Creating Knowledge Graphs from Unstructured Data
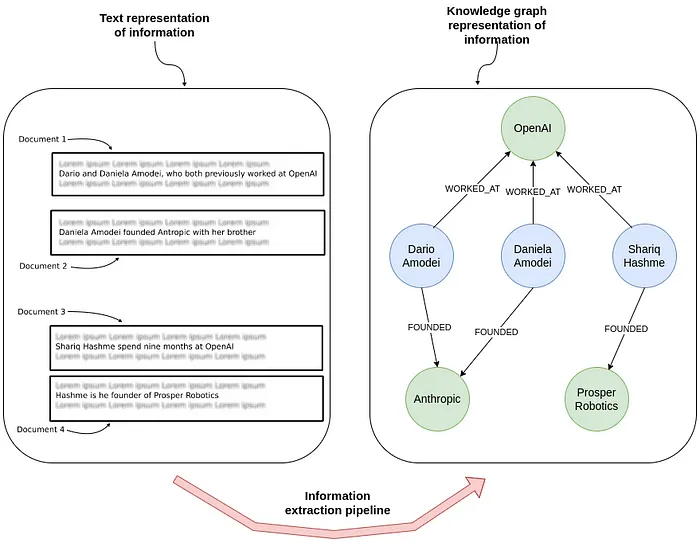
Creating graph structures from unstructured text using NLP techniques like Spacy, Stanford NLP, OpenNLTK etc. has been a long-standing possibility. Those usually required fine-tuning of the NLP models on the specific domain and language of the text to be processed and substantial NLP skills to get the best results.
The rise of prompt-able modern day Large Language Models (LLMs) with strong language skills across many languages and domains, extended the capabilities massively. The LLMs can be instructed with detailed prompts (instructions, examples, schema, existing entities, output formatting) to extract, and de-duplicate entities and relationships from unstructured text, images and audio fragments. The extracted information is returned in a structured JSON format and can be stored in a graph database like Neo4j and linked back to the source documents and additional metadata.
This allows to build Knowledge Graphs (KGs) from unstructured data and integrate them with existing structured data in Neo4j. Those Knowledge Graphs can then be used for a variety of applications, including GraphRAG (Retrieval Augmented Generation) applications, where the Knowledge Graph is used to retrieve relevant contextual information to augment the LLM’s responses.

Neo4j Product Capabilities
GraphRAG Python Package
The Neo4j Python GraphRAG package offers a comprehensive Pipeline for unstructured document processing, graph schema based entity extraction, resolution and storage.
The SimpleKGBuilder provides an easy way to get started, for full configurability, please use
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
ENTITIES = [
"Person",
{"label": "Company", "description": "Company or organization"},
{"label": "Location", "properties": [{"name": "city", "type": "STRING"}]},
]
RELATIONS = [
"LOCATED_AT",
{
"label": "COMPETES_WITH",
"description": "Used for competitor relationships between companies",
},
{"label": "WORKS_AT", "properties": [{"name": "fromYear", "type": "INTEGER"}]},
]
kg_builder = SimpleKGPipeline(
llm=llm, # an LLMInterface for Entity and Relation extraction
driver=neo4j_driver, # a neo4j driver to write results to graph
embedder=embedder, # an Embedder for chunks
from_pdf=True, # set to False if parsing an already extracted text
entities=ENTITIES,
relations=RELATIONS,
potential_schema=POTENTIAL_SCHEMA, # a optional list of node-relationship-node schema entries
)
await kg_builder.run_async(file_path=str(file_path))
A full Knowledge Graph (KG) construction pipeline requires a few more components:
-
Data loader: extract text from files (PDFs, …).
-
Text splitter: split the text into smaller pieces of text (chunks), manageable by the LLM * context window (token limit).
-
Chunk embedder (optional): compute the chunk embeddings.
-
Schema builder: provide a schema to ground the LLM extracted entities and relations and obtain * an easily navigable KG.
-
Lexical graph builder: build the lexical graph (Document, Chunk and their relationships) * (optional).
-
Entity and relation extractor: extract relevant entities and relations from the text.
-
Knowledge Graph writer: save the identified entities and relations.
-
Entity resolver: merge similar entities into a single node.
Learn more in the documentation:
Those generated Knowledge Graphs can then be used with the same Python package, for building GraphRAG powered GenAI applications.
Prototyping and Demonstrations
LLM Knowledge Graph Builder
The LLM Knowledge Graph Builder is an easy to use tool for building Knowledge Graphs from unstructured text.
It uses the LangChain LLMGraphTransformer under the hood, but provides a simple UI to extract entities and relations from uploaded PDFs, Office Documents, Web pages or YouTube video transcripts. It extracts first a lexical graph (Document, Chunk and their relationships) and then uses the chosen LLM to extract entities and relations. Optionally it enriches the graph community summaries and embeddings. You can specify a graph schema to guide the extraction process and visualize the extracted graphs.
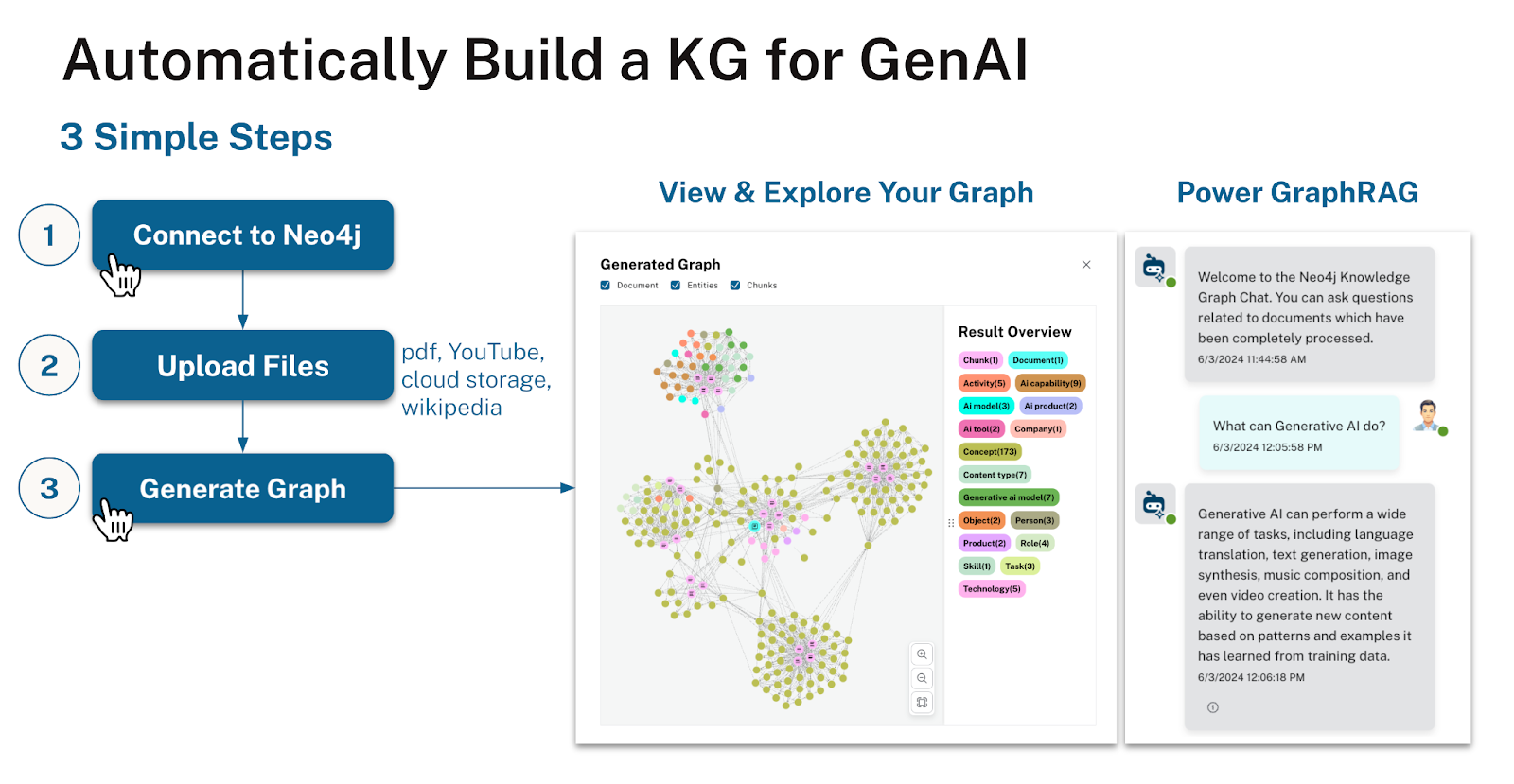
To interact with the extracted information, you can compare a number of different retrievers including GraphRAG, Vector, Hybrid and Text2Cypher. For each answer you can inspect the source of the information and the retrieved context that was used to generate the answer. It also allows to run an RAGAs evaluation across the retrieval results.
Some of the internal details are documented in LLM Graph Builder - Knowledge Graph Extraction Challenges.
AI Assistant with Neo4j MCP Server
A quick way of experimenting interactively with Knowledge Graph extraction is to use a AI assistant like Claude, ChatGPT or an MCP enabled IDE like VS Code, Cursor, Windsurf to process text or discussions interactively and prompt the LLM to extract Entities and Relationships.
Previously those extracted graph entities would have to be imported through an intermediate format like JSON or CSV (e.g. via the Data Importer) or via Cypher.
Now they can be automatically saved to a connected graph using the mcp-neo4j-cypher or mcp-neo4j-memory MCP servers.

Ecosystem Integrations
Neo4j integrates with a number of other tools and frameworks to provide solutions for Knowledge Graph extraction and usage.
Unstructured.io
Unstructured.io is a platform and python package for extracting structured data from unstructured documents. It provides a set of tools for parsing, cleaning, and transforming unstructured data into structured formats.
The Neo4j Integration allows you to extract lexical graphs from any supported source.
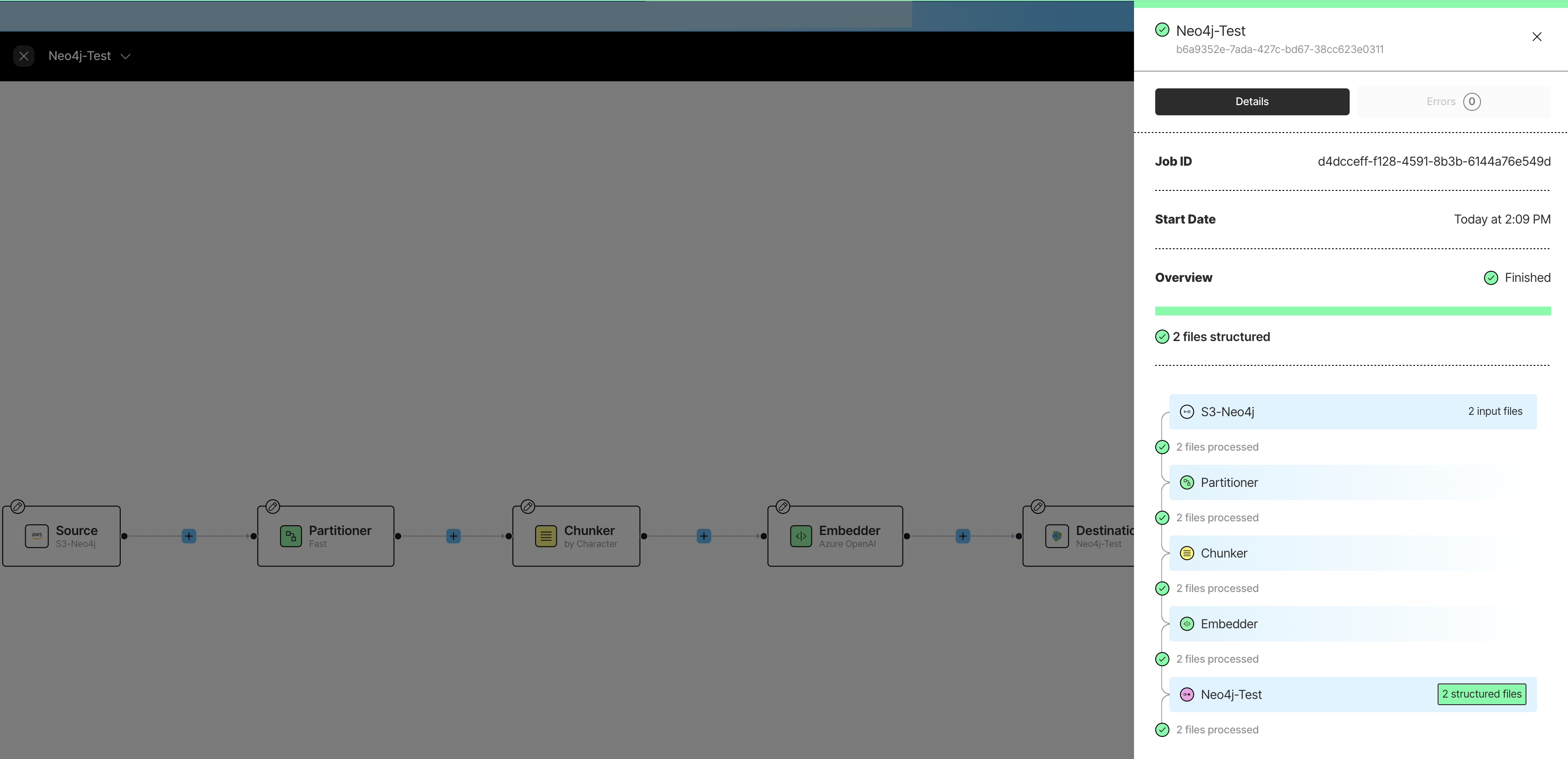
Both in the Platform and the open source package, you can use the Neo4jConnectionConfig, Neo4jUploaderConfig to write the extracted lexical data to a Neo4j graph.
Pipeline.from_configs(
context=ProcessorConfig(),
indexer_config=LocalIndexerConfig(input_path=os.getenv("LOCAL_FILE_INPUT_DIR")),
downloader_config=LocalDownloaderConfig(),
source_connection_config=LocalConnectionConfig(),
...
chunker_config=ChunkerConfig(chunking_strategy="by_title"),
embedder_config=EmbedderConfig(embedding_provider="huggingface"),
destination_connection_config=Neo4jConnectionConfig(
access_config=Neo4jAccessConfig(password=os.getenv("NEO4J_PASSWORD")),
username=os.getenv("NEO4J_USERNAME"),
uri=os.getenv("NEO4J_URI"),
database=os.getenv("NEO4J_DATABASE"),
),
stager_config=Neo4jUploadStagerConfig(),
uploader_config=Neo4jUploaderConfig(batch_size=100)
).run()LangChain
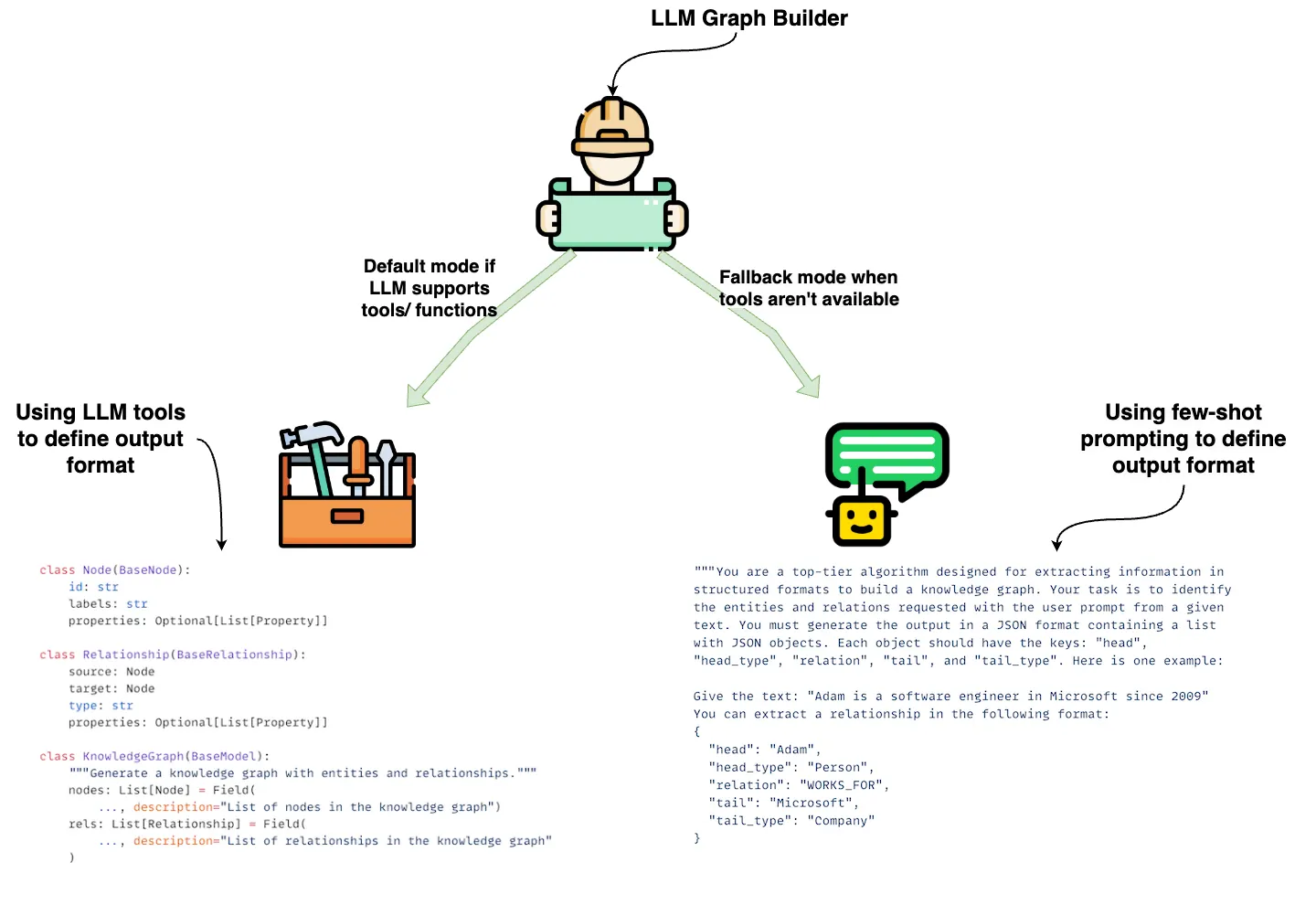
The usage is pretty straightforward, as documented in Constructing Knowledge Graphs.
You can use the convert_to_graph_documents method to convert a list of LangChain documents into graph documents (nodes and relationships).
To guide the extraction process, you can specify a schema with allowed nodes and relationships, as well as properties and additional extraction instructions.
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(
llm=llm,
allowed_nodes=["Person", "Country", "Organization"],
allowed_relationships=["NATIONALITY", "LOCATED_IN", "WORKED_AT", "SPOUSE"],
node_properties=["born_year"],
)
graph_documents = llm_transformer.convert_to_graph_documents(documents)[0]
print(f"Nodes: {graph_documents.nodes} Rels: {graph_documents.relationships}")
graph.add_graph_documents(graph_documents, include_source=True)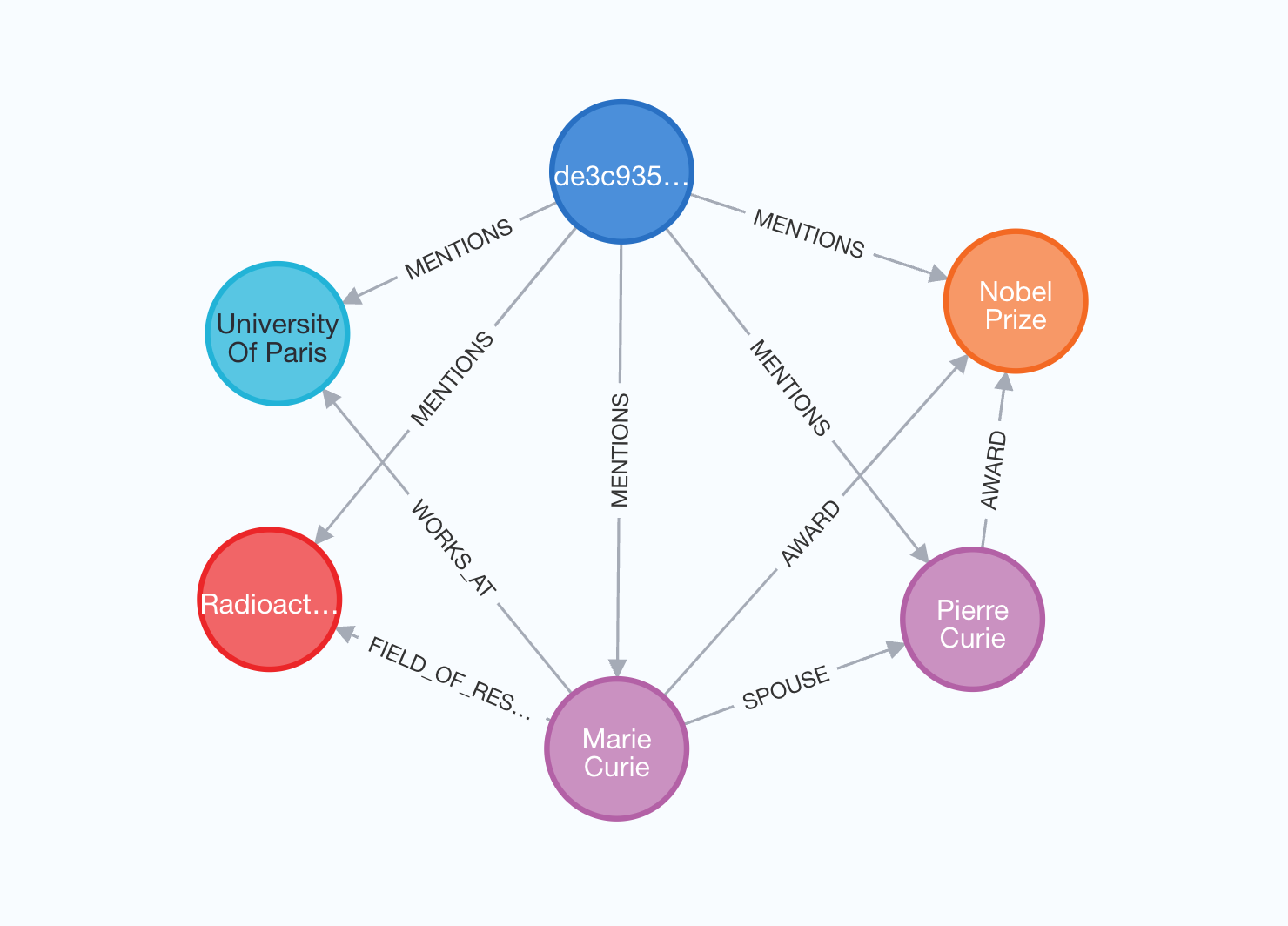
LlamaIndex
In LlamaIndex the PropertyGraphIndex is the main component for managing Knowledge Graphs including building them from unstructured data.
For extracting entities and relations, different extractors can be used, for instance the SchemaLLMPathExtractor.
from typing import Literal
from llama_index.core.indices.property_graph import SchemaLLMPathExtractor
entities = Literal["Person", "Place", "Thing"]
relations = Literal["PART_OF", "HAS", "IS_A"]
schema = {
"Person": ["PART_OF", "HAS", "IS_A"],
"Place": ["PART_OF", "HAS"],
"Thing": ["IS_A"],
}
kg_extractor = SchemaLLMPathExtractor(
llm=llm,
possible_entities=entities,
possible_relations=relations,
kg_validation_schema=schema,
strict=True, # if false, will allow triplets outside of the schema
num_workers=4,
max_triplets_per_chunk=10,
)
graph_store = Neo4jPropertyGraphStore(
username="neo4j",
password="<password>",
url="neo4j+s://xxx.databases.neo4j.io",
)
# creates an index
index = PropertyGraphIndex.from_documents(
documents,
property_graph_store=graph_store,
# optional, neo4j also supports vectors directly
vector_store=vector_store,
embed_kg_nodes=True,
)The Neo4j-PropertyGraphIndex can be used for GraphRAG as a retriever, e.g. via VectorContextRetriever, LLMSynonymRetriever, TextToCypherRetriever, CypherTemplateRetriever.
Blog Posts
-
From Unstructured Text to Interactive Knowledge Graphs using LLMs (2025)
-
GraphRAG in Action: From Commercial Contracts to a Dynamic Q&A Agent (2024)
-
Using LlamaParse for Knowledge Graph Creation from Documents (2024)
-
Automate Building Knowledge Graphs from Scientific Abstracts with LLMs and Neo4j (2024)
-
Enhancing the Accuracy of RAG Applications with Knowledge Graphs (2024)
-
Constructing Knowledge Graphs from Text using OpenAI Functions (2023)
-
Text to Knowledge Graph Information Extraction Pipeline (2022)