Preparing for Query Tuning
About this module
In this module you will learn about the steps you take before you begin your query tuning work.
At the end of this module, you will be able to:
-
Ensure you have the appropriate system hardware and settings that can affect performance.
-
Prepare Neo4j configuration settings for query tuning.
-
Use a representative data set for your queries.
-
Pre-test all queries to ensure expected rows based upon DB Stats.
-
Ensure the Page Cache is warmed up.
System performance factors
The hardware and system settings required for executing Cypher queries in a Neo4j instance are the typical ones required by most applications:
-
Disk - Ensure that you either use SSD or you have enough IOPs on the system.
-
On linux, configure disk scheduler to noop or deadline, mount the database volume with noatime.
-
-
RAM - Ideally you want to fit your entire graph in memory.
-
CPU cores - The more cores, the more concurrent operations can occur.
-
Number of open files - It is recommended that you set it to 40000 if many indexes and users connect.
-
Neo4j version - You will use the latest GA release of Neo4j to take advantage of the performance improvements that come with Neo4j.
In addition, you must monitor system bottlenecks:
-
top or htop for CPU and memory usage
-
iotop for disk usage
You can read more details about system configuration here
Neo4j configuration settings
To prepare for query tuning, examine and modify these settings in neo4j.conf:
| Property | Description | Default value |
|---|---|---|
|
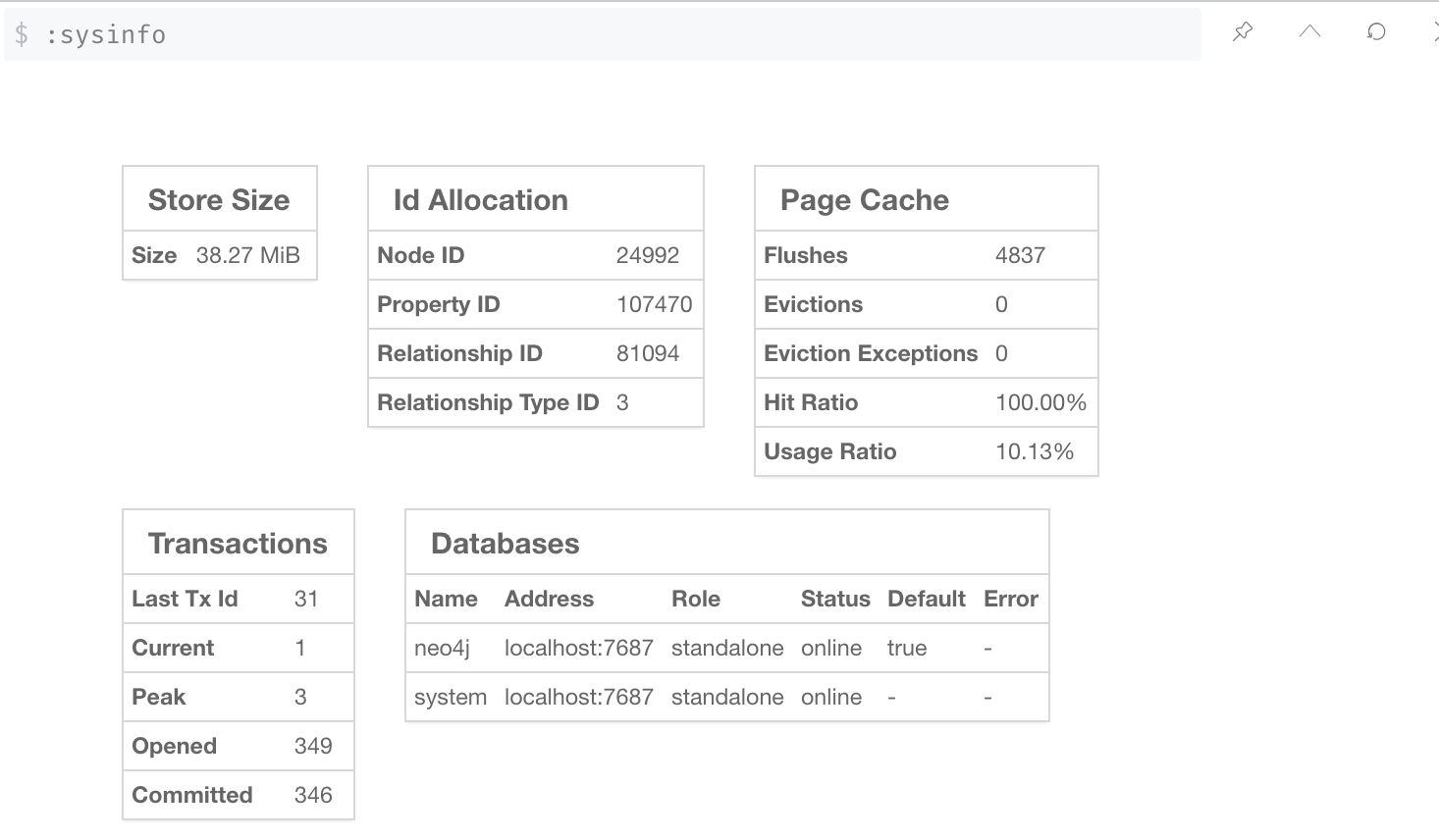
The amount of memory to use for mapping the store files, in bytes (or kilobytes with the 'k' suffix, megabytes with 'm' and gigabytes with 'g'). If possible, set to the size of the graph (:sysinfo). |
|
|
In most cases 8G - 16G is sufficient, but this can never exceed the amount of physical RAM. It must match what you configure for dbms.memory.heap.max_size. |
|
|
In most cases 8G - 16G is sufficient, but this must never exceed the amount of physical RAM |
|
Changes to these properties require a restart of the Neo4j instance.
Querying memory usage
For a started Neo4j instance, you can also query the DBMS to see how much memory is being used:
CALL dbms.listPools()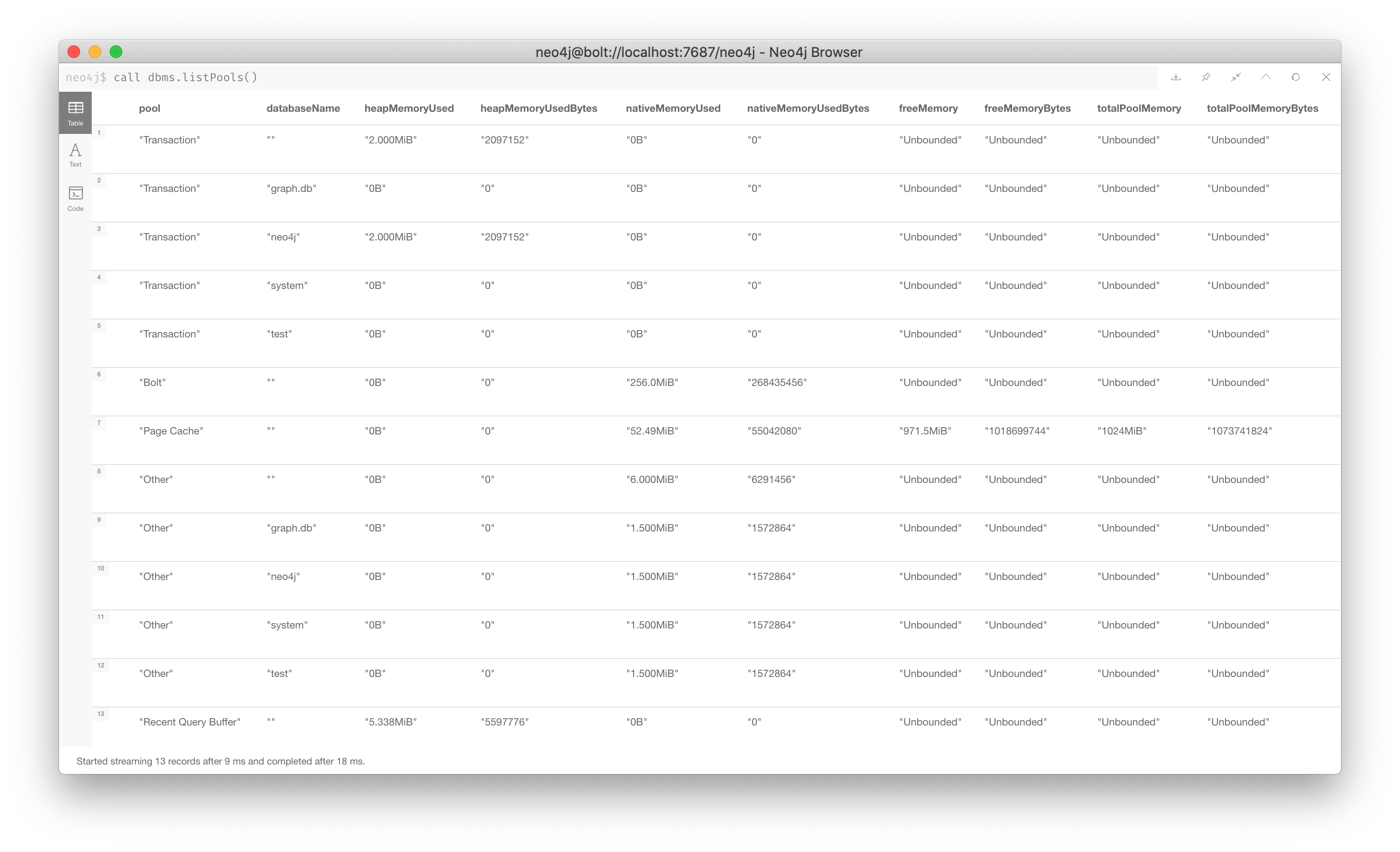
Querying configuration settings
You can also query the graph for what these settings are with this Cypher:
CALL dbms.listConfig() YIELD name, value
WHERE name STARTS WITH 'dbms.memory'
RETURN name, value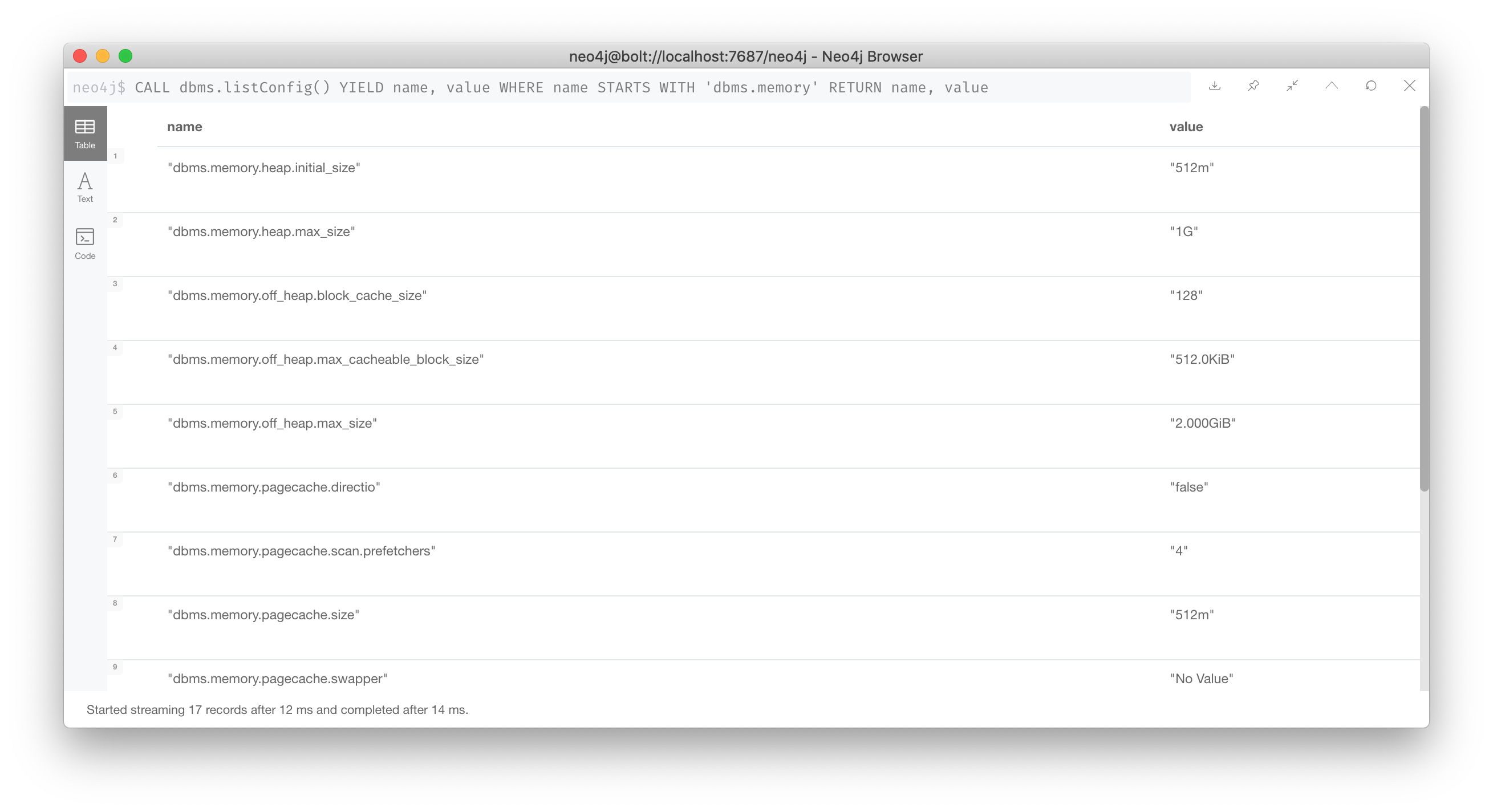
In the next lesson, when you begin query tuning, you will be setting these properties to use more heap.
Using a representative dataset
| It is extremely important that the dataset you are performing the queries against has the same characteristics your real data will have. |
How the execution plan is created depends upon the DB Stats as well as the indexes defined for the database.
You must always:
-
Ensure the data is loaded into the database you will be testing against and it represents a realistic number of nodes and relationships for your real dataset.
-
Understand the data model with
CALL apoc.meta.graph() -
Understand the DB Stats with
CALL apoc.meta.stats() -
Understand the indexes in the graph with
:schema
Pre-test all queries
Before you begin query tuning, make sure that all queries are properly formed:
-
Is the implied syntax correct?
-
Are indexes being used as expected?
-
Is there minimal to no use of literals in queries?
As you learned in the previous lesson, you aim to always use parameters in your queries, rather than literals. This will ensure that the Query Cache is used to your advantage. If a literal is used, it will be one that is always used in the queries.
Let’s look at some other examples where the queries could be written incorrectly.
Check all implied syntax
You can use EXPLAIN to help you when examining queries you will be tuning.
Suppose we had this query:
EXPLAIN
MATCH (p:Person)
WHERE p.fullName = $actorName
RETURN p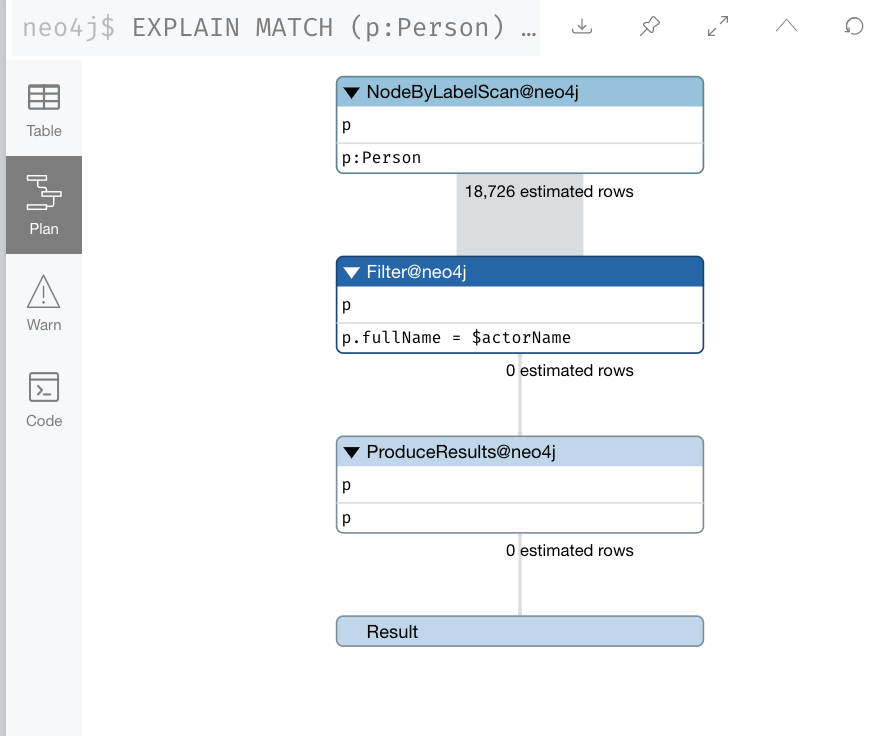
The problem we see with this query is that we know that there is an index on the Person nodes using the name property. With this query we would expect the index to be used. As we see in the image, no index is used to perform the query. p.fullName must have been specified as .name.
Furthermore, we can see that fullName is not a valid property key.
Verify property keys
You can execute this statement to get a list of all valid property names in the graph or you can simply view the keys in the left panel of Neo4j Browser.
CALL db.propertyKeys() YIELD propertyKey
RETURN propertyKey ORDER BY propertyKey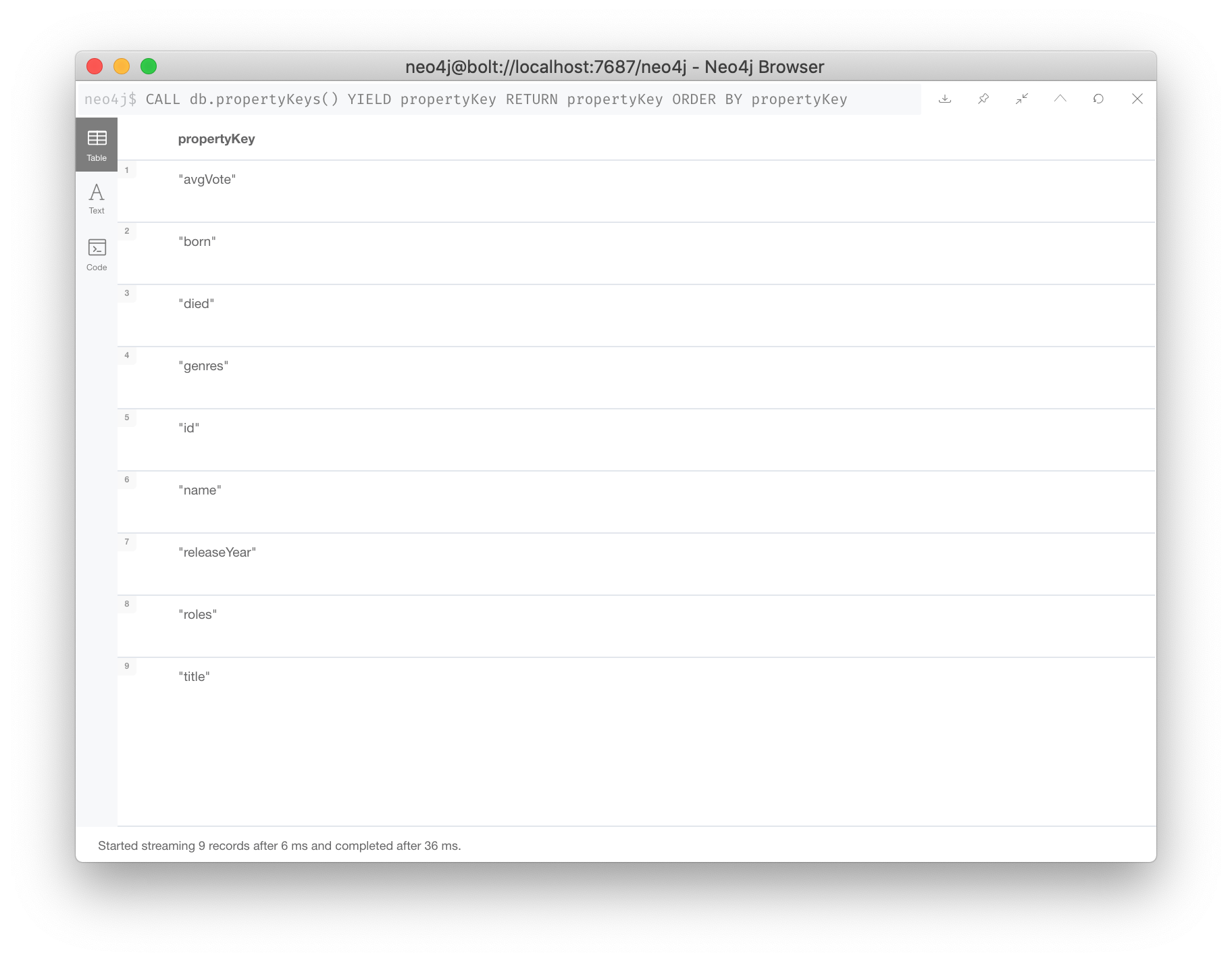
Check correct variable use
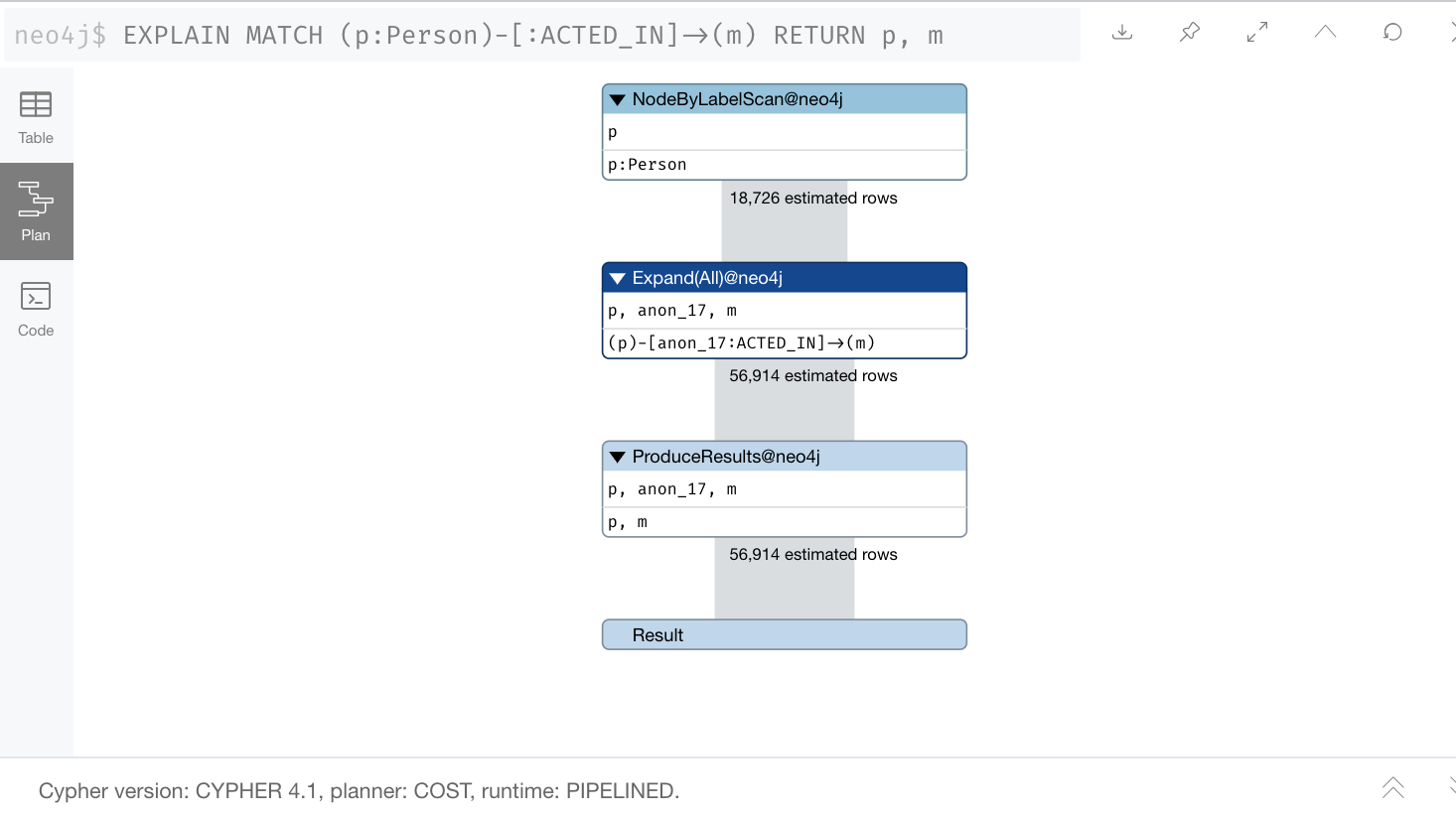
From our knowledge of DB Stats, we know that there are 56,914 (:Person)-(:_ACTED_IN_)→() relationships in the graph.
Suppose we will be tuning this query:
EXPLAIN
MATCH (p:Person)-[ACTED_IN]->(m)
RETURN p, m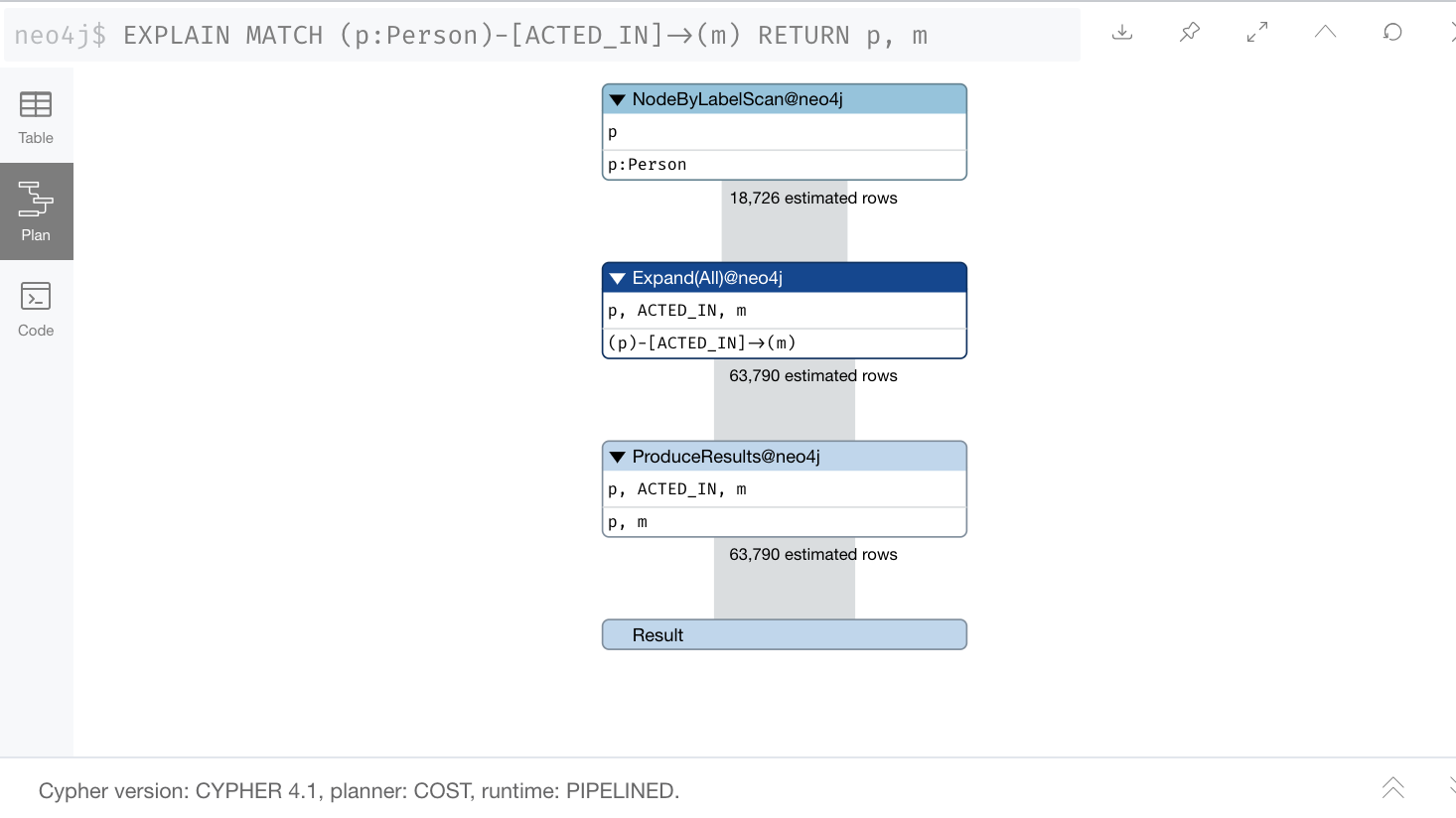
When we look at the expected number of rows, we see 63,790. This is not correct because the query had an error in it.
Warm up the Execution Plan and Page Caches
After you have confirmed that the queries are properly formed and use the expected resources to perform the queries, you are ready to begin tuning.
You want the query times to not include time for compilation. That is, you want to measure only the query execution time and the time it takes to return the results. To warm up the Execution Plan Cache, make sure you execute all queries you will be tuning. This will ensure that they are compiled and in the Execution Plan Cache.
There are different ways that you can warm up the Page Cache. Depending on the size of your graph and the size of RAM on your system, you may not be able to keep the entire graph in Page Cache.
Here are some ways that you can warm up the Page Cache:
MATCH (n) RETURN max(id(n))
MATCH ()-[rel]->() RETURN max(id(rel))
// or
CALL apoc.warmup.run() //nodes and relationships
CALL apoc.warmup.run(true) // include properties
CALL apoc.warmup.run(true,true) // include large strings and arrays
CALL apoc.warmup.run(true,true,true) // include indexes| When the Neo4j instance is restarted, it fills the Page Cache with the data it had before it was previously running. |
Exercise 2: Prepare for Query Tuning
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-query-tuning-exercises
and follow the instructions for Exercise 2.
| This exercise has 6 steps. Estimated time to complete: 15 minutes. |
Check your understanding
Question 1
Which of the following will impact your query tuning work?
Select the correct answers.
-
RAM
-
Version of Neo4j
-
Disk hardware and software
-
Number of Cores
Question 2
Which Cypher statement will provide you with count information that you can use to explain the behaviour of the queries you will be tuning?
Select the correct answer.
-
CALL db.countInfo()
-
CALL db.count-store()
-
CALL apoc.count-store()
-
CALL apoc.meta.stats()
Question 3
Why do you warm up the Page Cache?
Select the correct answer.
-
You want as much data from the graph in memory for your queries.
-
You want to make sure the DB Stats are updated.
-
You want the execution plans for queries you will be tuning to be in memory.
-
You want lock all data so that it cannot be modified during query tuning.
Summary
You can now:
-
Ensure you have the appropriate system hardware and settings that can affect performance.
-
Prepare Neo4j configuration settings for query tuning.
-
Use a representative data set for your queries.
-
Pre-test all queries to ensure expected rows based upon DB Stats.
-
Ensure the Page Cache is warmed up.
Need help? Ask in the Neo4j Community