


Function Calling in Agentic Workflows

Consulting Engineer, Neo4j
11 min read
Learn how to effectively use function calling with LangChain, LangGraph, and Pydantic
Introduction
In this article, I walk through how to effectively use function calling in your GenAI applications using LangChain, LangGraph, and Pydantic. Function calling is a powerful method that allows LLMs to generate structured output that adheres to function names and arguments called in the code. This allows GenAI applications to be more than just chatbots, extending their capabilities to more advanced data retrieval methods and more interactive engagements.
I discuss function calling and how to achieved it using the OpenAI Chat Completions API and LangChain. Other LLM providers may have different methods of function calling, but conceptually, they should be the same.
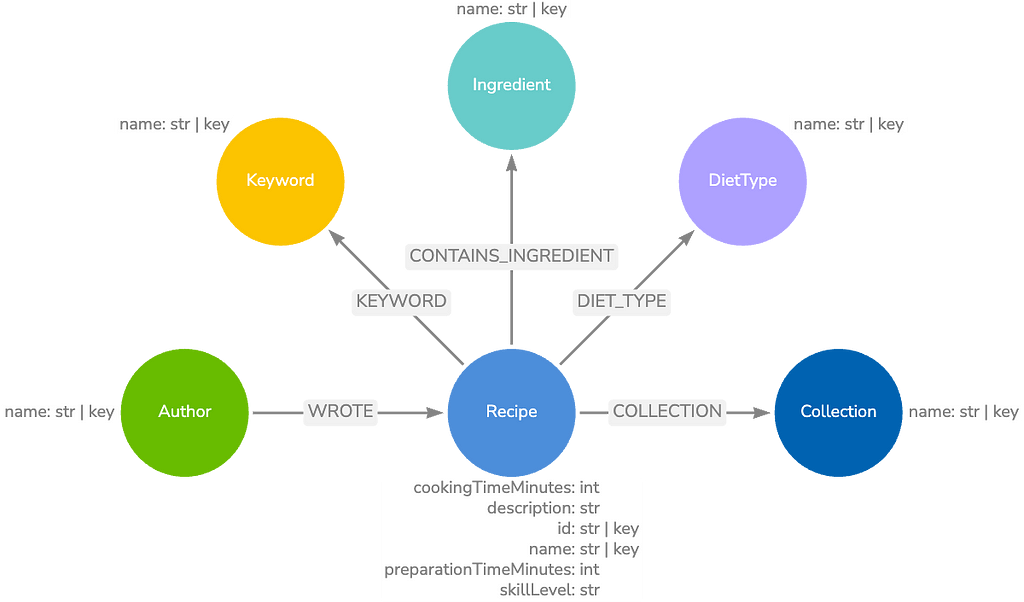
The example application here is a cooking assistant with access to a database of recipes and their authors. The article discusses the LangGraph workflow architecture, the various tools, and how to execute them. At the end, some example questions will demonstrate how this application uses different tools to solve problems.
This example application uses Neo4j as the underlying database. While the tools demonstrated here retrieve data from a Neo4j database via the Cypher query language, the concepts apply to LLM applications using any database.
The code is on GitHub, along with the example notebook.
Term Definitions
GenAI is rapidly evolving so there are some fuzzy definitions out there. The following terms will be used as defined below:
- Agent: A system that uses an LLM to decide which steps to take next
- Workflow: A system where LLMs and tools are orchestrated via predefined paths
- Agentic workflow: A system containing a mixture of predefined paths and agents
- GraphRAG: RAG that involves retrieving information from a graph database via graph traversals
- Retrieval-augmented generation (RAG): The process of gathering data from an external data source and providing it as context to an LLM for response generation
- Tool: A function the LLM is aware of and may call (the terms tool and function will be used interchangeably)
- Tool calling: Identical to function calling, this is the process of prompting an LLM to return structured output that contains a list of dictionaries, with each entry containing a function name and its arguments
Tech Stack
The concepts covered here aren’t constrained to this tech stack. However, please be aware that not all LLMs support function calling.
- LangChain: LLM interface
- LangGraph: LLM orchestration framework
- Neo4j: Graph database
- OpenAI: LLM provider
- Python
- Pydantic: Advanced type checking and validation for Python
Defining Tools
LangChain supports many ways of defining tools. A powerful method is via Pydantic classes. This allows you to explicitly define tool descriptions and arguments while providing validation checks. These same classes may then process and validate the returned tool call information. Below are some of the tools that the demo application has access to:
class text2cypher(BaseModel):
"""The default data retrieval tool. Use an LLM to generate a new Cypher query that satisfies the task."""
task: str = Field(..., description="The task the Cypher query must answer.")
class get_most_common_ingredients_an_author_uses(BaseModel):
"""Retrieve the most common ingredients a specific author uses in their recipes."""
author: str = Field(..., description="The full author name to search for.")
@field_validator("author")
def validate_author(cls, v: str) -> str:
return v.lower()Agentic Workflow Architecture
LangGraph orchestrates the agentic workflow in this example. Each node in the LangGraph workflow is a component that contains a process, while each edge represents the flow of information between these nodes. In this example, there are a few nodes to be aware of:
- Guardrails
- Planner
- Tool Selection
- Error Handling
- Predefined Cypher Executor
- Text2Cypher
- Summarize
- Final Answer

Although this article primarily focuses on function calling, there are some other features of this LangGraph workflow to be aware of.
The nodes between Planner and Summarize execute via a map-reduce operation where each found task maps to the Tool Selection node, and tool execution results reduce as a list to a state variable — in this case, cyphers. This allows each task to process in parallel, improving overall response times.
The Text2Cypher node is a subgraph treated as a node. This allows the Text2Cypher process to hold its own state easily and for it its modular inclusion in other agentic workflows.
Multi-tool agentic workflow construction code
Guardrails and Planner Nodes
The Guardrails node decides whether an incoming question is within the application’s scope. If not, a default message is provided, and the workflow routes to the final answer generation.
The Planner node receives a validated input question from the Guardrails node and identifies the tasks required to provide a satisfactory answer. These tasks can then process in parallel by the tool selection and execution steps.
Tool Selection Node
The Tool Selection node assigns a tool to an individual task. If the tool is Text2Cypher, the necessary state routes to the Text2Cypher subgraph. If the tool is a predefined Cypher query, the necessary state instead routes to the predefined Cypher Executor node. It’s also possible that no tool is selected. In this case, the node may default to Text2Cypher or route to an error-handling node, which will fail gracefully. Learn more about Cypher, the query language used by Neo4j.
Tool Nodes
There are many tools in this example, but only two methods of calling them. One is Text2Cypher, which will generate novel Cypher statements for questions that don’t match a pre-existing tool. This tool executes via the Text2Cypher subgraph detailed below. The other tools are prewritten parameterized Cypher queries, which take parameters extracted from the input task and run them via the predefined Cypher Executor node.
Predefined Cypher Executor
The predefined Cypher Executor is a node in our LangGraph agentic workflow. It’s responsible for running predefined Cypher queries with parameters found by the LLM. Each query represents a unique tool the LLM may use. This node will be responsible for executing the following tools:
- get_allergen_free_recipes
- get_most_common_ingredients_an_author_uses
- get_recipes_for_diet_restrictions
- get_easy_recipes
- get_mid_difficulty_recipes
- get_difficult_recipes
For example, if the LLM selects get_allergen_free_recipes as the tool, it will extract a list of allergens that it finds in the task text:
class get_allergen_free_recipes(BaseModel):
"""Retrieve a list of all recipes that do not contain the provided allergens."""
allergens: List[str] = Field(
..., description="A list of allergens that should be avoided in recipes."
)This list is injected into the predefined Cypher query via the $allergens parameter and execute against the Neo4j database to retrieve context for generating a final answer:
MATCH (r:Recipe)
WHERE none(i in $allergens WHERE exists(
(r)-[:CONTAINS_INGREDIENT]->(:Ingredient {name: i})))
RETURN r.name AS recipe,
[(r)-[:CONTAINS_INGREDIENT]->(i) | i.name]
AS ingredients
ORDER BY size(ingredients)
LIMIT 20Predefined Cypher Executor code
Text2Cypher
Text2Cypher is a subgraph in our LangGraph workflow, but it’s treated as a tool during the tool selection step. The LLM agent responsible for selecting a tool doesn’t need to know the details of Text2Cypher; it only needs to know what it can do and the inputs it requires. Abstracting away the subgraph details and function logic significantly reduces the tokens being processed by the LLM.

The details of Text2Cypher aren’t covered here, but more information is in the LangChain documentation that inspired this architecture and Effortless RAG With Text2CypherRetriever, written by Neo4j engineers.
Error-Handling Node
If the LLM request fails to return a tool during tool selection and there is no default tool, the application can route to an Error-Handling Node. In this example, it simply appends an empty dataset for the failed task, allowing the application to continue without interruption. This is at the cost of possibly missing the necessary context.
Tool Selection Error-Handling code
Summarize and Final Answer Nodes
The Summarize node is responsible for summarizing the retrieved data in an easily digestible format for the end user. The data processes in this node once all data has been retrieved asynchronously. This is then sent to the Final Answer node, which formats and returns the final answer along with executed queries and retrieved data.
Tools as Context
This section uses the OpenAI Chat Completions API to explain how tools are provided to LLMs as context alongside messages.
A typical LLM request may include a few message types:
- User → Contains the user question and some instructions
- System (Developer) → How the model should generally behave; these are provided before user messages
- Assistant → Any previous or example LLM responses
These messages pass to the messages argument of the OpenAI Chat Completions API as a list of Python dictionaries. Below is an example from the OpenAI documentation:
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "Write a haiku about recursion in programming."
}
]
)
print(completion.choices[0].message)See OpenAI’s text generation documentation for more information.
In order to pass functions as context to the LLM, they’re provided to the tools argument as a list of Python dictionaries. Below is another example from the OpenAI documentation:
from openai import OpenAI
client = OpenAI()
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
}
},
"required": [
"location"
],
"additionalProperties": False
},
"strict": True
}
}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "What is the weather like in Paris today?"}],
tools=tools # <-- Pass Functions / Tools here
)
print(completion.choices[0].message.tool_calls)See OpenAI’s function calling documentation for more information.
LangChain has an abstraction for this via the bind_tools() method on its LLM classes. This handles formatting the tools into Python dictionaries and passing them to the tools argument of the OpenAI Chat Completions API. Check out more examples of tool calling with LangChain.
Parsing Tool Responses
Remember that the functions in this example are defined using Pydantic classes. This allows you to easily validate the returned function calls using those same classes and capture any existing errors. These errors pass back to the LLM in a correction loop to fix the function call. It also enables easy post-processing of the results, such as casting all strings to lowercase or rounding numbers when appropriate.
LangChain provides an output parser that handles this called PydanticToolsParser. This parser allows for additional configuration, such as returning only the first tool in the list:
tool_selection_chain: Runnable[Dict[str, Any], Any] = (
tool_selection_prompt
| llm.bind_tools(tools=tool_schemas)
| PydanticToolsParser(tools=tool_schemas, first_tool_only=True)
)Data
This example application can access a Neo4j graph database containing information on BBC Good Food recipes. It’s an example dataset provided by Neo4j.

Demo
This agentic workflow is able to answer questions by using a predefined Cypher tool or Text2Cypher. It’s prompted to use predefined Cypher only if the tool description exactly matches what the task needs. Otherwise, it should choose Text2Cypher. Once all data is retrieved, it’s summarized and returned to the user.
This LangGraph agentic workflow outputs a response with the following fields. For the purposes of this demo, it’s not necessary to know the intermediate states within the workflow, but these output states are used to analyze the responses below.
class CypherOutputState(TypedDict):
task: str
statement: str
parameters: Optional[Dict[str, Any]]
errors: List[str]
records: List[Dict[str, Any]]
steps: List[str]
class OutputState(TypedDict):
"""The final output for multi agent workflows."""
answer: str
question: str
steps: List[str]
cyphers: List[CypherOutputState]Text2Cypher Only
This question doesn’t really match any of the predefined Cypher tools the LLM has at its disposal. Therefore, choose the Text2Cypher tool to address this question.
q1 = await agent.ainvoke(
{
"question": "How many authors have written a recipe?"
},
)The LLM returns:
**303 authors have written a recipe.**The workflow steps reveal that Text2Cypher was used to answer this question:
[
'guardrails',
'planner',
'tool_selection',
'generate_cypher', # <-- Begin Text2Cypher
'validate_cypher',
'execute_cypher',
'text2cypher', # <-- Text2Cypher Complete
'summarize',
'final_answer'
]Predefined Cypher Only
This question is answered by executing one of the predefined Cypher tools. The LLM chooses the appropriate tool based on the Pydantic class representations defined above:
q2 = await agent.ainvoke(
{"question": "What ingredients does Emma Lewis like to use most?"}
)The LLM returns:
- **Olive oil**: 39 recipes
- **Butter**: 37 recipes
- **Garlic clove**: 29 recipes
- **Onion**: 24 recipes
- **Egg**: 21 recipes
- **Lemon**: 21 recipes
- **Vegetable oil**: 18 recipes
- **Plain flour**: 15 recipes
- **Caster sugar**: 13 recipes
- **Thyme**: 11 recipesThe workflow steps validate that a predefined Cypher tool was used:
[
'guardrails',
'planner',
'tool_selection',
'execute_predefined_cypher', # <-- Predefined Cypher Tool
'summarize',
'final_answer'
]The Cypher query may also be viewed since it is returned in the response object:
What are the most frequently used ingredients by Emma Lewis?
MATCH (:Author {name: $author})-[:WROTE]->(:Recipe)-[:CONTAINS_INGREDIENT]->(i:Ingredient)
RETURN i.name as name, COUNT(*) as numRecipes
ORDER BY numRecipes DESC
LIMIT 10
Parameters:
{'author': 'emma lewis'}Text2Cypher and Predefined Cypher
This question contains two independent tasks. One may be solved with a predefined Cypher tool, while the other will require Text2Cypher. Since the Planner node routes tasks asynchronously, the application can execute these tools in parallel:
q3 = await agent.ainvoke(
{
"question": "What are some easy recipes I can make? Also can you share how many ingredients you know about?"
},
)The LLM returns:
- **Apricot & Pistachio Frangipane Blondies**
- **Camomile Tea with Honey**
- **Pastry Snakes**
- **Quick Banana Ice Cream Sandwiches**
- **Red Onion with Peanut Butter & Chilli**
I know about 3068 ingredients.Once again, the workflow steps validate the expected tools were used:
[
'guardrails',
'planner',
'tool_selection',
'execute_predefined_cypher', # <-- Predefined Cypher Executor
'generate_cypher', # <-- # Begin Text2Cypher
'validate_cypher',
'execute_cypher',
'text2cypher', # <-- Text2Cypher Complete
'summarize',
'final_answer'
]Although the steps above appear serially, remember that steps between planner and summarize are executed in parallel.
The application also stores the tasks with their Cypher queries and parameters. This may be used as additional validation.
# The Predefined Cypher Task
What are some easy recipes I can make?
MATCH (r:Recipe {skillLevel: "easy"})
RETURN r.name as name
LIMIT $number_of_recipes
Parameters:
{'number_of_recipes': 5} # This parameter was identified by the LLM
# The Text2Cypher Task
How many ingredients do you know about?
MATCH (i:Ingredient)
RETURN count(i) AS numberOfIngredients
Parameters: # No parameters are needed here
NoneSummary
Function calling is a powerful tool that allows LLMs to greatly expand their capabilities. This article demonstrated using two different types of tools to retrieve data from Neo4j, but tools can cover a wide range of functionality. For example, they may allow access to a variety of databases or make API requests. Pydantic models can define these tools and validate their outputs, allowing for more predictable responses.
While this article focuses on using LangChain and Pydantic to handle tool calling, there are various ways to achieve this, and it may be done simply by using the LLM provider’s API.
Resources
- GitHub Repo
- LangChain: Build a Question Answering Application Over a Graph Database
- Anthropic: Building Effective Agents
- LangChain: How to Use Subgraphs
- Neo4j: Effortless RAG with Text2CypherRetriever
- LangChain: How to Use Chat Models to Call Tools
- LangChain: How to Create Map-Reduce Branches for Parallel Execution
- OpenAI: OpenAI Chat Completions API Docs
- LangChain: LangGraph Docs
Function Calling in Agentic Workflows was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Build Accurate GenAI Apps: Free, Hands-on Training
Attend GraphAcademy to learn the basics of knowledge graphs, LLMs, graph data modeling, and more.
Share Article



Explore
Related Articles

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



