Working with Cypher Data
About this module
You have learned how to query nodes and relationships in a graph using simple patterns, complex patterns, and using multiple MATCH clauses.
You have used simple data types such as numbers and strings to filter queries and return results.
In this module you will learn how aggregation works in a Cypher query and how to work with properties that contain multiple values.
You will also gain some experience working with other data types in Cypher.
At the end of this module, you will write Cypher statements to:
-
Aggregate data into lists.
-
Work with lists.
-
Count results returned.
-
Work with maps.
-
Work with dates.
Aggregation in Cypher
When you return results as values, Cypher automatically returns the values grouped by a common value.
For example, with this query:
MATCH (p:Person)-[:REVIEWED]->(m:Movie)
RETURN p.name, m.titleReturns the following:
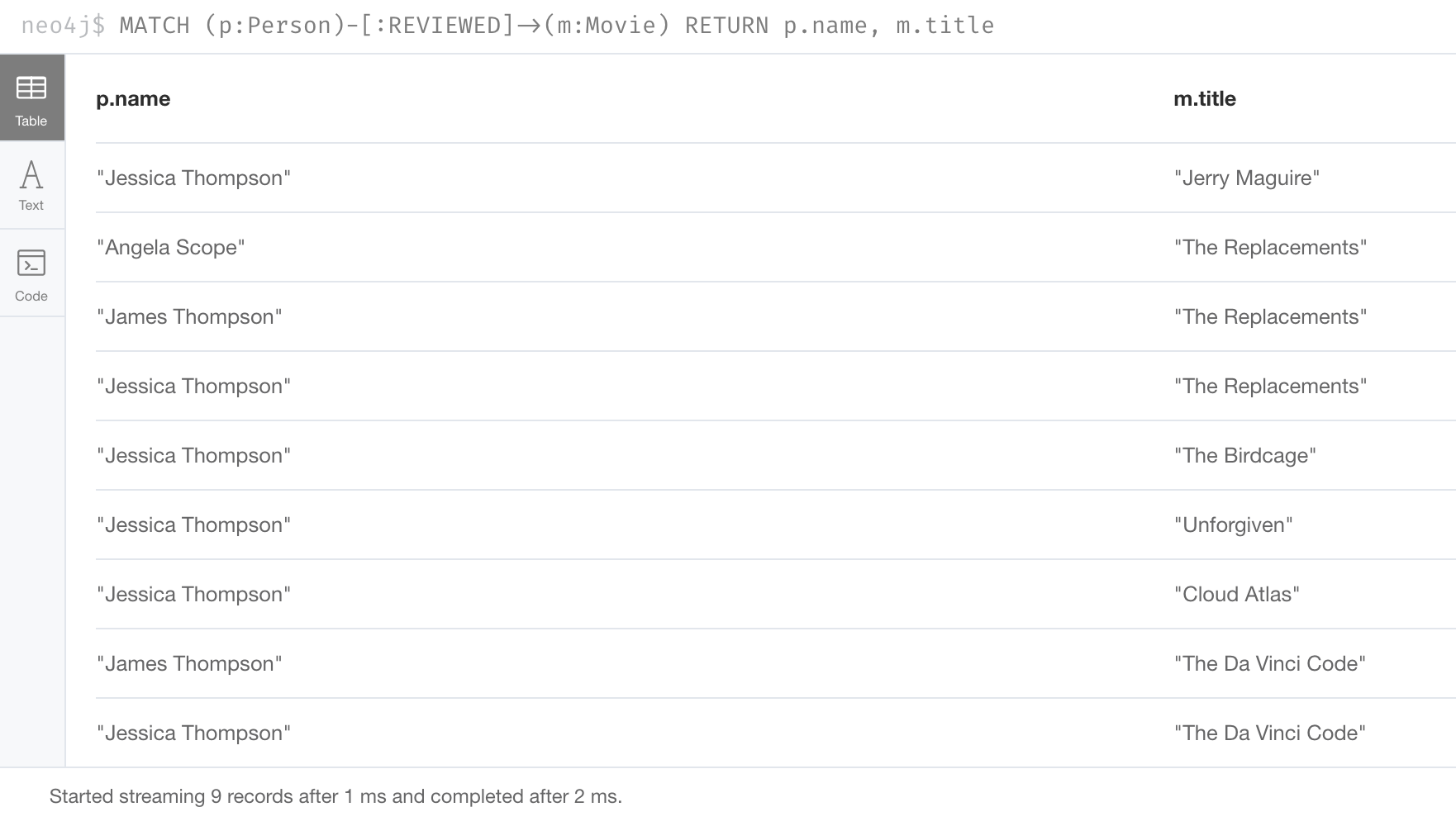
Notice that with this particular graph, the rows are ordered by the value of m.title. In this example three people review the movie, The Replacements, and they are ordered together in the rows returned. How Cypher orders values returned by default will depend on the number of nodes of each type in the graph. You cannot rely on this ordering. To guarantee ordering, you must explicitly aggregate the rows.
Using count() to aggregate
A common way to aggregate data in Cypher is to count.
Cypher has a count() function that you can use to perform a count of nodes, relationships, paths, rows during query processing.
When you aggregate in a Cypher query, this means that the query must process all patterns in the MATCH clause to complete the aggregation to either return results or perform the next part of the query.
Here is an example:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person)
RETURN a.name, d.name, count(m)With this result returned:
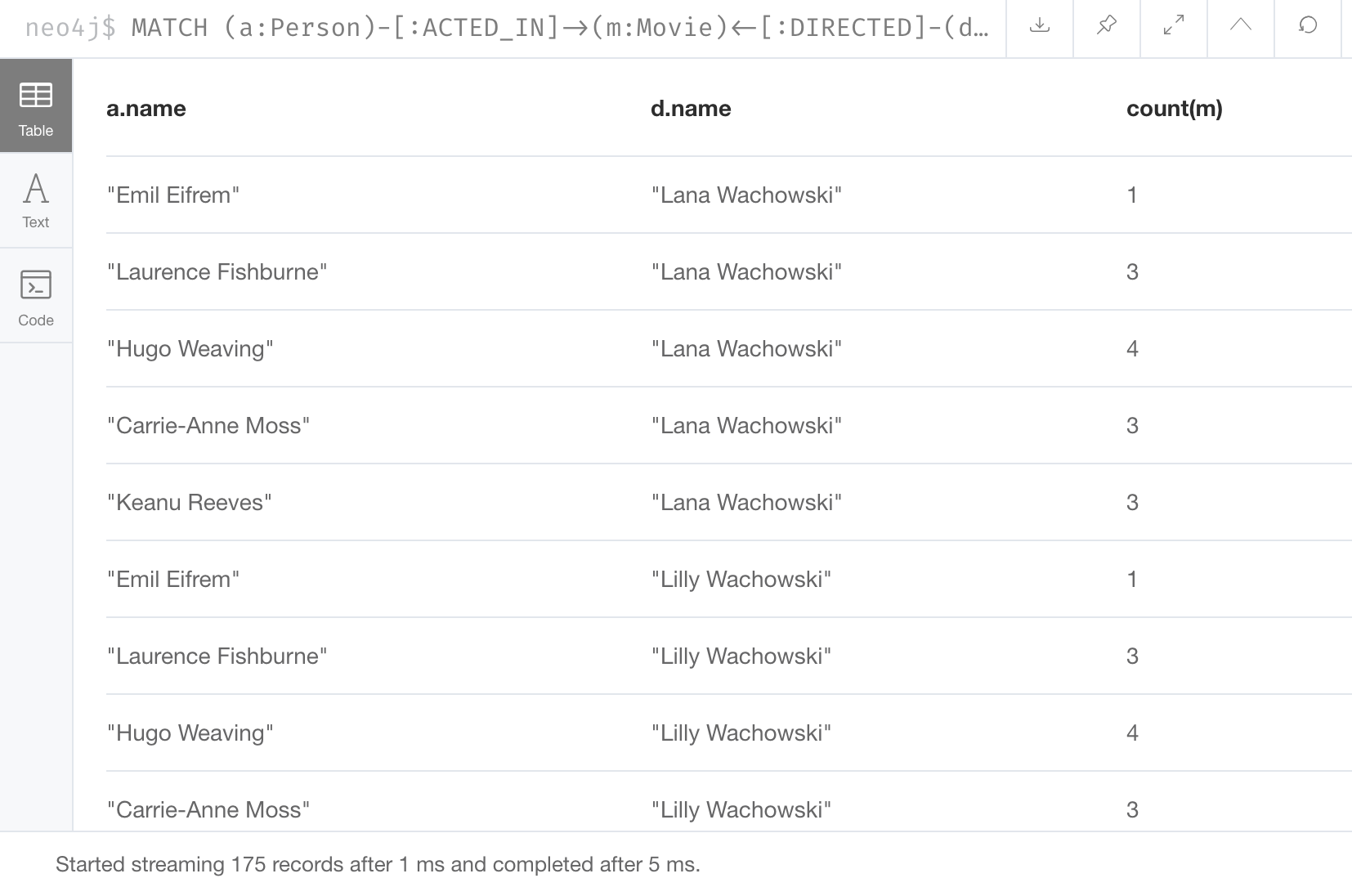
The query engine processed all nodes and relationships in the pattern so that it could perform a count of all movies for a particular actor/director pair in the graph. Then, it returned the results grouped by the name of the director.
Aggregation in Cypher is different from aggregation in SQL. In Cypher, you need not specify a grouping key. As soon as an aggregation function is used, all non-aggregated result columns become grouping keys.
The grouping is implicitly done, based upon the fields in the RETURN clause.
For example, in the Cypher statement shown above, all rows returned with the same values for a.name and d.name are counted and only returned once. That is, there are exactly four movies that Lana Washowski directed with Hugo Weaving acting in.
Collecting results
Cypher has a built-in function, collect() that enables you to aggregate a value into a list.
The value can be a property value, a node, a relationship, or a path.
Here is an example where we collect the list of movie titles that Tom Cruise acted in:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name ='Tom Cruise'
RETURN collect(m.title) AS `movies for Tom Cruise`Here is the result returned:

Notice that the list is defined in square brackets and each element of the list is separated by a comma. This list contains a set of strings.
Collecting nodes
As you gain more experience with Cypher queries, you will learn to collect nodes, in addition to string values. For example, rather than collecting the values of the title properties for all movies that Tom Cruise acted in, we can collect the nodes. For this simple query, it is the same as returning m, but for more complex queries, you will find that collecting nodes and using them for a later step of the query is useful.
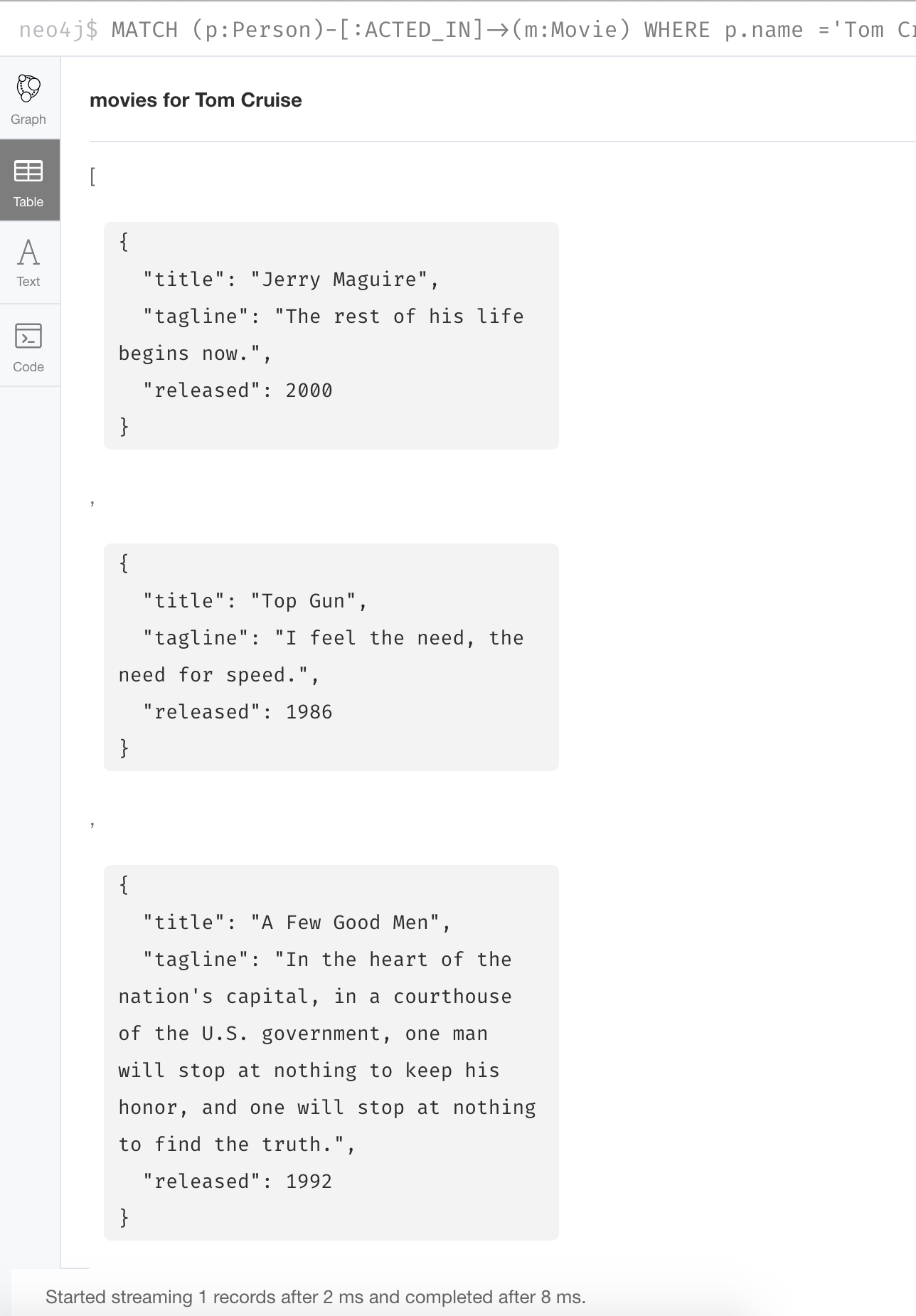
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
WHERE p.name ='Tom Cruise'
RETURN collect(m) AS `movies for Tom Cruise`Here is the result returned viewed as a graph. It is the same as simply returning m:

Here is the result returned viewed as a table. Each node is an object in the list returned:
Counting and collecting
The Cypher count() function is very useful when you want to count the number of occurrences of a particular query result.
If you specify count(n), the graph engine calculates the number of occurrences of n.
If you specify count(*), the graph engine calculates the number of rows retrieved, including those with null values.
When you use count(), the graph engine does an implicit "group by" based upon the aggregation.
Here is an example where we count the paths retrieved where an actor and director collaborated in a movie and the count() function is used to count the number of paths found for each actor/director collaboration.
MATCH (actor:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor.name, director.name,
count(m) AS collaborations, collect(m.title) AS moviesHere is the result returned:

Notice here that the director.name value is a grouping key for the results returned.
Using collect() and size()
There are more aggregating functions such as min() or max() that you can also use in your queries.
These are described in the Aggregating Functions section of the Neo4j Cypher Manual.
You can either use count() to count the number of rows, or alternatively, you can return the size of the collected results.
The size() function returns the number of elements in a list.
As you gain more experience with query tuning, you will learn that count() is more efficient because it gets its values from the internal count store of the graph.
|
Here is an alternative to using count() that returns the same results, but using size():
MATCH (actor:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(director:Person)
RETURN actor.name, director.name, size(collect(m)) AS collaborations,
collect(m.title) AS moviesWorking with Cypher data
Thus far, you have specified both string and numeric types in your Cypher queries. You have also learned that nodes and relationships can have properties, whose values are structured like JSON objects when returned in the Neo4j Browser UI. For example:
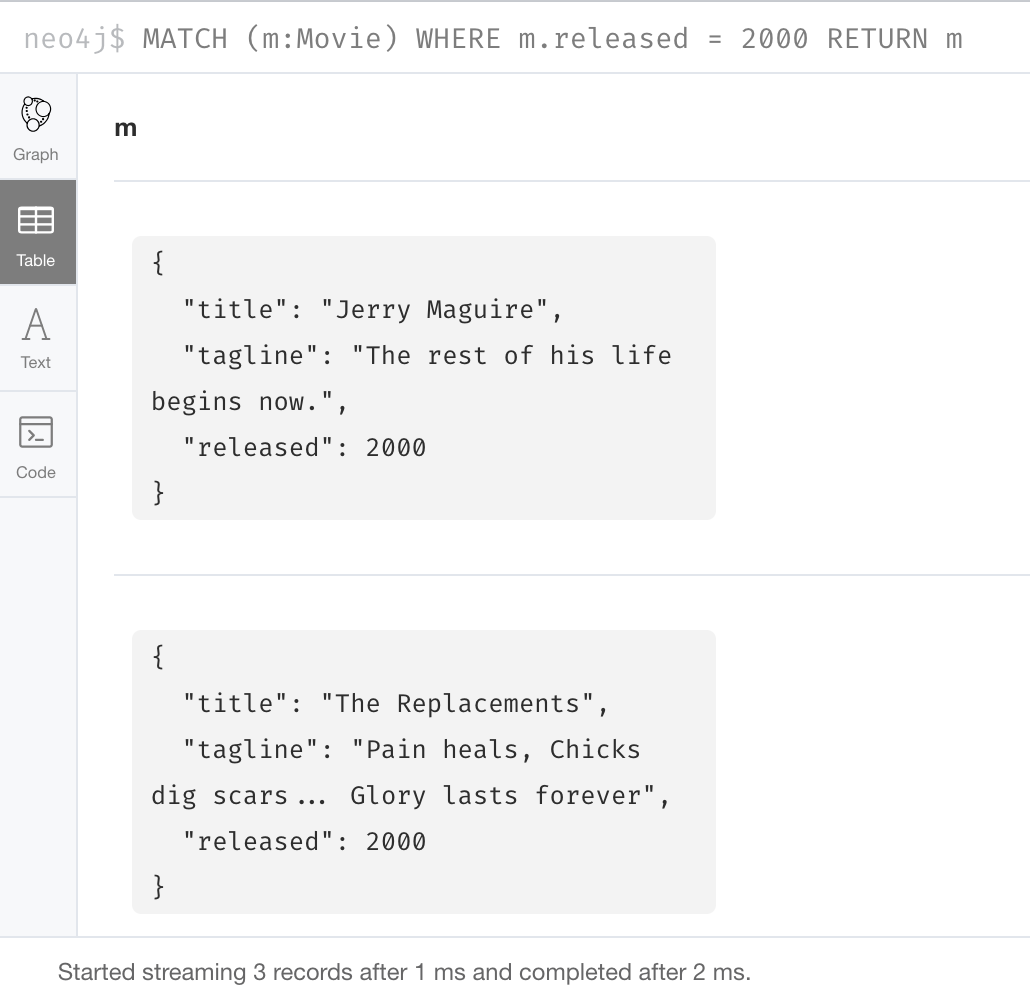
Here we see that the Movie nodes have three properties, two of them are of type String while the other is of type Integer.
You have also learned that the collect() function can create lists of values or objects where a list is comma-separated and you can use the IN keyword to search for a value in a list.
Next, you will learn more about working with lists and dates in Cypher.
Lists
There are many built-in Cypher functions that you can use to build or access elements in lists.
Here we return the cast list for every movie, as well as the size of the cast:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN m.title, collect(a) as cast, size(collect(a)) as castSizeHere is the result returned:
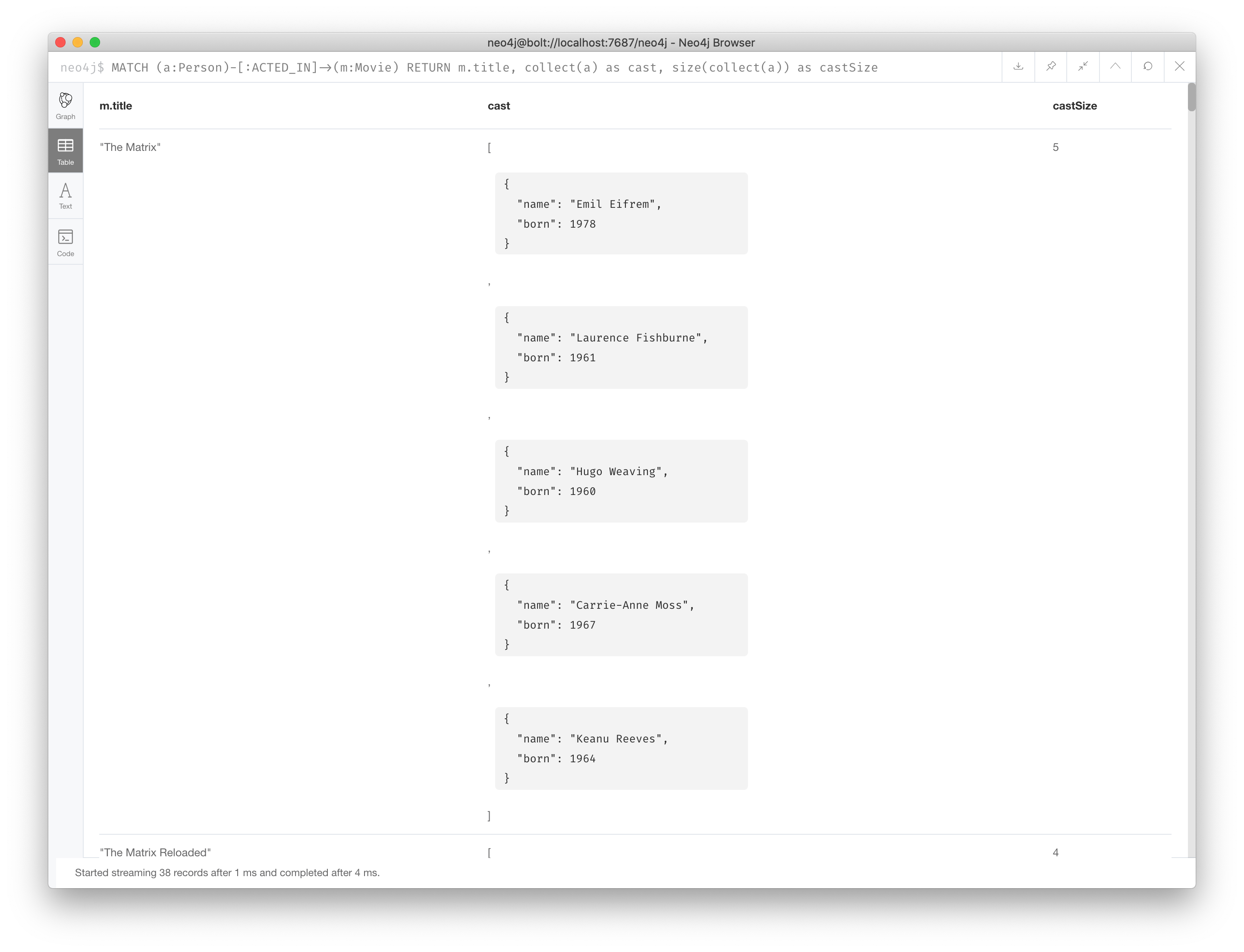
Notice that when viewing nodes in table view, each node is shown with {} notation and key value pairs. This structure is called a map in Cypher.
Using strings in lists
We can adjust this query slightly so that the list contains the names, rather than the entire set of Person node properties.
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN m.title, collect(a.name) as cast, size(collect(a.name)) as castSizeHere is the result returned:

Accessing elements of the list
You can access particular elements of the list using the [index-value] notation where a list begins with index 0.
In this example we return the first cast member for each movie.
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
RETURN m.title, collect(a.name)[0] as `A cast member`,
size(collect(a.name)) as castSizeHere is the result returned:
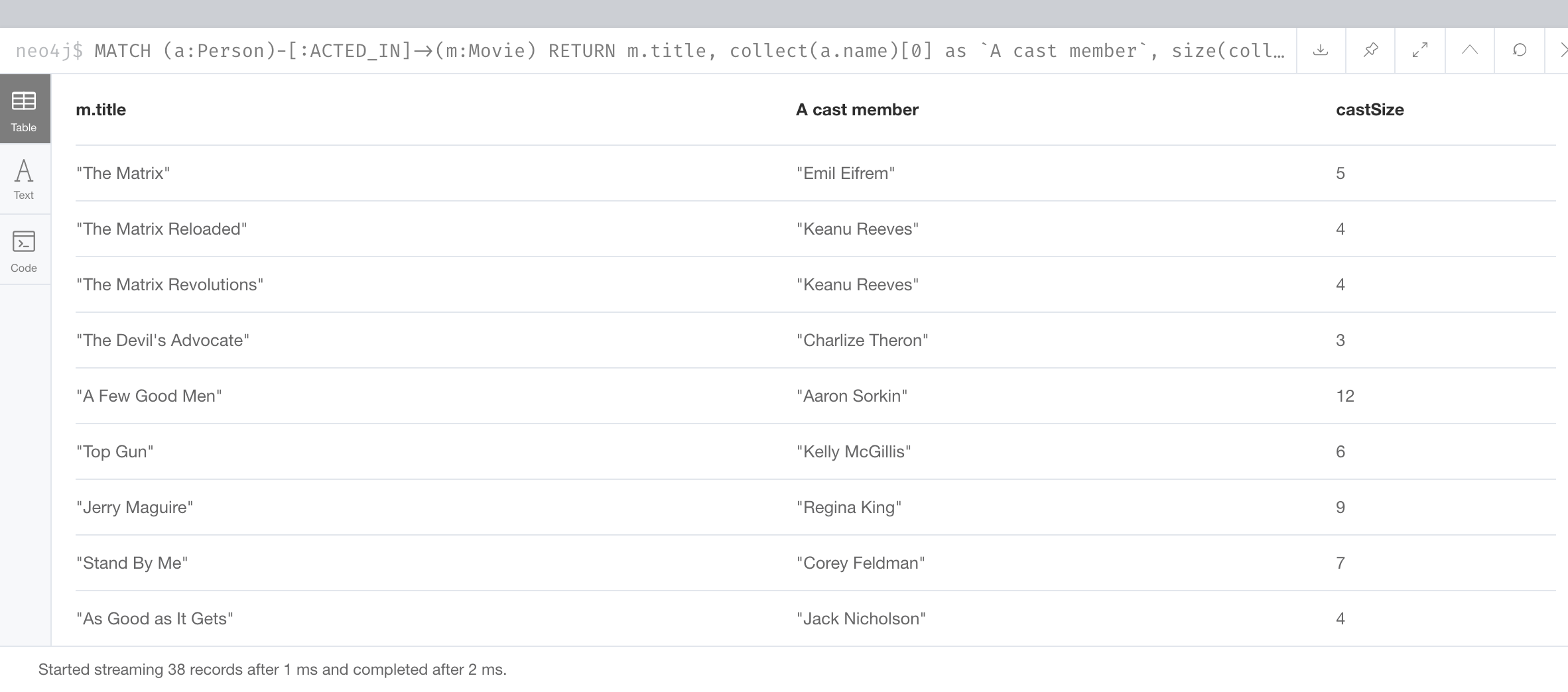
In this result we return the first cast member (indexed by 0) of each list for every movie.
You can read more about working with lists in the List Functions section of the Neo4j Cypher Manual.
Working with maps
A Cypher map is list of key/value pairs where each element of the list is of the format 'key': value. For example, a map of months and the number of days per month could be:
{Jan: 31, Feb: 28, Mar: 31, Apr: 30 , May: 31, Jun: 30 , Jul: 31, Aug: 31, Sep: 30, Oct: 31, Nov: 30, Dec: 31}
Using this map, we can return the value for one of its elements:
RETURN {Jan: 31, Feb: 28, Mar: 31, Apr: 30 , May: 31, Jun: 30 ,
Jul: 31, Aug: 31, Sep: 30, Oct: 31, Nov: 30, Dec: 31}['Feb'] AS DaysInFebHere is the result:
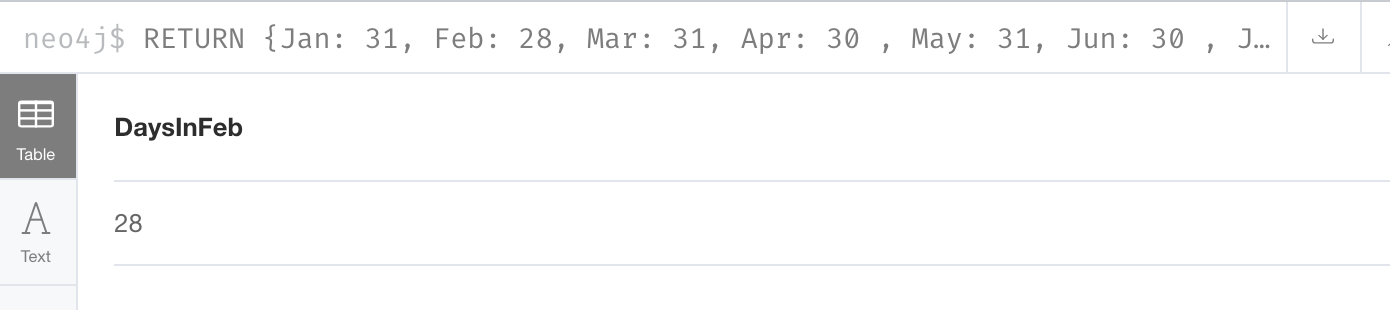
Accessing map elements
Here we use the key, 'Feb' to access its value. Notice that this statement is a single RETURN statement without a MATCH.
We are returning a value that is not retrieved from the graph.
A node in the graph, when returned in Neo4j Browser is a map, when displayed as table rows. For example, a Movie node:
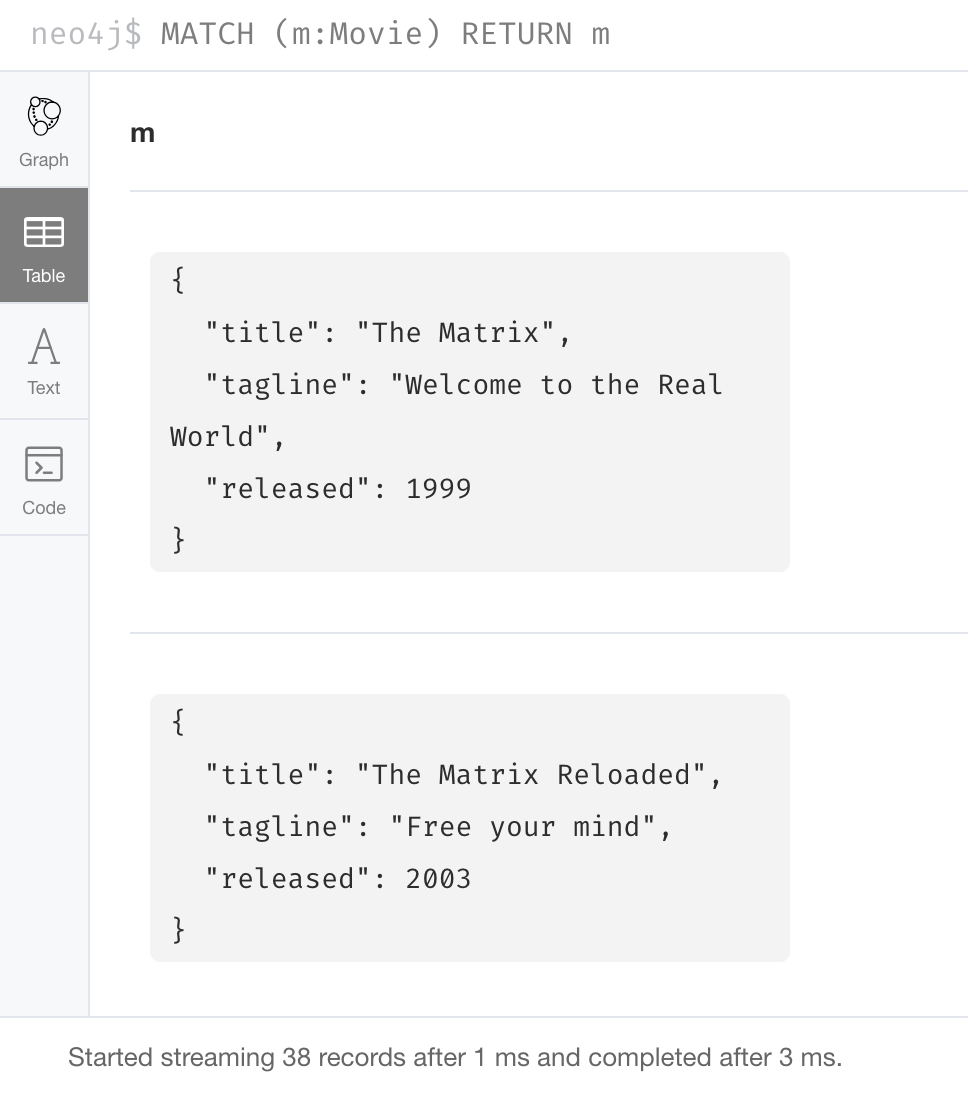
Map projections
Map projections are when you can use retrieved nodes to create or return some of the information in the nodes. A Movie node can have the properties title, released, and tagline. Suppose we want to return the Movie node information, but without the tagline property? You can do so as follows using map projections:
MATCH (m:Movie)
WHERE m.title CONTAINS 'Matrix'
RETURN m { .title, .released } AS movieHere is what is returned, the movie node data with only the title and released values:
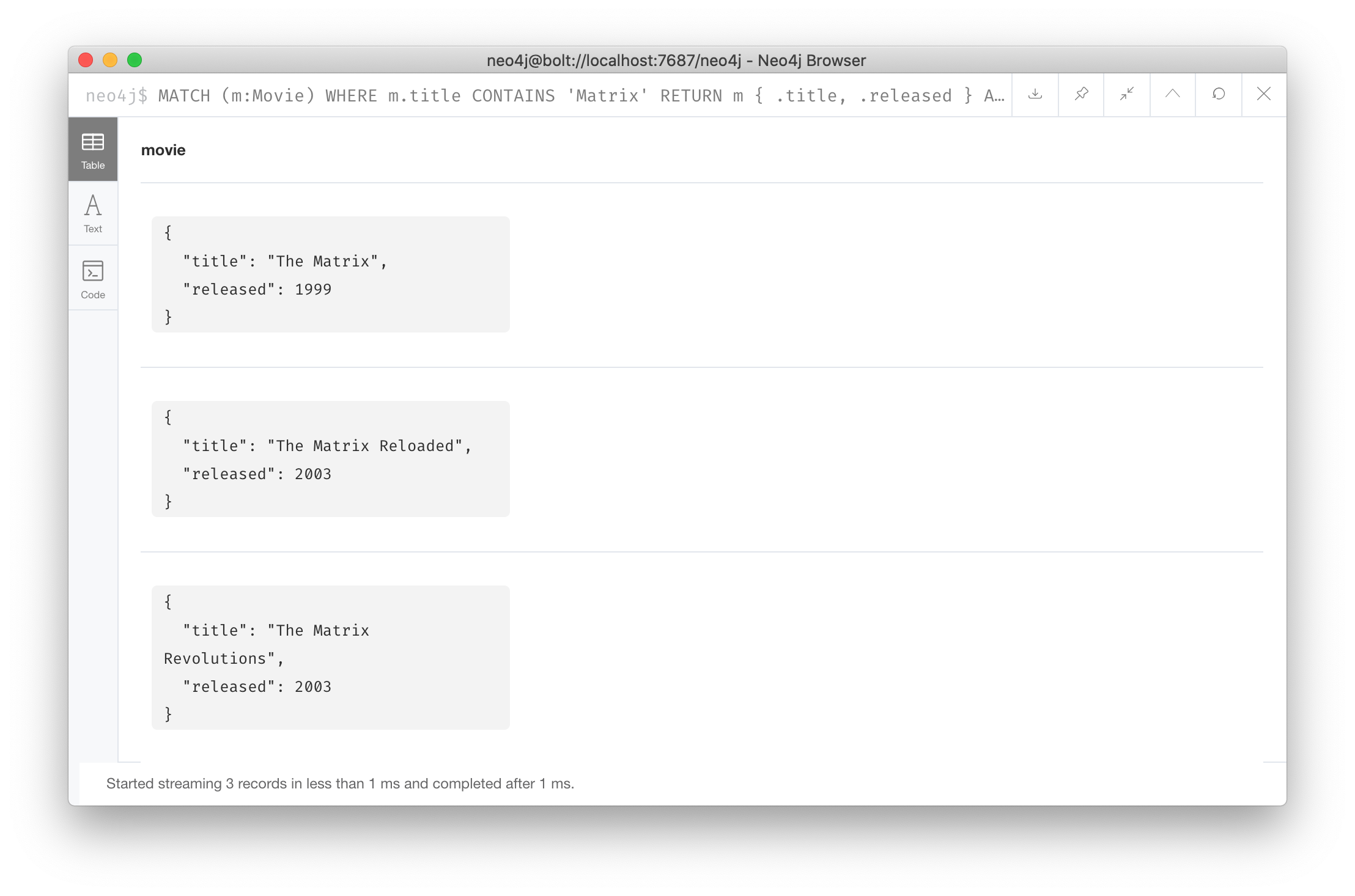
You can learn more about map projections in the Cypher Reference Manual.
Working with dates
In your application, you may need to decide how you will store date/time information in the graph.
Neo4j has these several basic formats for storing date/time data. There are a number of other types of data such as Time, LocalTime, LocalDateTime, and Duration which are described in the documentation.
RETURN date(), datetime(), time(), timestamp()
Accessing components of dates
With date() and datetime(), you can use properties such as day, year, time to extract the values that you need:
RETURN date().day, date().year, datetime().year, datetime().hour,
datetime().minute
Working with timestamp()
Working with timestamp() is different as its value is a long integer that represents time. The value of datetime().epochmillis is the same as timestamp().
To extract a month, year, or time from a timestamp, you would do the following:
RETURN datetime({epochmillis:timestamp()}).day,
datetime({epochmillis:timestamp()}).year,
datetime({epochmillis:timestamp()}).month
Type and data conversions
Depending on how you need to convert data in the graph, you can use any of the built-in Cypher functions to convert the values.
Here are some of the built-in conversion functions:
-
toInteger() -
toLower() -
toUpper( ) -
toString()
Consult the Neo4j Cypher Manual for more information about the built-in functions available for working with data of all types.
Exercise 6: Working with Cypher data
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 6.
| This exercise has 6 steps. Estimated time to complete: 15 minutes. |
Check your understanding
Summary
You can now write Cypher statements to:
-
Aggregate data into lists.
-
Count results returned.
-
Work with lists.
-
Work with maps.
-
Work with dates.
Need help? Ask in the Neo4j Community