LangChain Neo4j Integration
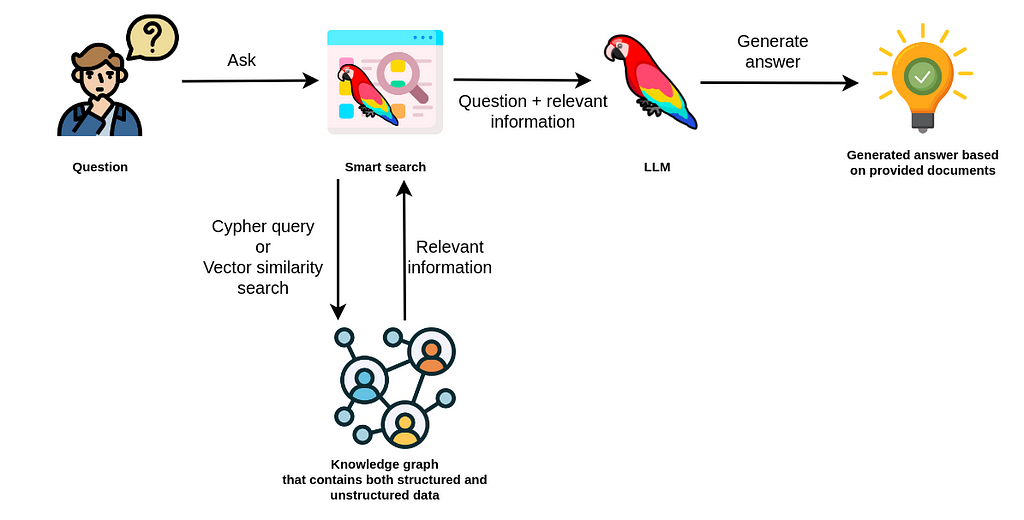
LangChain is a vast library for GenAI orchestration, it supports numerous LLMs, vector stores, document loaders and agents. It manages templates, composes components into chains and supports monitoring and observability.
The broad and deep Neo4j integration allows for vector search, cypher generation and database querying and knowledge graph construction.
Here is an overview of the Graph Integrations.
| When upgrading to LangChain 0.1.0+ make sure to read this article: Updating GraphAcademy Neo4j & LLM Courses to Langchain v0.1. |

Installation
pip install langchain langchain-community langchain-neo4j
# pip install langchain-openai tiktoken
# pip install neo4jFunctionality Includes
Neo4jVector
The Neo4j Vector integration supports a number of operations
-
create vector from langchain documents
-
query vector
-
query vector with additional graph retrieval Cypher query
-
construct vector instance from existing graph data
-
hybrid search
-
metadata filtering
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, embeddings, url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)Hybrid Search
Hybrid search combines vector search with fulltext search with re-ranking and de-duplication of the results.
from langchain.docstore.document import Document
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
loader = TextLoader("../../modules/state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
# The Neo4jVector Module will connect to Neo4j and create a vector index if needed.
db = Neo4jVector.from_documents(
docs, embeddings, url=url, username=username, password=password,
search_type="hybrid"
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=2)Metadata filtering
Metadata filtering enhances vector search by allowing searches to be refined based on specific node properties. This integrated approach ensures more precise and relevant search results by leveraging both the vector similarities and the contextual attributes of the nodes.
db = Neo4jVector.from_documents(
docs,
OpenAIEmbeddings(),
url=url, username=username, password=password
)
query = "What did the president say about Ketanji Brown Jackson"
filter = {"name": {"$eq": "adam"}}
docs = db.similarity_search(query, filter=filter)Neo4j Graph
The Neo4j Graph integration is a wrapper for the Neo4j Python driver. It allows querying and updating the Neo4j database in a simplified manner from LangChain. Many integrations allow you to use the Neo4j Graph as a source of data for LangChain.
from langchain_neo4j import Neo4jGraph
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
QUERY = """
MATCH (m:Movie)-[:IN_GENRE]->(:Genre {name: $genre})
RETURN m.title, m.plot
ORDER BY m.imdbRating DESC LIMIT 5
"""
graph.query(QUERY, params={"genre": "action"})CypherQAChain
The CypherQAChain is a LangChain component that allows you to interact with a Neo4j graph database in natural language. Using an LLM and the graph schema it translates the user question into a Cypher query, executes it against the graph and uses the returned context information and the original question with a second LLM to generate a natural language response.
# pip install --upgrade --quiet langchain
# pip install --upgrade --quiet langchain-openai
from langchain_neo4j import Neo4jGraph, GraphCypherQAChain
from langchain_openai import ChatOpenAI
graph = Neo4jGraph(url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)
# Insert some movie data
graph.query(
"""
MERGE (m:Movie {title:'Top Gun'})
WITH m
UNWIND ['Tom Cruise', 'Val Kilmer', 'Anthony Edwards', 'Meg Ryan'] AS actor
MERGE (a:Actor {name:actor})
MERGE (a)-[:ACTED_IN]->(m)
"""
)
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature=0), graph=graph, verbose=True,
allow_dangerous_requests=True
)
chain.run("Who acted in Top Gun?")Advanced RAG Strategies
Besides the basic RAG strategy, the Neo4j Integration in LangChain supports advanced RAG strategies that allow for more complex retrieval strategies. These are also available as LangChain Templates.
-
regular rag - direct vector search
-
parent - child retriever that links embedded chunks representing specific concepts to parent documents
-
hypothetical questions - generate questions from the document chunks and vector index those to have better matching candidates for user questions
-
summary - index summaries of the documents not the whole document
pip install -U "langchain-cli[serve]"
langchain app new my-app --package neo4j-advanced-rag
# update server.py to add the neo4j-advanced-rag template as an endpoint
cat <<EOF > server.py
from fastapi import FastAPI
from langserve import add_routes
from neo4j_advanced_rag import chain as neo4j_advanced_chain
app = FastAPI()
# Add this
add_routes(app, neo4j_advanced_chain, path="/neo4j-advanced-rag")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
EOF
langchain serve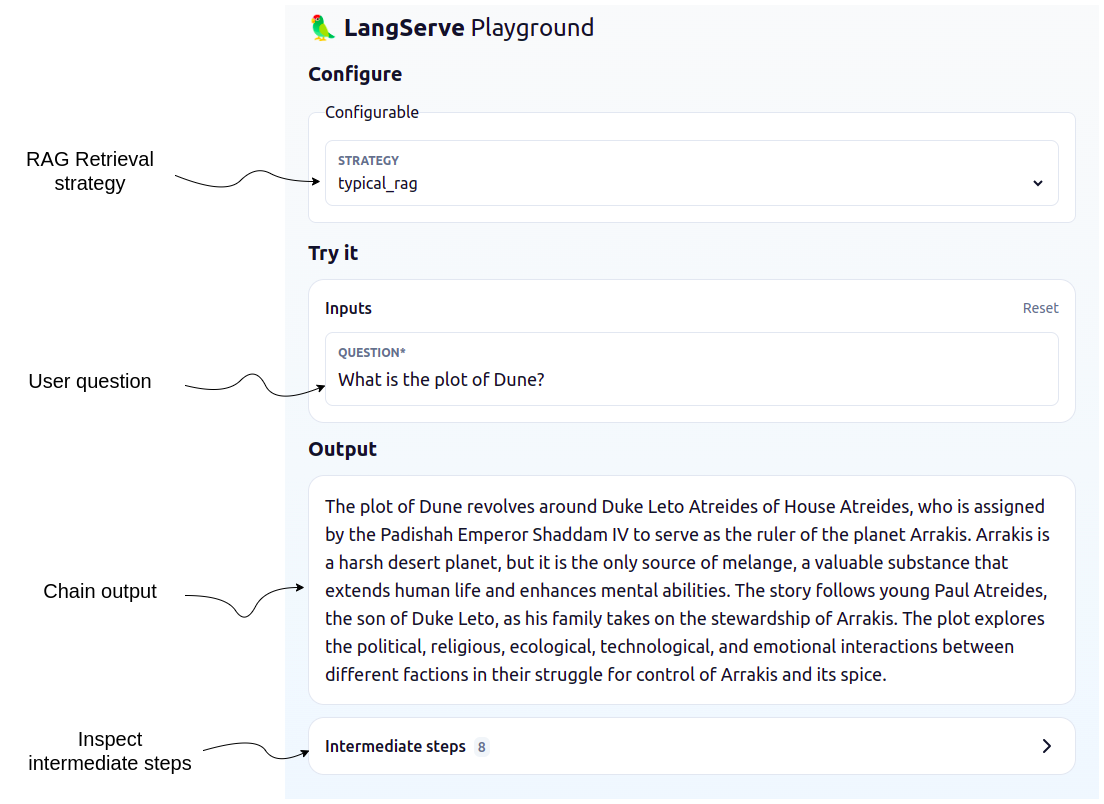
Semantic Layer
A semantic layer on top of a (graph) database doesn’t rely on automatic query generation but offers a number of APIs and tools to give the LLM access to the database and it’s structures.
Unlike automatically generated queries, these tools are safe to use as they are implemented using correct queries and interactions and only take parameters from the LLM.
Many cloud (llm) providers offer similar integrations either via function calling (OpenAI, Anthropic) or extensions (Google Vertex AI, AWS Bedrock).
Examples for such tools or functions include:
-
retrieve entities with certain names
-
retrieve the neighbors of a node
-
retrieve a shortest path between two nodes
-
Enhancing Interaction Between Language Models and Graph Databases via a Semantic Layer
Conversational Memory
Storing the conversation, i.e. the flow of questions and answers of user sessions in a graph allows you to analyze the conversation history and use it to improve the user experience.
You can index embeddings for and link questions and answers back to the retrieved chunks and entities in the graph and use user feedback to re-rank those inputs for future similar questions.
Knowledge Graph Construction
Creating a Knowledge Graph from unstructured data like PDF documents used to be a complex and time-consuming task that required training and using dedicated, large NLP models.
The Graph Transformers are tools that allows you to extract structured data from unstructured documents and transform it into a Knowledge Graph.
| You can see a practical application, code and demo for extracting knowledge graphs from PDFs, YouTube transcripts, wikipedia articles and more with the LLM Graph Builder. |
Starter Kit
This starter-kit demonstrates how to run a FastAPI server using LangChain to answer queries on data stored in a Neo4j instance. The single endpoint can be used to retrieve answers using either a Vector index chain, GraphCypherQA Chain, or a composite answer of both. The langserve branch contains an example of the same service, using LangServe
See this Developer Blog Article for additional details and instructions on working with the Starter Kit.
Agent Integration
For using LangChain and LangGraph as agent frameworks with Neo4j — including MCP integration, custom tools, checkpoint savers, and multi-agent workflows — see:
Relevant Links
Authors |
|
Community Support |
|
LangChain Repository |
|
LangChain Issues |
|
LangChain Neo4j Repository |
|
LangChain Neo4j API Docs |
|
LangChain Neo4j Issues |
|
Documentation |
|
Documentation |
|
Starter Kit |
|
Juypter |