
Couchbase & JDBC Integrations for Neo4j 3.x

Founder & CEO, LARUS Business Automation
2 min read
Editor’s Note: This presentation was given by Lorenzo Speranzoni at GraphConnect Europe in April 2016. Here’s a quick review of what he covered:
–
What we’re going to be talking about today is the connector
(LARUS)-[:PARTNERS_WITH]->(Neo4j)
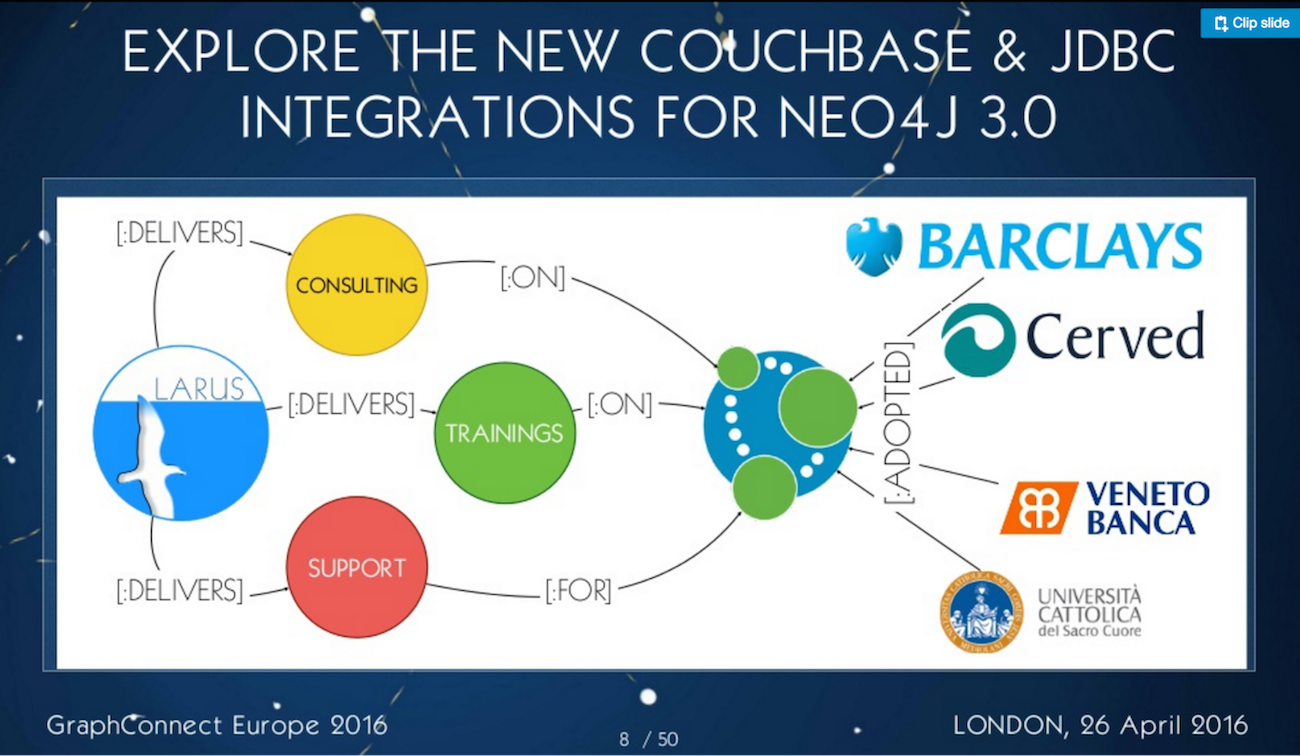
LARUS has been a Neo4j partner since 2015. We’re based in Venice, Italy and provide consultancy and training. The company was founded in 2011 when Neo4j was only in the first version of its release.
At the time, we were working for a retail company and the goal was to arrange all the articles and clusters of articles inside a graph database. That’s right about the time we met with
In 2015, we decided to become a Neo4j solution partner, and last year we started the process to become Neo4j certified as well.
We work with a variety of companies throughout Italy:
We offer services to a company that ran an interesting POC for Barclays to provide fraud detection. Cerved, one of the early adopters of Neo4j, uses the graph database to store its entire business network to so that it can easily find the owner of a company by surfing their graph. There’s an real-time recommendation engine of that content.
Converting JSON to Nodes
So what about the Couchbase connector? To make the tool as effective as possible, the two most important features we included were bi-directional relationships and configurable connectors.
The first step for building such a tool involved figuring out how to transform JSON into a graph. There are a number of papers on this topic, one of which was published by William Lyon for MongoDB, that provides instructions for this conversion.
Let’s review a case study using Spotify, which has an interesting API. Below is a typical album representation as JSON:

Each album has tracks; in this particular album, there are 11. Below is an array of these tracks, each of which includes all the relevant information for the individual tracks:

How can we convert this data into a graph?
In general, the basic strategy is this one: You can copy primitive articles like strings or numbers inside the nodes. We create an album node and all the primitives and arrays of primitive attributes becomes properties inside the node:

Things become a bit more complex with nested objects, such as an artist. The general idea is that nested objects become connected nodes. We create a relationships to the album and copy all of the artist information with the same strategy outlined above:
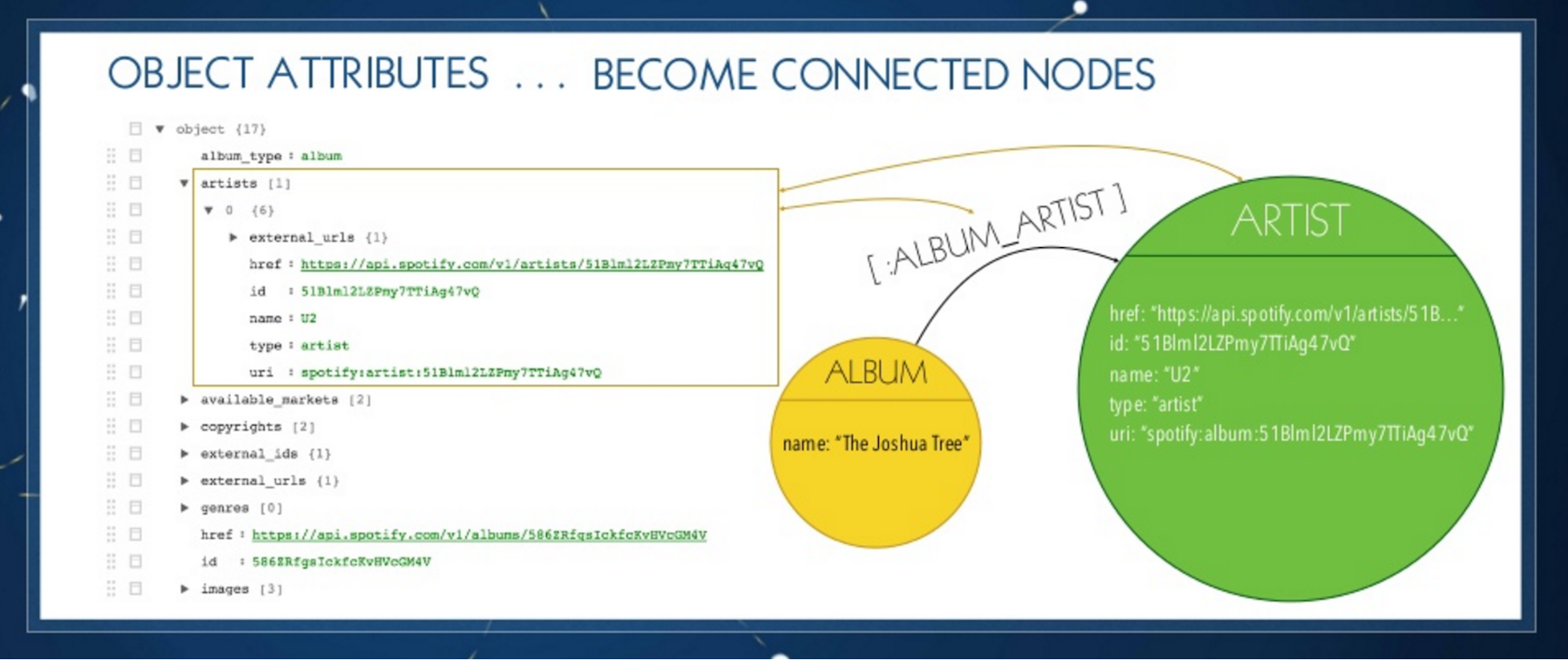
We can also have an array of objects as attributes that become items in the form of a list of connected nodes. The JSON becomes an album with an artist, and the album has tracks:

Architecture of the Couchbase Integration
The Couchbase connector architecture is based on four main components:

The Couchbase listener (1) listens for documents that are either changed or created inside Couchbase. This listener then transfers the mutated document inside the graph through our Neo4j server extension, which is a JSON loader (2) that can actually load JSON coming from any source. (We separated the two projects, which you can now find in our own GitHub repository.) We have another server extension, Neo4j Mutation Listener (3), that looks for changes to nodes and relationships and reconstructs them in Neo4j. The Neo4j JSON loader (4) transfers the JSON to Neo4j through the Couchbase software development kit (SDK) tools.
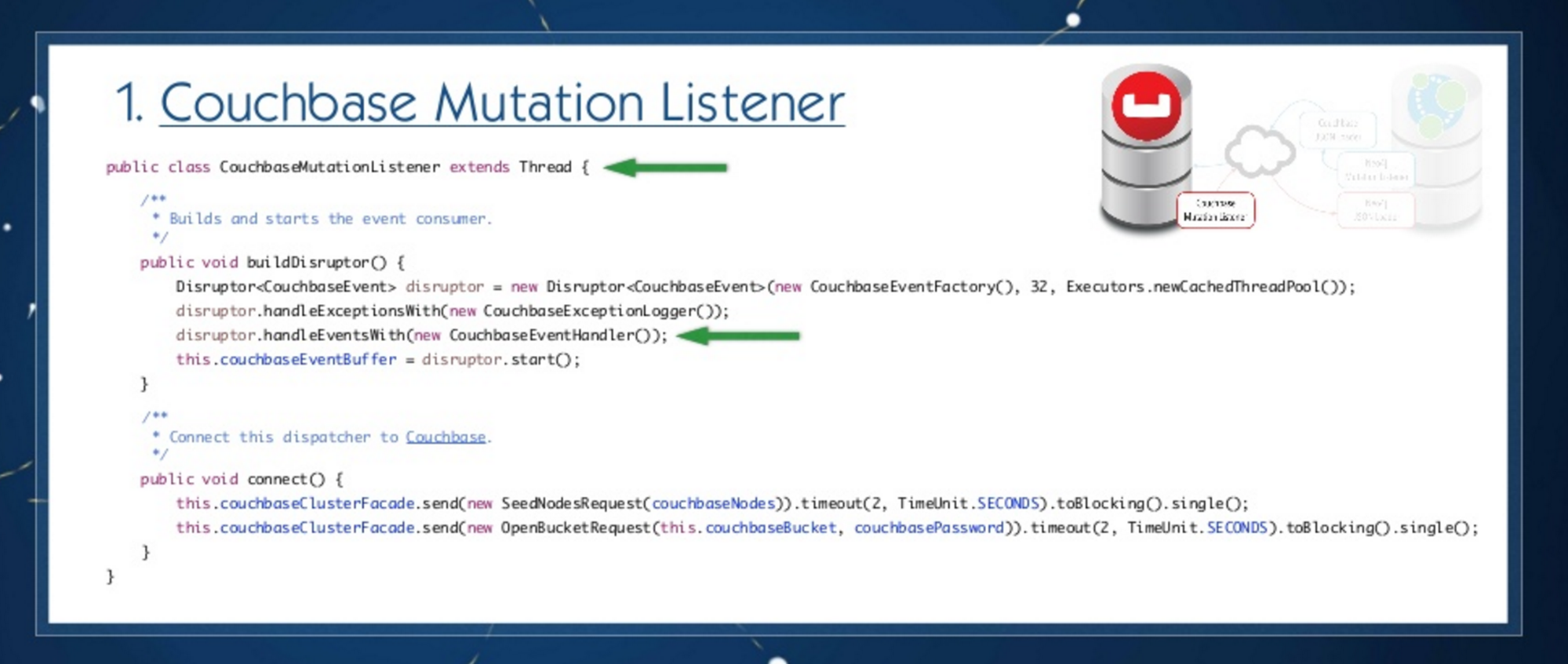
1. Couchbase Mutation Listener
To start, we have an event which wraps a message and then we filter this kind of event so that we only receive mutation messages. Those are all classes coming from the software development kit that I mentioned before. Then we implement an event handler that only accepts mutation events, and then send that through our remote Neo4j transformer, the JSON loader:

We then have to register the listener by implementing a disruptor. This is done by attaching an event handler and sending the mutated documents to Neo4j:
2. The JSON Loader
The JSON loader is also configurable, and in the future we would like to introduce the stored procedures that are now included in Neo4j 3.0. At this point we have enriched the original content, which is in JSON, and we are trying to get more information from it. We train the translator with a specific approach, add a domain descriptor and set it to instruct the JSON loader:

There’s a REST API that published a connector and accepted the JSON that we just provided:

And we have a transformer that translates the JSON document into a Cypher statement, which is then executed inside the transaction:

3. The Neo4j Mutation Listener
The Neo4j Mutation Listener is implemented as a Neo4j transaction event handler; after a commit happens, the state of Neo4j is changed. We reconstruct the JSON document through subqueries and then send the mutated documents back through our Couchbase JSON loader:

4. Couchbase JSON Loader
Those are Couchbase classes we attach to the cluster in the specific bucket, and then we run an upstart which is used to transfer and update the JSON document:

The Domain
But what about the domain? How can we instruct the domain — the JSON loader — about how our business domain is configured and then match this within Neo4j?
Below is a look inside the JSON document from Spotify. Even if information is aggregated inside a document database, we need to be able to identify something as an album. Now each album and individual track has a universal ID that identifies it. We can then use this ID to find a node that exists inside the database and assign a label name:
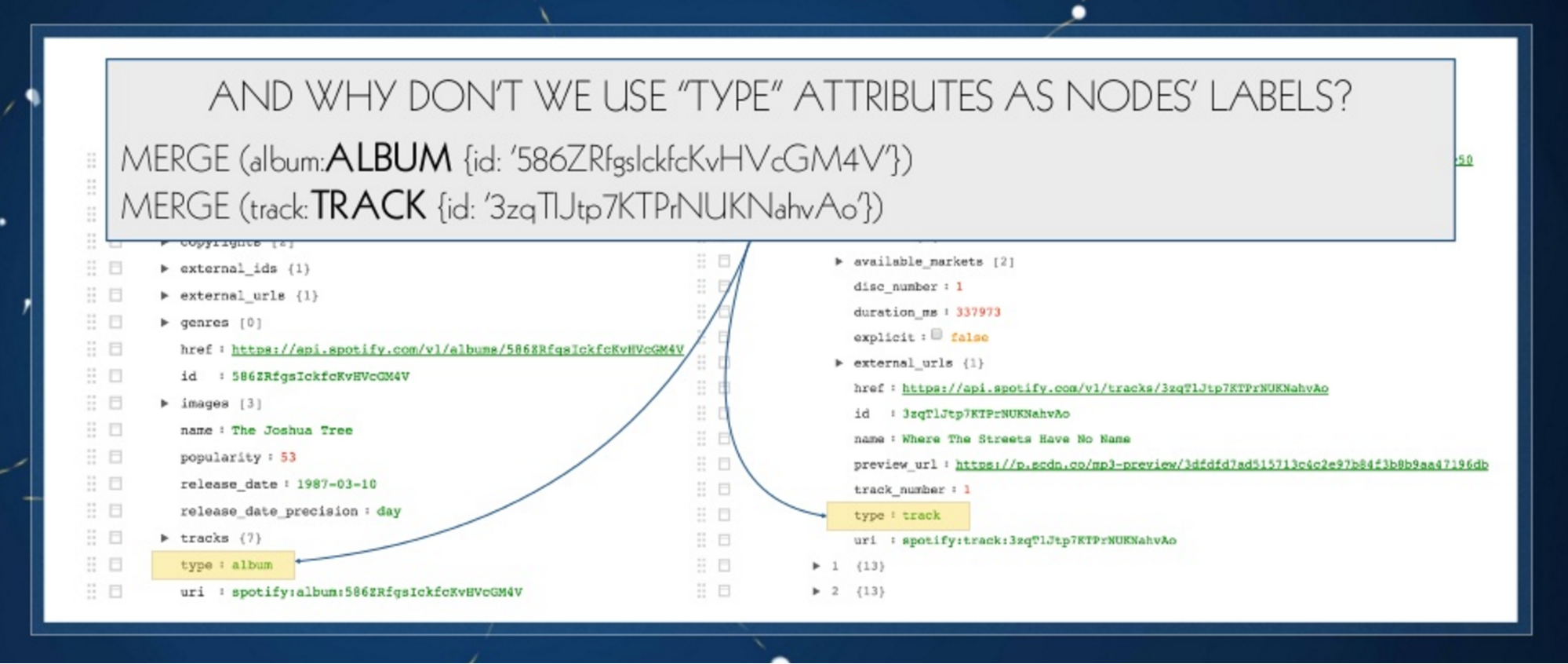
At this point, we have introduced a way to describe the domain and added a JSON descriptor. The album domain object is now uniquely identified by the ID property. With this set of information, we enrich the original JSON document by saying, “Okay, this is an album, the type and the unique key that Couchbase assigns whenever you store a new document inside of it.”

The resulting query that we create translates the JSON into a big Cypher statement. MERGE album ID is the simple part, because we already told the JSON loader that the ID is the unique key, and then we have the set of information that was updated for this node.

Below is the resulting graph for the U2 album Joshua Tree:

The domain-driven transformer allows you to reuse “U2” and all other nodes so that you can get the real benefit from relationships. If you have to create different nodes every time you load JSON, you can’t make use of relationships to build a recommendation engine on top of this:

The JDBC Driver and Bolt Protocol
The second thing we did was contribute to community drivers for Neo4j 3.0. Of course, as a Java company, we have this expertise so it was natural to start working on a standard JDBC interface.
Below is the team that developed the JDBC driver:

We have Stefan and Michael, both from Neo4j, who coordinated the development with the LARUS team. And we have Ralph, a friend from Germany who helped with testing and Benoit from Neo4j who worked on the ACTP protocol. Without them, we couldn’t have built a successful product.
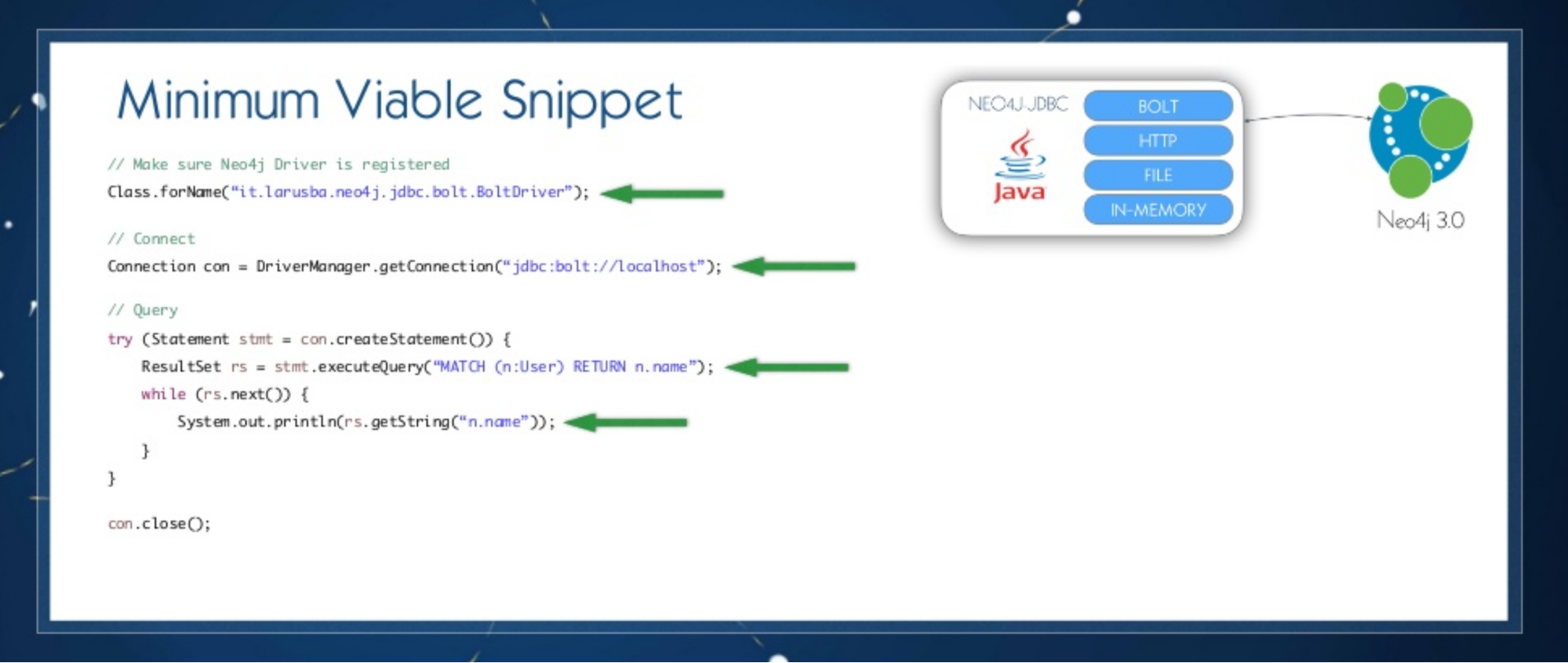
The driver took advantage of the new Bolt protocol in Neo4j 3.0. The tool has a modular design because it isn’t very fast; it’s quite heavy because of all the different ways in which you can interact with the database — HTTP, Bolt, in-memory, file — are merged into one module.
The idea is that you can decide which way to interact with the Neo4j, and you import just the specific part that you are interested in according to the application that you are developing. And finally, the product is heavily tested and is focused on performance.
The Bolt implementation is just a wrapper:

The Neo4j team recently produced a Java driver, which is the Bolt implementation of the driver.
A Java application can talk with Neo4j through a standard JDBC driver, making use of the Bolt protocol in that way. And then as I said, we have all the other models here. These will be implemented for retro-compatibility so that they can work across versions:

As I mentioned earlier, it’s heavily tested — we have 460 classes, almost 300 unit tests and 15 technician testers, so every single piece of code that we have implemented has lots of testing on top because so that you can use it in your production environment.
There are a number of performance issues with our old driver, which would take up to 30 minutes to import these CSV lines, while the new one takes closer to 17 minutes:

We’re happy with this performance, but are still doing performance testing. We’ve already tested it with all of the following tools, all of which use JDBC:

To do the testing, we load the driver and connect through a URL that is defined according to the protocol. Then we create a statement, execute a query, match user retort and of name, and then we cycle on the result set. In this case we just print the name of all the user nodes. After that, we close the connection:
Below is our timeline for release:
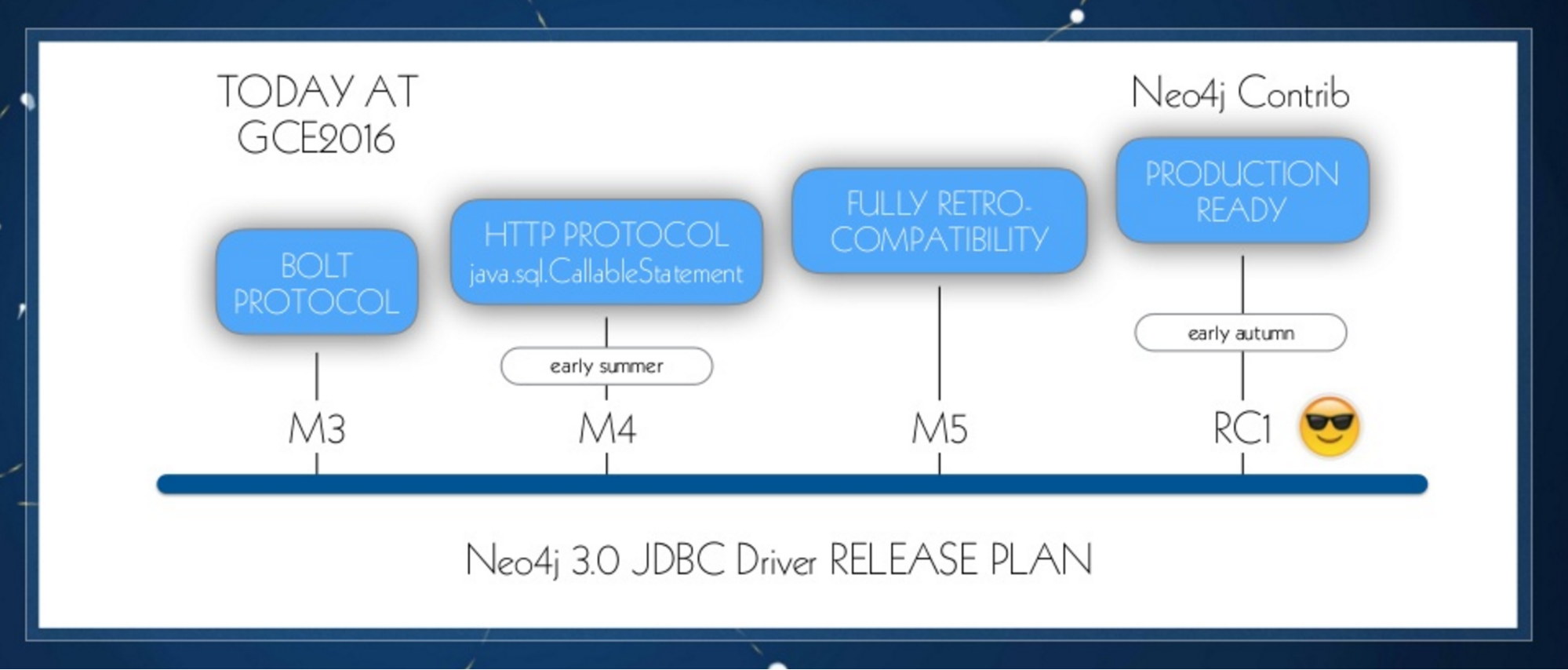
At GraphConnect Europe, we announced Milestone 3, which has the Bolt protocol. In Milestone 4 we will introduce the HTTP protocol and the Callable Statement so that we can make use of Neo4j’s new stored procedures. Then we will work on fully retro-compatible implementation for Milestone 5, and more or less in early autumn 2016 we would like to have a production-ready version of the software, which will probably be moved to the Neo4j contributor repository:
So have fun with us, please — we need the help, and there’s lots of work and fun things to do.
Take our online training class, Neo4j in Production, and learn how scale the world’s leading graph database to unprecedented levels.
Share Article



Explore
Related Articles

Text2Cypher Across Languages: Evaluating Foundational Models Beyond English




Integrating Neo4j With Symfony: Profiling Queries and Centralized Logging
