Kafka Topics Overview
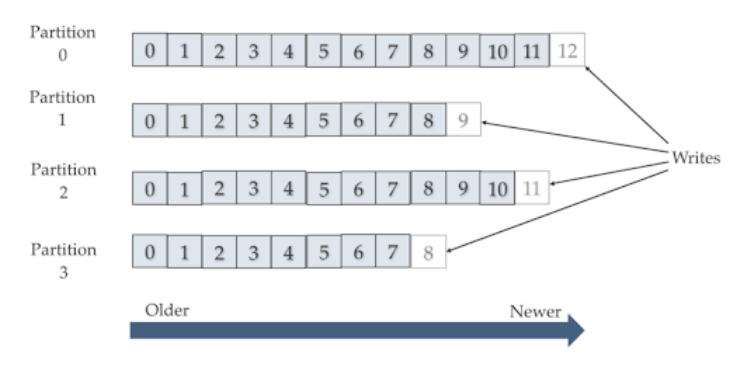
Each topic (message queue) is broken into any number of partitions, which can accept independent reads and writes. Producers push messages onto the end of the queue, and readers advance through the partition offsets.
Partitions and Offsets
Partitions in Kafka are generally read by a client in "round robin" fashion. Partition offsets describe where a given reader is in a given partition. In a simple example, given a single partition, Bob may be currently reading at offset 3 while Sarah is at offset 11. Either reader can selectively "rewind" or "replay" any part of the message queue if they like.
Compaction & Retention
Kafka topics can be configured with various "compaction" and "retention" settings that control how long the Kafka cluster keeps parts of the topic. If all history on the topic is retained, then in theory you can reconstruct all of history by playing it from the beginning.
Database Replication
All databases in Kafka land can be thought of as generic data buckets that can emit messages (producers) or can consume messages (consumers). A common technique in Kafka is to set up one database to publish all its ongoing flow of changes (CDC) to a Kafka topic. Generally, the Debezium format is used for this, but not exclusively.
This is an important concept for database replication, which is common. If you are ingesting from a Kafka topic and you have a setup with decent performance, you may be able to 100% recreate a database by "replaying the topic" into a new Neo4j database.
Polyglot Persistence
Given all of this, an important architectural pattern to be aware of is the idea of having one single "Source of Truth" database (such as Oracle) - which publishes all of its changes to Kafka, feeding multiple downstream "helper systems" such as ElasticSearch and Neo4j. In this way, copies of the data are in 3 different places. The "helper systems" probably don’t accept writes, and just add new query capabilities to the existing data. High Availability may be less of a topic for the helper systems, as they can always be recreated from the topic.