Create a graph projection
|
This feature is experimental and not ready for use in production. It is only available as part of an Early Access Program, and can go under breaking changes until general availability. |
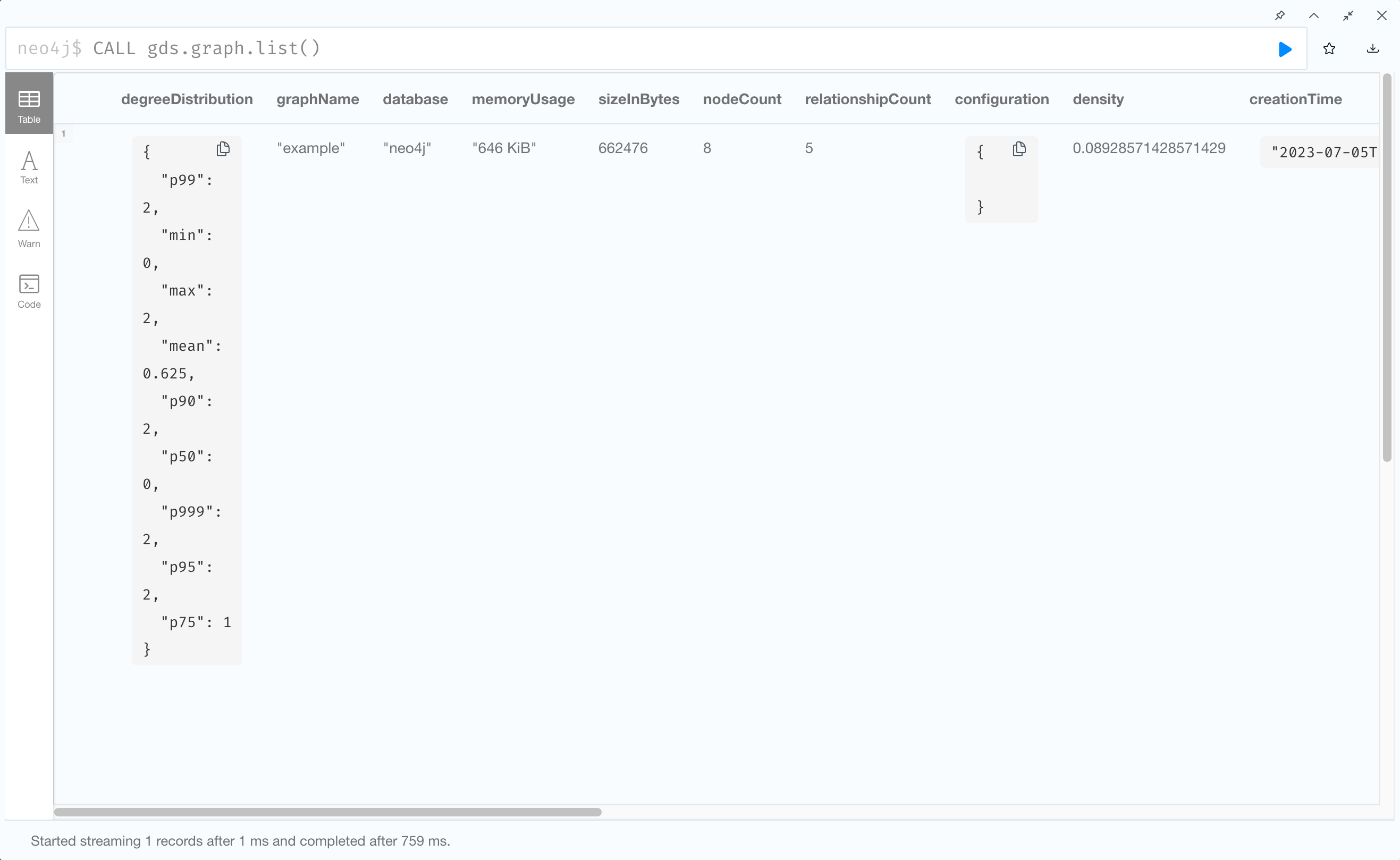
Once we have prepared the data and created a mapping for it, we can proceed to execute the stored procedure that will actually create a graph projection out of BigQuery data. In BigQuery Query Editor, execute the following script replacing the placeholders according to your environment.
DECLARE graph_name STRING DEFAULT "example"; (1)
DECLARE graph_uri STRING DEFAULT "gs://<your-bucket-name>/my-graph-model.json"; (2)
DECLARE neo4j_secret STRING DEFAULT "<secret-resource-name>"; (3)
DECLARE bq_project STRING DEFAULT "<gcp-project-id>"; (4)
DECLARE bq_dataset STRING DEFAULT "<bigquery-dataset>"; (5)
DECLARE node_tables ARRAY<STRING> DEFAULT ["USERS", "QUESTIONS", "ANSWERS"]; (6)
DECLARE edge_tables ARRAY<STRING> DEFAULT ["QUESTIONS", "ANSWERS"]; (7)
CALL `<gcp-project-id>.<bigquery-dataset>.neo4j_gds_graph_project`(
graph_name, graph_uri, neo4j_secret, bq_project, bq_dataset, node_tables, edge_tables);| 1 | Name of the graph projection to create. |
| 2 | URI to the graph mapping model created in Map your tabular data into graph entities. |
| 3 | Resource name of the secret created in Create secrets for Neo4j connection. |
| 4 | Google Cloud Project ID of the BigQuery dataset. |
| 5 | Name of the BigQuery dataset. |
| 6 | List of BigQuery tables to include for node creation. |
| 7 | List of BigQuery tables to include for edge creation. |
It will take a couple of minutes to spin up a Dataproc serverless environment, and the actual graph projection will only start after then. You can track the progress and view logs of the procedure in the All Results pane of the Query Editor.
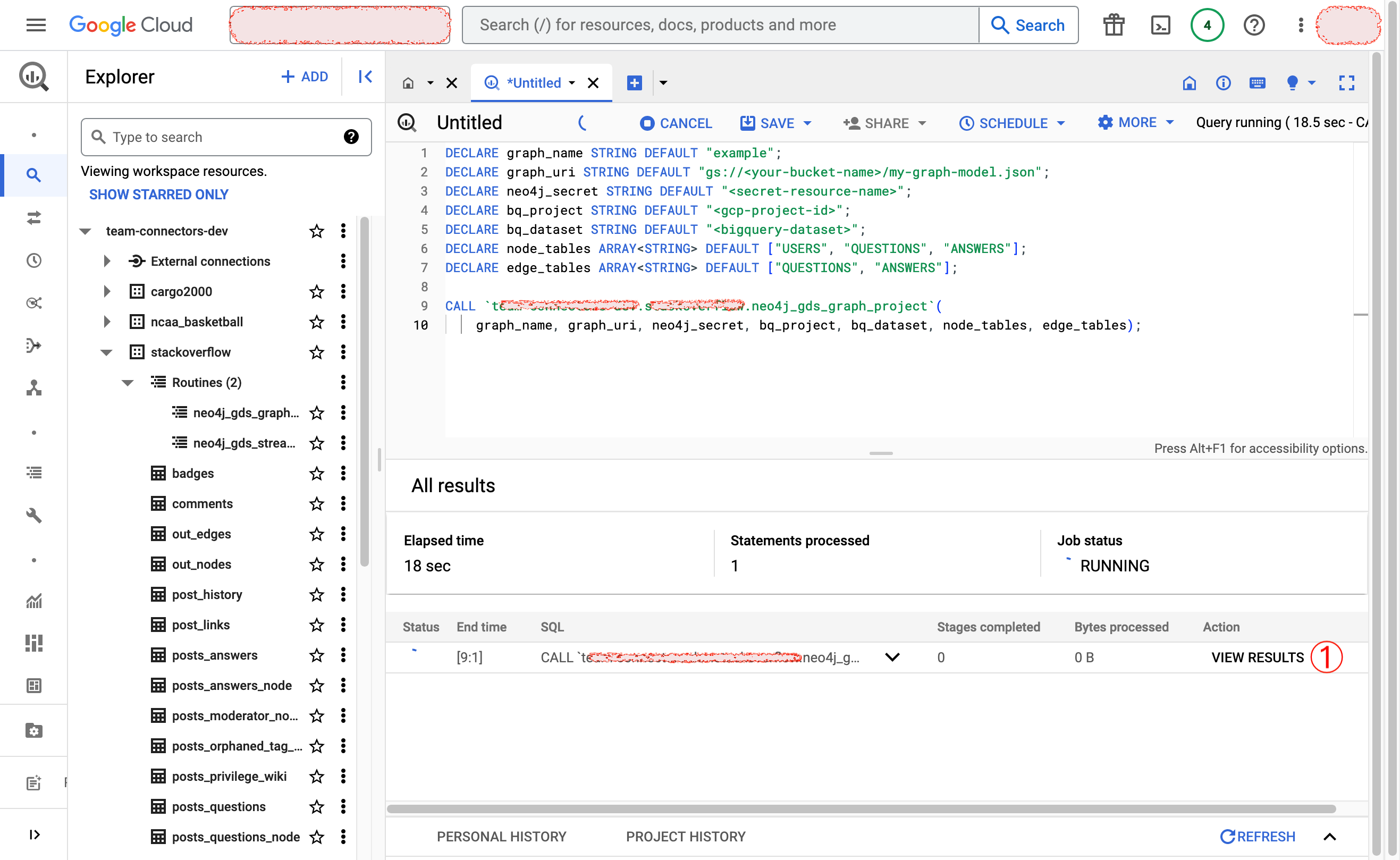
Once the stored procedure finishes execution, validate your graph projection in Neo4j GDS/AuraDS using CALL gds.graph.list().