








Create a Neo4j GraphRAG Workflow Using LangChain and LangGraph

Data Scientist, Slalom
12 min read

Since Neo4j announced its integration with LangChain, we’ve seen myriad use cases around building with Retrieval-Augmented Generation (RAG) with Neo4j and LLM. This has led to a rapid increase in using knowledge graphs for RAG in recent months. It also seems that knowledge graph-based RAG systems tend to perform well against conventional RAG in terms of managing hallucinations. We have also seen a surge in using agent-based systems to further enhance the RAG applications. To take these one step further, the LangGraph framework has been added to the LangChain ecosystem to add cycles and persistence to the LLM application.
I will walk you through how to create a GraphRAG workflow for Neo4j using LangChain and LangGraph. We will develop a fairly complicated workflow, using LLM at multiple stages and employ dynamic prompting query decomposition techniques. We will also use a routing technique to split between vector semantic search and Graph QA chains. Using the LangGraph GraphState, we will enrich our prompt templates with context derived from earlier steps.
A high-level example of our workflow would look something like the following image.
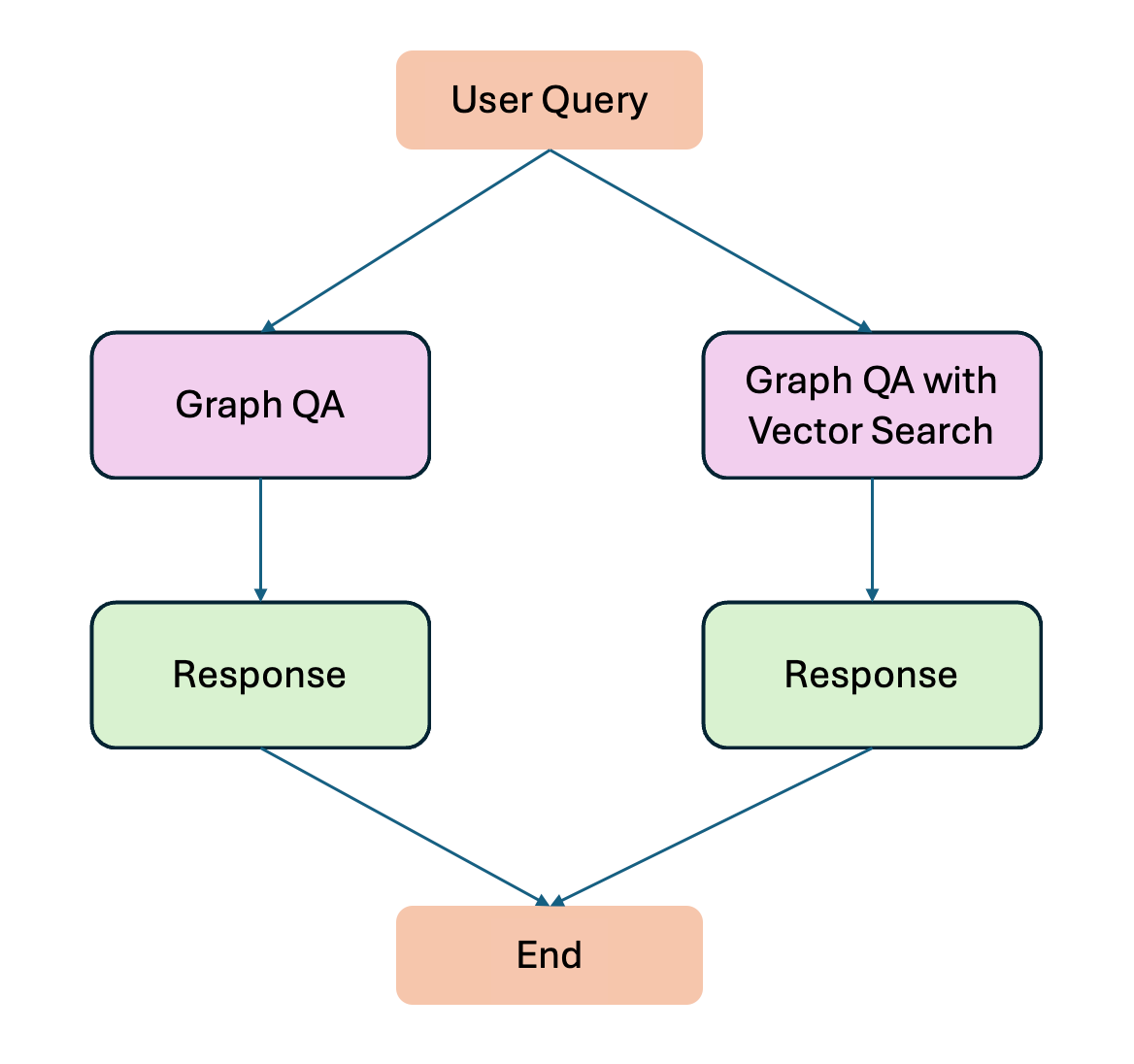
Image by the author
Before we dig deep into the details, here’s a quick recap on LangChain-based GraphRAG workflow:
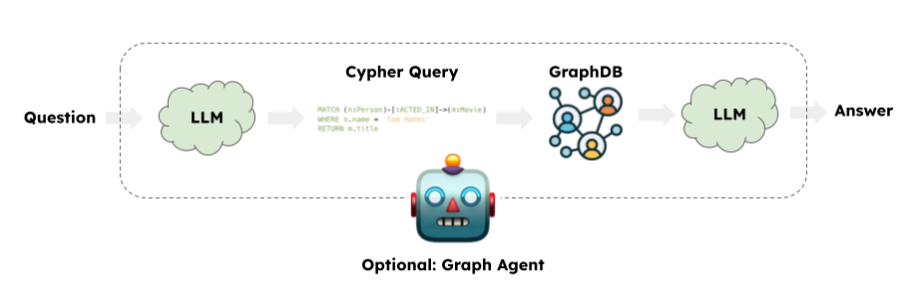
Source: LangChain
A typical GraphRAG application involves generating Cypher query language with the LLM. The LangChain GraphCypherQAChain will then submit the generated Cypher query to a graph database (Neo4j, for example) to retrieve query output. Finally, the LLM will return a response based on the initial query and graph response. At this point, the response is based only on the traditional graph query. Since the introduction of Neo4j vector indexing capabilities, we can also perform a semantic query. When dealing with a property graph, it is sometimes beneficial to combine the semantic query and graph query or bifurcate between the two.
Graph Query Example
Let’s say we have a graph database of academic journals with nodes like articles, authors, journals, institutions, etc.
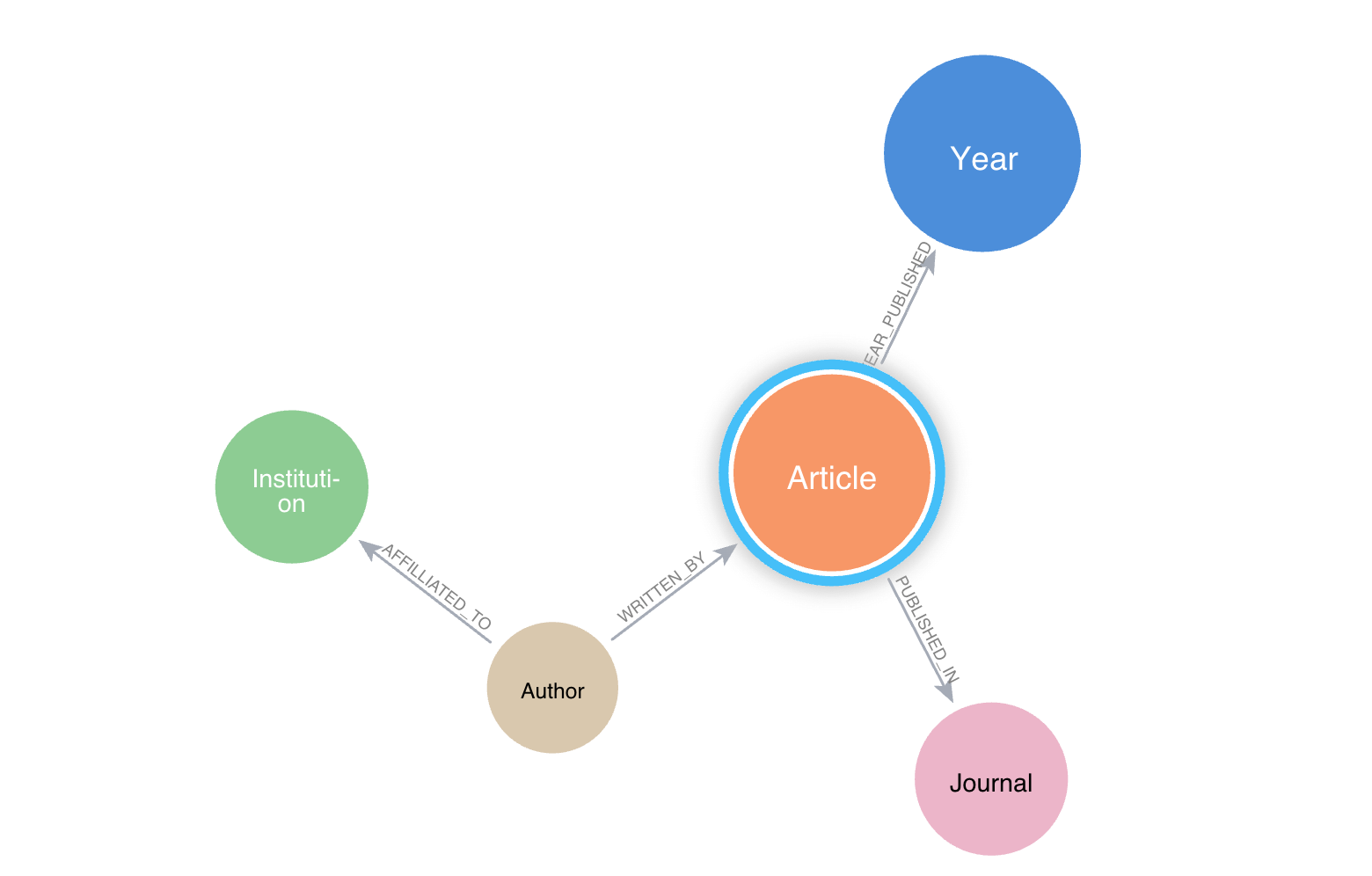
Image by author
A typical graph query to “Find the top 10 most cited articles” would look like this:
MATCH(n:Article)
WHERE n.citation_count > 50
RETURN n.title, n.citation_countSemantic Retrieval Example
“Find articles about climate change” would look like this:
query = "Find articles about climate change? "
vectorstore = Neo4jVector.from_existing_graph(**args)
vectorstore.similarity_search(query, k=3)Hybrid Query
A hybrid query may involve performing a semantic similarity search first, followed by graph query using the result of the semantic search. This is mostly useful when we want to use property graphs such as academic graphs. A typical question to ask is, “Find articles about climate change and return their authors and institutions.”
In this situation, we need to parse the question into the desired number of subqueries that perform a necessary task. A vector search, in this case, works as a context for our graph query. Hence, we need to be able to design a complex prompt template that accommodates such context. (To learn more, check out Advanced Prompting.)
The Developer’s Guide to GraphRAG
Build a knowledge graph to feed your LLM with valuable context for your GenAI application. Learn the three main patterns and how to get started.
LangGraph Workflow
Our current workflow will have two branches (see below) — one with simple graph query retrieval QA using a graph schema and one using vector similarity search. To follow along with this workflow, I created a GitHub repo with all the code for this experiment: My_LangGraph_Demo. The dataset for this experiment was acquired from OpenAlex, which provides scholarly metadata (see OpenAlex Data for more information). In addition, you also need a Neo4j AuraDB instance.
The general workflow is designed as:
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"
workflow = StateGraph(GraphState)
# Nodes for graph qa
workflow.add_node(PROMPT_TEMPLATE, prompt_template)
workflow.add_node(GRAPH_QA, graph_qa)
# Nodes for graph qa with vector search
workflow.add_node(DECOMPOSER, decomposer)
workflow.add_node(VECTOR_SEARCH, vector_search)
workflow.add_node(PROMPT_TEMPLATE_WITH_CONTEXT, prompt_template_with_context)
workflow.add_node(GRAPH_QA_WITH_CONTEXT, graph_qa_with_context)
# Set conditional entry point for vector search or graph qa
workflow.set_conditional_entry_point(
route_question,
{
'decomposer': DECOMPOSER, # vector search
'prompt_template': PROMPT_TEMPLATE # for graph qa
},
)
# Edges for graph qa with vector search
workflow.add_edge(DECOMPOSER, VECTOR_SEARCH)
workflow.add_edge(VECTOR_SEARCH, PROMPT_TEMPLATE_WITH_CONTEXT)
workflow.add_edge(PROMPT_TEMPLATE_WITH_CONTEXT, GRAPH_QA_WITH_CONTEXT)
workflow.add_edge(GRAPH_QA_WITH_CONTEXT, END)
# Edges for graph qa
workflow.add_edge(PROMPT_TEMPLATE, GRAPH_QA)
workflow.add_edge(GRAPH_QA, END)
app = workflow.compile()
app.get_graph().draw_mermaid_png(output_file_path="graph.png")This code will generate a workflow as shown below:
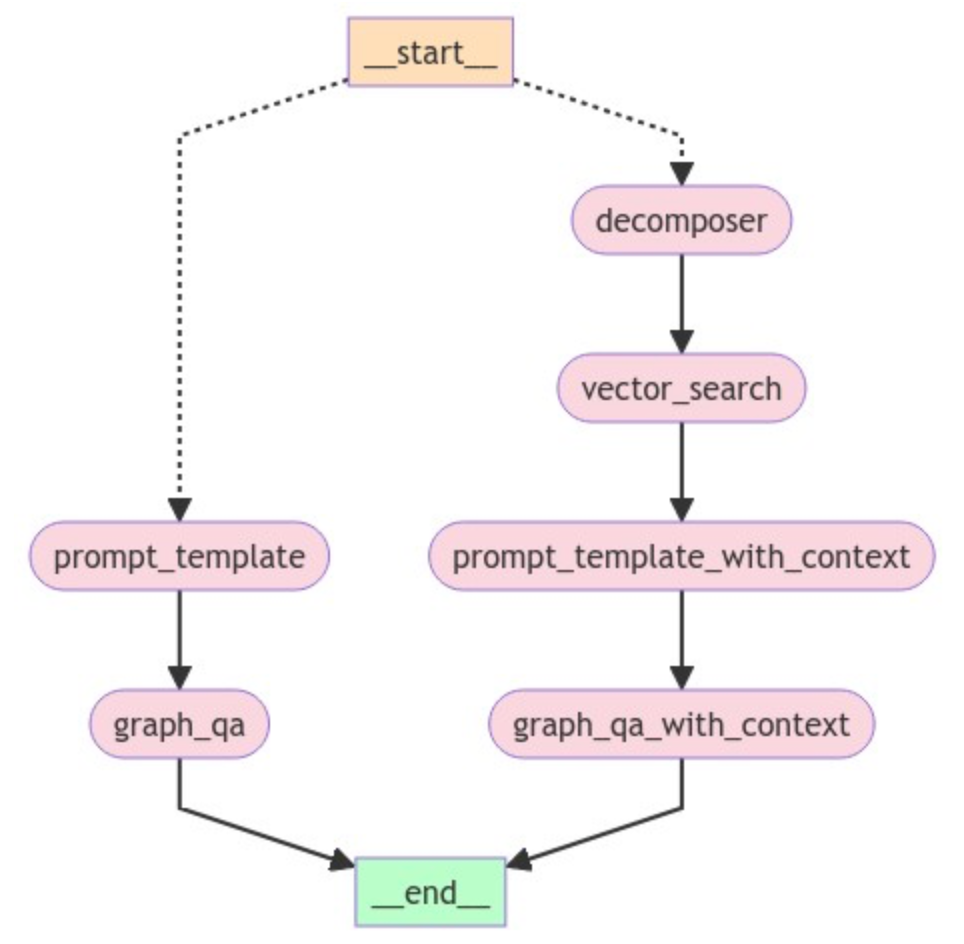
Image by author
In this GraphRAG flow, we start our workflow with a conditional entry point that allows us to decide which route the query flows. The __START__ node in this case starts with a user query. Depending upon the query, the information flows on the either side. If the query needs to look up vector embedding, it will go to the right. If the query is simple graph-based query, the workflow follows the left part. The left part of the workflow is basically the typical graph query using LangChain, as discussed earlier; the only difference is we are using LangGraph here.
Let’s look at the right side of the above workflow. We start with a node for DECOMPOSER. This node basically splits a user question into subqueries. Let’s say we have a user question asking to “Find articles about oxidative stress. Return the title of the most relevant article.”
Subqueries:
-
- Find articles related to oxidative stress — For vector similarity search
- Return title of the most relevant article — For graph QA chain
You can see why we need to decompose a question. The graph QA chain struggled when passing the entire user question as the input query. The decomposition is simply done with a query_analyzer chain that uses a GPT-3.5 Turbo model and a basic prompt template:
class SubQuery(BaseModel):
"""Decompose a given question/query into sub-queries"""
sub_query: str = Field(
...,
description="A unique paraphrasing of the original questions.",
)
system = """You are an expert at converting user questions into Neo4j Cypher queries.
Perform query decomposition. Given a user question, break it down into two distinct subqueries that
you need to answer in order to answer the original question.
For the given input question, create a query for similarity search and create a query to perform neo4j graph query.
Here is example:
Question: Find the articles about the photosynthesis and return their titles.
Answers:
sub_query1 : Find articles related to photosynthesis.
sub_query2 : Return titles of the articles
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm_with_tools = llm.bind_tools([SubQuery])
parser = PydanticToolsParser(tools=[SubQuery])
query_analyzer = prompt | llm_with_tools | parserVector Search
Another important node on the right branch is the prompt template with context. When we query against a property graph, we will get the desired result if our Cypher generation uses graph schema. Creating a context with vector search allows us to focus the Cypher template on the particular node the vector search provides and receive a more accurate result:
template = f"""
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
A context is provided from a vector search {context}
Using the context, create cypher statements and use that to query with
the graph.
"""Prompt Template With Context
We create a context using a similarity search from the stored vector embeddings. We can generate either a semantic context or a node itself as a context. For example, here we are retrieving node IDs that represent the articles most similar to the user query. These node IDs are passed as context to our prompt template.
Once the context is captured, we also want to ensure our prompt templates get the right Cypher examples. As our Cypher examples grow, we can expect that the static prompt examples start to become irrelevant, causing the LLM to struggle. We introduced a dynamic prompting mechanism to select the most relevant Cypher examples based on similarity. We can use the Chroma vector store on the fly to select k-samples based on the user query. So our final prompt template looks like the following:
context = state["article_ids"]
prefix = f"""
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
...
...
A context is provided from a vector search in a form of tuple ('a..', 'W..')
Use the second element of the tuple as a node id, e.g 'W.....
Here are the contexts: {context}
Using node id from the context above, create cypher statements and use that to query with the graph.
Examples: Here are a few examples of generated Cypher statements for some question examples:
"""
FEW_SHOT_PROMPT = FewShotPromptTemplate(
example_selector = example_selector,
example_prompt = example_prompt,
prefix=prefix,
suffix="Question: {question}, nCypher Query: ",
input_variables =["question", "query"],
)
return FEW_SHOT_PROMPTNote that the dynamically selected Cypher examples are passed through a suffix argument. Finally, we pass the template to the node that invokes the graph QA chain. We used the similar dynamic prompt template on the left side of the workflow as well, but without the context.
Unlike in a typical RAG workflow, when introducing context into prompt templates, we do it by creating input variables and passing the variables when we invoke a model chain (e.g., GraphCypherQAChain()):
template = f"""
Task:Generate Cypher statement to query a graph database.
Instructions:
Use only the provided relationship types and properties in the schema.
Do not use any other relationship types or properties that are not provided.
A context is provided from a vector search {context}
Using the context, create cypher statements and use that to query with
the graph.
"""
PROMPT = PromptTemplate(
input_variables =["question", "context"],
template = template,
)Sometimes it gets trickier to pass multiple variables through LangChain chains:
chain = (
{
"question": RunnablePassthrough(),
"context" : RetrievalQA.from_chain_type(),
}
| PROMPT
| GraphCypherQAChain() # typically you have llm() here!
)The above workflow won’t work because GraphCypherQAChain() requires a prompt template, not a prompt text (when you invoke a chain, a prompt template output will be text). This led me to experiment with LangGraph, which seemed to pass as many contexts as I wanted and could execute the workflow.
GraphQA Chain
The final step after the prompt template with context is a graph query. From here, the typical Graph QA Chain is used to pass the prompt to the graph database to execute the query, and the LLM generates responses. Note the similar path on the left side of the workflow after the prompt generation. Furthermore, we use a similar dynamic prompting approach to generate a prompt template on either side.
Before we execute the workflow, here are a few thoughts on router chain and GraphState.
Router Chain
As mentioned, we start our workflow with a conditional entry point that allows us to decide which route the query flows. This is achieved with a router chain, for which we used a simple prompt template and LLM. The Pydantic model comes in handy in this type of situation:
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vector search", "graph query"] = Field(
...,
description="Given a user question choose to route it to vectorstore or graphdb.",
)
llm = ChatOpenAI(temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
system = """You are an expert at routing a user question to perform vector search or graph query.
The vector store contains documents related article title, abstracts and topics. Here are three routing situations:
If the user question is about similarity search, perform vector search. The user query may include term like similar, related, relvant, identitical, closest etc to suggest vector search. For all else, use graph query.
Example questions of Vector Search Case:
Find articles about photosynthesis
Find similar articles that is about oxidative stress
Example questions of Graph DB Query:
MATCH (n:Article) RETURN COUNT(n)
MATCH (n:Article) RETURN n.title
Example questions of Graph QA Chain:
Find articles published in a specific year and return it's title, authors
Find authors from the institutions who are located in a specific country, e.g Japan
"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}")
]
)
question_router = route_prompt | structured_llm_router
def route_question(state: GraphState):
print("---ROUTE QUESTION---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "vector search":
print("---ROUTE QUESTION TO VECTOR SEARCH---")
return "decomposer"
elif source.datasource == "graph query":
print("---ROUTE QUESTION TO GRAPH QA---")
return "prompt_template"GraphState
One beautiful aspect of LangGraph is the flow of information through GraphState. You will need to define all the potential data in the GraphState that a node might need to access at any stage:
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
documents: result of chain
article_ids: list of article id from vector search
prompt: prompt template object
prompt_with_context: prompt template with context from vector search
subqueries: decomposed queries
"""
question: str
documents: dict
article_ids: List[str]
prompt: object
prompt_with_context: object
subqueries: objectTo access this data, you just need to inherit the state when defining a node or any function. For example:
def prompt_template_with_context(state: GraphState):
question = state["question"] # Access data through state
queries = state["subqueries"] # Access data through state
# Create a prompt template
prompt_with_context = create_few_shot_prompt_with_context(state)
return {"prompt_with_context": prompt_with_context, "question":question, "subqueries": queries}With these main topics discussed, let’s execute the Neo4j GraphRAG app.
Graph QA:
app.invoke({"question": "find top 5 cited articles and return their title"})
---ROUTE QUESTION---
---ROUTE QUESTION TO GRAPH QA---
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (a:Article) WITH a ORDER BY a.citation_count DESC RETURN a.title LIMIT 5
> Finished chain.
# Examine the result
graph_qa_result['documents']
{'query': 'find top 5 cited articles and return their title',
'result': [{'a.title': 'Humic Acids Isolated from Earthworm Compost Enhance Root Elongation, Lateral Root Emergence, and Plasma Membrane H+-ATPase Activity in Maize Roots'},
{'a.title': 'Rapid Estimates of Relative Water Content'},
{'a.title': 'ARAMEMNON, a Novel Database for Arabidopsis Integral Membrane Proteins'},
{'a.title': 'Polyamines in plant physiology.'},
{'a.title': 'Microarray Analysis of the Nitrate Response in Arabidopsis Roots and Shoots Reveals over 1,000 Rapidly Responding Genes and New Linkages to Glucose, Trehalose-6-Phosphate, Iron, and Sulfate Metabolism '}]}Graph QA with vector search:
app.invoke({"question": "find articles about oxidative stress. Return the title of the most relevant article"})
---ROUTE QUESTION---
---ROUTE QUESTION TO VECTOR SEARCH---
> Entering new RetrievalQA chain...
> Finished chain.
# Examine the result
graph_qa_result['documents']
{'query': 'Return the title of the most relevant article.',
'result': [{'a.title': 'Molecular Responses to Abscisic Acid and Stress Are Conserved between Moss and Cereals'}]}
# Examine output of GraphState
graph_qa_result.keys()
dict_keys(['question', 'documents', 'article_ids', 'prompt_with_context', 'subqueries'])
# Examine decomposer output
graph_qa_result['subqueries']
[SubQuery(sub_query='Find articles related to oxidative stress.'),
SubQuery(sub_query='Return the title of the most relevant article.')]As you can see, based on the user question, we were able to successfully route the question to the right branch and retrieve the desired output. As the complexity grows, we must modify the prompt for the router chain itself. While decomposition is critical for an application like this, query expansion is another feature in LangChain that might also be a helpful tool, especially when there are multiple ways of writing Cypher queries to return similar answers.
We’ve covered the most important part of the workflow. Please follow My_LangGraph_Demo codebase for a deeper dive.
Summary
This workflow combines many steps, and I haven’t discussed all of them here. However, I would acknowledge that I had difficulties just using LangChain to build an advanced GraphRAG application. Those difficulties were overcome by using LangGraph. The main frustrating one for me is not being able to introduce as many input variables as needed in the prompt template and pass that template to the Graph QA chain through LangChain Expression Language.
The LangGraph at the beginning seemed a lot to unpack, but once you pass that hurdle, it starts to get smoother. In the future, I will be experimenting with incorporating agents into the workflow. If you want to share suggestions, please reach out to me. I am learning as much as I can.
References:
This article is based on another detailed example on LangGraph:
- Advance RAG control flow with Mistral and LangChain: Corrective RAG, Self-RAG, Adaptive RAG
- langgaph-course/README.md at main · emarco177/langgaph-course
- cookbook/third_party/langchain at main · mistralai/cookbook
- Dynamic Prompting with LangChain Expression Language
GraphRAG for Beginners
Build a GraphRAG application that can answer complex questions based on connected data. Learn the three major retrieval patterns.

Share Article



Explore
Related Articles

From Data to Intelligence: Why Every Enterprise Needs an AI Knowledge Layer


Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

