in this example is that some of the displayed nodes are connected by the FOLLOWS relationship. The visualization shows the relationship between these nodes because we have specified Connect result nodes in our Neo4j Browser settings. Some of the Person nodes represent people who reviewed Movies and as such, they follow each other.
Viewing nodes as table data
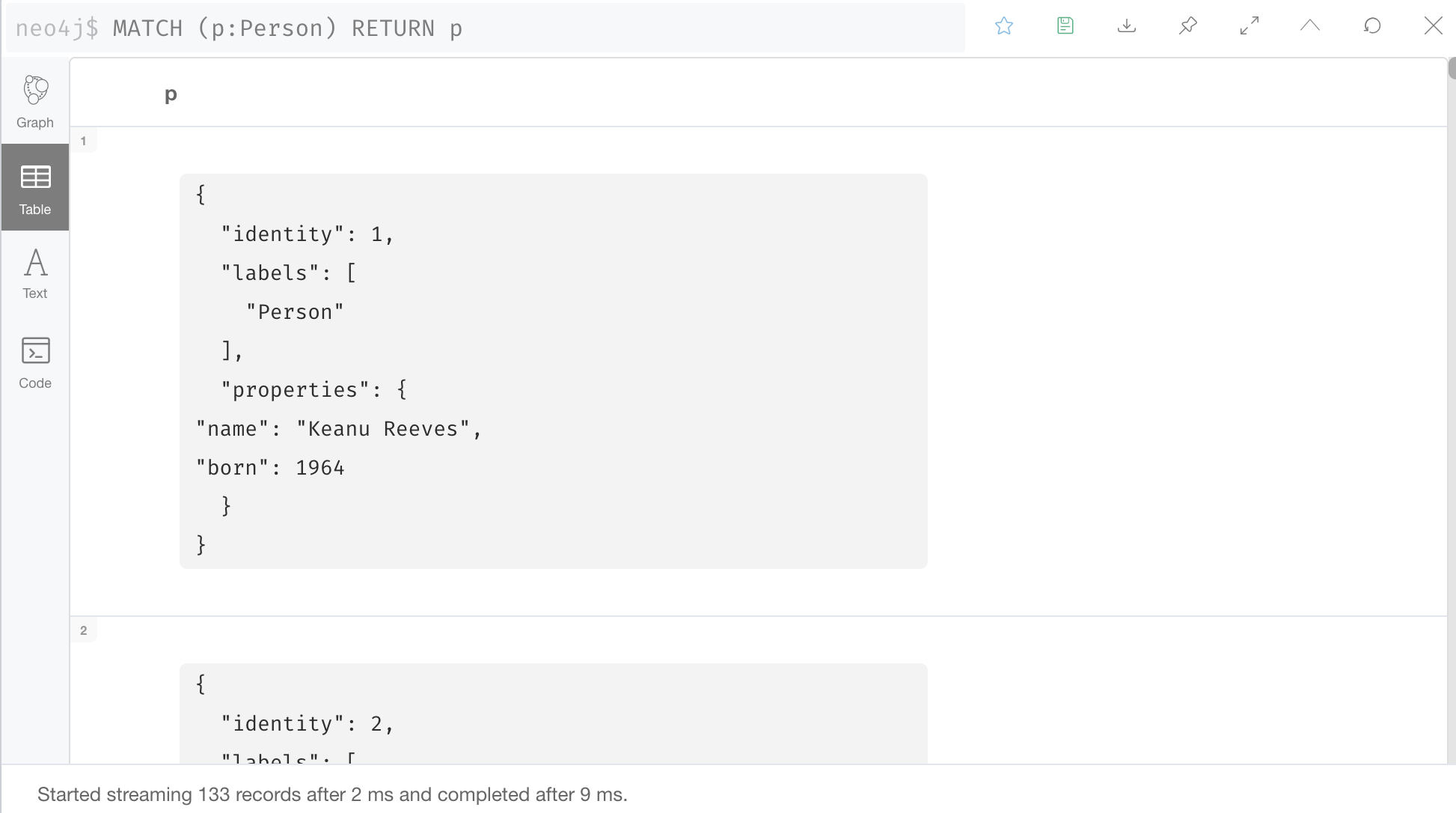
We can also view the nodes as table data where the nodes and their associated property values are shown in a JSON-style format.
When nodes are displayed as table values, the node labels and ids are also shown if you are using version 4.1 or later. Node ids are unique identifiers and are set by the graph engine when a node is created.
Exercise 1: Retrieving nodes
| Prior to performing this exercise, set up your development environment to use one of the following, which is covered in the course, Overview of Neo4j 4.x. |
-
Neo4j Desktop
-
Neo4j Sandbox
-
Neo4j Aura
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 1.
| This exercise has 4 steps. Estimated time to complete: 10 minutes. |
Properties
In Neo4j, a node (and a relationship, which you will learn about later) can have properties that are used to further define a node. A property is identified by its property key. Recall that nodes are used to represent the entities of your business model. A property is defined for a node and not for a type of node. All nodes of the same type need not have the same properties.
For example, in the Movie graph, all Movie nodes have both title and released properties. However, it is not a requirement that every Movie node has a property, tagline.
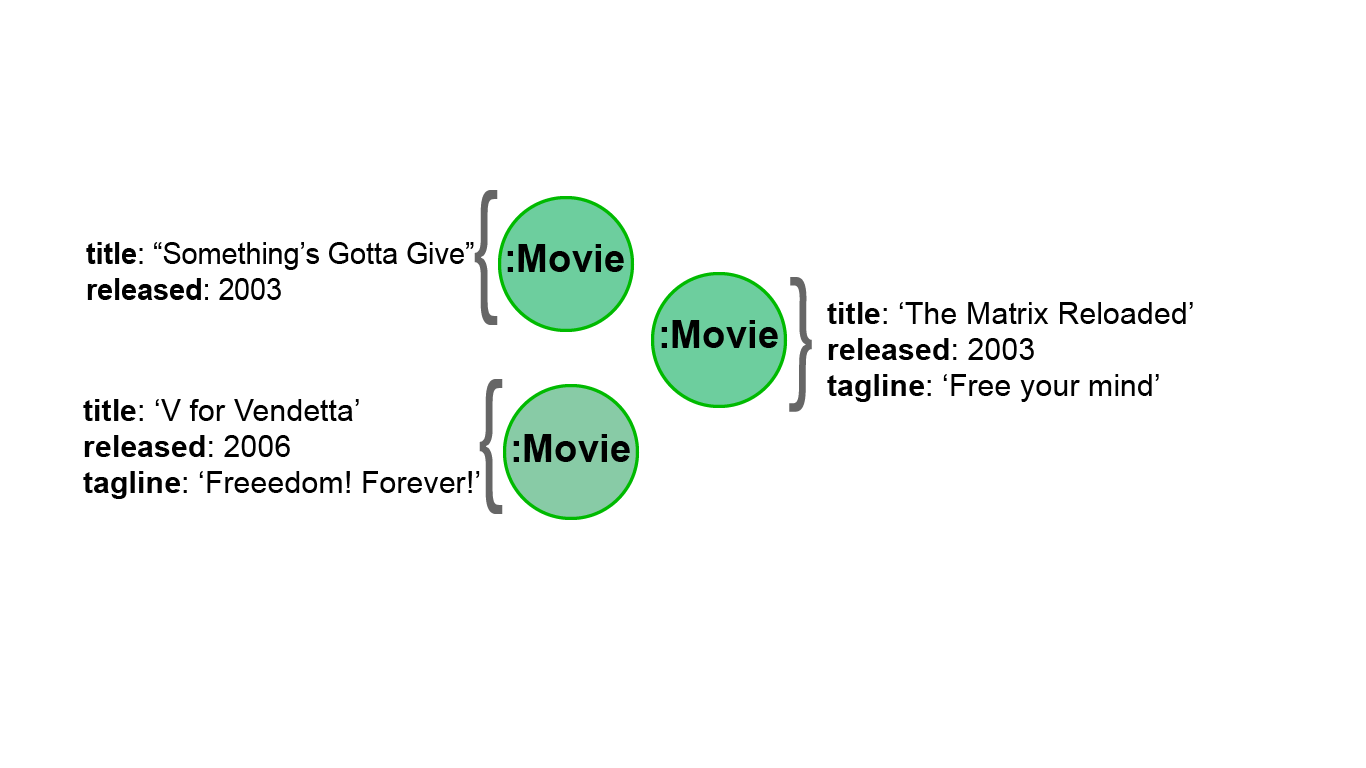
Properties can be used to filter queries so that a subset of the graph is retrieved.
In addition, with the RETURN clause, you can return property values from the retrieved nodes, rather than the nodes.
Examining property keys
As you prepare to create Cypher queries that use property values to filter a query, you can view the values for property keys of a graph by simply clicking the Database icon in Neo4j Browser.
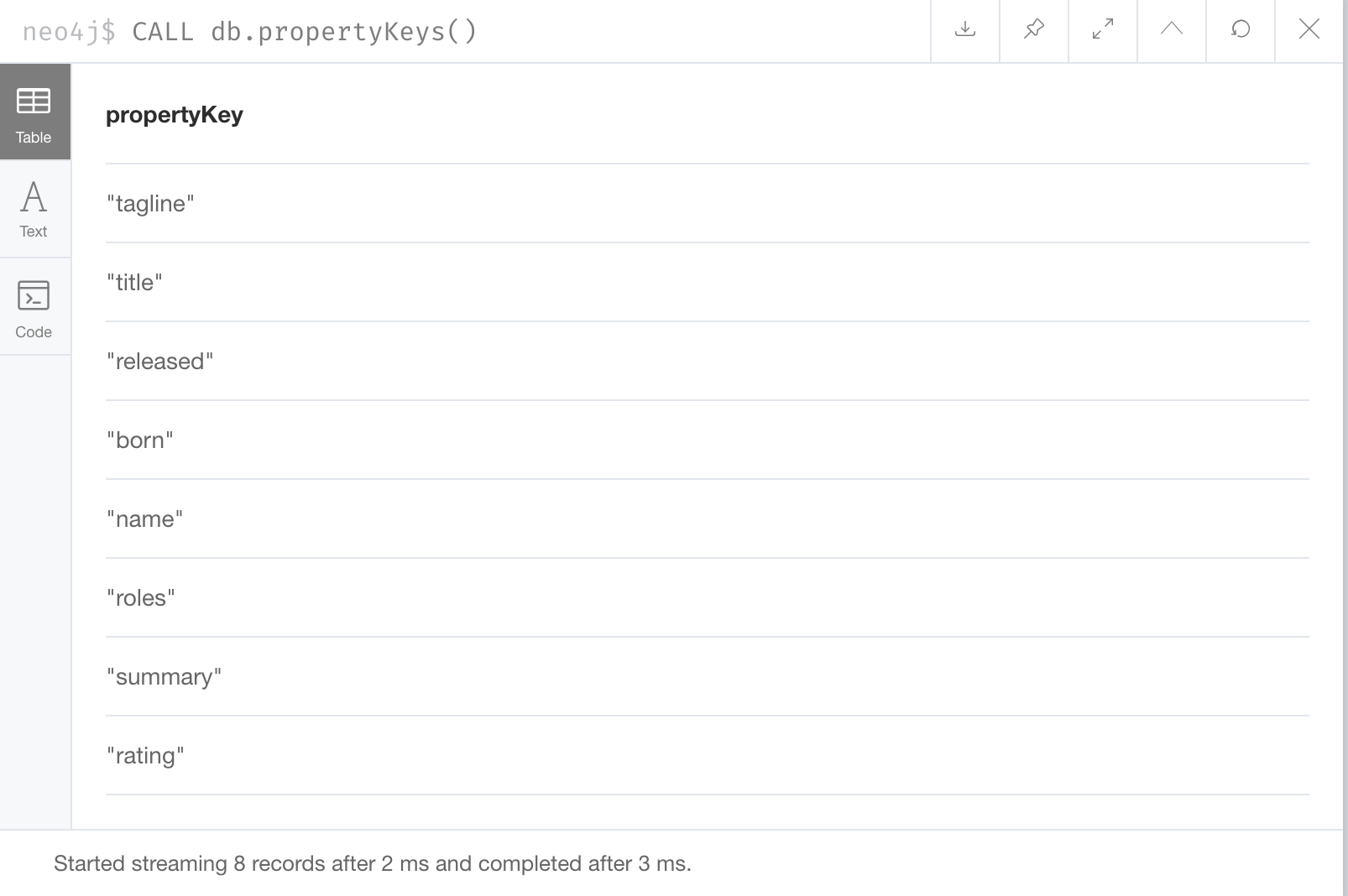
Alternatively, you can execute CALL db.propertyKeys(), which calls the Neo4j library method that returns the property keys for the graph.
Here is what you will see in the result pane when you call the method to return the property keys in the Movie graph. This result stream contains all property keys in the graph. It does not display which nodes utilize these property keys.
Syntax: Retrieving nodes filtered by a property value
You have learned previously that you can filter node retrieval by specifying a label. Another way you can filter a retrieval is to specify a value for a property. Any node that matches the value will be retrieved.
Here are simplified syntax examples for a query where we specify one or more values for properties that will be used to filter the query results and return a subset of the graph:
MATCH (variable {propertyKey: propertyValue})
RETURN variableMATCH (variable:Label {propertyKey: propertyValue})
RETURN variableMATCH (variable {propertyKey1: propertyValue1, propertyKey2: propertyValue2})
RETURN variableMATCH (variable:Label {propertyKey: propertyValue, propertyKey2: propertyValue2})
RETURN variableExample: Filtering query by year born
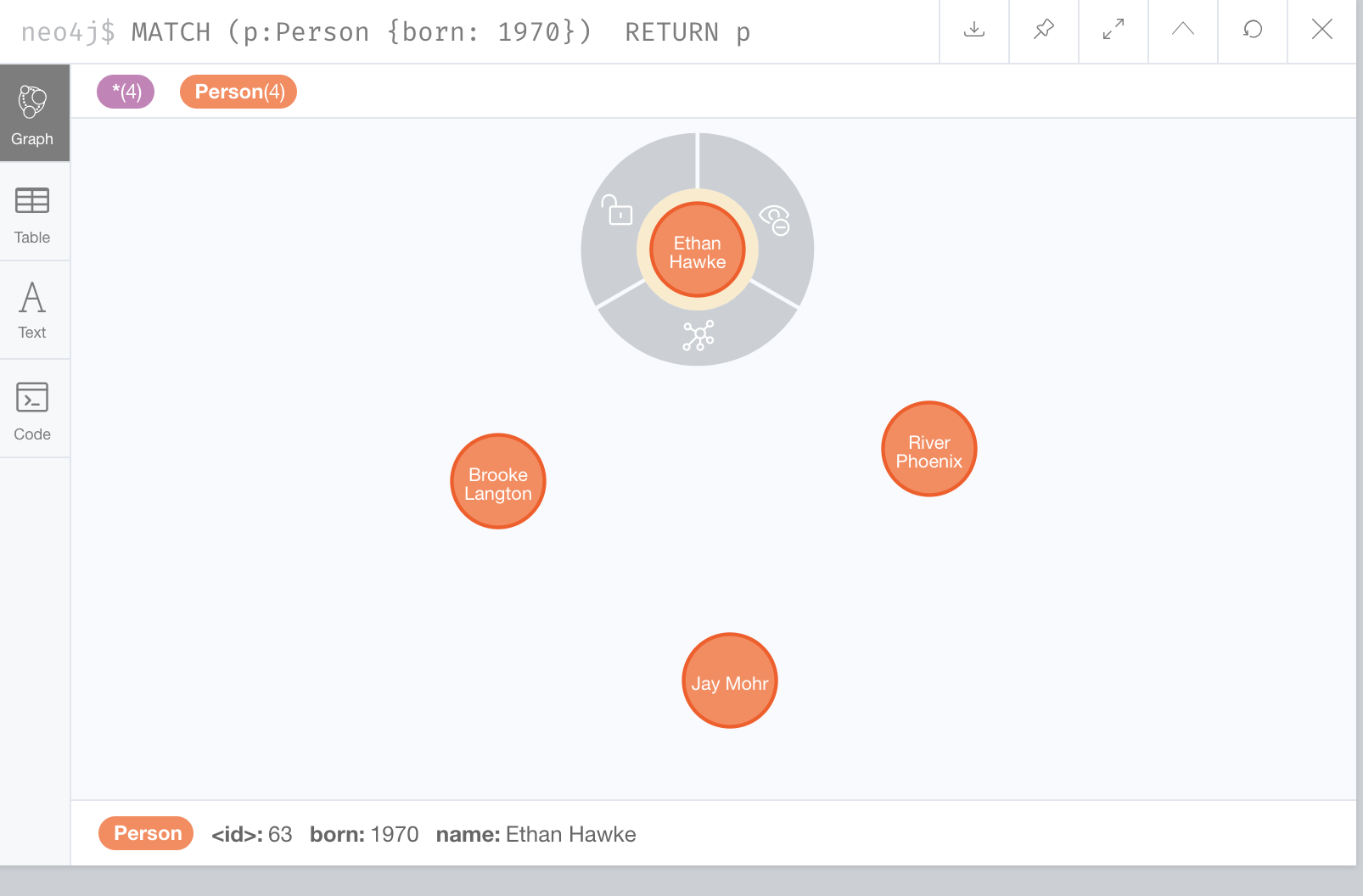
Here is an example where we filter the query results using a property value. We only retrieve Person nodes that have a born property value of 1970.
MATCH (p:Person {born: 1970})
RETURN pThe result returned is:
Example: Filtering query by multiple properties
Here is an example where we specify two property values for the query.
MATCH (m:Movie {released: 2003, tagline: 'Free your mind'})
RETURN mHere is the result returned:
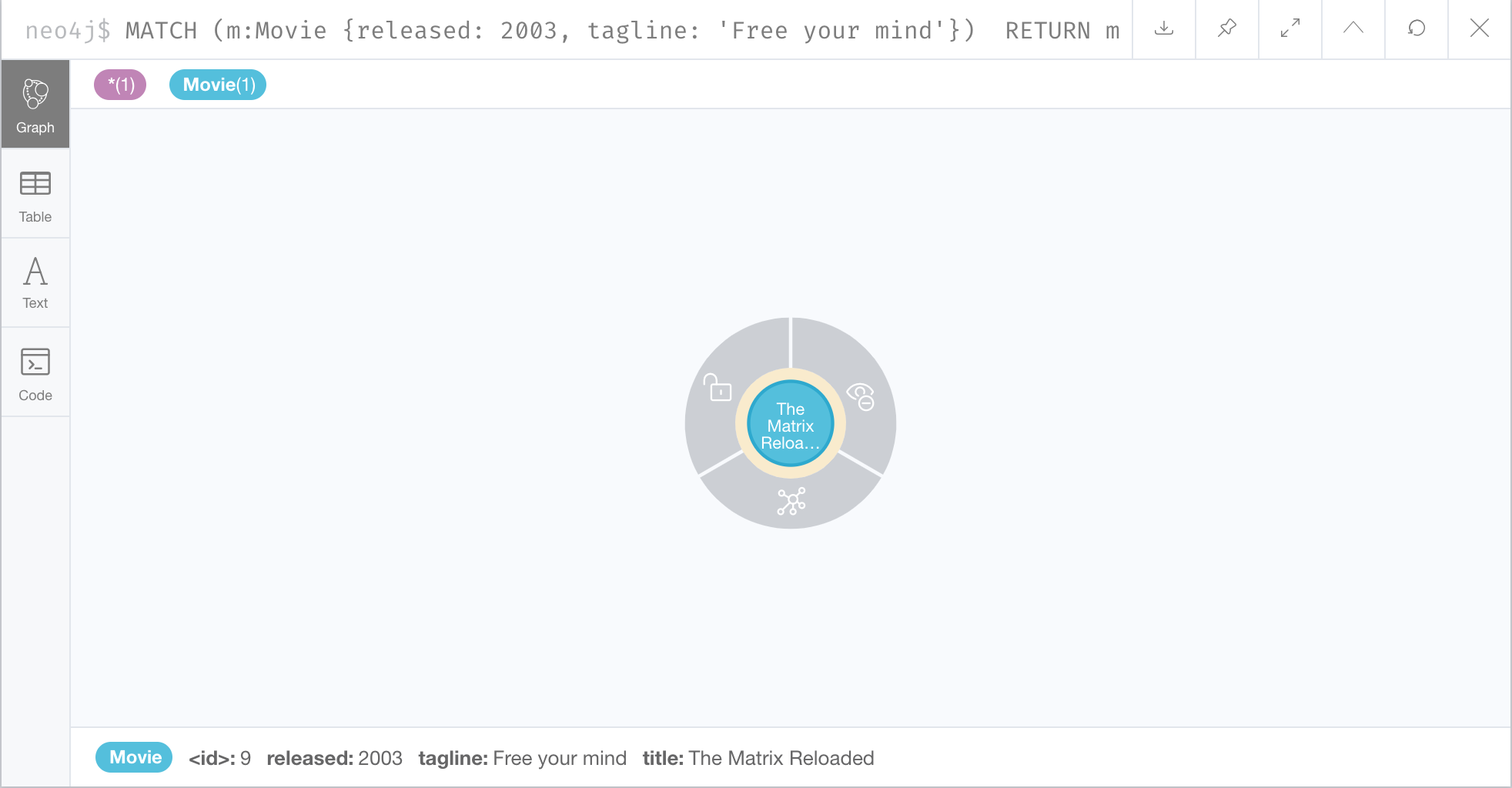
As it turns out, there is only one movie with the tagline, 'Free your mind` in the Movie database. If we had specified a different year, the query would not have returned a value because when you specify properties, both properties must match.
Syntax: Returning property values
Thus far, you have seen how to retrieve nodes and return nodes (entire graph or a subset of the graph).
You can use the RETURN clause to return property values of nodes retrieved.
Here are simplified syntax examples for returning property values, rather than nodes:
MATCH (variable {prop1: value})
RETURN variable.prop2MATCH (variable:Label {prop1: value})
RETURN variable.prop2MATCH (variable:Label {prop1: value, prop2: value})
RETURN variable.prop3MATCH (variable {prop1:value})
RETURN variable.prop2, variable.prop3Example: Returning property values
In this example, we use the born property to filter the query, but rather than returning the nodes, we return the name and born values for every node that satisfies the query.
MATCH (p:Person {born: 1965})
RETURN p.name, p.bornThe result returned is:

Syntax: Specifying aliases for column headings
If you want to customize the headings for a table containing property values, you can specify aliases for column headers.
Here is the simplified syntax for specifying an alias for a property value:
MATCH (variable:Label {propertyKey1: propertyValue1})
RETURN variable.propertyKey2 AS alias2| If you want a heading to contain a space between strings, you must specify the alias with the back tick ` character, rather than a single or double quote character. In fact, you can specify any variable, label, relationship type, or property key with a space also by using the back tick ` character. |

Exercise 2: Filtering queries using property values
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 2.
| This exercise has 6 steps. Estimated time to complete: 15 minutes. |
Relationships
Relationships are what make Neo4j graphs such a powerful tool for connecting complex and deep data. A relationship is a directed connection between two nodes that has a relationship type (name). In addition, a relationship can have properties, just like nodes. In a graph where you want to retrieve nodes, you can use relationships between nodes to filter a query.
ASCII art
Thus far, you have learned how to specify a node in a MATCH clause.
You can specify nodes and their relationships to traverse the graph and quickly find the data of interest.
Here is how Cypher uses ASCII art to specify the path used for a query:
() // a node
()--() // 2 nodes have some type of relationship
()-[]-() // 2 nodes have some type of relationship
()-->() // the first node has a relationship to the second node
()<--() // the second node has a relationship to the first nodeSyntax: Querying using relationships
In your MATCH clause, you specify how you want a relationship to be used to perform the query. The relationship can be specified with or without direction.
Here are simplified syntax examples for retrieving a set of nodes that satisfy one or more directed and typed relationships:
MATCH (node1)-[:REL_TYPE]->(node2)
RETURN node1, node2MATCH (node1)-[:REL_TYPEA | REL_TYPEB]->(node2)
RETURN node1, node2where:
node1 |
is a specification of a node where you may include node labels and property values for filtering. |
REL_TYPE |
is the type (name) for the relationship. For this syntax the relationship is from node1 to node2. |
REL_TYPEA , REL_TYPEB |
are the relationships from node1 to node2. The nodes are returned if at least one of the relationships exists. |
node2 |
is a specification of a node where you may include node labels and property values for filtering. |
Examining relationships
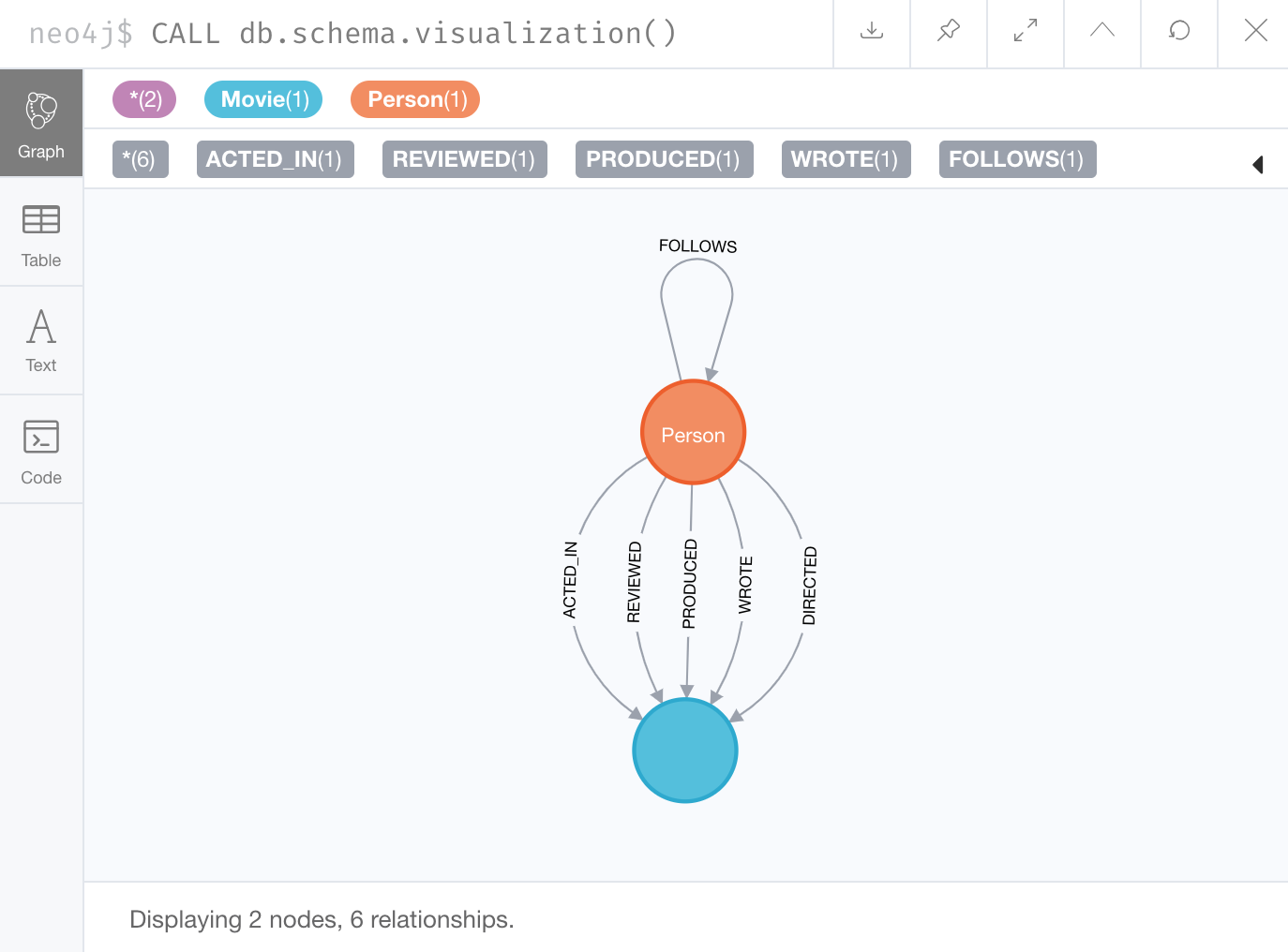
You can run CALL db.schema.visualization() to view the relationship types in the graph.
In the Movie graph, we see these relationships between the nodes.
Here we see that this graph has a total of 6 relationship types between the nodes. Some Person nodes are connected to other Person nodes using the FOLLOWS relationship type. All of the other relationships in this graph are from Person nodes to Movie nodes.
Using a relationship in a query
Here is an example where we retrieve the Person nodes that have the ACTED_IN relationship to the Movie, The Matrix. In other words, show me the actors that acted in The Matrix.
MATCH (p:Person)-[rel:ACTED_IN]->(m:Movie {title: 'The Matrix'})
RETURN p, rel, mThe result returned is:
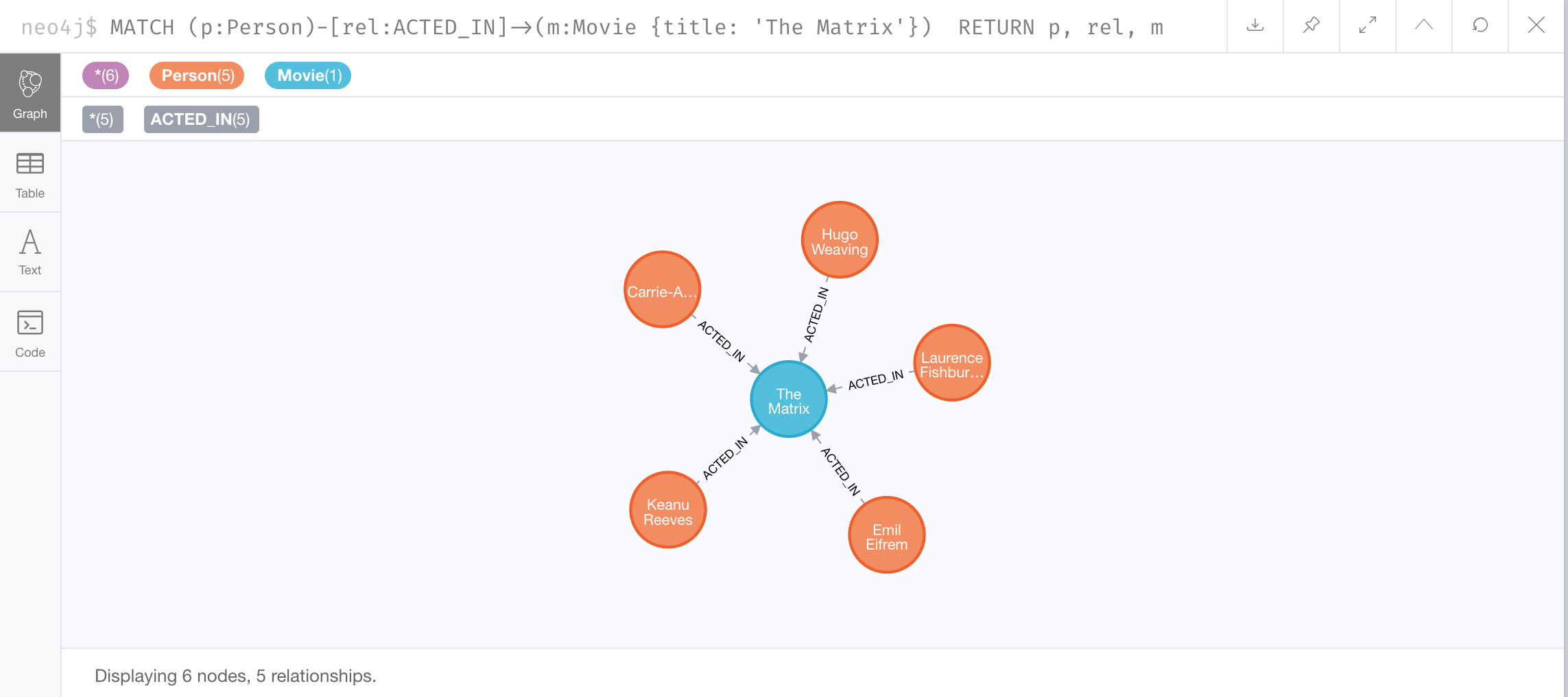
For this query, we are using the variable p to represent the Person nodes during the query, the variable m to represent the Movie node retrieved, and the variable rel to represent the relationship for the relationship type, ACTED_IN. We return a graph with the Person nodes, the Movie node and their ACTED_IN relationships.
Querying by multiple relationships
Here is another example where we want to know the movies that Tom Hanks acted in or directed:
MATCH (p:Person {name: 'Tom Hanks'})-[:ACTED_IN|DIRECTED]->(m:Movie)
RETURN p.name, m.titleThe result returned is:
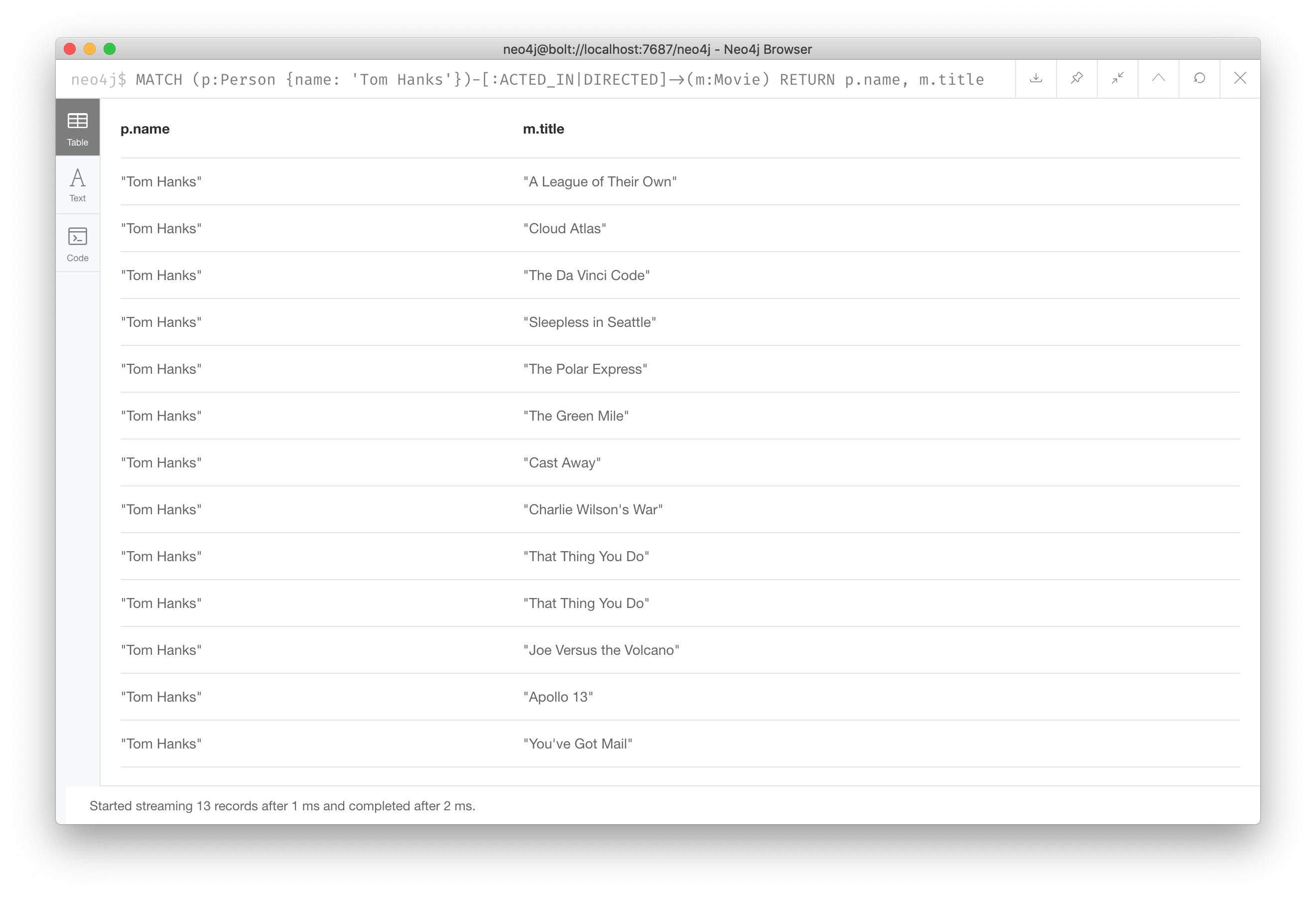
Notice that there are multiple rows returned for the movie, That Thing You Do. This is because Tom Hanks acted in and directed that movie.
Using anonymous nodes in a query
Suppose you wanted to retrieve the actors that acted in The Matrix, but you do not need any information returned about the Movie node. You need not specify a variable for a node in a query if that node is not returned or used for later processing in the query. You can simply use the anonymous node in the query as follows:
MATCH (p:Person)-[:ACTED_IN]->(:Movie {title: 'The Matrix'})
RETURN p.nameThe result returned is:

A best practice is to place named nodes (those with variables) before anonymous nodes in a MATCH clause.
|
Using an anonymous relationship for a query
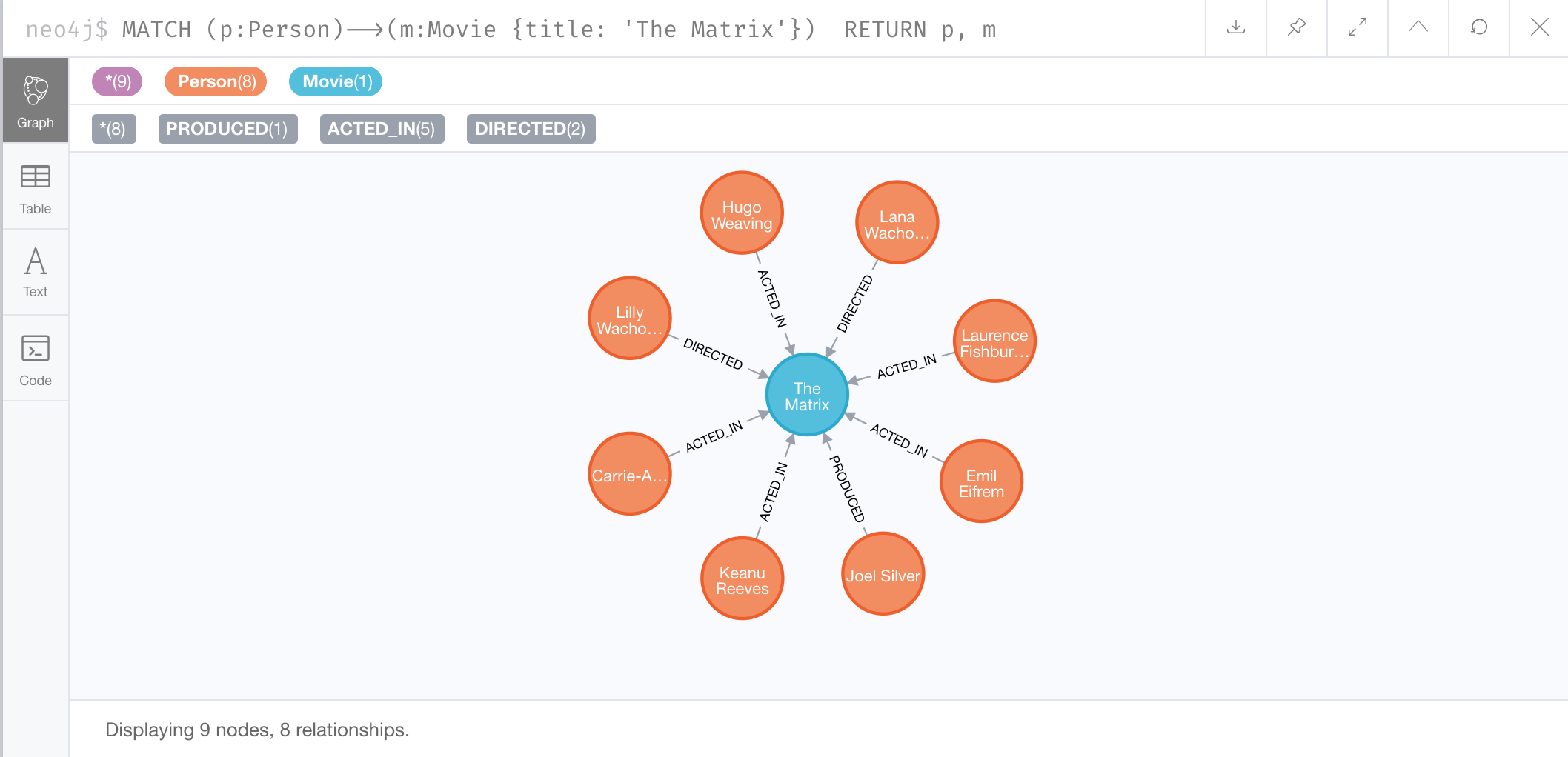
Suppose you want to find all people who are in any way connected to the movie, The Matrix. You can specify an empty relationship type in the query so that all relationships are traversed and the appropriate results are returned. In this example, we want to retrieve all Person nodes that have any type of connection to the Movie node, with the title, The Matrix. This query returns more nodes with the relationships types, DIRECTED, ACTED_IN, and PRODUCED.
MATCH (p:Person)-->(m:Movie {title: 'The Matrix'})
RETURN p, mThe result returned is:
More anonymous relationships
Here are other examples of using the anonymous relationship:
MATCH (p:Person)--(m:Movie {title: 'The Matrix'})
RETURN p, mMATCH (p:Person)-[]-(m:Movie {title: 'The Matrix'})
RETURN p, mMATCH (m:Movie)<--(p:Person {name: 'Keanu Reeves'})
RETURN p, mIn this training, we will use -->, --, and <-- to represent anonymous relationships as it is a Cypher best practice.
Retrieving the relationship types
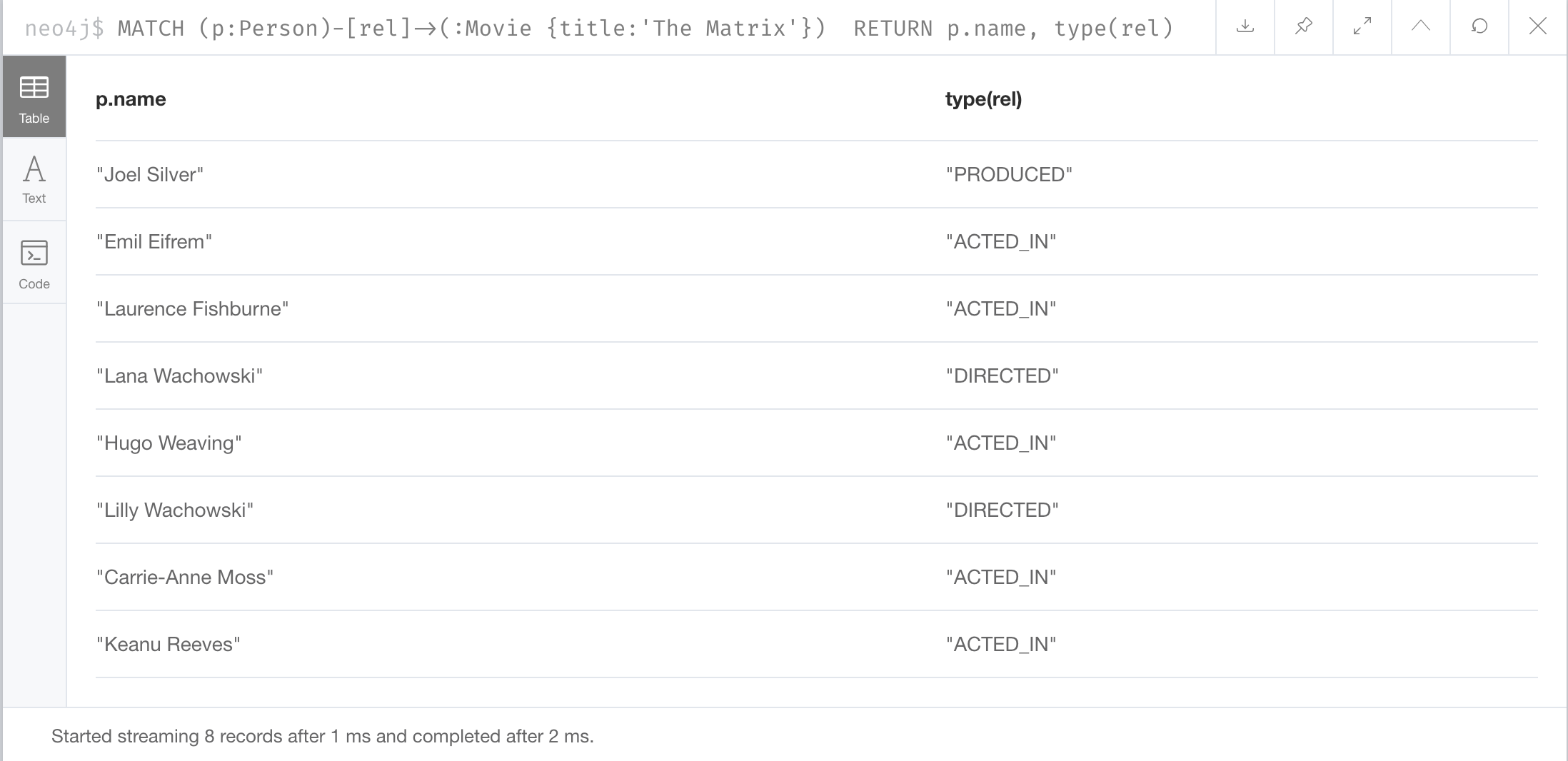
There is a built-in function, type() that returns the type of a relationship.
Here is an example where we use the rel variable to hold the relationships retrieved. We then use this variable to return the relationship types.
MATCH (p:Person)-[rel]->(:Movie {title:'The Matrix'})
RETURN p.name, type(rel)The result returned is:
Properties for relationships
Recall that a node can have a set of properties, each identified by its property key. Relationships can also have properties. This enables your graph model to provide more data about the relationships between the nodes.
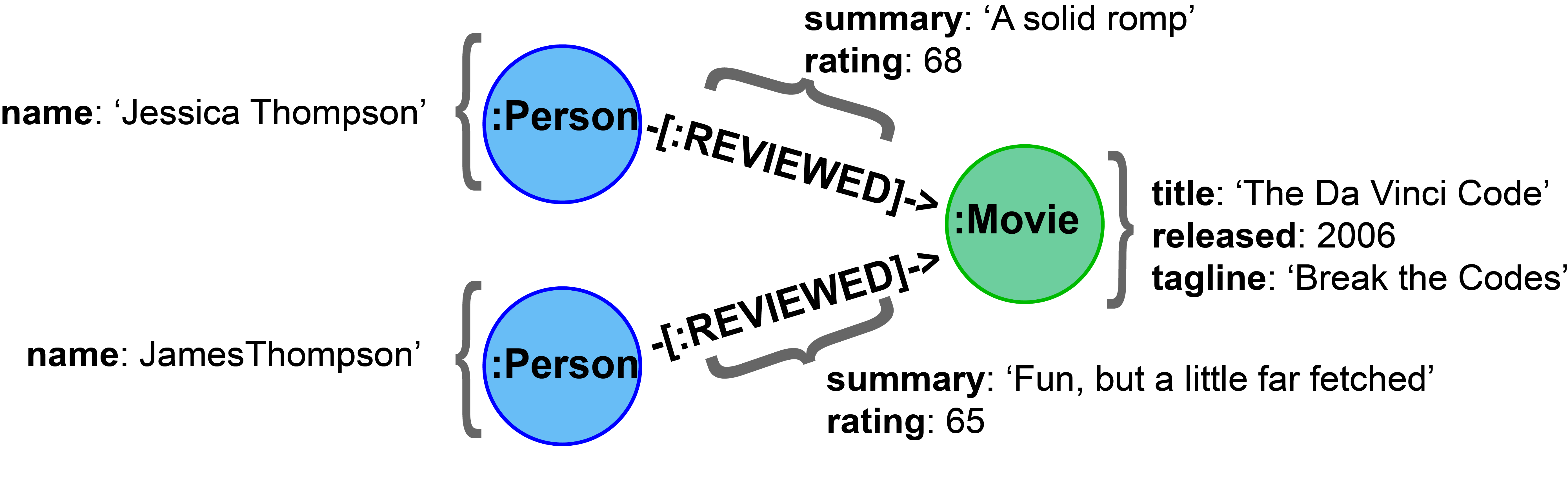
Here is an example from the Movie graph. The movie, The Da Vinci Code has two people that reviewed it, Jessica Thompson and James Thompson. Each of these Person nodes has the REVIEWED relationship to the Movie node for The Da Vinci Code. Each relationship has properties that further describe the relationship using the summary and rating properties.
Filtering using relationship properties
Just as you can specify property values for filtering nodes for a query, you can specify property values for a relationship. This query returns the name of the person who gave the movie a rating of 65.
MATCH (p:Person)-[:REVIEWED {rating: 65}]->(:Movie {title: 'The Da Vinci Code'})
RETURN p.nameThe result returned is:

Patterns in the graph
Thus far, you have learned how to specify nodes, properties, and relationships in your Cypher queries.
Since relationships are directional, it is important to understand how patterns are used in graph traversal during query execution.
How a graph is traversed for a query depends on what directions are defined for relationships and how the pattern is specified in the MATCH clause.
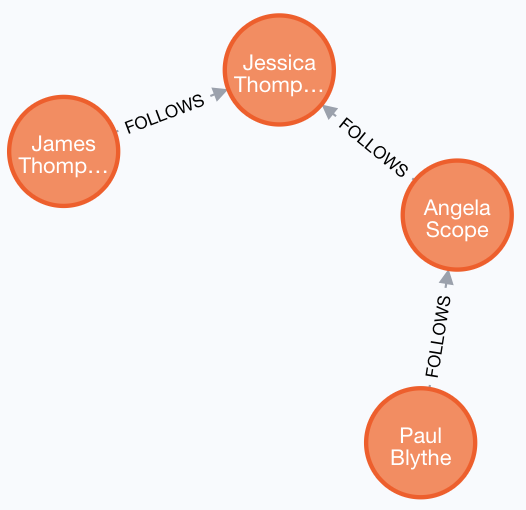
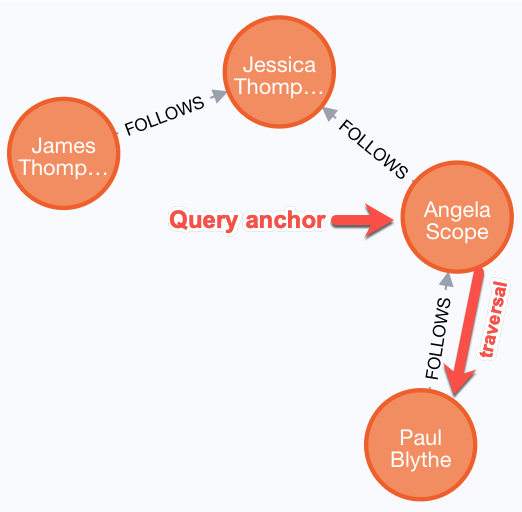
Here is an example of where the FOLLOWS relationship is used in the Movie graph. Notice that this relationship is directional.
Using patterns for queries
We can perform a query that returns all Person nodes who follow Angela Scope:
MATCH (p:Person)-[:FOLLOWS]->(:Person {name:'Angela Scope'})
RETURN pThe result returned is:
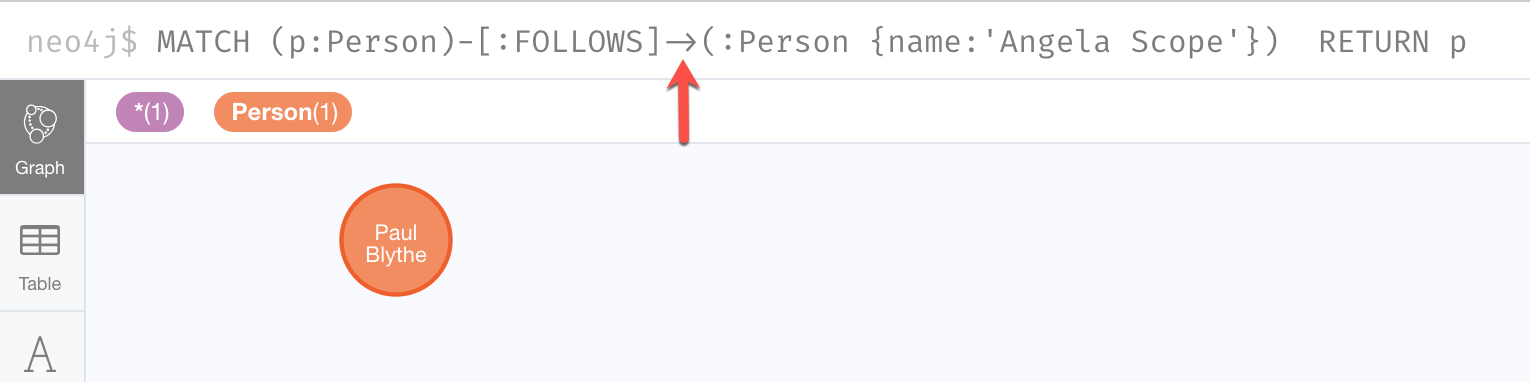
For this query the Person node for Angela Scope is the anchor of the query. It is the first node that is retrieved from the graph. Then the query engine looks for all relationships into this node and retrieves them. In this case there is only one relationship that is defined that points to the Angela Scope node, Paul Blythe.
Reversing the traversal
If we reverse the direction in the pattern, the query returns different results:
MATCH (p:Person)<-[:FOLLOWS]-(:Person {name:'Angela Scope'})
RETURN pThe result returned is:
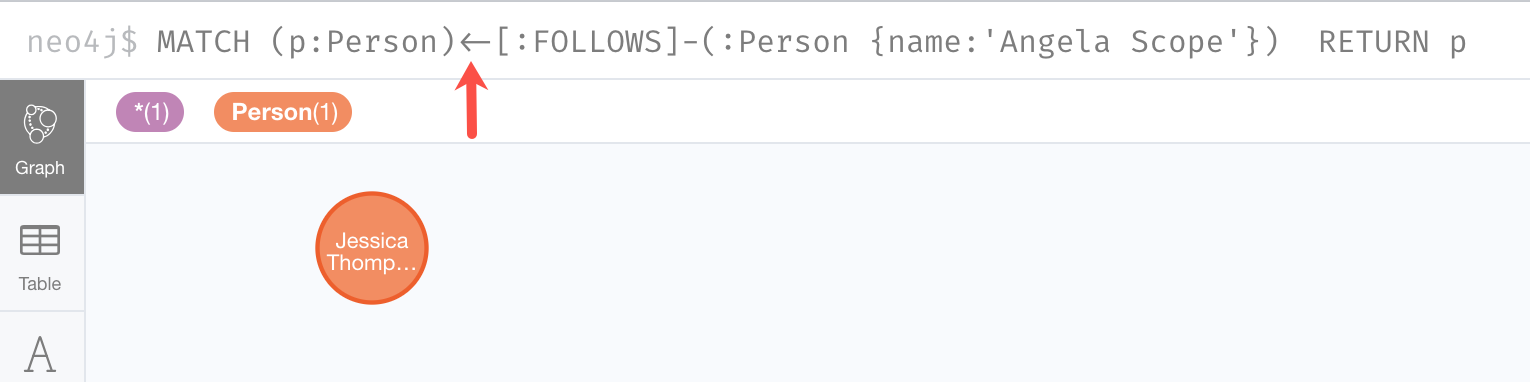
In this case the query engine found the Angela Scope node as the anchor and then looked for all relationships out from the Angela Scope node.
Querying a relationship in both directions
We can also find out what Person nodes are connected by the FOLLOWS relationship in either direction by removing the directional arrow from the pattern.
MATCH (p1:Person)-[:FOLLOWS]-(p2:Person {name:'Angela Scope'})
RETURN p1, p2We also return the Angela Scope node so that we can see the relationships in the result. The result returned is:
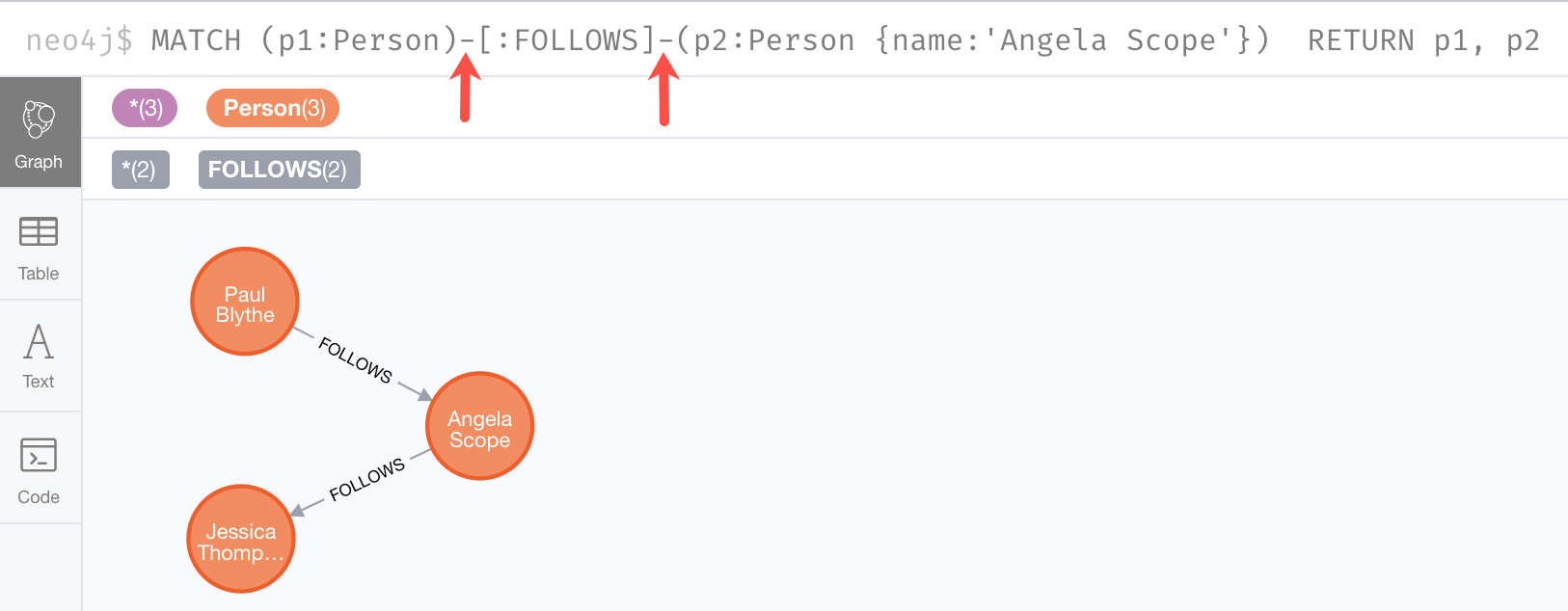
In this case the Angela Scope node is the anchor and the query engine traverses all FOLLOWS relationships both in and out of the Angela Scope Node.
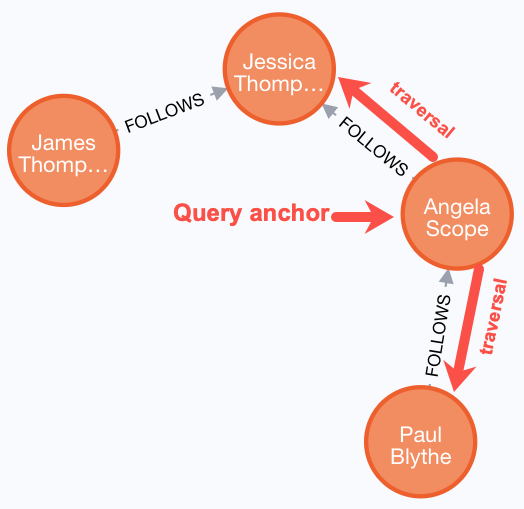
Traversing multiple relationships
Since we have a graph, we can traverse through nodes to obtain relationships further into the traversal.
For example, we can write a Cypher query to return all followers of the followers of Jessica Thompson.
MATCH (p:Person)-[:FOLLOWS]->(:Person)-[:FOLLOWS]->(:Person {name:'Jessica Thompson'})
RETURN pThe result returned is:

For this query the Jessica Thompson node is the anchor. Then from the Jessica Thompson node, the query engine looks for any relationships into that node. It finds two, but then it must traverse more to find the next FOLLOWS relationship (if any) out of the found nodes. It finds only one node, Paul Blythe that matches the query.
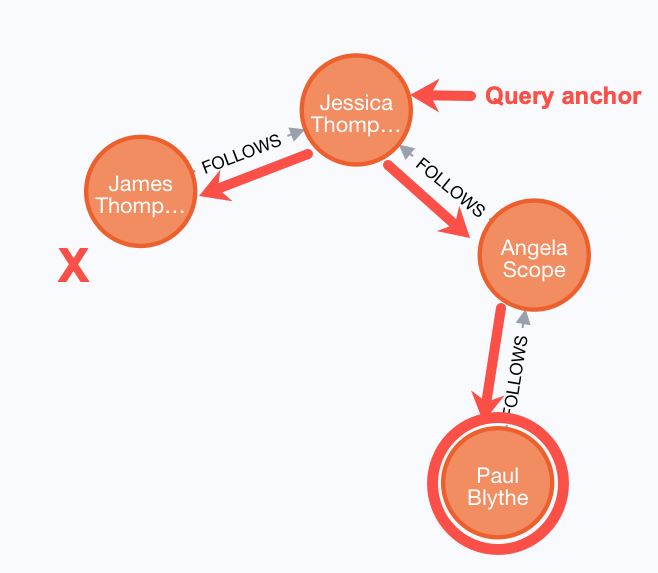
Variation on the traversal
This query could also be modified to return each person along the matched path by specifying variables for the nodes and returning them. For example:
MATCH (p:Person)-[:FOLLOWS]->(p2:Person)-[:FOLLOWS]->(p3:Person {name:'Jessica Thompson'})
RETURN p.name, p2.name, p3.nameFor this query, although the query engine traverses the path from Jessica Thompson to James Thompson, it finds that the James Thompson node does not match the entire path specified.
The result returned is:

Using patterns to focus the query
As you gain more experience with Cypher, you will see how patterns in your queries enable you to focus on the relationships in the graph. For example, suppose we want to retrieve all unique relationships between an actor, a movie, and a director. This query will return many unique rows of information that provide this pattern in the graph:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person)
RETURN a.name, m.title, d.nameThe result returned is:
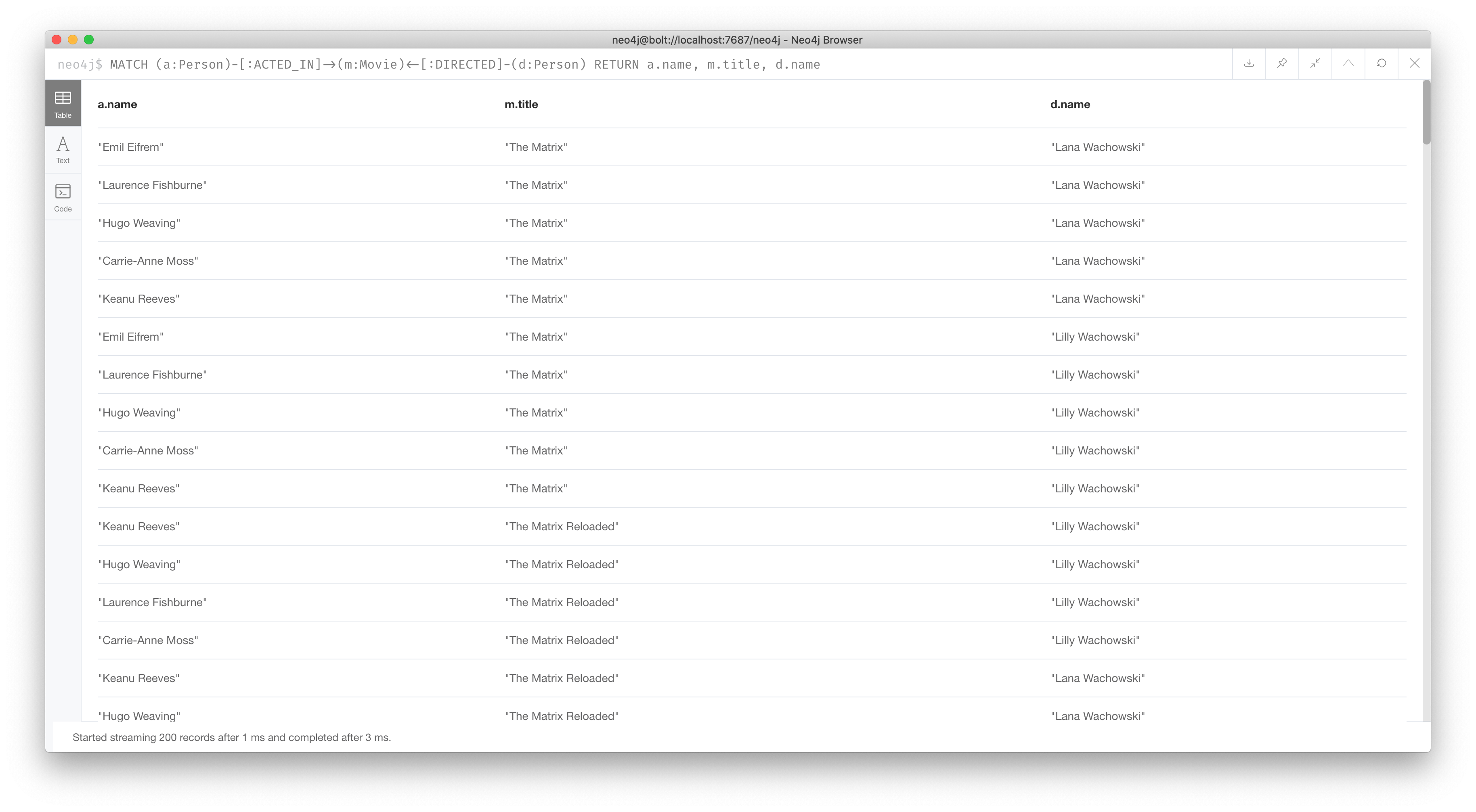
In this query, notice that there are multiple records returned for a movie, each with its set of values for the actor and director. Each row is unique since the focal point of the query is the actor/director for a particular movie.
Returning paths
In addition, you can assign a variable to the path and return the path as follows:
MATCH path = (:Person)-[:FOLLOWS]->(:Person)-[:FOLLOWS]->(:Person {name:'Jessica Thompson'})
RETURN pathThe result returned is:

Returning multiple paths
Here is another example where multiple paths are returned. The query is to return all paths from actors to a movie that was directed by Ron Howard
MATCH path = (:Person)-[:ACTED_IN]->(:Movie)<-[:DIRECTED]-(:Person {name:'Ron Howard'})
RETURN pathMultiple paths are returned. Even if we set Neo4j Browser to not connect result nodes, the nodes are shown as connected in the visualization because we are returning paths, not nodes:
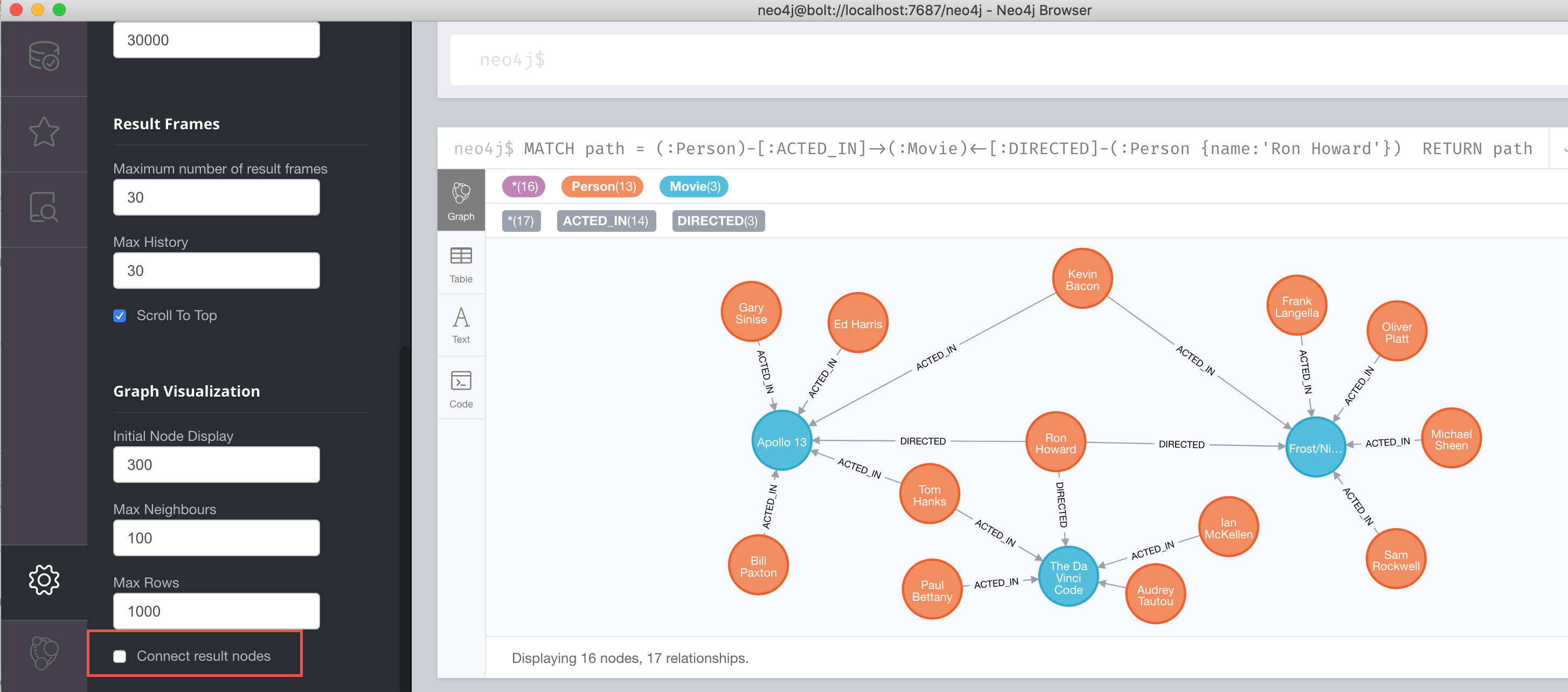
A best practice is to specify direction in your MATCH statements. This will optimize queries, especially for larger graphs.
|
Later in this course, you will learn other ways to query data and how to control the results returned.
Cypher style recommendations
Here are the Neo4j-recommended Cypher coding standards that we use in this training:
-
Node labels are CamelCase and begin with an upper-case letter (examples: Person, NetworkAddress). Note that node labels are case-sensitive.
-
Property keys, variables, parameters, aliases, and functions are camelCase and begin with a lower-case letter (examples: businessAddress, title). Note that these elements are case-sensitive.
-
Relationship types are in upper-case and can use the underscore. (examples: ACTED_IN, FOLLOWS). Note that relationship types are case-sensitive and that you cannot use the "-" character in a relationship type.
-
Cypher keywords are upper-case (examples:
MATCH,RETURN). Note that Cypher keywords are case-insensitive, but a best practice is to use upper-case. -
String constants are in single quotes, unless the string contains a quote or apostrophe (examples: 'The Matrix', "Something’s Gotta Give"). Note that you can also escape single or double quotes within strings that are quoted with the same using a backslash character.
-
Specify variables only when needed for use later in the Cypher statement.
-
Place named nodes and relationships (that use variables) before anonymous nodes and relationships in your
MATCHclauses when possible. -
Specify anonymous relationships with
-->,--, or<--.
Example: Using style recommendations
Here is an example showing some best coding practices:
MATCH (:Person {name: 'Diane Keaton'})-[movRel:ACTED_IN]->
(:Movie {title:"Something's Gotta Give"})
RETURN movRel.rolesWe recommend that you follow the Cypher Style Guide when writing your Cypher statements.
Exercise 3: Filtering queries using relationships
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 3.
| This exercise has 5 steps. Estimated time to complete: 15 minutes. |
Check your understanding
Question 1
Suppose you have a graph that contains nodes representing customers and other business entities for your application. The node label in the database for a customer is Customer. Each Customer node has a property named email that contains the customer’s email address. What Cypher query do you execute to return the email addresses for all customers in the graph?
Select the correct answer.
-
MATCH (n) RETURN n.Customer.email -
MATCH (c:Customer) RETURN c.email -
MATCH (Customer) RETURN email -
MATCH (c) RETURN Customer.email
Question 2
Suppose you have a graph that contains Customer and Product nodes. A Customer node can have a BOUGHT relationship with a Product node. Customer nodes can have other relationships with Product nodes. A Customer node has a property named customerName. A Product node has a property named productName. What Cypher query do you execute to return all of the products (by name) bought by customer 'ABCCO'.
Select the correct answer.
-
MATCH (c:Customer {customerName: 'ABCCO'}) RETURN c.BOUGHT.productName -
MATCH (p:Product)←[:BOUGHT]-(:Customer 'ABCCO') RETURN p.productName -
MATCH (p:Product)←[:BOUGHT_BY]-(:Customer 'ABCCO') RETURN p.productName -
MATCH (p:Product)←[:BOUGHT]-(:Customer {customerName: 'ABCCO'}) RETURN p.productName
Question 3
Thus far, you have learned to use a simple MATCH clause to return values. When must you use a variable in a simple MATCH clause?
Select the correct answer.
-
When you want to query the graph using a node label.
-
When you specify a property value to match the query.
-
When you want to use the node or relationship to return a value.
-
When the query involves 2 types of nodes.
Summary
You can now write Cypher statements to:
-
Retrieve nodes from the graph.
-
Filter nodes retrieved using property values of nodes.
-
Retrieve property values from nodes in the graph.
-
Filter nodes retrieved using relationships.
Need help? Ask in the Neo4j Community