How to extend Cypher
This guide explains how to create, use and deploy user-defined procedures and functions, the extension mechanism of Cypher®, Neo4j’s query language.
Extending Cypher
Cypher is a powerful and expressive language, with first class graph pattern and collection support. But sometimes you need to do more than it currently offers, like additional graph algorithms, parallelization, or custom conversions.
Cypher can be extended with User-defined procedures and functions, as described in Java Reference → User-defined procedures and Java Reference → User-defined functions.
Neo4j itself provides and utilizes custom procedures. Many of the monitoring, introspection and security features exposed by Neo4j Browser are implemented using procedures.
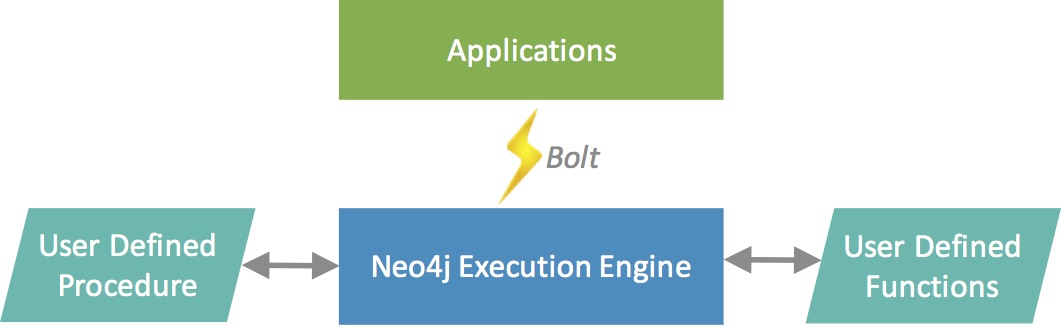
Procedures and functions in Neo4j
-
Functions are simple computations / conversions and return a single value.
-
Functions can be used in any expression or predicate.
-
Procedures are more complex operations and generate streams of results.
-
Procedures can generate, fetch, or compute data to make it available to later processing steps in your Cypher query.
-
To call a procedure deployed in the database, use the
CALLclause (for more details, see Cypher Manual → CALL procedure).
Listing and using functions and procedures in Neo4j
Neo4j comes with a number of built-in procedures. To learn more about them, see Operations Manual → Procedures.
To list all available functions and procedures in DBMS, use the following Cypher commands:
-
SHOW FUNCTIONS -
SHOW PROCEDURES
You can refer to the Cypher Cheat Sheet to get a quick reference on how to use these commands.
Each procedure returns one or more columns of data.
With the YIELD clause these columns can be selected and also aliased and are then available in your Cypher query.
Like other Cypher administrative commands, SHOW PROCEDURES can be used with a subset of Cypher clauses, as shown below where we filter by 'db.' prefix and return the results ordered by name.
SHOW PROCEDURES
YIELD name, signature, description as text
WHERE name STARTS WITH 'db.'
RETURN * ORDER BY name ASCBelow you can find one more example on how to group available procedures by a chosen category, for example by package.
SHOW PROCEDURES
YIELD name, signature, description
RETURN split(name,".")[0..-1] AS package, count(*) AS count,
collect(split(name,".")[-1]) AS names
ORDER BY count DESCSet of the available procedures depends on the type of installation you have and your configuration settings. The result can be the following:
| package | count | names |
|---|---|---|
["dbms"] |
20 |
["checkConfigValue", "components", "info",…] |
["db"] |
16 |
["awaitIndex", "awaitIndexes", "checkpoint",…] |
["db","stats"] |
6 |
["clear", "collect", "retrieve",…] |
["dbms", "cluster"] |
6 |
["checkConnectivity", "cordonServer", "protocols",…] |
["db", "index", "fulltext"] |
4 |
["awaitEventuallyConsistentIndexRefresh", "listAvailableAnalyzers",…] |
User-defined functions are written in Java, deployed into the database and are called in the same way as any other Cypher functions. There are two main types of functions that can be developed and used:
-
user-defined scalar functions,
-
user-defined aggregation functions.
For more details, see Cypher Manual → User-defined functions.
You can take any procedure library and deploy it to your self-managed server to make additional procedures and functions available.
Also take a look at the procedure section in the Neo4j Java Reference.
Deploying procedures and functions
If you build your own procedures or download them from a community project, they are packaged in a JAR file.
You can copy that file into the $NEO4J_HOME/plugins directory of your Neo4j server and restart.
|
As procedures and functions use the low level Java API they can access all Neo4j internals as well as the file system and machine. That’s why you should know which procedures you deploy and why. Only install procedures from trusted sources. If they are open source, check their source-code and best build them yourself. See Operations Manual → Securing extensions for best practices on how to ensure the security of these additions. |
|
Certain procedures and functions are available for self-managed Neo4j Enterprise Edition and Community Edition. |
Procedure and function gallery
The APOC Core library offers you a set of useful procedures on Cypher to increase functionality in areas of data integration, graph algorithms and data conversion.
For example, functions to format and parse timestamps of different resolutions:
RETURN apoc.date.format(timestamp()) as time,
apoc.date.format(timestamp(),'ms','yyyy-MM-dd') as date,
apoc.date.parse('13.01.1975','s','dd.MM.yyyy') as unixtime,
apoc.date.parse('2017-01-05 13:03:07') as millis| time | date | unixtime | millis |
|---|---|---|---|
"2017-01-05 13:06:39" |
"2017-01-05" |
158803200 |
1483621387000 |
In our Neo4j Labs projects, you can find a set of libraries built by our community and staff. Check it out to see what’s already there. Many of your needs will already be covered by those, for example:
-
index operations
-
database/api integration
-
graph refactorings
-
import and export
-
spatial index lookup
-
rdf import and export
-
and many more
|
Community and Neo4j Labs projects are not supported officially and we don’t provide any SLAs or guarantees around backwards compatibility and deprecation. |
Developing your own procedures and functions
You can find details on writing and testing procedures in the Neo4j Java Reference.
The example GitHub repository contains detailed documentation and comments that you can clone directly and use as a starting point.
Here are just some initial tips.
User-defined functions are simpler, so let’s start with them:
-
@UserFunctionare annotated, public Java methods in a class -
their default name is package-name.method-name
-
they return a single value
-
are read only
User-defined procedures are similar:
-
@Procedureannotated, Java methods -
with an additional
modeattribute (READ, WRITE, DBMS) -
return a Java 8
Streamof simple objects withpublicfields -
these fields names are turned into result columns available for
YIELD
These things are valid for both:
-
take
@Nameannotated parameters (with optional default values) -
can use an injected
@Context public GraphDatabaseService -
run within transaction of the Cypher statement
-
supported types for parameters and results are:
Long, Double, Boolean, String, Node, Relationship, Path, Object