Working with Patterns in Queries
About this module
You have learned how to query nodes and relationships in a graph using simple patterns and also how to use the WHERE clause for filtering queries.
At the end of this module, you will write Cypher statements to:
-
Specify multiple
MATCHpatterns. -
Specify multiple
MATCHclauses. -
Specify varying length paths.
-
Return a subgraph.
-
Specify
OPTIONALin a query.
Traversal in a MATCH clause
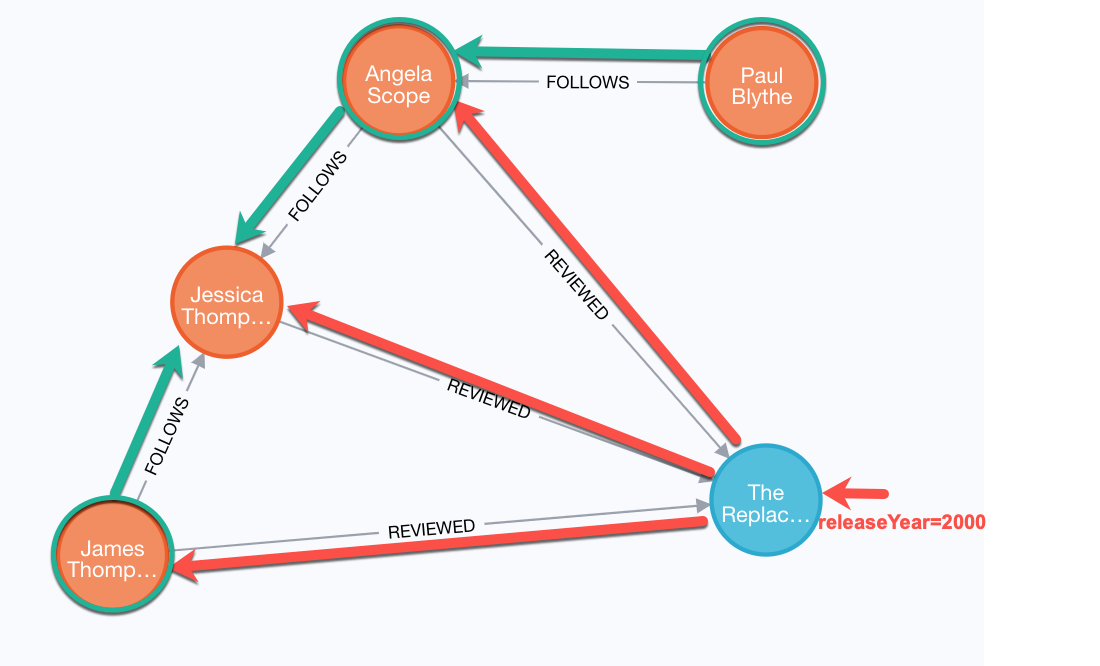
Suppose we want to find all of the followers of people who reviewed the movie, The Replacements.
Here is the query:
MATCH (follower:Person)-[:FOLLOWS]->(reviewer:Person)-[:REVIEWED]->(m:Movie)
WHERE m.title = 'The Replacements'
RETURN follower.name, reviewer.nameHere is the result:

Here is the traversal that the graph engine performed. It first found the movie, The Replacements. Then it found all Person nodes that reviewed that movie, Angela, Jessica, and James. Then it found all Person nodes who follow the people who reviewed the movie, Paul, Angela, and James. In all, six relationships were traversed.
Specifying multiple patterns in a MATCH
Up until now, you have specified a single MATCH pattern in a query with filtering in a WHERE clause.
You can specify multiple patterns in a MATCH clause.
Suppose we want to write queries that focus on movies released in the year 2000. Here are the nodes and relationships for these movies:
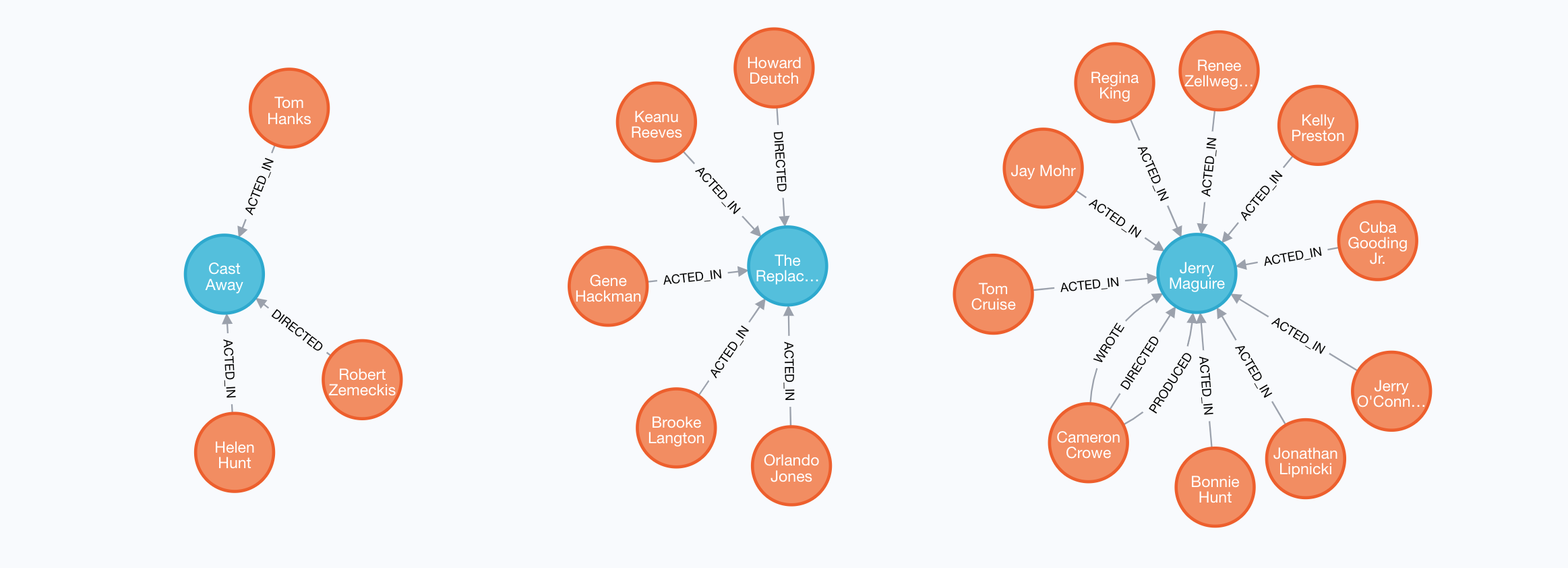
This MATCH clause includes a pattern specified by two paths separated by a comma:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie),
(m)<-[:DIRECTED]-(d:Person)
WHERE m.released = 2000
RETURN a.name, m.title, d.nameIt returns all Person nodes for people who acted in these three movies and using that same movie node, m it retrieves the Person node who is the director for that movie, m.
Here is the result of executing this query:
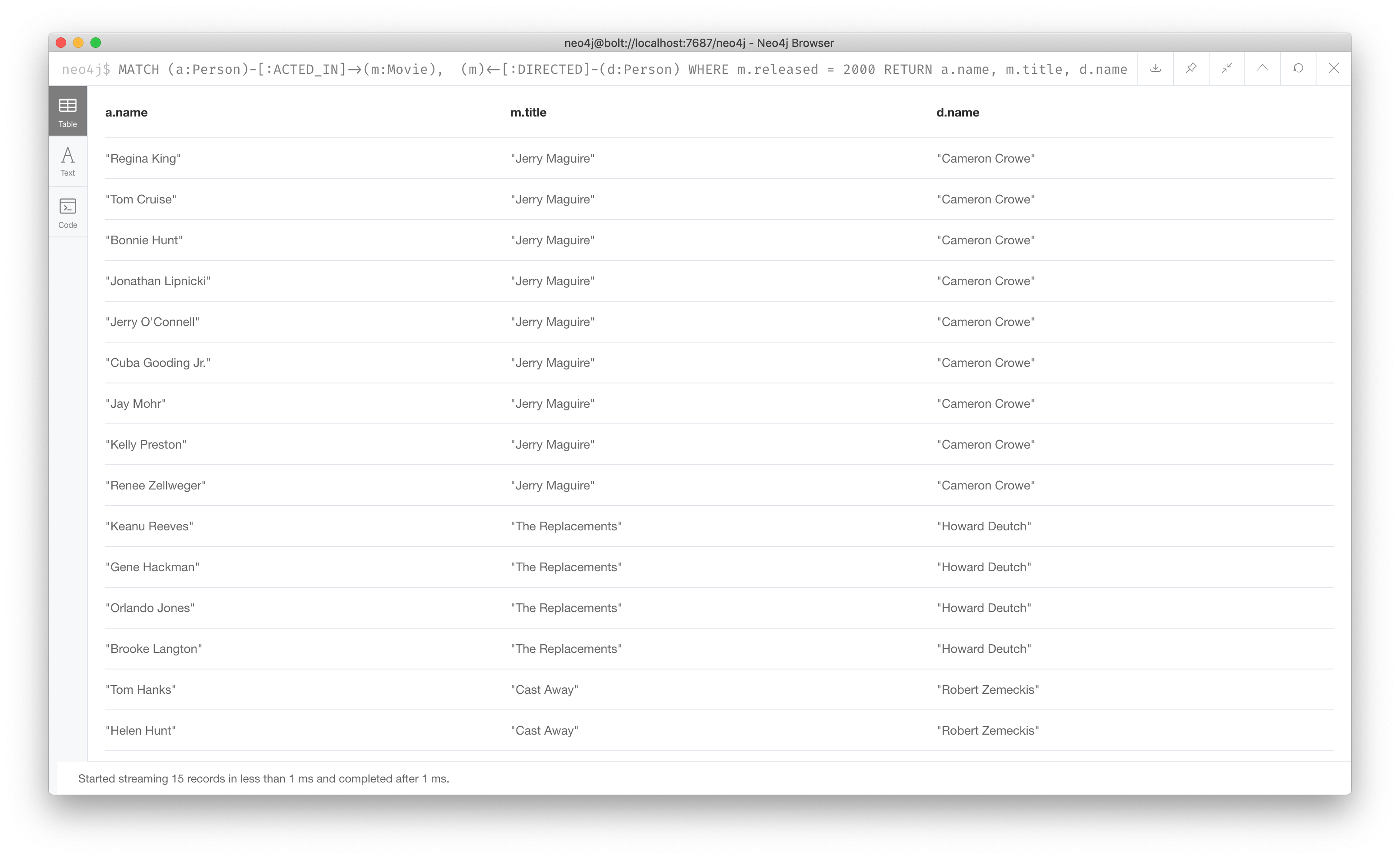
It returns 15 rows, one for each actor with the associated movie title and name of the director for that particular movie.
When multiple patterns are specified in a MATCH clause, no relationship is traversed more than one time.
Specifying a single pattern
However, a better way to write this same query would be:
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person)
WHERE m.released = 2000
RETURN a.name, m.title, d.nameThere are, however, some queries where you will need to specify two or more patterns. Multiple patterns are used when a query is complex and cannot be satisfied with a single pattern. This is useful when you are looking for a specific node in the graph and want to connect it to a different node. You can learn about creating nodes and relationships in the course, Creating Nodes and Relationships in Neo4j 4.x.
Example: Using two patterns in a MATCH
Here are some examples of specifying two paths in a MATCH clause.
In the first example, we want the actors that worked with Keanu Reeves to meet Hugo Weaving, who has worked with Keanu Reeves.
Here we retrieve the actors who acted in the same movies as Keanu Reeves, but not when Hugo Weaving acted in the same movie.
To do this, we specify two paths for the MATCH:
MATCH (keanu:Person)-[:ACTED_IN]->(movie:Movie)<-[:ACTED_IN]-(n:Person),
(hugo:Person)
WHERE keanu.name='Keanu Reeves' AND
hugo.name='Hugo Weaving'
AND NOT (hugo)-[:ACTED_IN]->(movie)
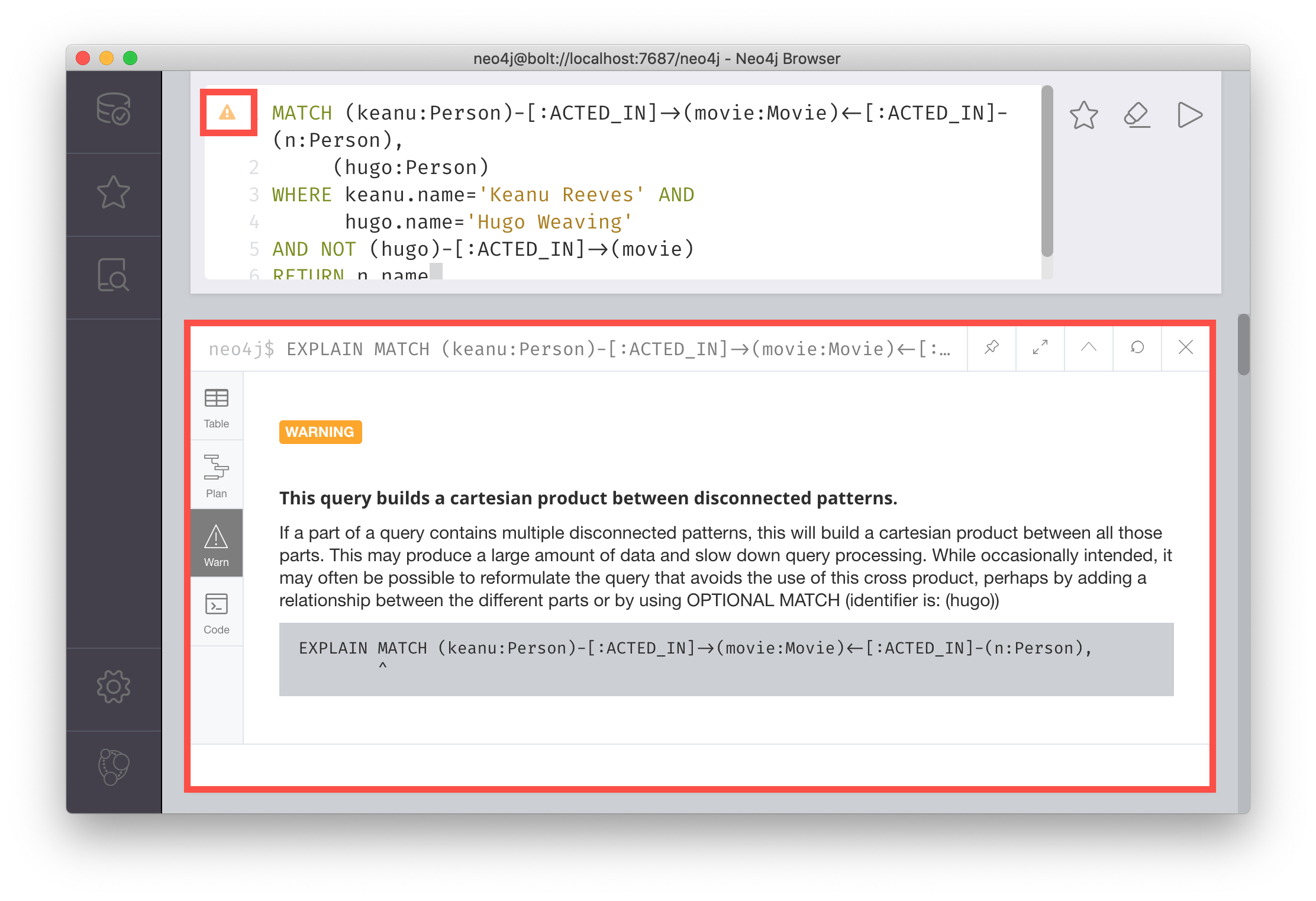
RETURN n.nameWhen you perform this type of query, you may see a warning in the query edit pane stating that the pattern represents a cartesian product and may require a lot of resources to perform the query. You only perform these types of queries if you know the data well and the implications of doing the query.
If you click the warning symbol in the top left corner, it produces an explanation result pane.
Here is the result of executing this query:
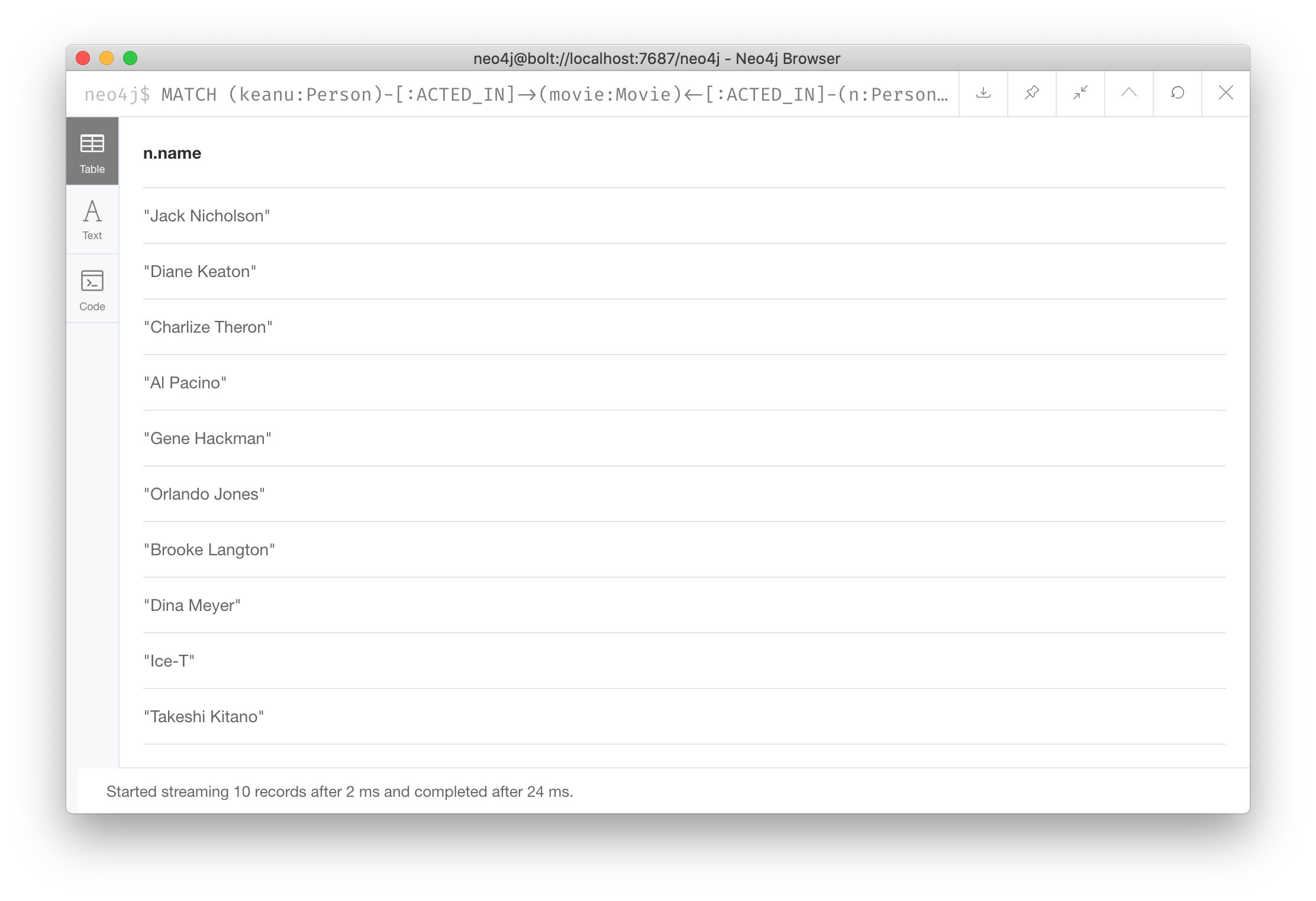
The actors Laurence Fishburne, Carrie-Anne Moss, Emil Eifrem (and of course Hugo Weaving and Keanu Reeves) do not appear in the results list, because these actors were in the same movie (The Matrix) as Hugo Weaving and Keanu Reeves.
Example: Two patterns in a MATCH required
Here is another example where two patterns are necessary.
Suppose we want to retrieve the movies that Meg Ryan acted in and their respective directors, as well as the other actors that acted in these movies. Here is the query to do this:
MATCH (meg:Person)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d:Person),
(other:Person)-[:ACTED_IN]->(m)
WHERE meg.name = 'Meg Ryan'
RETURN m.title as movie, d.name AS director , other.name AS `co-actors`Here is the result returned:
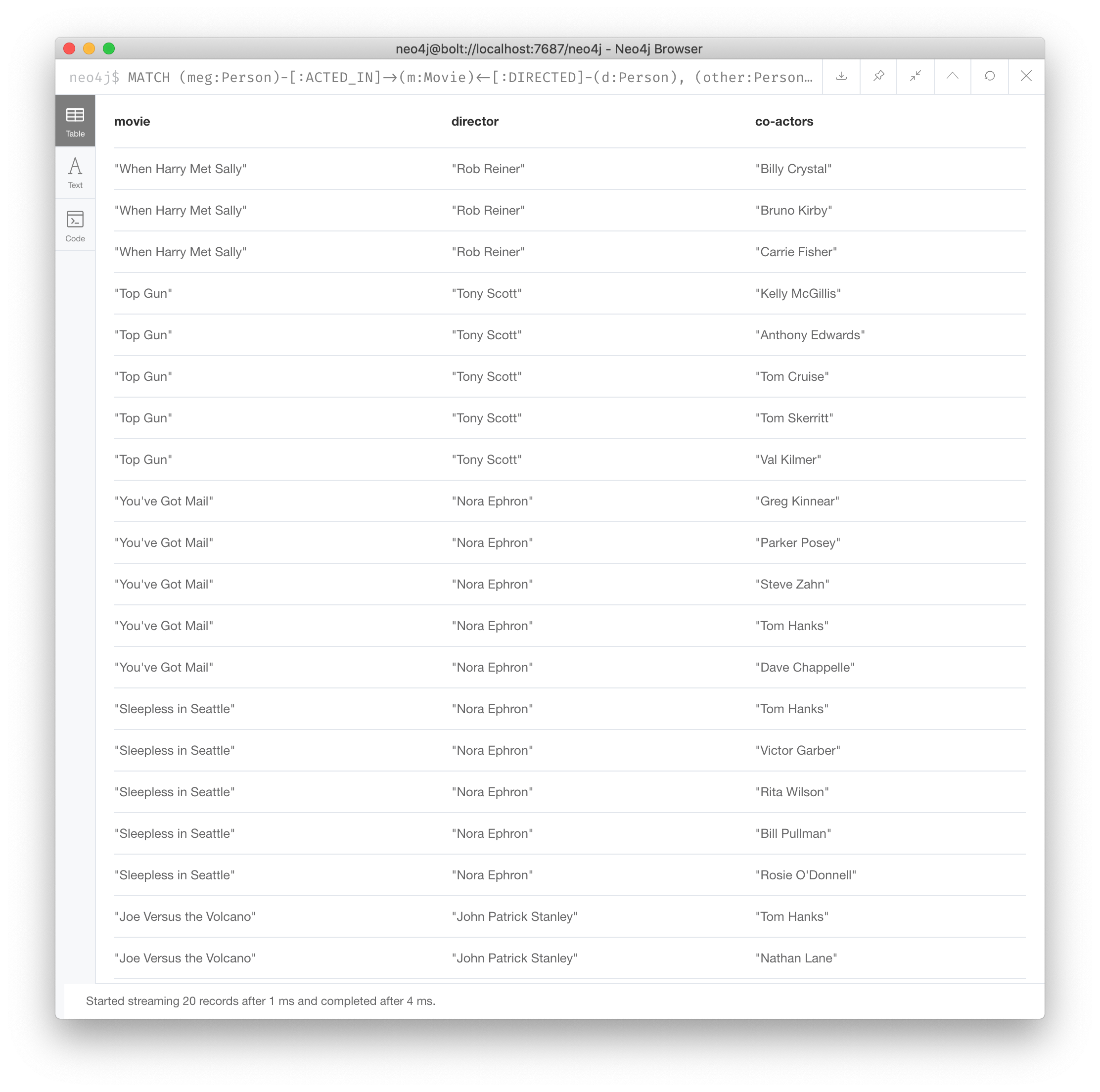
An important thing to understand about multiple patterns in a single MATCH statement is that the query processor will never traverse a relationship more than once.
That is why the Meg Ryan node is not retrieved in the other node retrievals. All other nodes of people who acted in that same movie are retrieved.
Traversal with patterns
During a query, you want to minimize the number of paths traversed.
In some cases, however, you can only retrieve the nodes, relationships, or paths of interest using multiple patterns or even multiple MATCH clauses.
Here is an example query where multiple MATCH clauses are used:
MATCH (valKilmer:Person)-[:ACTED_IN]->(m:Movie)
MATCH (actor:Person)-[:ACTED_IN]->(m)
WHERE valKilmer.name = 'Val Kilmer'
RETURN m.title as movie , actor.nameThe first MATCH clause retrieves Val Kilmer pointing to the movie, Top Gun using the ACTED_IN relationship.
The anchor of this MATCH clause is the Val Kilmer Person node.
The second MATCH clause retrieves all Person nodes that have the ACTED_IN relationship with the movie, Top Gun.
The anchor of the MATCH clause is the Top Gun Movie node.
When the query engine traverses the graph for these MATCH clauses, we see that the ACTED_IN relationship is traversed twice.
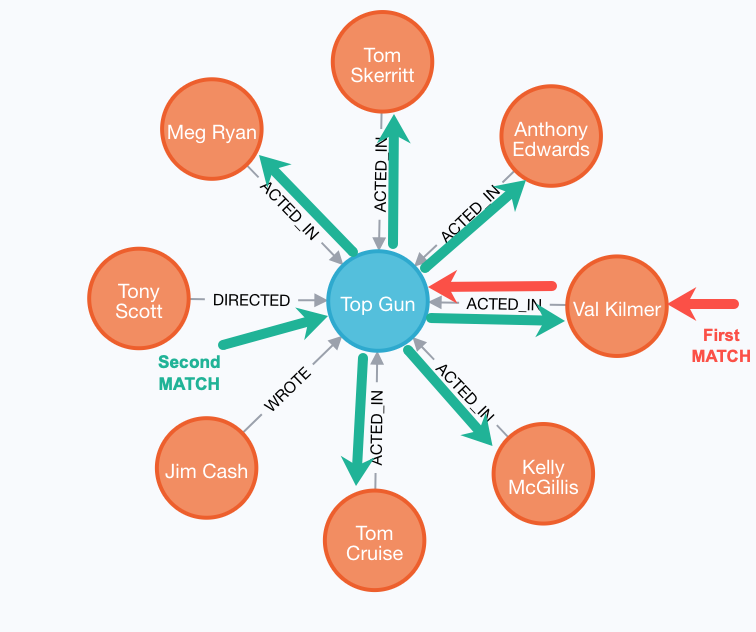
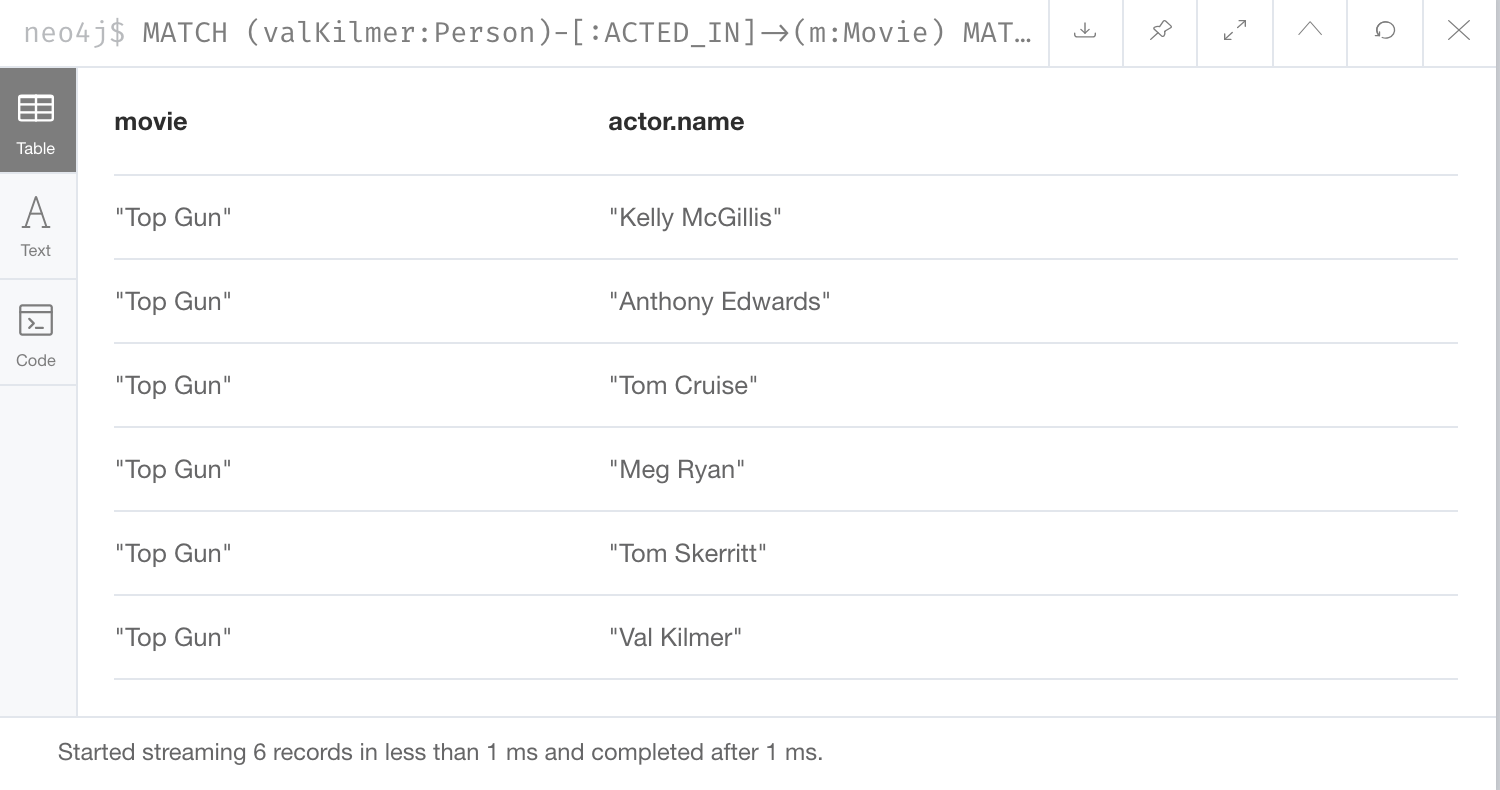
Here is the result returned:
Traversal: Multiple patterns in a MATCH clause
Here is the same example where multiple patterns are specified in a single MATCH clause:
MATCH (valKilmer:Person)-[:ACTED_IN]->(m:Movie),
(actor:Person)-[:ACTED_IN]->(m)
WHERE valKilmer.name = 'Val Kilmer'
RETURN m.title as movie , actor.nameThe MATCH clause retrieves the Val Kilmer node and uses the ACTED_IN relationship to retrieve the Top Gun node, then it uses the movie node to retrieve all actors.
With this scenario, the ACTED_IN relationship is only traversed once.
We already know the Person node for Val Kilmer so we need not return it.
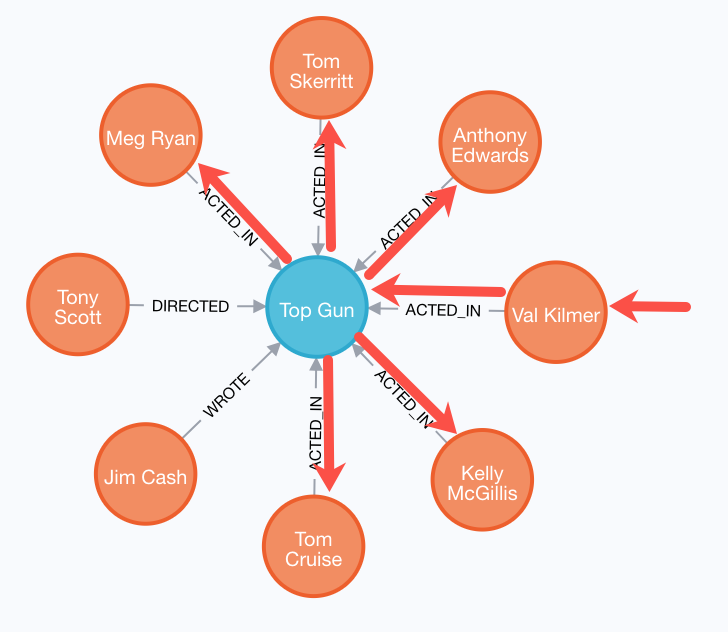
The result returned is smaller because it does not include the Val Kilmer node.
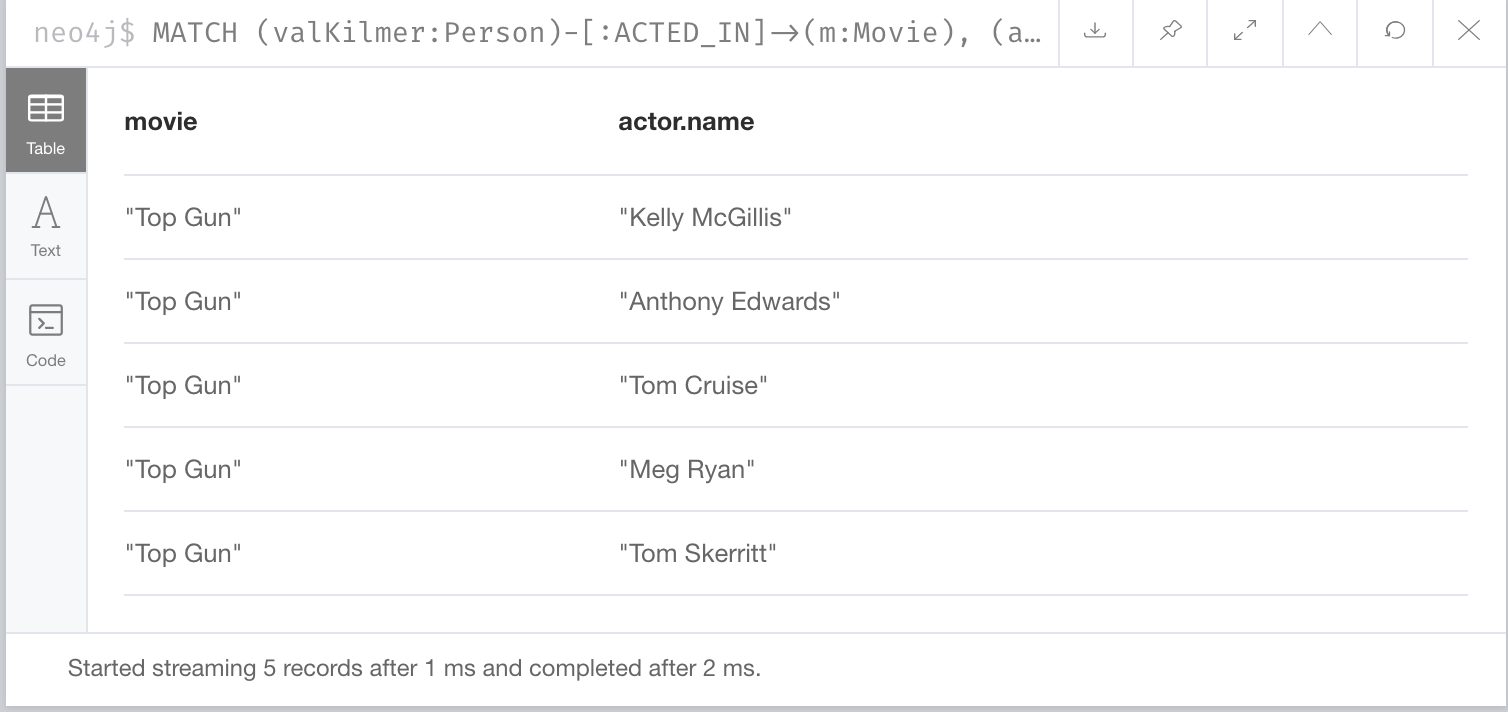
A best practice is to traverse as few nodes as possible so in this example, using multiple MATCH patterns is best.
Specifying varying length paths
Any graph that represents social networking, trees, or hierarchies will most likely have multiple paths of varying lengths. Think of the connected relationship in LinkedIn and how connections are made by people connected to more people. The Movie database for this training does not have much depth of relationships, but it does have the :FOLLOWS relationship that you learned about earlier:
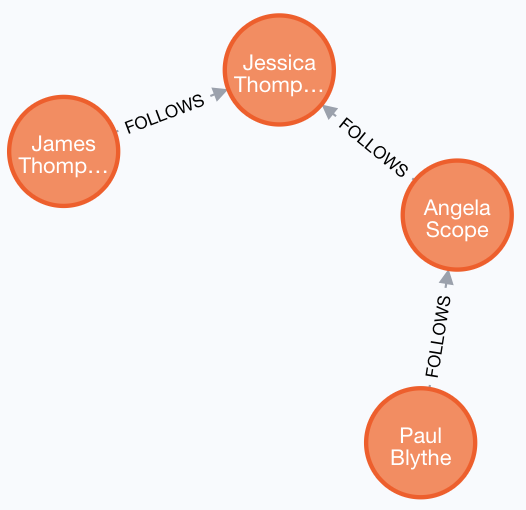
You write a MATCH clause where you want to find all of the followers of the followers of a Person by specifying a numeric value for the number of hops in the path.
Here is an example where we want to retrieve all Person nodes that are exactly two hops away:
MATCH (follower:Person)-[:FOLLOWS*2]->(p:Person)
WHERE follower.name = 'Paul Blythe'
RETURN p.nameHere is the result returned:
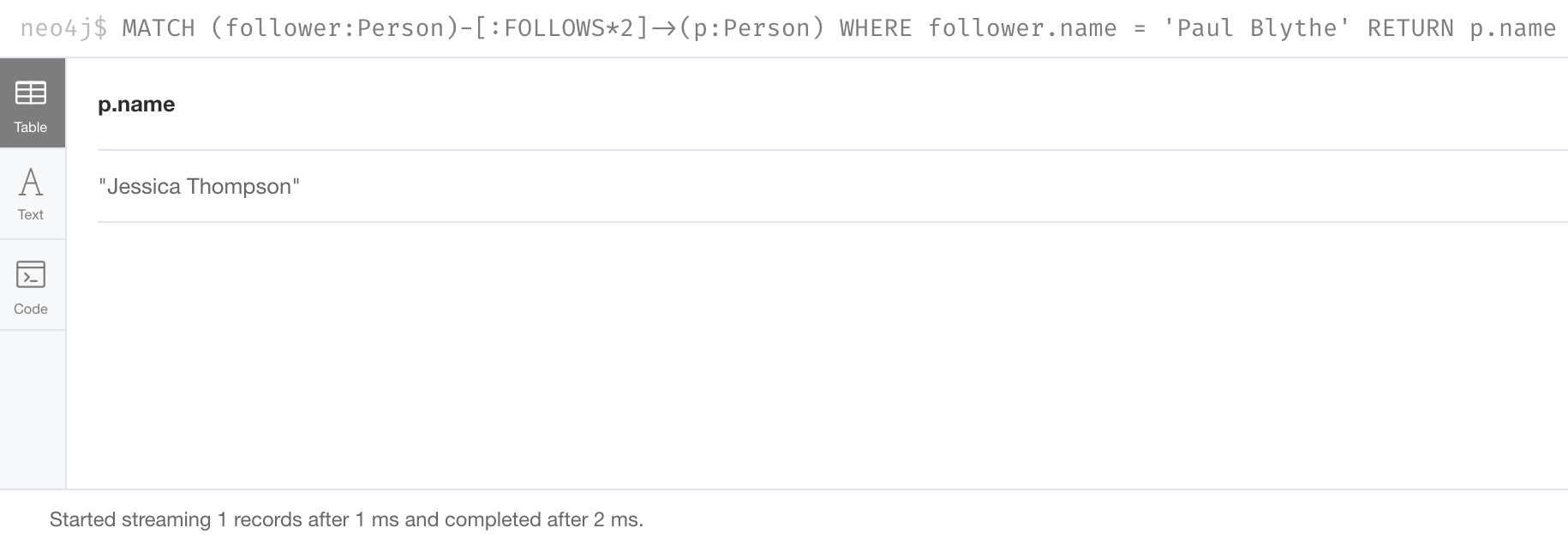
If we had specified [:FOLLOWS*] rather than [:FOLLOWS*2], the query would return all Person nodes that are in the :FOLLOWS path from Paul Blythe.
Syntax: Varying length patterns - 1
Here are simplified syntax examples for how varying length patterns are specified in Cypher:
Retrieve all paths of any length with the relationship, :RELTYPE from nodeA to nodeB and beyond:
(nodeA)-[:RELTYPE*]->(nodeB)Retrieve all paths of any length with the relationship, :RELTYPE from nodeA to nodeB or from nodeB to nodeA and beyond. This is usually a very expensive query so you place limits on how many nodes are retrieved:
(nodeA)-[:RELTYPE*]-(nodeB)Syntax: Varying length patterns - 2
Retrieve the paths of length 3 with the relationship, :RELTYPE from nodeA to nodeB:
(nodeA)-[:RELTYPE*3]->(nodeB)Retrieve the paths of lengths 1, 2, or 3 with the relationship, :RELTYPE from nodeA to nodeB, nodeB to nodeC, as well as, nodeC to nodeD) (up to three hops):
(nodeA)-[:RELTYPE*1..3]->(nodeB)Finding the shortest path
A built-in function that you may find useful in a graph that has many ways of traversing the graph to get to the same node is the shortestPath() function. Using the shortest path between two nodes improves the performance of the query.
In this example, we want to discover a shortest path between the movies The Matrix and A Few Good Men. In our MATCH clause, we set the variable p to the result of calling shortestPath(), and then return p. In the call to shortestPath(), notice that we specify * for the relationship. This means any relationship; for the traversal.
MATCH p = shortestPath((m1:Movie)-[*]-(m2:Movie))
WHERE m1.title = 'A Few Good Men' AND
m2.title = 'The Matrix'
RETURN pWhen you specify this MATCH clause to use the shortestPath() function as shown here with an unbounded varying length, you will see this warning:
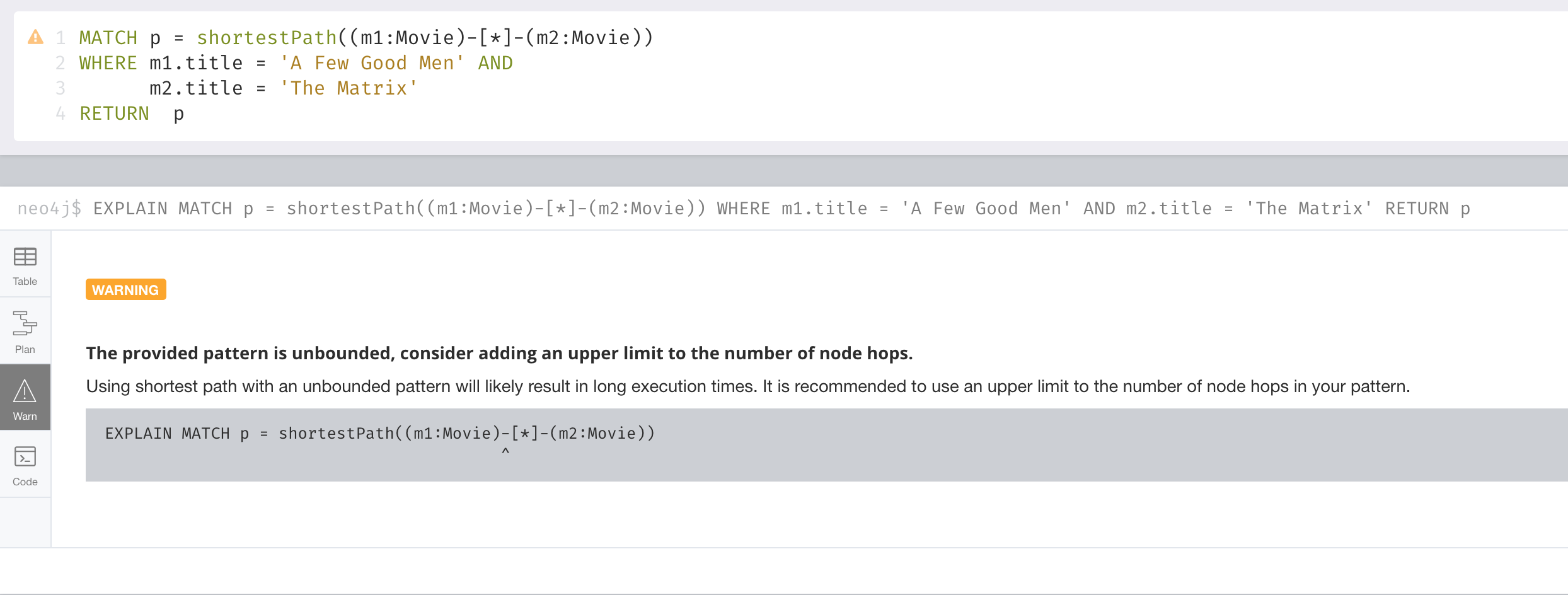
You must heed the warning, especially for large graphs. You can also read the Graph Data Science documentation about the shortest path algorithm, which performs even better than the one that is build into Cypher.
Here is the result returned:

Notice that the graph engine has traversed many types of relationships to get to the end node.
When you use shortestPath(), you can specify a upper limits for the shortest path. In addition, aim to provide the patterns for the from and to nodes that execute efficiently. For example, use labels and indexes.
Returning a subgraph
In using shortestPath(), the return type is a path. A subgraph is essentially a set of paths derived from your MATCH clause.
For example, here is an example where we want a subgraph of all nodes connected to the movie, The Replacements:
MATCH paths = (m:Movie)--(p:Person)
WHERE m.title = 'The Replacements'
RETURN pathsIf in Neo4j Browser where have unset Connect result nodes, the result is visualized as a graph because the query has returned a set of paths which are a subgraph.
Here is the result of this query:
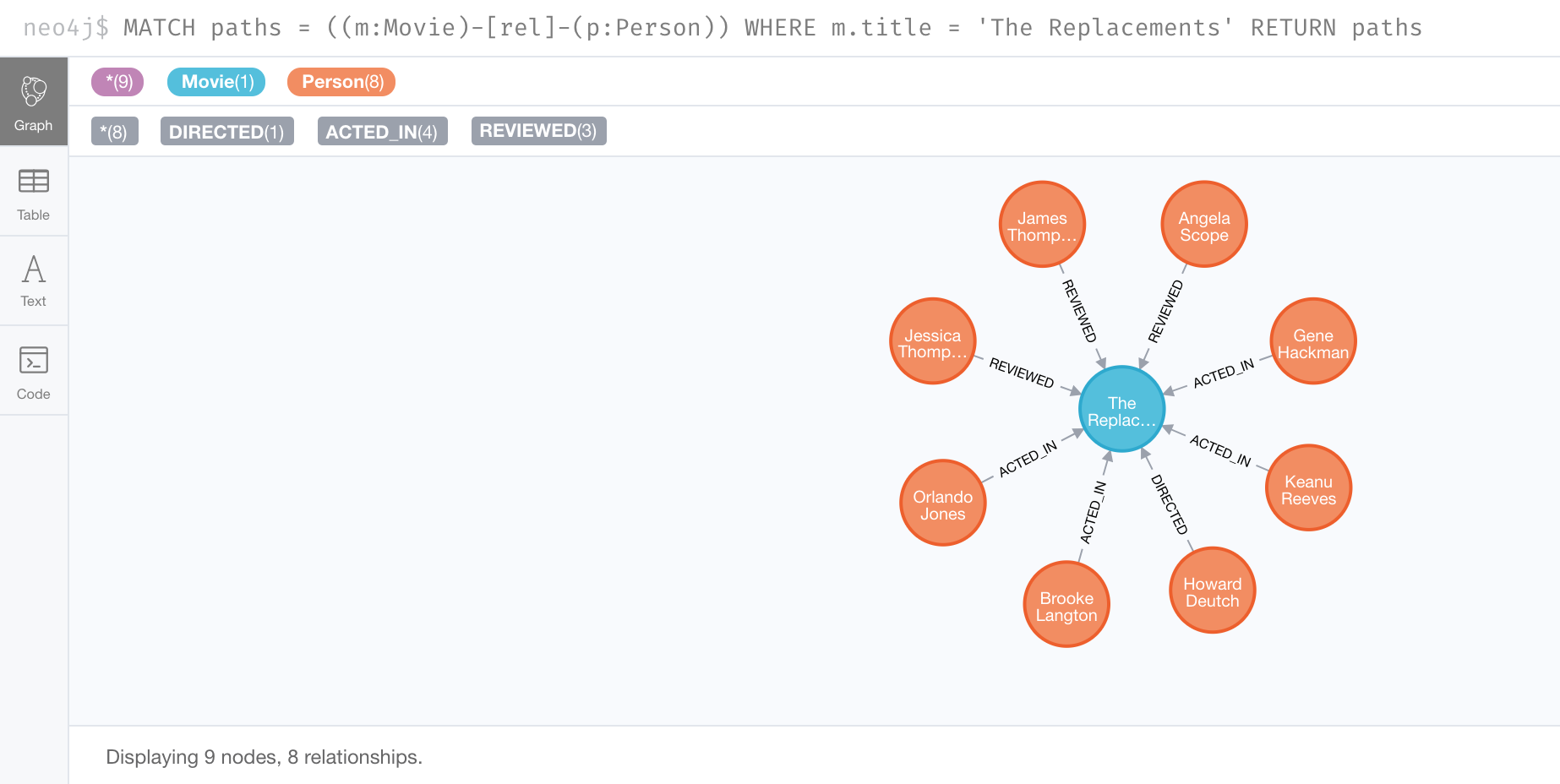
If you view the result as text, you will see that it is simply a set of rows where a movie is connected to a person:
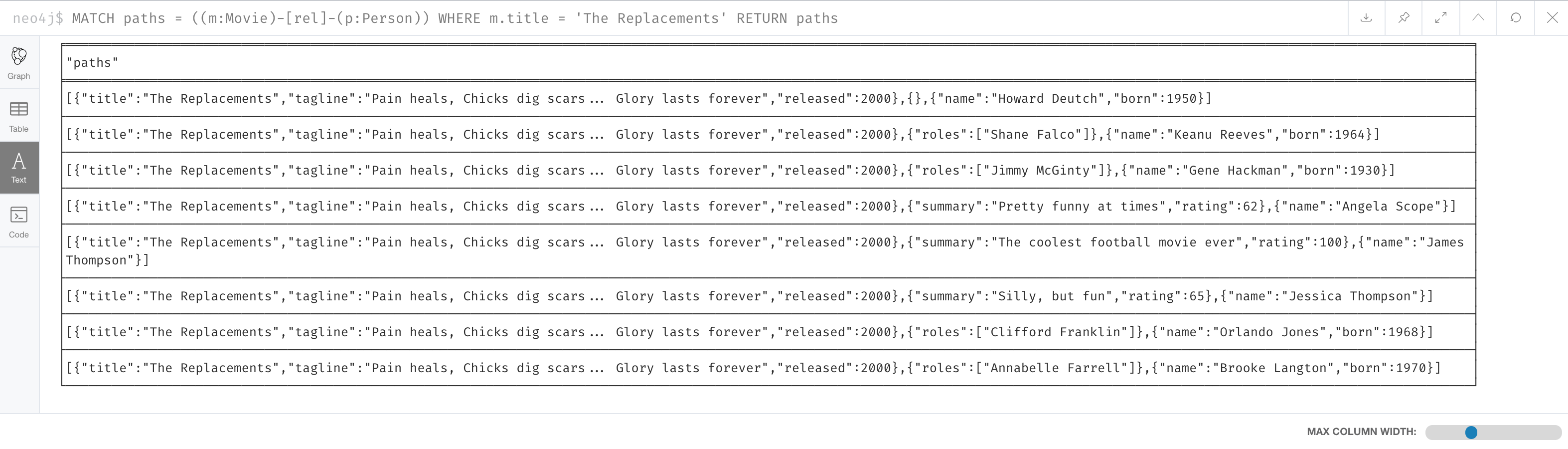
Some actor relationships have data for the roles property or summary property of the relationship. Note that in this text, the name of the relationship is not shown, but it is in the graph visualization. Later in this course, you will learn more about working with lists, which is what this data represents.
The APOC library is very useful if you want to query the graph to obtain subgraphs.
Specifying optional pattern matching
OPTIONAL MATCH matches patterns with your graph, just like MATCH does.
The difference is that if no matches are found, OPTIONAL MATCH will use nulls for missing parts of the pattern.
OPTIONAL MATCH could be considered the Cypher equivalent of the outer join in SQL.
Here is a subgraph of our movies graph with all people named James and their relationships:
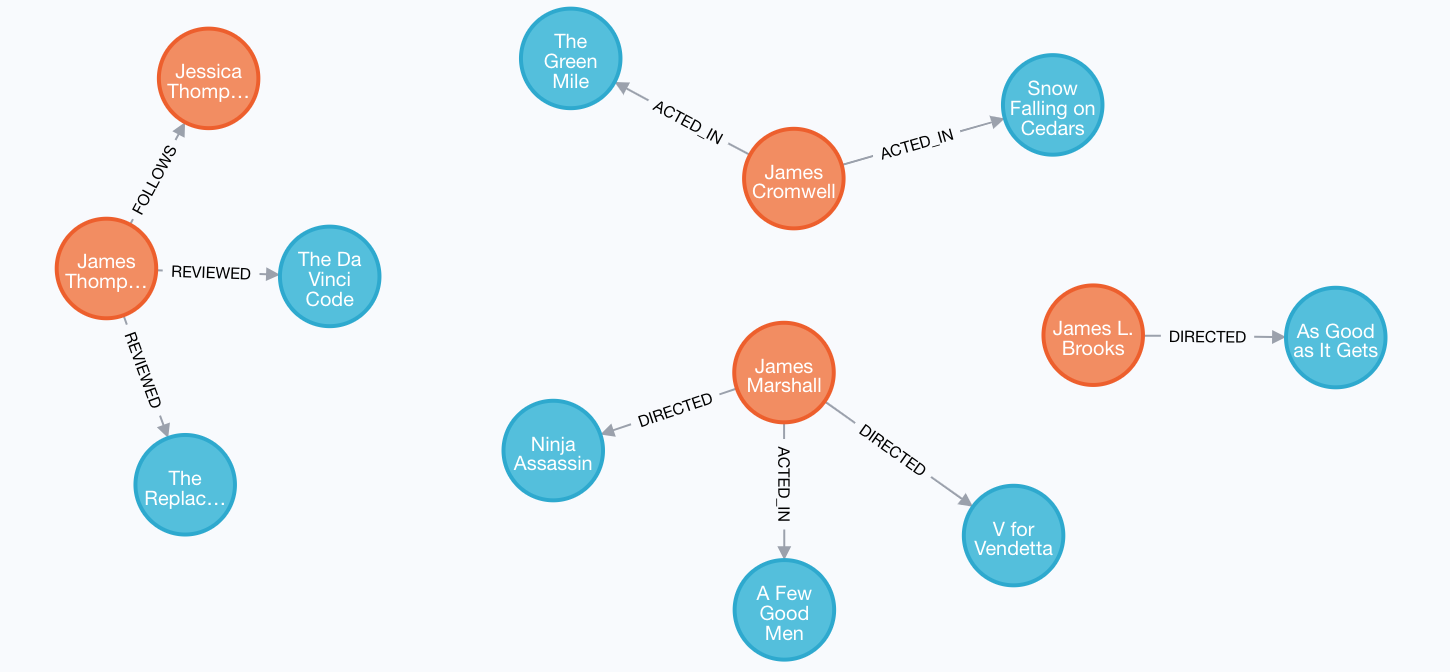
Here is an example where we query the graph for all people whose name starts with James.
The OPTIONAL MATCH is specified to include people who have reviewed movies:
MATCH (p:Person)
WHERE p.name STARTS WITH 'James'
OPTIONAL MATCH (p)-[r:REVIEWED]->(m:Movie)
RETURN p.name, type(r), m.titleHere is the result returned:

Notice that for all rows that do not have the :REVIEWED relationship, a null value is returned for the movie part of the query, as well as the relationship.
Exercise 5: Working with patterns in queries
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 5.
| This exercise has 6 steps. Estimated time to complete: 30 minutes. |
Check your understanding
Question 1
Given this Cypher query:
MATCH (follower:Person)-[:FOLLOWS]->(reviewer:Person)-[:REVIEWED]->(m:Movie)
WHERE m.title = 'The Replacements' RETURN follower.name, reviewer.nameWhat is the first node that is retrieved by the query engine?
Select the correct answer.
-
The first Person node with a FOLLOWS relationship
-
The first Person node with a REVIEWED relationship
-
The Movie node for the movie, The Replacements
-
The first Movie node in the alphabetical list of movies in the graph
Question 2
We want a query that returns a list of people who acted in movies released later than 2005 and for those movies, also return title and released year of the movie, as well as the name of the writer. How can you correct this query?
MATCH (a:Person)-[:ACTED_IN]->(m:Movie)
(m)<-[:WROTE]-(w:Person)
WHERE m.released > 2005
RETURN a.name, m.title, m.released, w.nameSelect the correct answers.
-
The second line must be:
(m2:Movie)←[:WROTE]-(w:Person). -
Add a comma after the first pattern in the
MATCHclause. -
The second line must be:
(m2:Movie)←[:WROTE]-(a). -
Add a
MATCHclause at the beginning of the second line.
Question 3
Suppose you have a graph of Person nodes representing a social network graph.
A Person node can have an IS_FRIENDS_WITH relationship with any other Person node.
Like in Facebook, there can be a long path of connections between people.
What Cypher MATCH clause would you use to find all people in this graph that are two to four hops away from each other?
Select the correct answer.
-
MATCH (p:Person)-[:IS_FRIENDS_WITH*2..4]→(p2:Person) -
MATCH (p:Person)-[:IS_FRIENDS_WITH*2-4]→(p2:Person) -
MATCH (p:Person)-[:IS_FRIENDS_WITH,2-4]→(p2:Person) -
MATCH (p:Person)-[:IS_FRIENDS_WITH,2,4]→(p2:Person)
Summary
You can now write Cypher statements to:
-
Specify multiple
MATCHpatterns. -
Specify multiple
MATCHclauses. -
Specify varying length paths.
-
Return a subgraph.
-
Specify
OPTIONALin a query.
Need help? Ask in the Neo4j Community