Example datasets
Neo4j offers a variety of example datasets to get started with the products. Some of them are built-in, others can be retrieved from a GitHub repository. This page shows how to access them.
Available datasets
This list includes all available datasets, descriptions, and how to access them from different platforms.
|
Some datasets are not continuously maintained. Information may be outdated. |
| GitHub | Aura | Neo4j Browser | Demo server | Description |
|---|---|---|---|---|
|
A small graph containing actors and directors that are related through the movies they have collaborated on. It includes the year when the actors, producers, and directors were born, as well as the year when the movie was released. |
|||
|
A graph representing a traditional retail system with products, orders, customers, suppliers, and employees. |
|||
|
A graph including users, tags, and Q&A data retrieved from the website StackOverflow. |
|||
A graph example using a dataset of movie reviews for generating personalized, real-time recommendations. |
||||
A Persons Objects Locations Events example data model focused on the relationships between people, objects, locations, and events. |
||||
Healthcare analysis |
An example graph using FDA Adverse Event Reporting System (FAERS) datasets. It contains information on adverse event and medication error reports submitted to FDA. |
|||
|
A graph based on George R. R. Martin’s series Game of Thrones. It contains information on the interaction between the characters throughout the books. |
|||
A graph with data from the global investigation FinCEN Files concerning money laundering. |
||||
An example graph based on the structure of a social network, with Neo4j’s Twitter data. |
||||
BBC recipes |
|
A graph using data from BBC Good Foods. It contains information on ingredients, diet types, recipes, and author of the recipes. |
||
UK companies |
|
A graph containing information on UK company registration, land ownership, and political donation data. |
||
Airbnb listings |
|
A graph containing information on Airbnb listings, hosts, and reviews. |
||
Football transfers |
|
A graph with transfers data. It includes information on players, clubs, transfers, and countries. |
||
A graph with over 300 movie nodes including information on release status and date, revenue, budget, language, and synopsis. |
||||
WordNet |
A graph using data from WordNet, a large lexical database of English. It groups nouns, verbs, adjectives, and adverbs into sets of cognitive synonyms (synsets), each expressing a distinct concept. |
|||
The Paradise Papers dataset and guide from the International Consortium of Investigative Journalists (ICIJ). |
||||
A graph of the London public transportation network containing information on statios and tube lines. |
||||
An example graph representing a network and IT management. It contains information for dependency and root cause analysis, and more. |
Built-in examples
Some example datasets can be retrieved directly from Aura and Neo4j Browser in the form of guides. With them, you can create or import a dataset and learn how to explore it.
Aura Learning Center
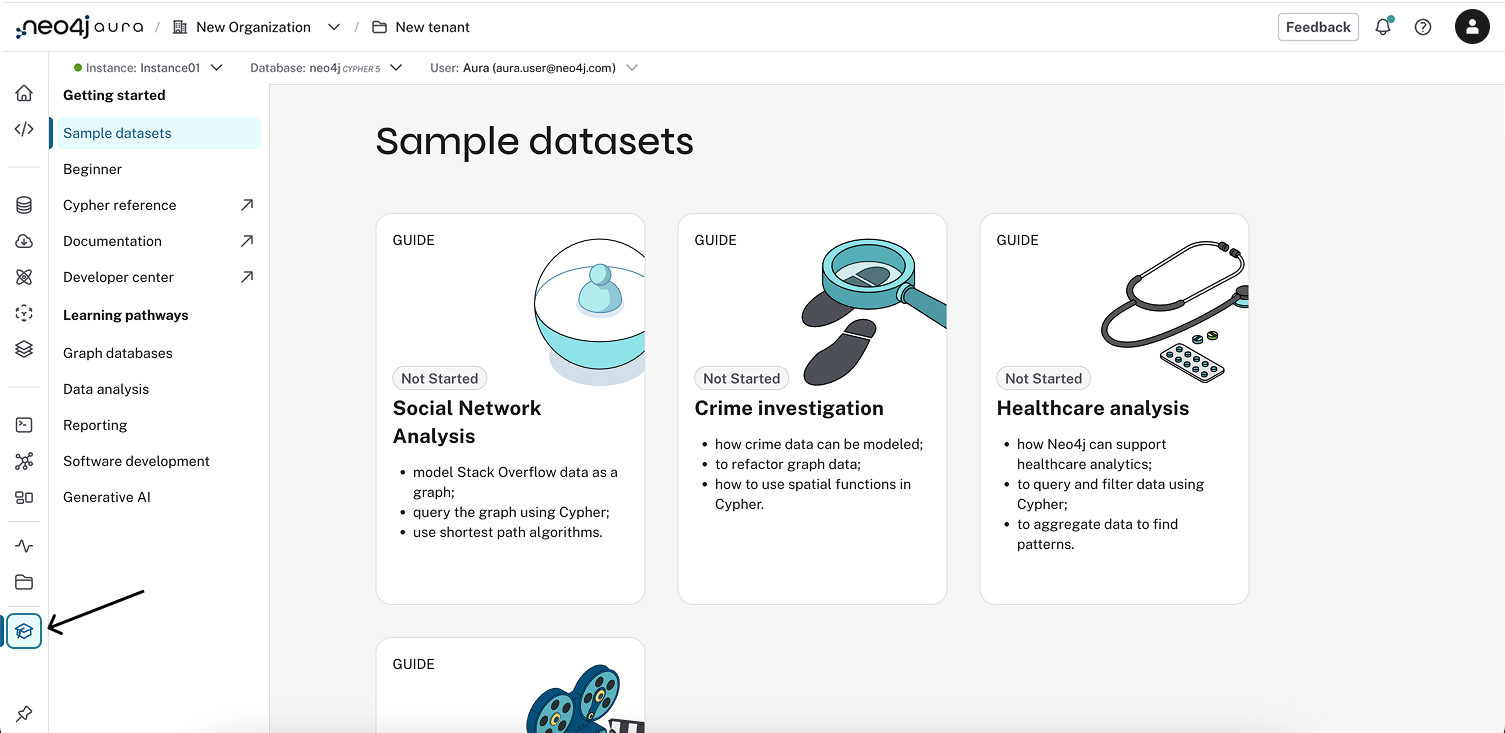
You can access the example datasets through the Learning Center in the Aura console.
Select the cap icon ![]() in the left-hand navigation to see a list of datasets available as learning guides.
in the left-hand navigation to see a list of datasets available as learning guides.
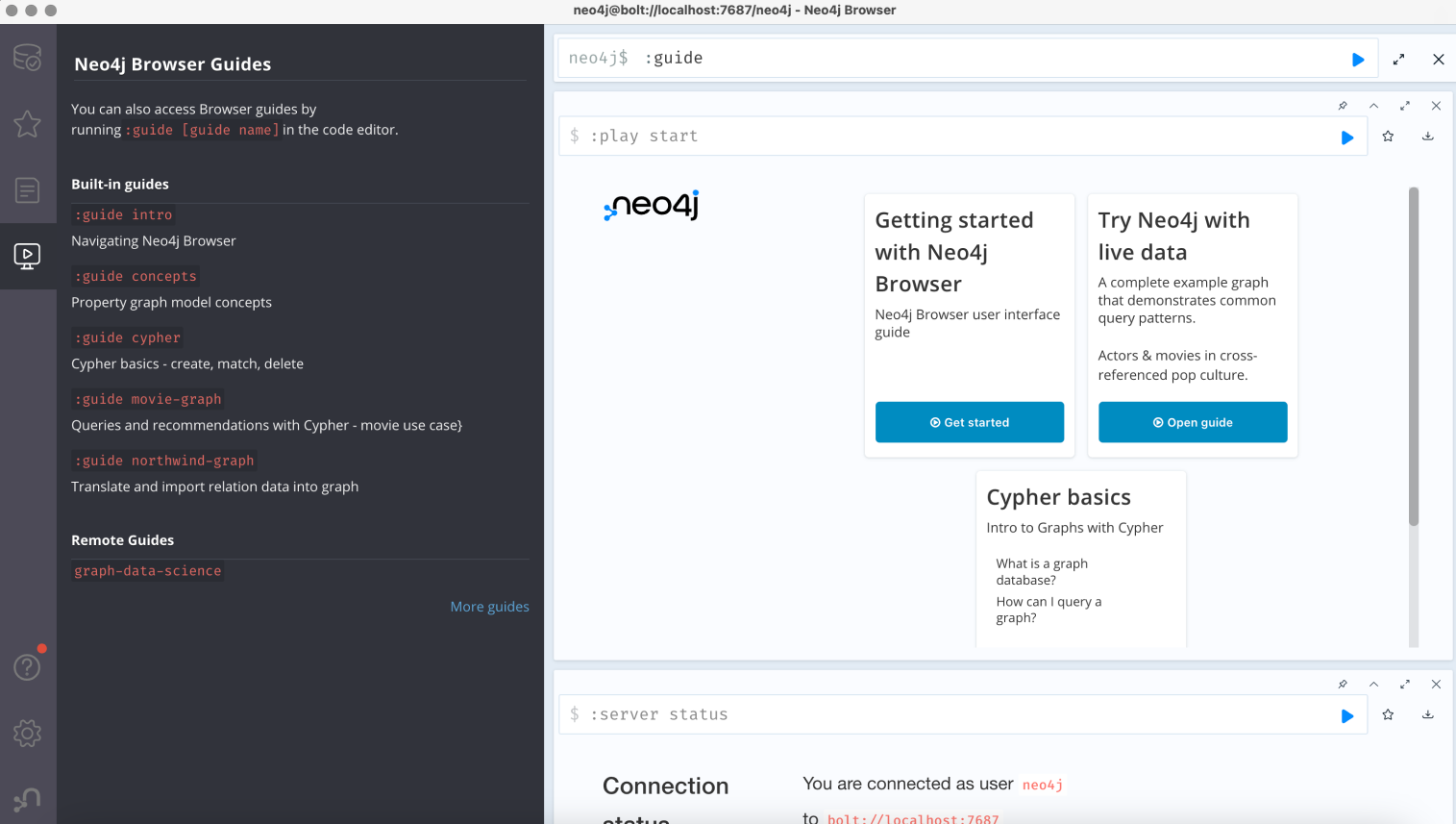
Neo4j Browser
Use the command :guide to access a list of built-in interactive guides or access them directly using these previously listed commands.
Demo server
Optionally, you can access the demo server on https://demo.neo4jlabs.com:7473 to explore a number of datasets with read-only access for public use.
The username and password are the same as the dataset name.
For instance, for the recommendations dataset the username is recommendations and password is recommendations too.
Find the full list of datasets and the username/password entries to use in the available datasets table.
Database dump files
In the GitHub repository Neo4j graph examples, you find dump files for several graph example datasets, including the ones listed previously in the available datasets table.
There are several ways to load them, depending on the environment that is being used:
You can also refer to the Importing your data section to learn more ways to load a dataset to your instance, including other supported file formats.
|
The Neo4j version of some of the dump files may be older than your Neo4j version.
In this case, you need to upgrade your database dump using the |