









Use Neo4j with Qdrant for external vector searches by spinning up both locally and preloading with example data
In previous posts, we explored how Neo4j can power retrieval-augmented generation (RAG) pipelines. Today, we’ll expand on integrating Neo4j with Qdrant for external vector searches by spinning up both databases locally and preloading them with example data using the scripts from the neo4j/neo4j-graphrag-python repo.
Why Qdrant?
Qdrant is a fast open-source vector database known for flexible payloads and high-performance similarity searches. Offloading your embeddings to Qdrant — while keeping relationships in Neo4j — lets you:
- Handle large or frequently updated embeddings externally
- Leverage Neo4j’s graph model to enrich AI queries with contextual relationships
- Perform top-k nearest neighbor searches via Qdrant, leaving heavy relational logic to Neo4j
Local Setup
1. Clone and Install
git clone https://github.com/neo4j/neo4j-graphrag-python.git
cd neo4j-graphrag-python
poetry install
If you’re not using Poetry, you can still reference the code and scripts — just ensure the necessary dependencies (neo4j, qdrant-client, etc.) are installed in your environment.
Additionally, ensure that you have Docker installed in your setup.
2. Start Services Locally
From the project root, launch the Neo4j and Qdrant Docker containers via:
docker compose -f examples/customize/retrievers/external/qdrant/docker-compose.yml up
This spins up a local Neo4j instance on port 7687 and Qdrant on 6333.
3. Confirm Additional Dependency Installation
poetry install --extras "qdrant sentence-transformers"The sentence-transformers package is required to generate the embeddings.
Now you have everything you need to run an integrated Neo4j Qdrant RAG pipeline.
4. Populate Databases
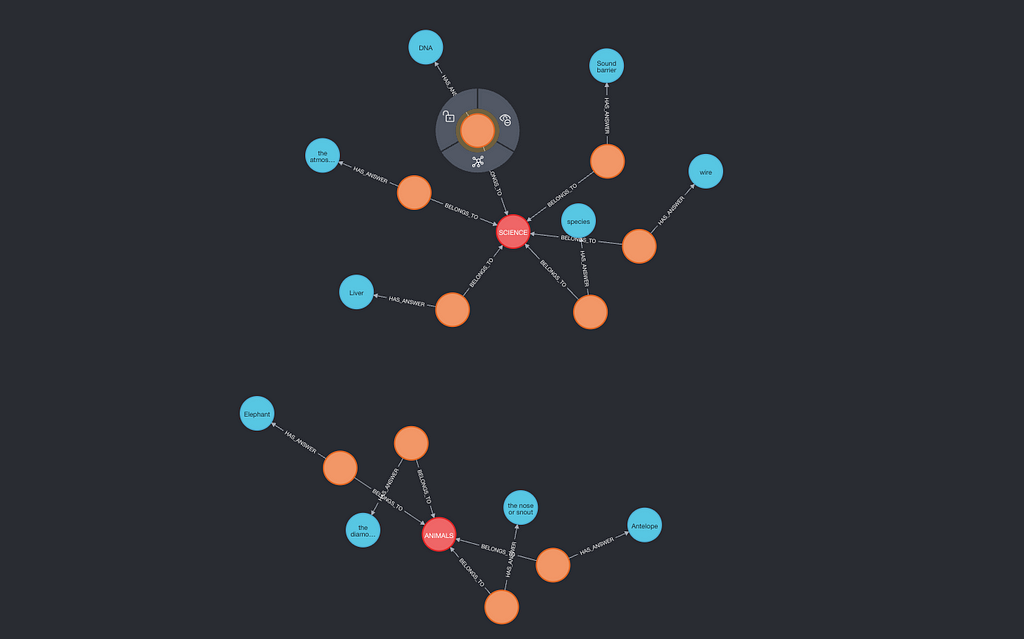
We provide a handy script to write example data to both Neo4j and Qdrant:
poetry run python -m tests.e2e.qdrant_e2e.populate_dbsThis script seeds a “Jeopardy” dataset into each database, so you can jump straight to retrieval tests.
After populating your databases, you can inspect your data on the local Neo4j browser and local Qdrant dashboard, respectively.
Example Usage
Below is a snippet illustrating how to use QdrantNeo4jRetriever with an embedder:
from neo4j import GraphDatabase
from neo4j_graphrag.embeddings.sentence_transformers import (
SentenceTransformerEmbeddings,
)
from neo4j_graphrag.retrievers import QdrantNeo4jRetriever
from qdrant_client import QdrantClient
NEO4J_URL = "neo4j://localhost:7687"
NEO4J_AUTH = ("neo4j", "password")
def main() -> None:
with GraphDatabase.driver(NEO4J_URL, auth=NEO4J_AUTH) as neo4j_driver:
embedder = SentenceTransformerEmbeddings(model="all-MiniLM-L6-v2")
retriever = QdrantNeo4jRetriever(
driver=neo4j_driver,
client=QdrantClient(url="http://localhost:6333"),
collection_name="Jeopardy",
id_property_external="neo4j_id",
id_property_neo4j="id",
embedder=embedder,
)
res = retriever.search(query_text="biology", top_k=2)
print(res)
if __name__ == "__main__":
main()From the results, we can see that the top two retrieved questions are:
- In 1953, James Watson and Francis Crick built a model of the molecular structure of this gene-carrying substance.
- This organ removes excess glucose from the blood and stores it as glycogen.
How It Works
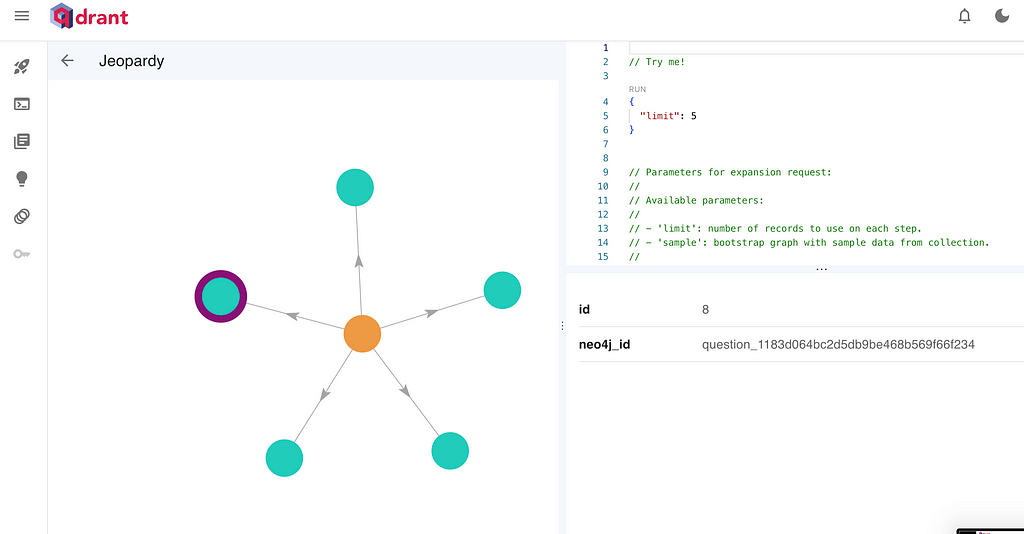
- Vector embeddings: The SentenceTransformerEmbeddings model encodes “biology” into a vector.
- Qdrant search: Qdrant finds the top-two most similar items in the “Jeopardy” collection.
- Node linking: Each Qdrant match references a Neo4j node ID (id_property_neo4j). The retriever uses that ID to fetch the corresponding node in Neo4j.
- Consolidated results: You get a list of RetrieverResultItem objects, each referencing the matching node’s properties.
Quick Tips
- Existing embeddings: If your questions are already embedded as vectors, pass query_vector to .search() and skip the embedder step.
- Schema alignment: Make sure your Qdrant payload (e.g. “neo4j_id”) matches the node property in Neo4j (“id”) so the retriever can join data seamlessly.
- Large dataset workflow: Qdrant handles vector indexing, while Neo4j stores relationships — the best of both worlds for RAG.
Summary
Following the above instructions, you can quickly set up a local environment to test the QdrantNeo4jRetriever. This setup integrates Neo4j for managing graph-based data and Qdrant for performing vector similarity searches, allowing you to explore how the retriever connects these systems for RAG workflows.
The QdrantNeo4jRetriever makes it simple to connect these systems with just a few lines of Python, enabling you to run vector-based searches in Qdrant while using Neo4j’s graph model to add context and relationships to your results. The package also supports Weaviate and Pinecone for users exploring other vector databases, offering flexibility to fit different requirements.
To dive deeper into the code and see it in action, check out the GitHub repository. Feel free to contribute or start a conversation if you have questions or ideas. This package is designed to make combining graph data and vector similarity easier, and we’re excited to see how you’ll apply it in your AI projects.
Integrate Qdrant and Neo4j to Enhance Your RAG Pipeline was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



Architecting Graph-Based Agentic System: When a Regulator Asks “Why Was This Loan Approved?”