Reducing cardinality
About this module
As you examine execution plans for your queries, you will see that rows are processed and passed through to the next step of the execution plan. Even though much of the data resides in the Page Cache, you want to reduce the number of rows that the query needs to process. In this module, you will learn how to modify queries to reduce the amount of duplicate information that may be passed from the steps of the execution plan.
At the end of this module, you will be able to:
-
Describe cardinality in an execution plan.
-
Tune and rewrite queries to:
-
Aggregate early.
-
Use pattern comprehension.
-
Anchor node through selectivity by label.
-
Use indexes.
-
Use full-text schema indexes.
-
Use query hints for index usage.
-
Use
LIMITearly in the query. -
Use
DISTINCTearly in the query. -
Use
UNWINDto your advantage. -
Avoid cartesian products.
-
| Because some of the code examples in this lesson modify the database, it is recommended that you do not execute them against your database as you will be doing so in the hands-on exercises. |
Understanding row cardinality
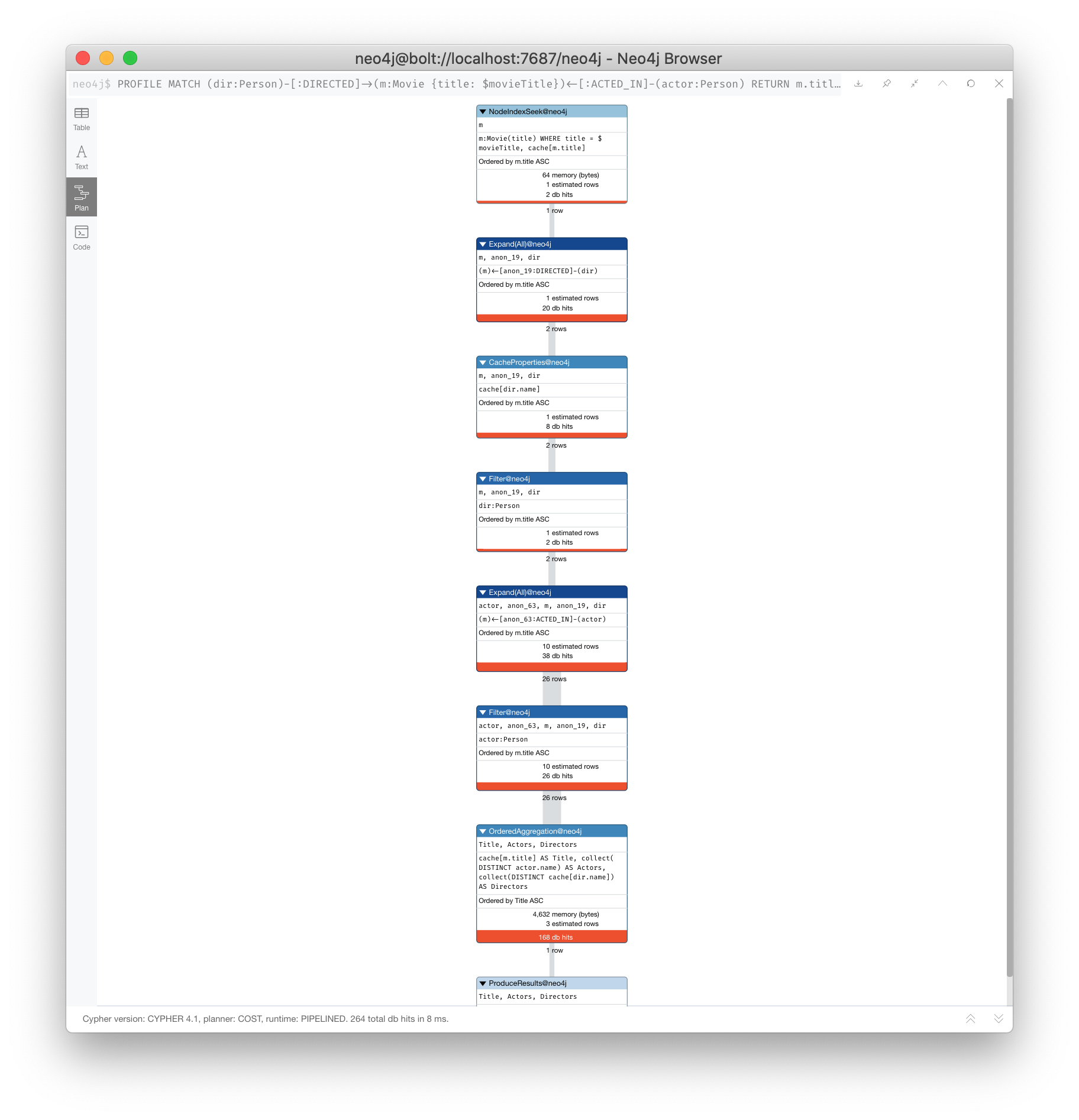
Here is a query that we will be looking to improve. The value of $movieTitle is "The Matrix":
PROFILE
MATCH (m:Movie {title: $movieTitle})
MATCH (dir:Person)-[:DIRECTED]->(m)
MATCH (actor:Person)-[:ACTED_IN]->(m)
RETURN m.title AS Title,
collect(DISTINCT actor.name) AS Actors,
collect(DISTINCT dir.name) AS DirectorsHere is the resulting execution plan:
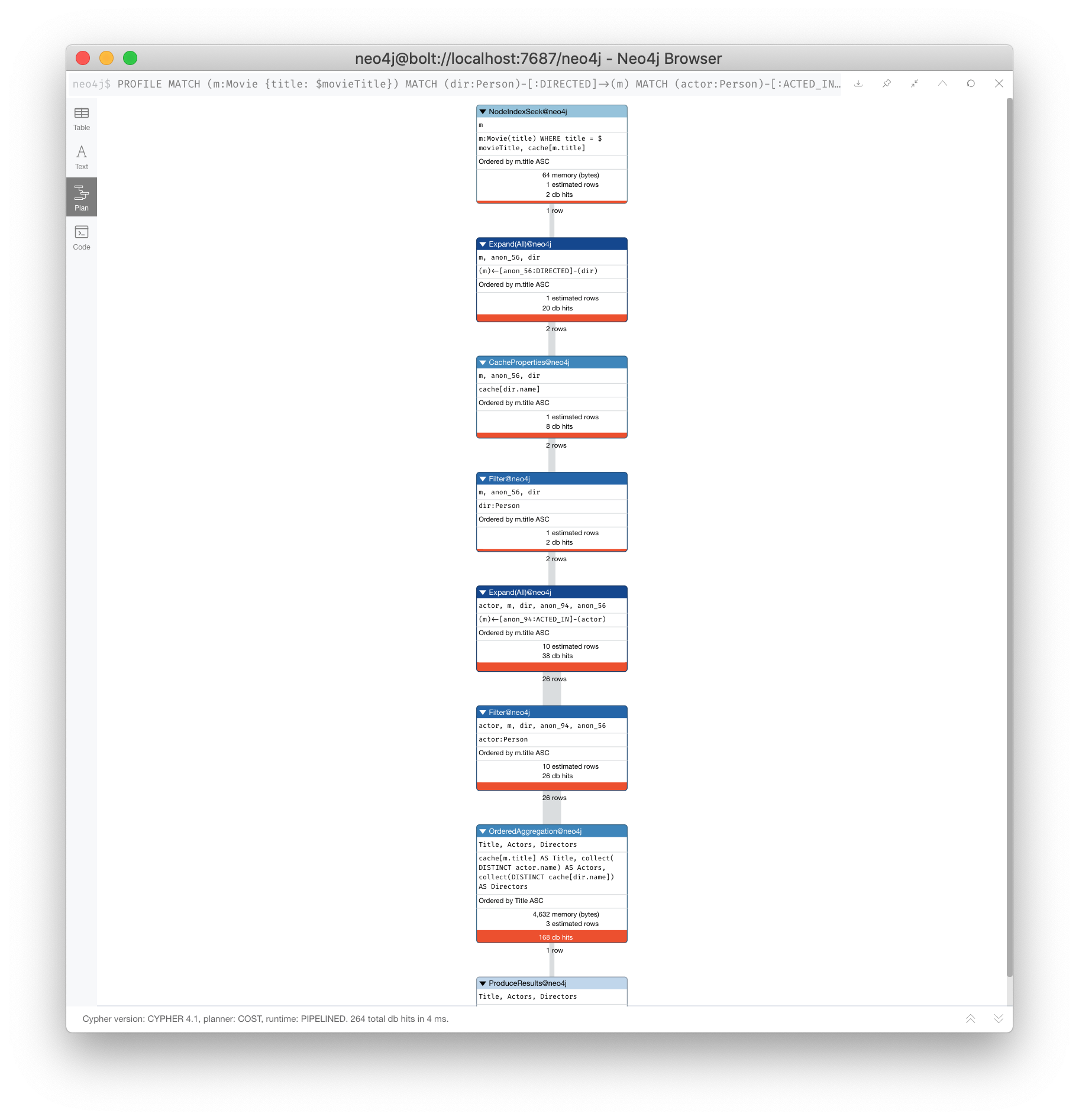
Query execution is not what you might expect
Here is how you might expect the query to execute:
-
We find all Movies with the title "The Matrix", where one row is returned.
-
We then find all directors associated with that one movie. There are two rows returned.
-
We also find all actors associated with that one movie. There are 13 rows returned.
-
Then we return the title of the movie, the list of 2 unique directors, and the list of 13 unique actors.
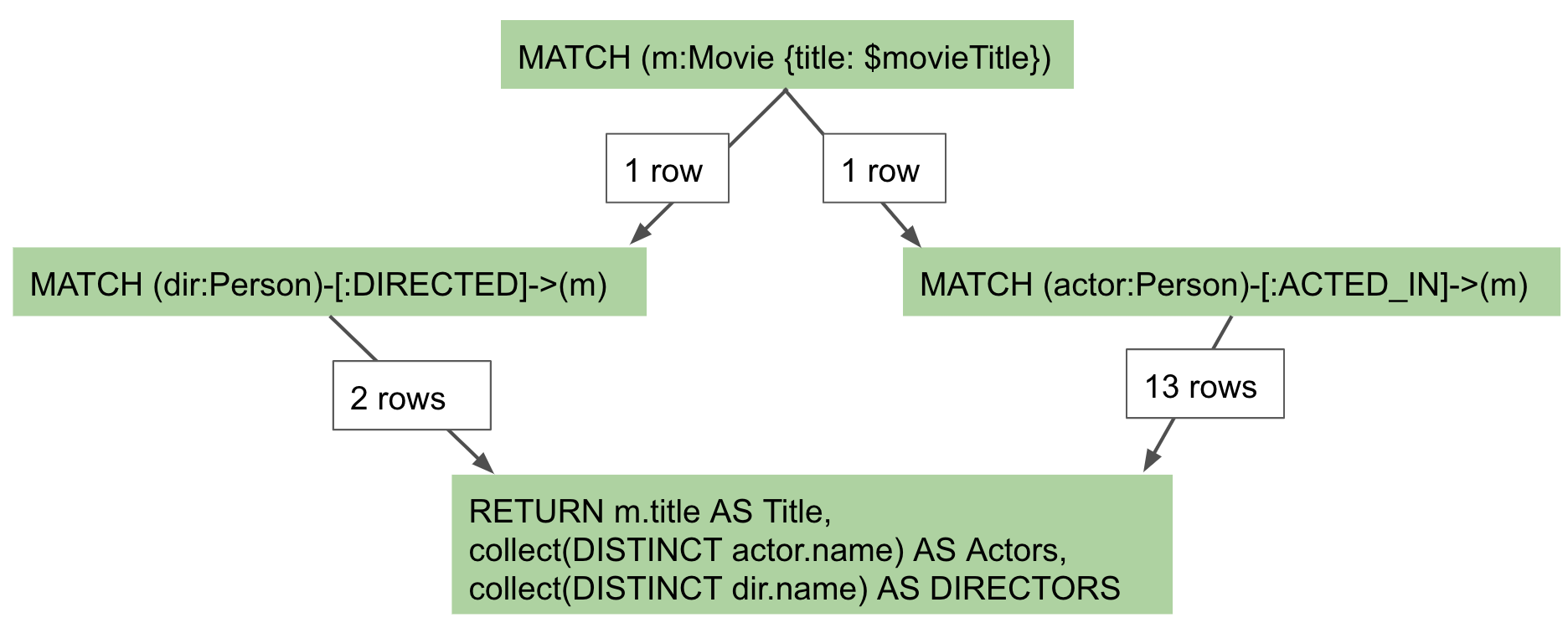
Actual query explained
But this is NOT how the steps in the execution plan work. This is what really happens in the query.
-
We find all Movies with the title "The Matrix", where one row is returned.
-
We then find all directors associated with that one movie. There are two rows returned.
-
We then find all actors associated with that one movie and a director. There are 26 rows returned, for each director/actor combination.
-
Then we return the title of the movie, the list of 2 unique directors, and the list of 13 unique actors.
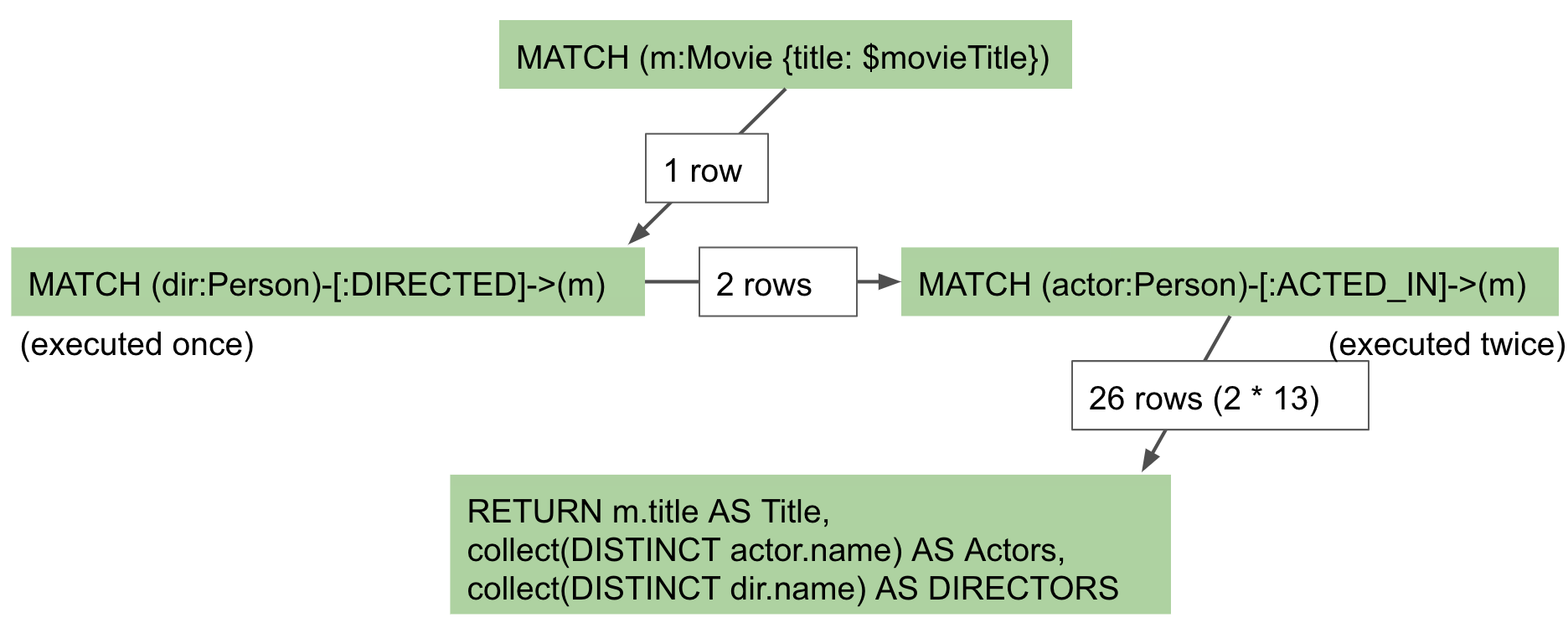
In reality, we are processing twice as many rows as we need to when matching the actors. There is duplicate work that we need to eliminate. We do see the correct result because we are specifying DISTINCT for the names of the actors and directors.
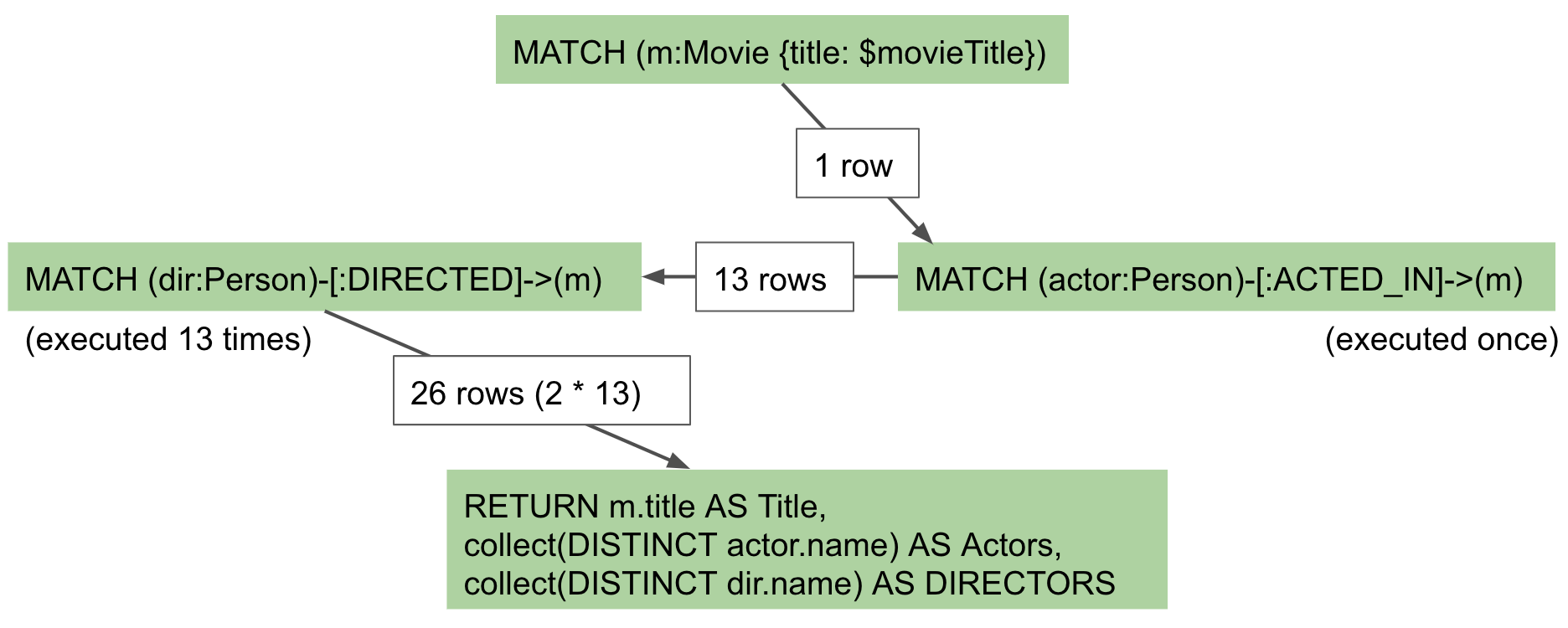
What increases cardinality?
Here are some things to keep in mind that typically increase the cardinality of your queries:
-
Multiple
MATCHandOPTIONAL MATCHstatements that are back-to back (even with aWITH) in between, especially when:-
The nodes have a degree > 1 and you need to expand.
-
Index selectivity is > 1
-
-
Overuse of
UNWINDoperations because each element of the list becomes a row -
Procedure results (when they
YIELDsomething) -
Lack of selectivity for the anchor nodes
How to reduce cardinality?
Here are some tips:
-
Aggregate earlier where the grouping key will become distinct.
-
Use pattern comprehension.
-
Use subqueries (new in Neo4j 4.1)
-
Use labels or indexes to select anchor nodes.
-
Take advantage of indexes.
-
WITH DISTINCTapplies to the entire row, not just a single variable. -
LIMITreduces all rows, not results per row.
WITH on its own does not shrink cardinality.
|
Cardinality is a problem
Here is our original query:
PROFILE
MATCH (m:Movie {title: $movieTitle})
MATCH (dir:Person)-[:DIRECTED]->(m)
MATCH (actor:Person)-[:ACTED_IN]->(m)
RETURN m.title AS Title,
collect(DISTINCT actor.name) AS Actors,
collect(DISTINCT dir.name) AS Directors
We see that the problems are that we have back-to-back MATCH statements and we aggregate too late in the query.
We are passing 26 rows through the query.
Reducing cardinality by aggregating earlier
We can improve this query buy moving the aggregation up:
PROFILE
MATCH (m:Movie {title: $movieTitle})
MATCH (dir:Person)-[:DIRECTED]->(m)
WITH m, collect(dir.name) AS Directors
MATCH (actor:Person)-[:ACTED_IN]->(m)
WITH m, Directors, collect(actor.name) AS Actors
RETURN m.title AS Title, Directors, ActorsWith this revised query, as soon as we match the directors, we will collect the names which will be unique.
Then when we execute the final MATCH. We are not passing two director rows to be processed, but simply the single row with the movie and list of directors.
Here is the execution plan:
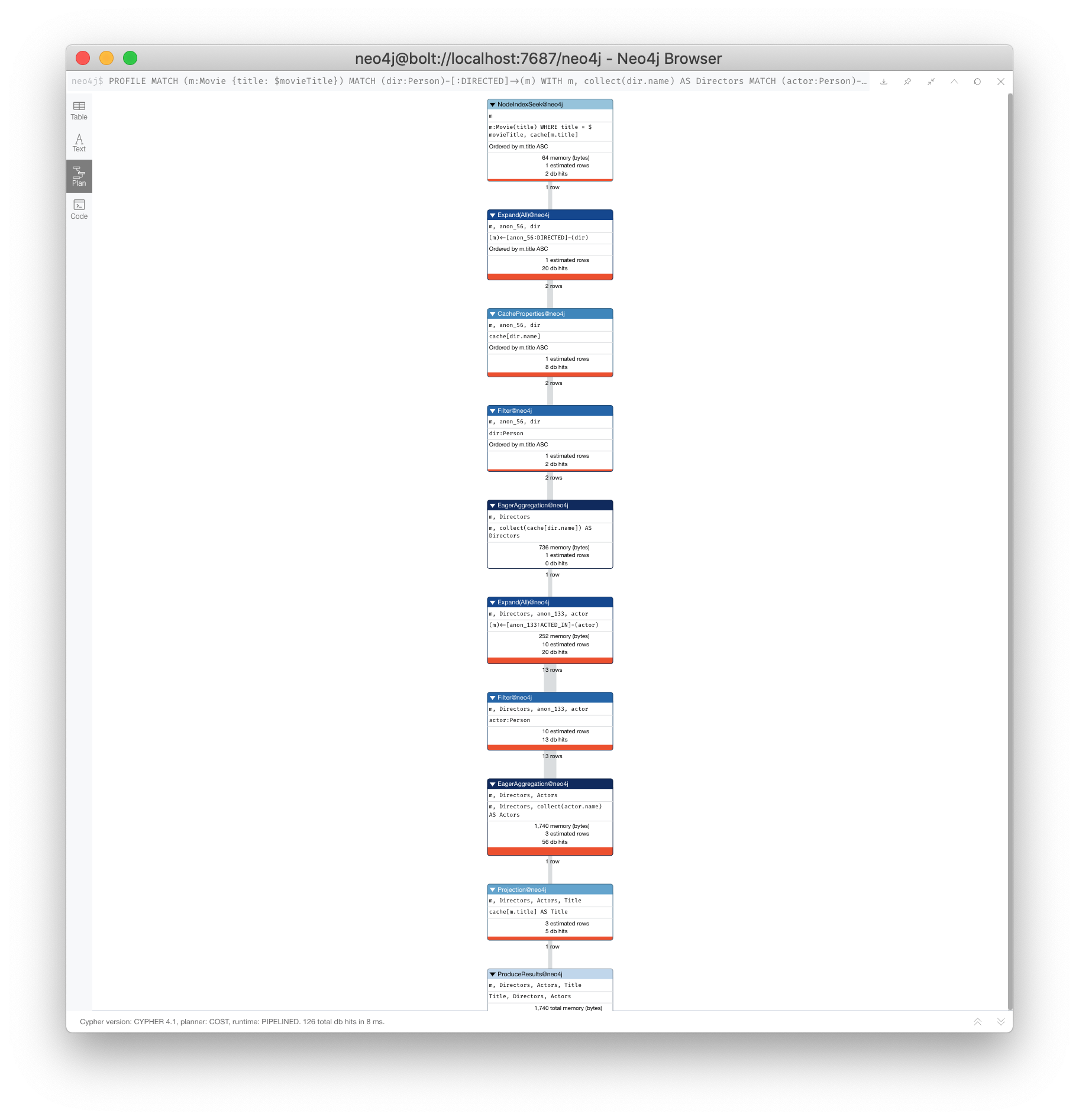
Here we see that the number of rows has been reduced and subsequently we also see that the number of db hits has been reduced.
Reducing cardinality with pattern comprehension
Pattern comprehension is a very powerful way to reduce cardinality. It behaves like an OPTIONAL MATCH combined with collect().
It behaves line an inline subquery.
Here is a rewrite of the original query using pattern comprehension:
PROFILE
MATCH (m:Movie {title: $movieTitle})
RETURN m.title,
[(dir:Person)-[:DIRECTED]->(m) | dir.name] AS Directors,
[(actor:Person)-[:ACTED_IN]->(m) | actor.name] AS ActorsIn the RETURN statement, we are returning two lists, but they are created using pattern comprehension.
A match pattern is specified that creates the lists by performing an implicit match and in this case, extracts the name property from the nodes retrieved.
Pattern comprehension does introduce new identifiers, but they are very useful especially if you want to do some filtering with WHERE and computing an expression as the result.
For example: [pattern WHERE <predicate> | <expression>]
Here is the execution plan for this query:
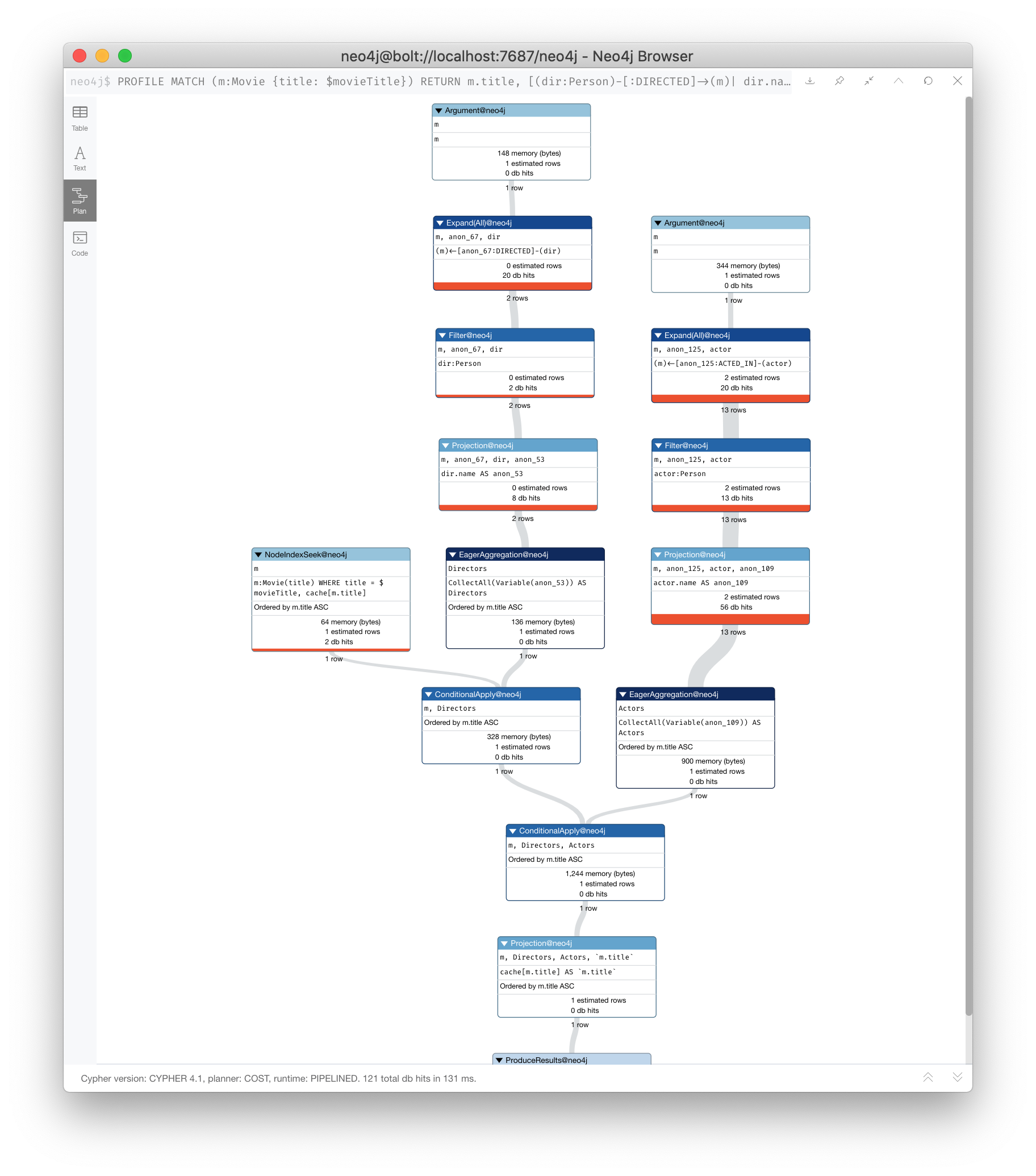
Here we see that the query retrieves the movie row and finds 2 rows for directors. With pattern comprehension, these 2 rows are collected and 1 row is then passed to the next pattern comprehension specified for actors. The 13 rows are collected into 1 row so that the final number of rows returned is 1. The use of pattern comprehension is slightly better and reduces the number of db hits.
Exercise 3: Reducing cardinality with aggregation
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-query-tuning-exercises
and follow the instructions for Exercise 3.
| This exercise has 3 steps. Estimated time to complete: 20 minutes. |
Reducing cardinality with anchor node selectivity
In your MATCH statement patterns, strive to create execution plans that either use an index or label (which is also an index).
In your execution plans, you may see these operators at the leaf steps:
-
NodeByLabelScan
-
Operators that use an index:
-
NodeIndexSeek
-
NodeUniqueIndexSeek
-
MultiNodeIndexSeek
-
NodeIndexSeekByRange
-
NodeUniqueIndexSeekByRange
-
NodeIndexContainsScan
-
NodeIndexEndsWithScan
-
NodeIndexScan
-
You never want to see AllNodesScan in an execution plan.
Reducing cardinality with labels
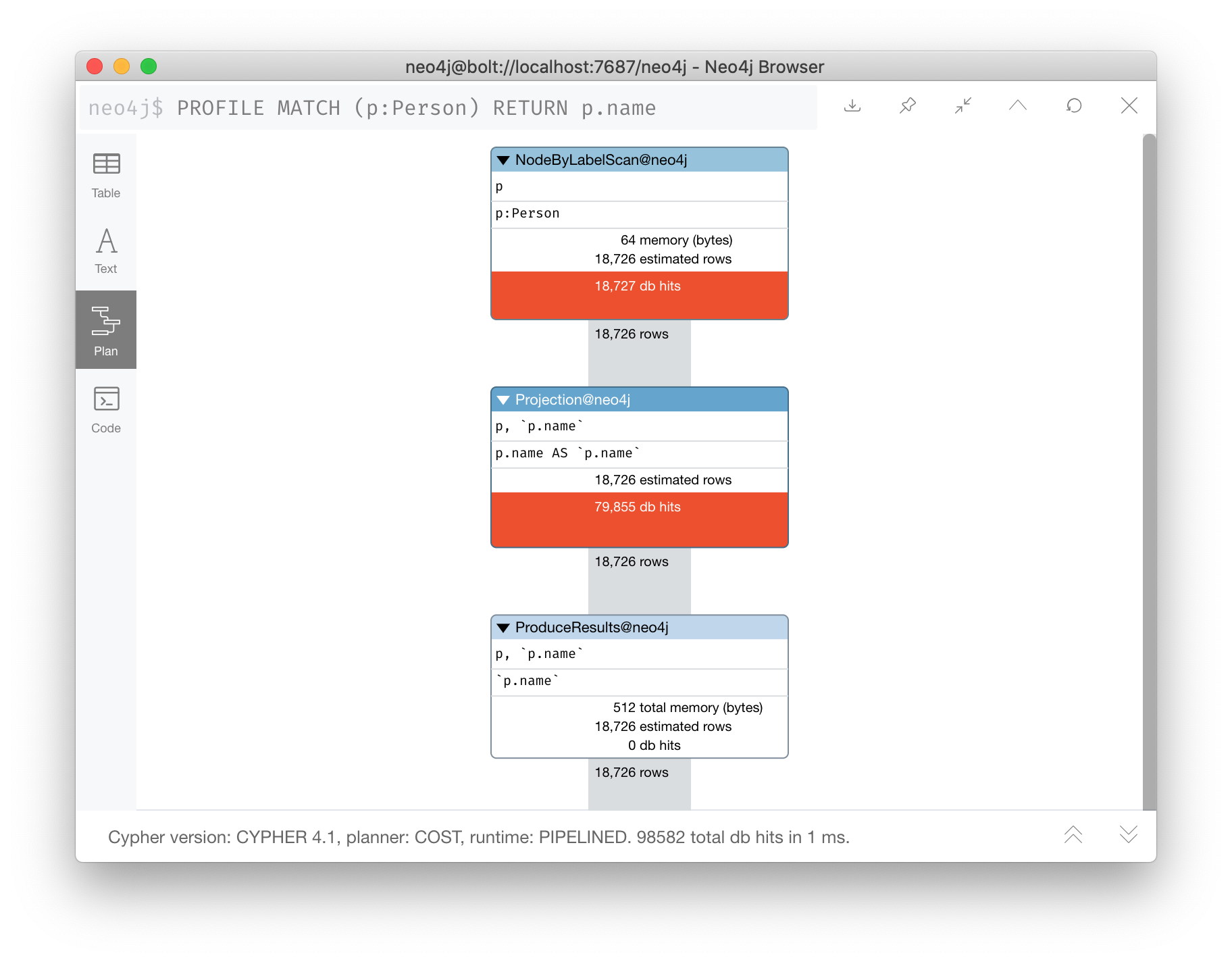
You want to see NodeByLabelScan in your execution plans if an index cannot be used. You must be familiar with how labels are used. Ideally you want the greatest selectivity for the anchor nodes.
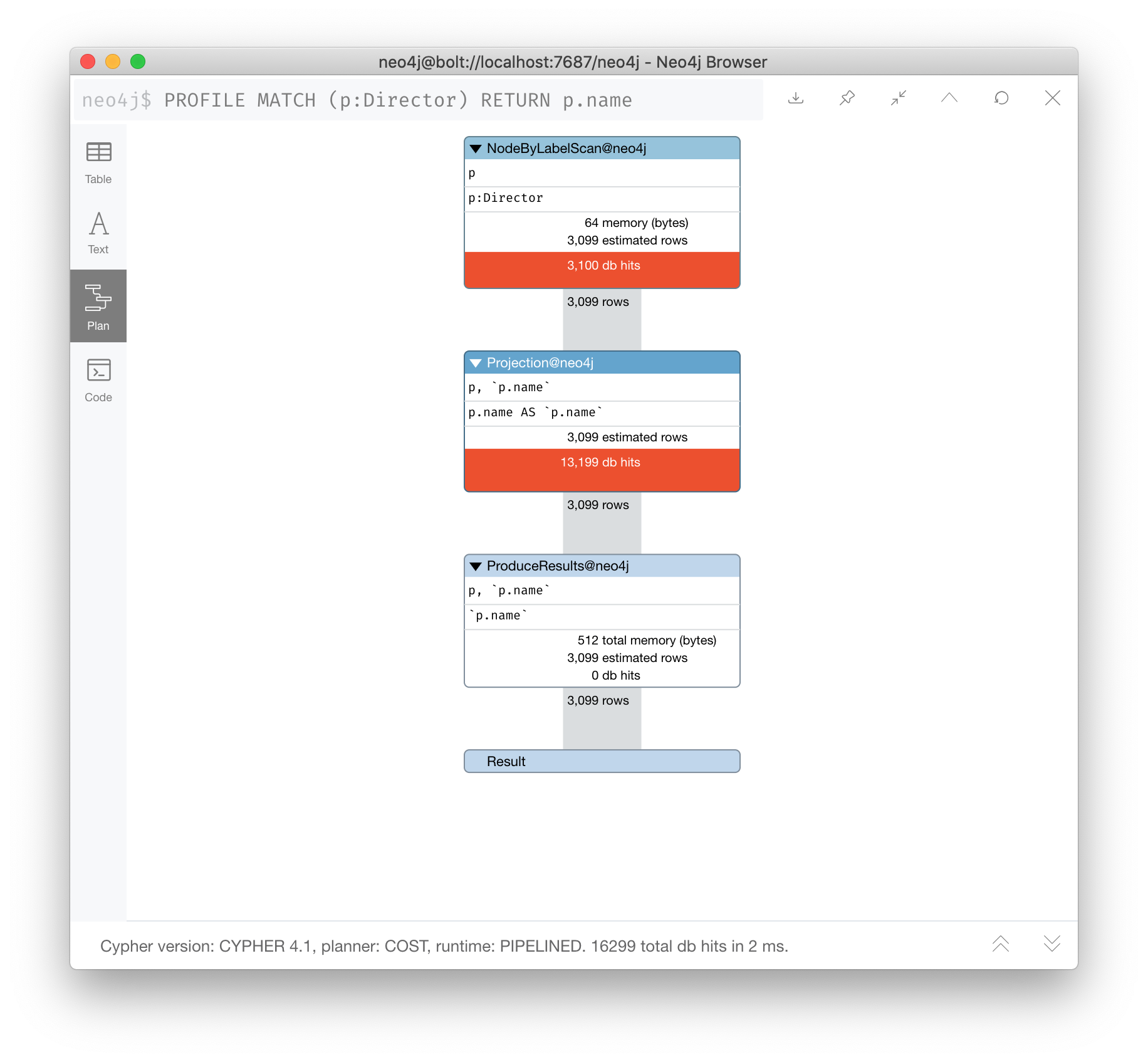
For example, here is a query that will use NodeByLabelScan:
PROFILE
MATCH (p:Person)
RETURN p.nameIt returns 18,726 rows.
Reducing cardinality with indexes
A really big win for reducing cardinality is to ensure that indexes can be used for your queries, especially if they represent unique constraints for a value. If a query is performed frequently by the application, you must add an index for the property that is used for the query. The type of index-related step in the execution plan will depend upon the type of filtering your query requires.
Another type of index you can create in the database is the full-text schema index which provides additional indexing capabilities that you do not get from regular indexes:
-
multiple labels
-
properties of relationships
-
support for case-insensitive lookup
-
wildcard lookup
-
custom lucene analyzers
Example: A query that needs improvement
Here is an example where a full-text schema index helps. We want to query the roles in the ACTED_IN relationships. For this example, the value of $testString is "CABBIE".
PROFILE
MATCH (a:Actor)-[r:ACTED_IN]->(m:Movie)
WHERE ANY (role IN r.roles WHERE toUpper(role) CONTAINS $testString)
return m.title, r.roles, a.nameHere is the execution plan for this query:

We see that to execute this query, we need many rows (6231,6231,56914,7). This spike in rows needed is something you never want to see in an execution plan. This query requires 185,771 db hits!
If this query is one that the application uses frequently, you will want to modify things so that it performs better.
Example: Refactoring the graph
We know that full-text schema indexes allow you to create indexes on relationship properties. This is what we want to do to improve the query.
The caveat, however is that the roles property of the ACTED_IN relationship contains a list of roles and we cannot create a full-text schema index on a list of strings. To solve this problem, we will refactor the graph to have 2 properties for the ACTED_IN relationship:
-
primaryRole
-
secondaryRole
We refactor the graph as follows, keeping the roles property as is:
MATCH (a:Actor)-[r:ACTED_IN]->(m:Movie)
SET r.primaryRole = r.roles[0], r.secondaryRole = r.roles[1]As you learn about graph data modeling and implementing graphs, you will find that sometimes you will need to refactor the graph to improve query performance.
It is also possible to create an index on a comma-separated list with apoc.text.join(r.roles,",").
|
Example: Rewritten query with the refactored graph?
So the previous query with this change is:
PROFILE
MATCH (a:Actor)-[r:ACTED_IN]->(m:Movie)
WHERE toUpper(r.primaryRole) CONTAINS $testString OR
toUpper(r.secondaryRole) CONTAINS $testString
RETURN m.title, r.roles, a.nameAnd we see an execution plan that is still not performing well:
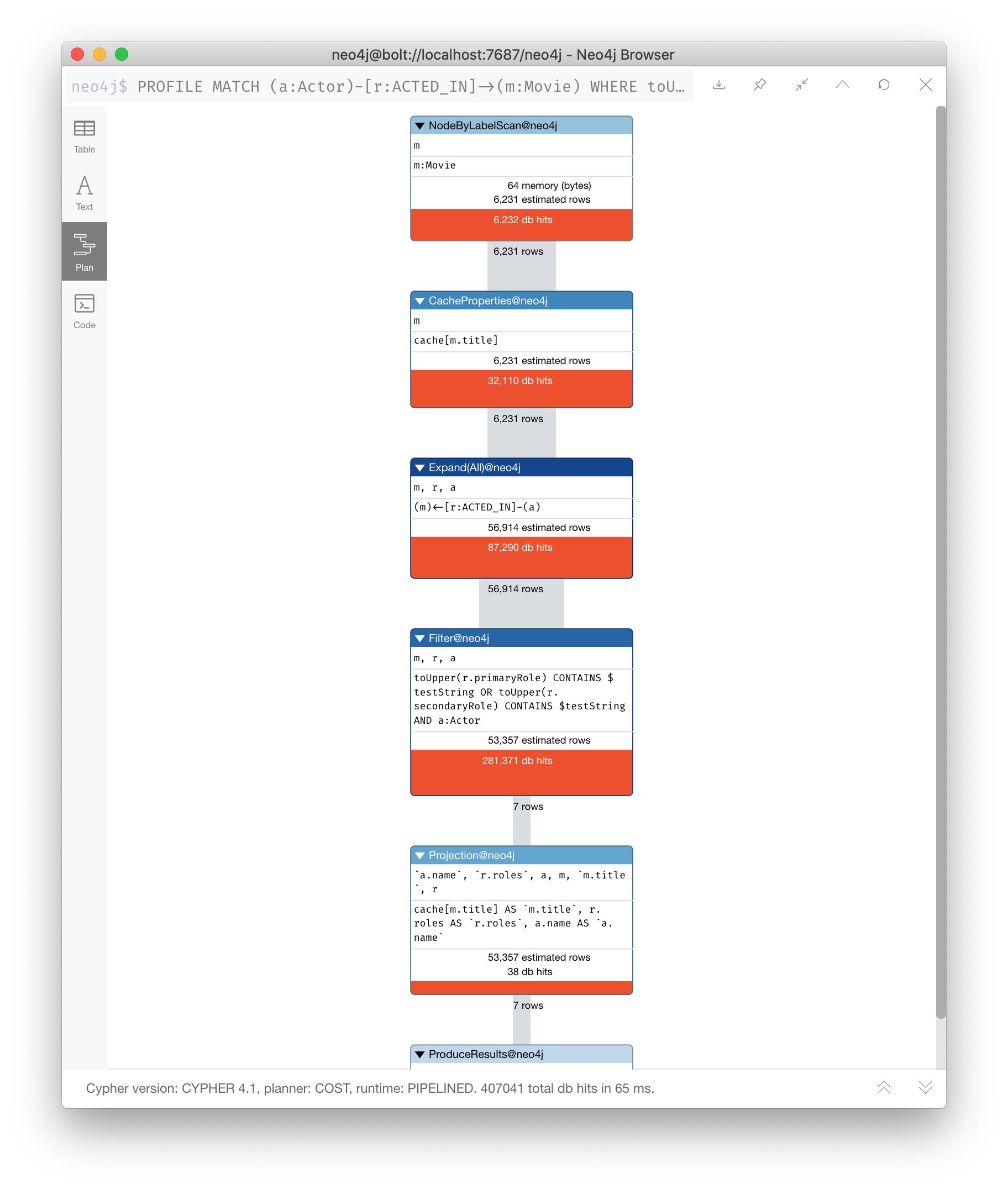
It has even more db hits, 407,041 because the properties are stored in different physical locations and require greater db access.
Solution: Adding a full-text schema index
Now that we have separated out the values for the roles, we can add a full-text schema index for these properties:
CALL db.index.fulltext.createRelationshipIndex(
'ActedInRoleIndex',['ACTED_IN'], ['primaryRole','secondaryRole'])Example: Using the full-text schema index
After adding this type of index, we can query the graph, but the query will change. Because it is a full-text schema index, it must be called differently and the query changes to something like this:
PROFILE
CALL db.index.fulltext.queryRelationships(
'ActedInRoleIndex', $testString) YIELD relationship
WITH relationship AS rel
RETURN startNode(rel).name, endNode(rel).title, rel.rolesHere is the execution plan for this query:
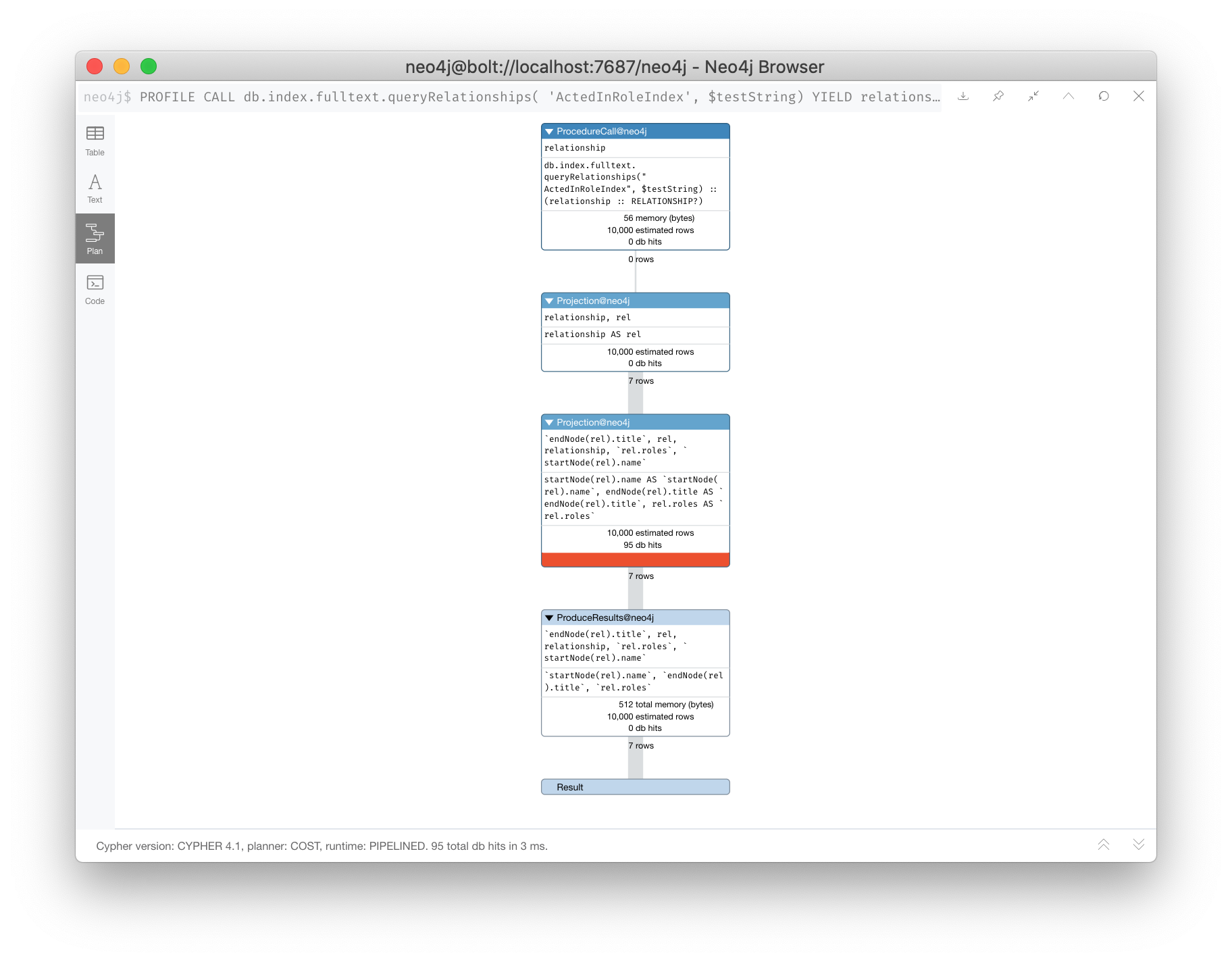
We can’t really compare db hits here because we are calling a procedures for the full-text schema search, but we do see fewer rows in the execution plan. In the previous query (before adding the full-text schema index), the execution plan performed a NodeByLabelScan which produced a lot of rows. We have already determined from the call to queryRelationships which particular relationships are associated with the index. The problem, however is that the execution plan scans for all relationships between Actors and Movies. This is a problem.
Example: Improved query using full-text schema index
The solution to this is the remove the labels from the MATCH statement so that only the found relationships will be used to retrieve the appropriate Actor and Movie nodes.
Here is the improved query:
PROFILE
CALL db.index.fulltext.queryRelationships(
'ActedInRoleIndex', $testString) YIELD relationship
WITH relationship AS rel
MATCH (a)-[rel]->(m)
RETURN a.name, m.title, rel.rolesIn this special case, we do not want the NodeByLabel scan to occur. Here is the execution plan:
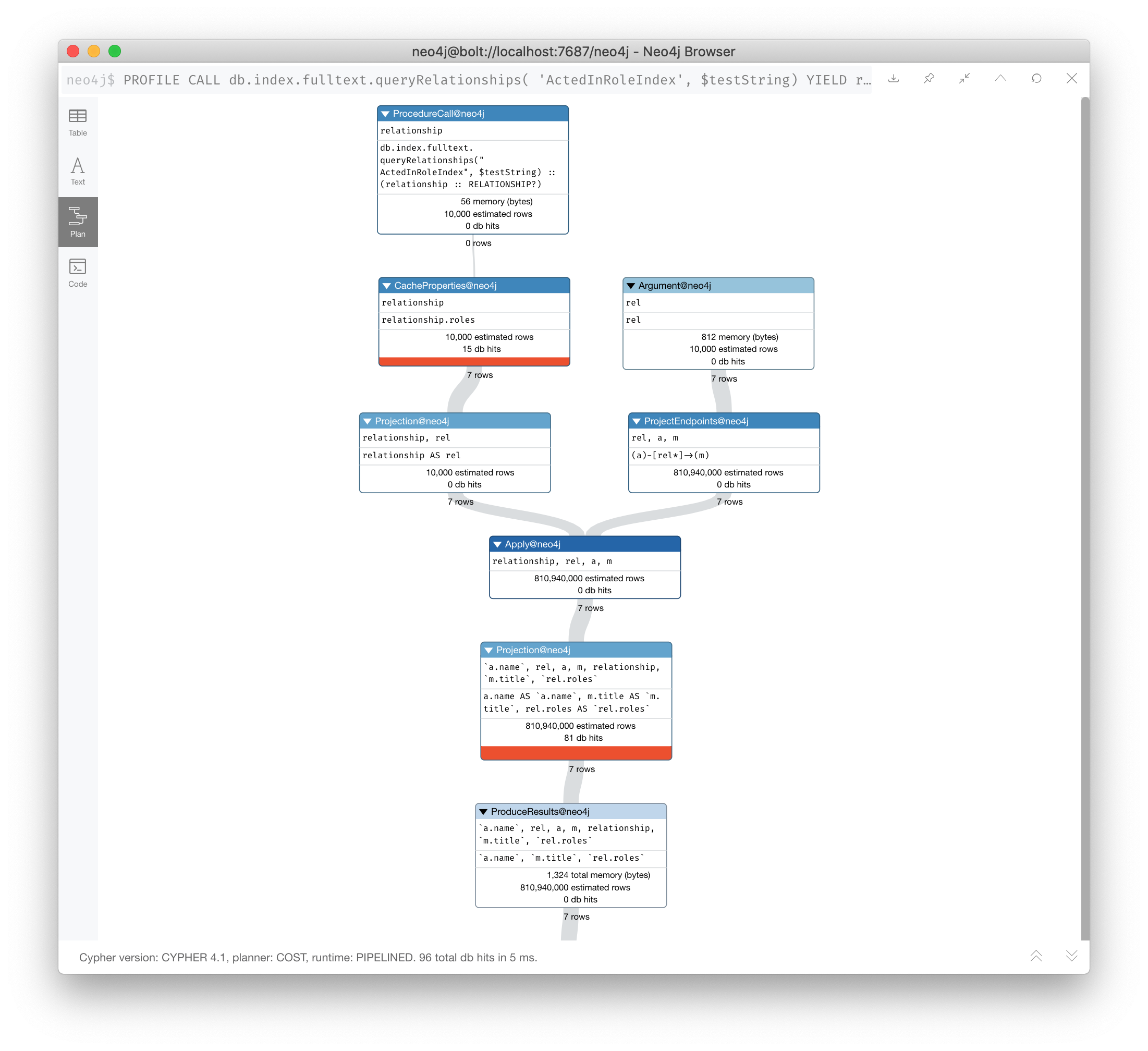
This is much better. We see far fewer rows, no NodeByLabelScan, much fewer db hits, and a smaller elapsed time.
| When you call a procedure in Cypher, the execution plan shows zero db hits. When calling procedures, you will mainly rely on rows and elapsed time. |
When you use CALL for a subquery, however, db hits are measured.
Full-text schema indexes can be used in these special cases where you want to optimize access to a property of a relationship. They are also good for optimizing case-insensitive searches on any node or relationship property string.
Reducing cardinality with query hints
If the database has indexes, strive to ensure that execution plans use them. Ideally, you want indexes that have values with the lowest selectivity. The query planner will always choose to use indexes with low selectivity values.
By default, the execution plan will use a single index.
Here is a query that uses an index $actor1 is "Tom Cruise" and $actor2 is "Kevin Bacon".
PROFILE
MATCH p = (p1:Person)-[:ACTED_IN*4]-(p2:Person)
WHERE p1.name = $actor1
AND p2.name = $actor2
RETURN [n IN nodes(p) | coalesce(n.title, n.name)]It finds all paths that represent 4 hops between two actors where $actor1 is "Tom Cruise" and $actor2 is "Kevin Bacon". Then it returns a list of names or titles for the nodes in the paths found.
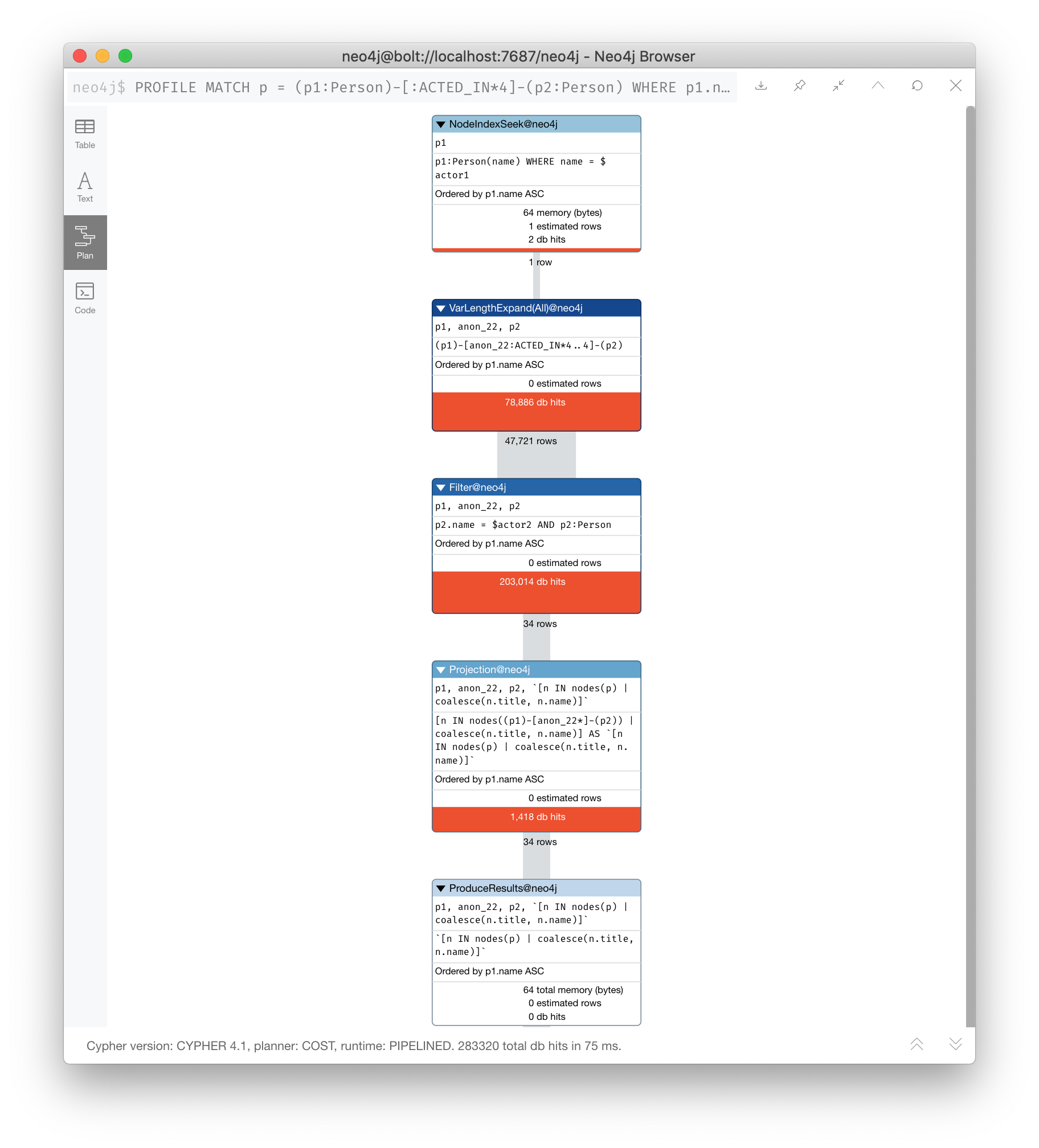
The index on Person.name is used for the MATCH for the p1 side of the query path, but then you see that there are 47,721 rows retrieved and then 34 rows filtered to return the data required. A total of 283,320 db hits.
In this example, we are interested in all possible paths of this length. If you only need one, use shortestPath() for significantly better performance.
|
Using query hints
You can force the use of more than one index so that an index is used to find p1 nodes and p2 nodes:
PROFILE
MATCH p = (p1:Person)-[:ACTED_IN*4]-(p2:Person)
USING INDEX p1:Person(name)
USING INDEX p2:Person(name)
WHERE p1.name = $actor1
AND p2.name = $actor2
RETURN [n IN nodes(p) | coalesce(n.title, n.name)]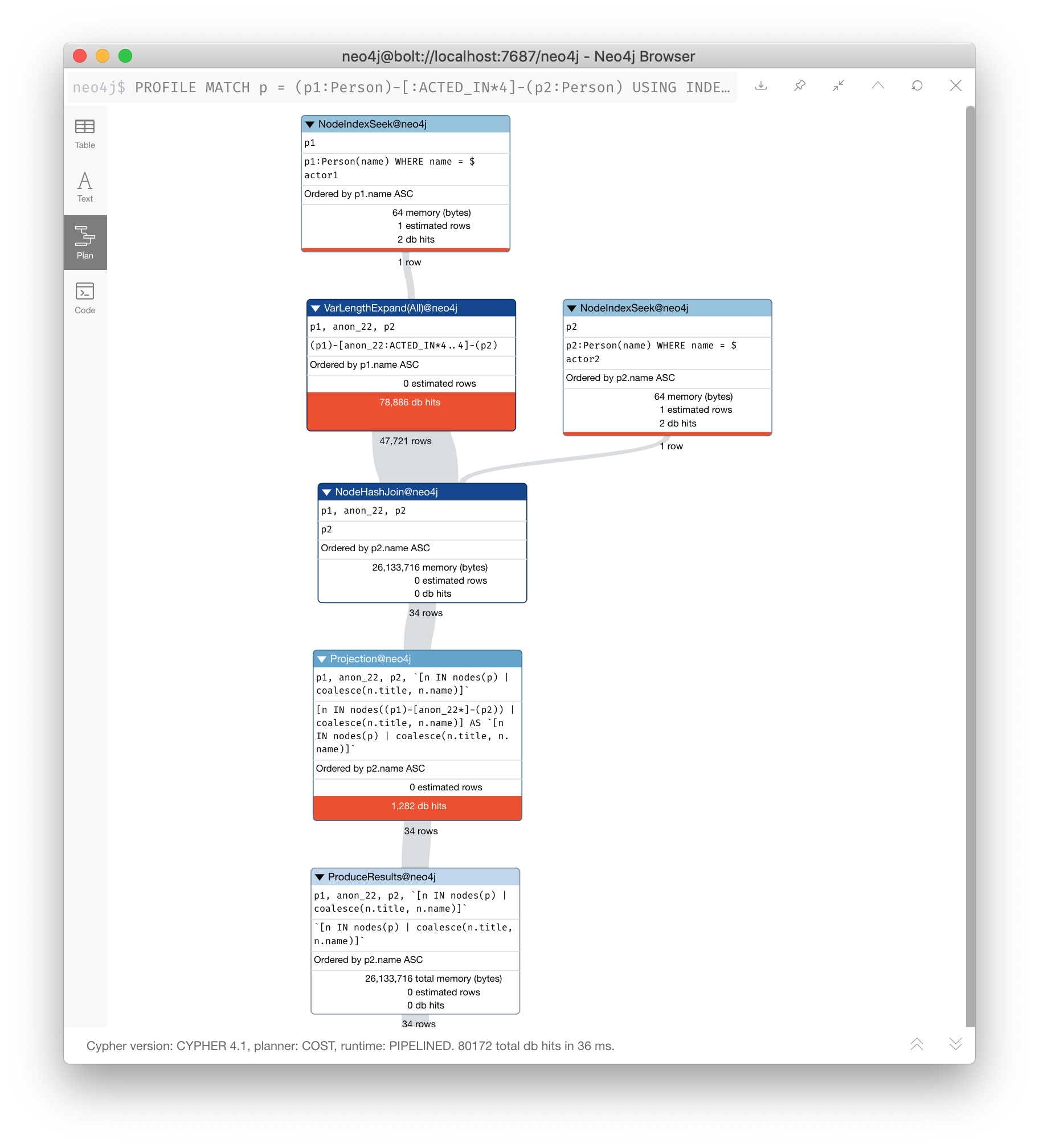
Here we see fewer rows and fewer db hits, as well as a reduced elapsed time.
What you will find is that the performance of this type of query when the indexes are unique will out-perform indexes that are non-unique because the runtime stops fetching from them after the first result. In this database, the Person.name index is not unique. But for this particular database, there is only one actor named Tom Cruise and one actor named Kevin Bacon. If the database had multiple actors with these names, you would see a greater performance degradation (and cardinality) with using multiple indexes.
Use query hints with caution
Use caution, however when you are explicitly specifying the use of indexes. Here are some things to consider:
-
The planner will take the selectivity of an index into account when evaluating equality.
-
Forcing a plan means that planner cannot adapt when the underlying data changes.
-
Your plan may be more efficient specifically while being less efficient generally.
-
Hints can inform the planner about the structure of your data in ways the planner cannot infer itself.
-
If you do use hints, use them to force the plan around aspects of the data model that will remain consistent.
USING SCAN
Just like you can explicitly specify if/when an index will be used or assume the index will be automatically used, you can also specify not to use an index. You would specify not to use an index if one of your node labels represented the data you are interested in retrieving. For example, you can set a flag or status label to a set of nodes that you know will be queried. That way, you need not access any properties.
In our graph, there is an index on the Genre nodes. By default, any query that is based upon the name property will use the index. If you want to scan the nodes by their label and not use the index, then you can specify:
PROFILE
MATCH (g:Genre)
USING SCAN g:Genre
WHERE g.name CONTAINS $text
RETURN g.nameWhether queries that rely simply on labels, rather than the index, will depend on your data model.
Using JOIN to reduce cardinality
JOIN is useful when you are performing queries on patterns that are focused on a particular node. This is particularly useful for dense nodes.
Here is our starting query:
PROFILE
MATCH (a)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d)
RETURN collect(a.name), m.title, collect(d.name)
Adding JOIN
We can add JOIN to this query:
PROFILE
MATCH (a)-[:ACTED_IN]->(m:Movie)<-[:DIRECTED]-(d)
USING JOIN ON m
RETURN collect(a.name), m.title, collect(d.name)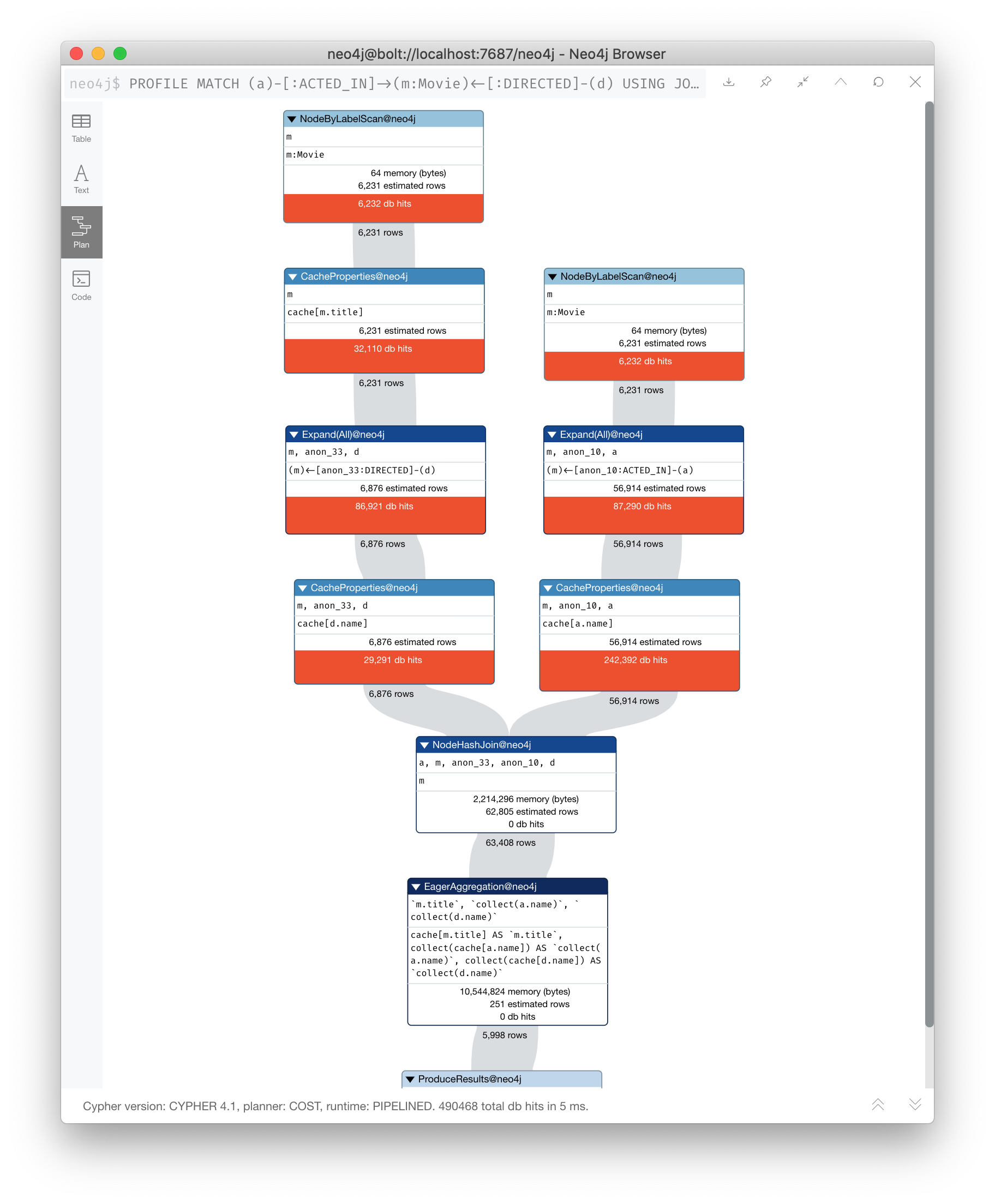
What happens here is that it does two expands to follow the path to m from a and from d. Then it compares the m’s from each side with each other in a hash-join. There are fewer rows in the execution plan, as well as db hits, and a lower execution time.
Exercise 4: Reducing Cardinality with Anchor Selectivity
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-query-tuning-exercises
and follow the instructions for Exercise 4.
| This exercise has 3 steps. Estimated time to complete: 20 minutes. |
LIMIT is too far down in the query
If the query is written so that a limited number of results are returned, it is best to move the LIMIT up in the query.
Here is an example:
PROFILE
MATCH (m:Movie)<-[:ACTED_IN]-(a)
WITH m, collect(a) AS Actors
RETURN m.title as Title, Actors LIMIT 10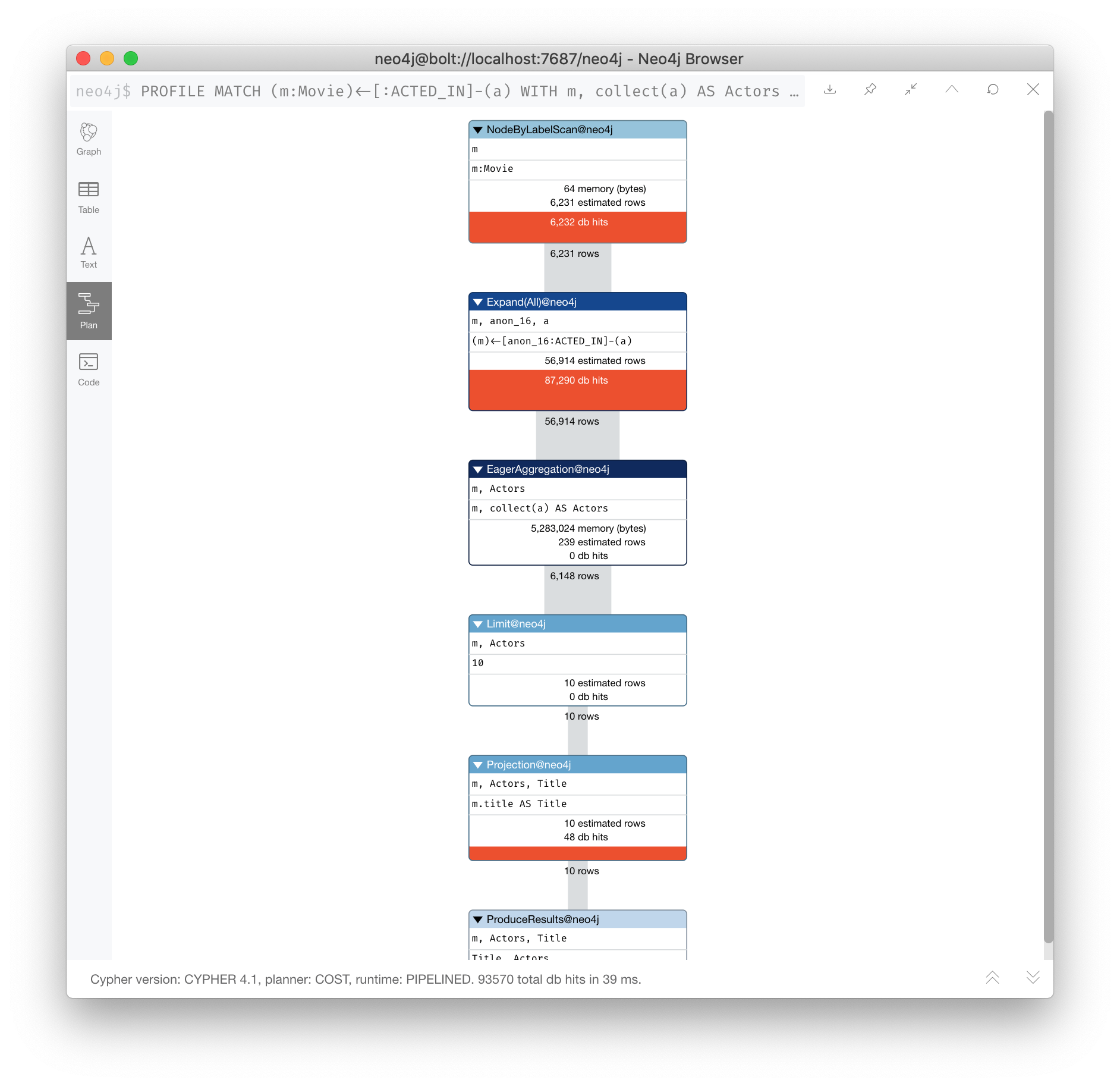
Here you can see that after the initial query, many rows are passed through the steps of the execution plan.
Solution: Moving LIMIT up in the query
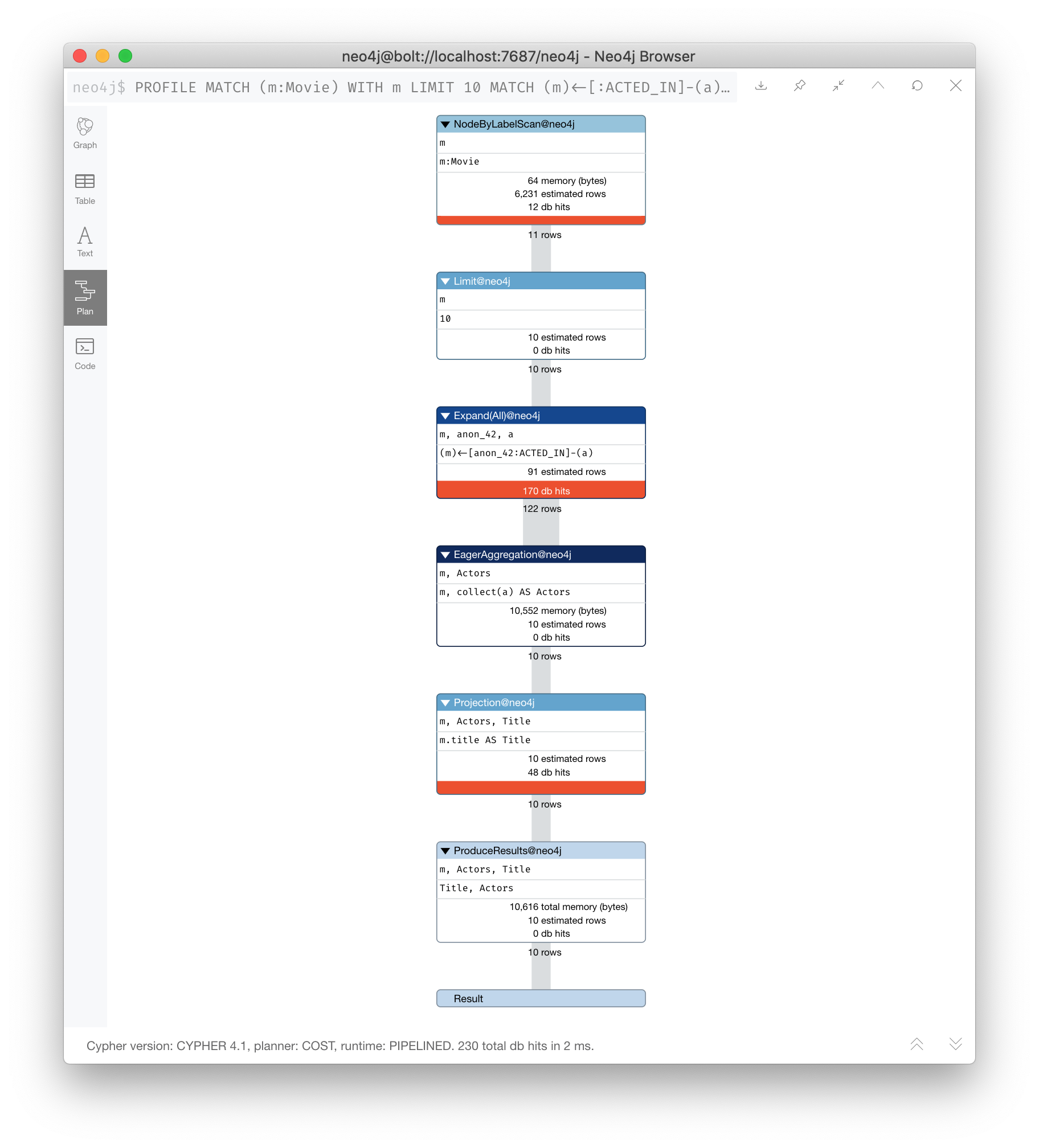
Here is a better way to do it:
PROFILE
MATCH (m:Movie)
WITH m LIMIT 10
MATCH (m)<-[:ACTED_IN]-(a)
WITH m, collect(a) AS Actors
RETURN m.title AS Title, ActorsWe know ahead of time that we want 10 rows, one for each movie so expanding after we have retrieved the 10 rows is better.
DISTINCT is too far down in the query
DISTINCT is another way that you can reduce row cardinality in the execution plan. Just like you just saw how to move LIMIT earlier in the query, you can move DISTINCT up to reduce rows required.
Here is another example where we have set $titleMatch to "Matrix"
PROFILE
MATCH (p:Person)-[:ACTED_IN| DIRECTED]->(m)
WHERE m.title CONTAINS $titleMatch
WITH p
MATCH (p)-[:ACTED_IN]->()<-[:ACTED_IN]-(p2:Person)
RETURN DISTINCT p.name, p2.nameThis query finds all people who acted in or directed a movie with $titleMatch in the title.
This query will return duplicate Person nodes because some people both acted in and directed movies.
Then we have a subsequent query where we use the returned people to find other people who have acted in a movie with the first actor, p.
We then use DISTINCT to ensure that we have distinct rows in our return.

Solution: Moving DISTINCT further up in the query
We can make a slight improvement by moving DISTINCT earlier in the query:
PROFILE
MATCH (p:Person)-[:ACTED_IN| DIRECTED]->(m)
WHERE m.title contains $titleMatch
WITH DISTINCT p
MATCH (p)-[:ACTED_IN]->()<-[:ACTED_IN]-(p2:Person)
RETURN p.name, p2.name
It has slightly better execution time and we definitely see fewer rows in the execution plan.
Use UNWIND judiciously
UNWIND creates rows so if you use it, be aware that you are introducing more rows.
Sometimes UNWIND is useful, especially if you are creating relationships or refactoring nodes in the graph.
Here is an example where we do a query to find all Movie nodes that are between two Person nodes by at most 4 hops.
In this example $actor1 is "Tom Cruise" and $actor2 is "Kevin Bacon".
We use UNWIND to create the rows for all nodes visited:
PROFILE
MATCH path = (p1:Person)-[:ACTED_IN*4]-(p2:Person)
USING INDEX p1:Person(name)
USING INDEX p2:Person(name)
WHERE p1.name = $actor1
AND p2.name = $actor2
UNWIND (nodes(path)) as visitedNode
WITH DISTINCT visitedNode
WHERE visitedNode:Movie
RETURN visitedNode.title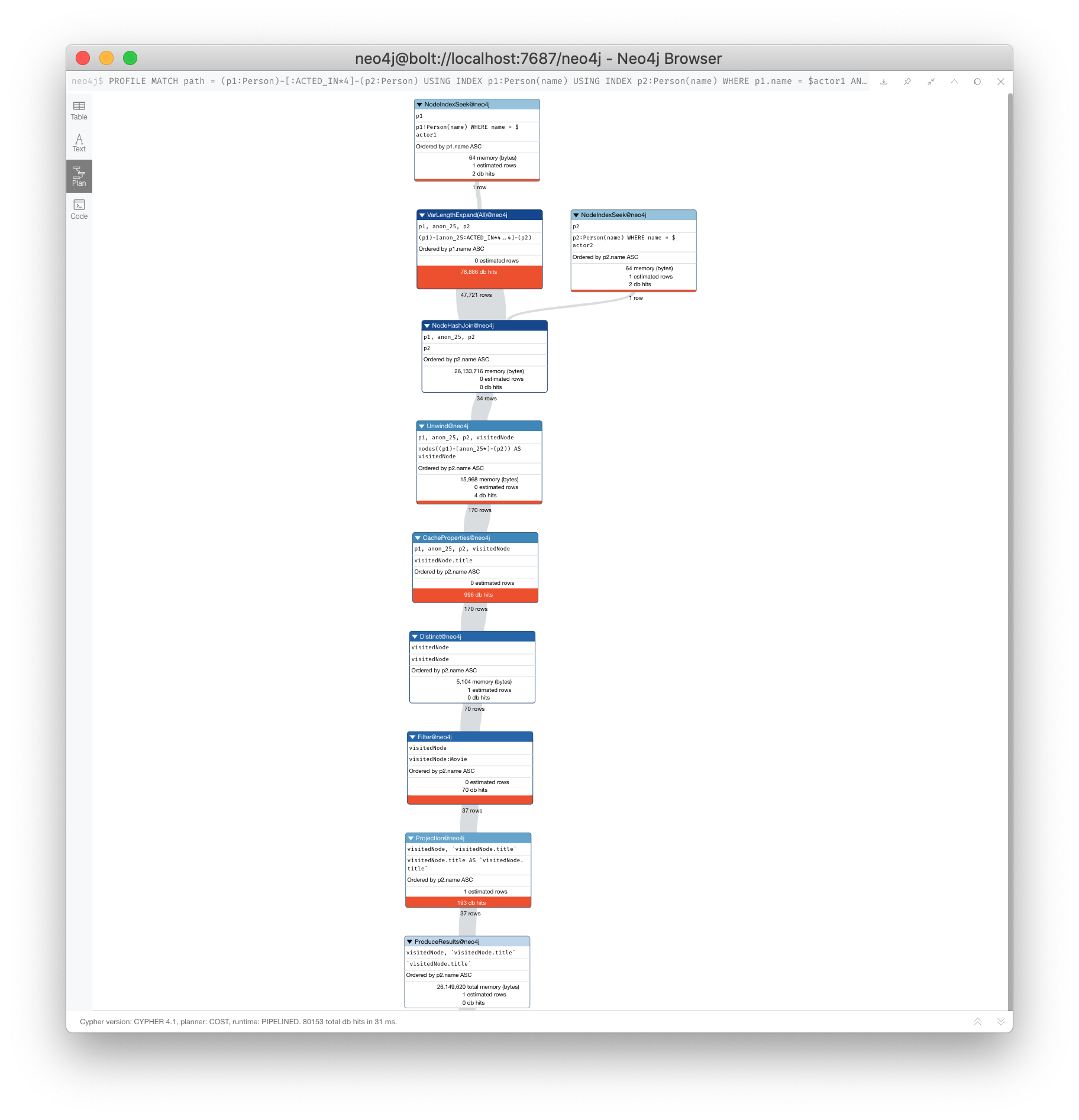
The UNWIND adds 170 rows to the query. This isn’t that bad considering the total number of rows passed between the steps of the execution plan.
Another UNWIND example
Here is another example where we use UNWIND to combine lists to return rows to process:
PROFILE
MATCH (p1:Person)-[:ACTED_IN]-(m1)-[:ACTED_IN]-(p)-[:ACTED_IN]-(m2)-[:ACTED_IN]-(p2:Person)
USING INDEX p1:Person(name)
USING INDEX p2:Person(name)
WHERE p1.name = $actor1
AND p2.name = $actor2
WITH collect(m1) as movies1, collect(m2) as movies2
UNWIND (movies1 + movies2) as VisitedNode
WITH DISTINCT VisitedNode
RETURN VisitedNode.title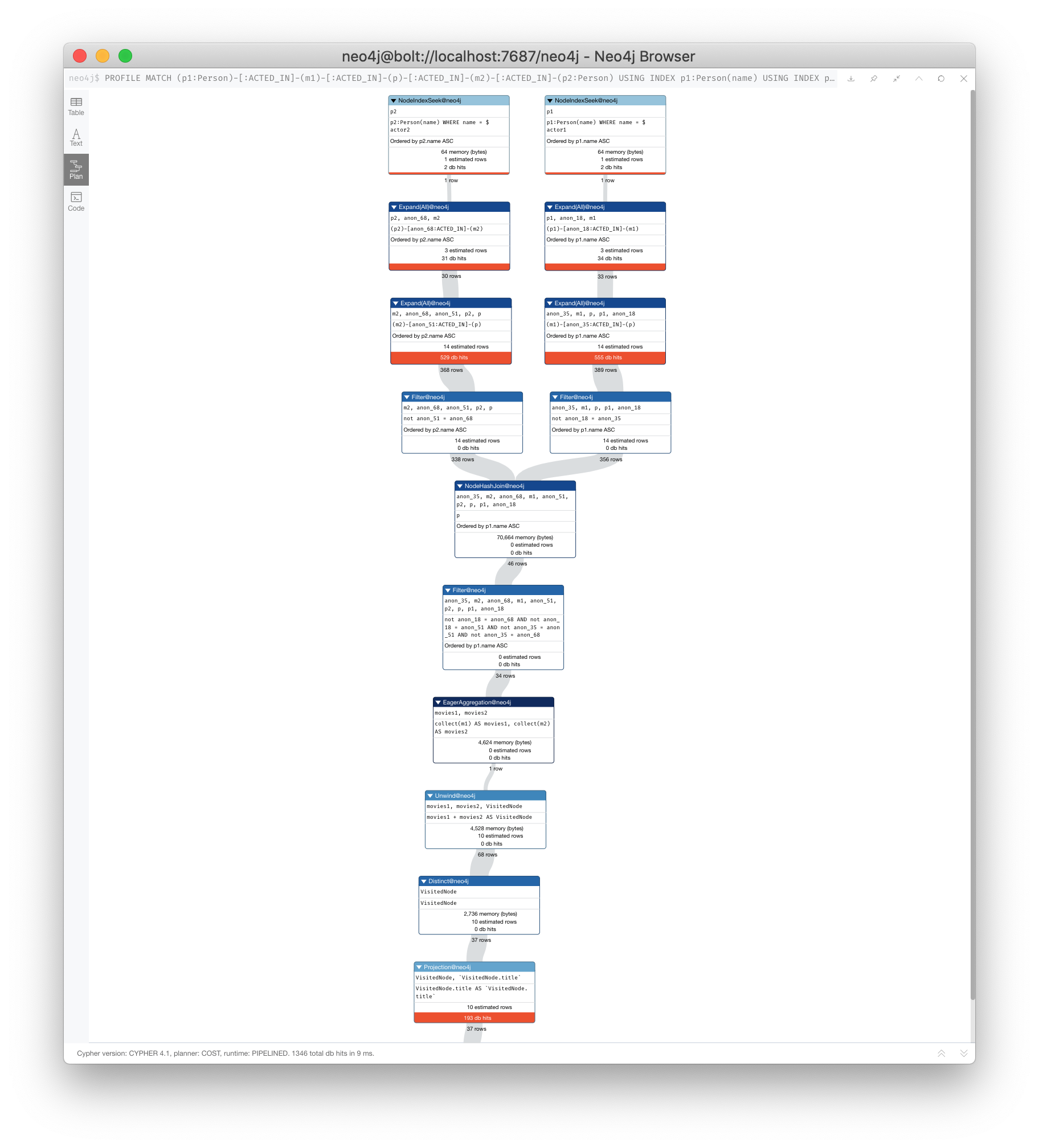
This version of the query produces fewer rows from the UNWIND and had better performance.
Cartesian products are expensive
Cartesian products are useful as hash-joins when you are creating relationships between nodes. But for read-only queries, aim to eliminate cartesian products in your queries.
Here is an example where we have set $year to 1990:
PROFILE MATCH (a:Actor), (m:Movie)
WHERE m.releaseYear = $year AND a.born > $year
RETURN collect(DISTINCT a) AS actors, collect(DISTINCT m) AS movies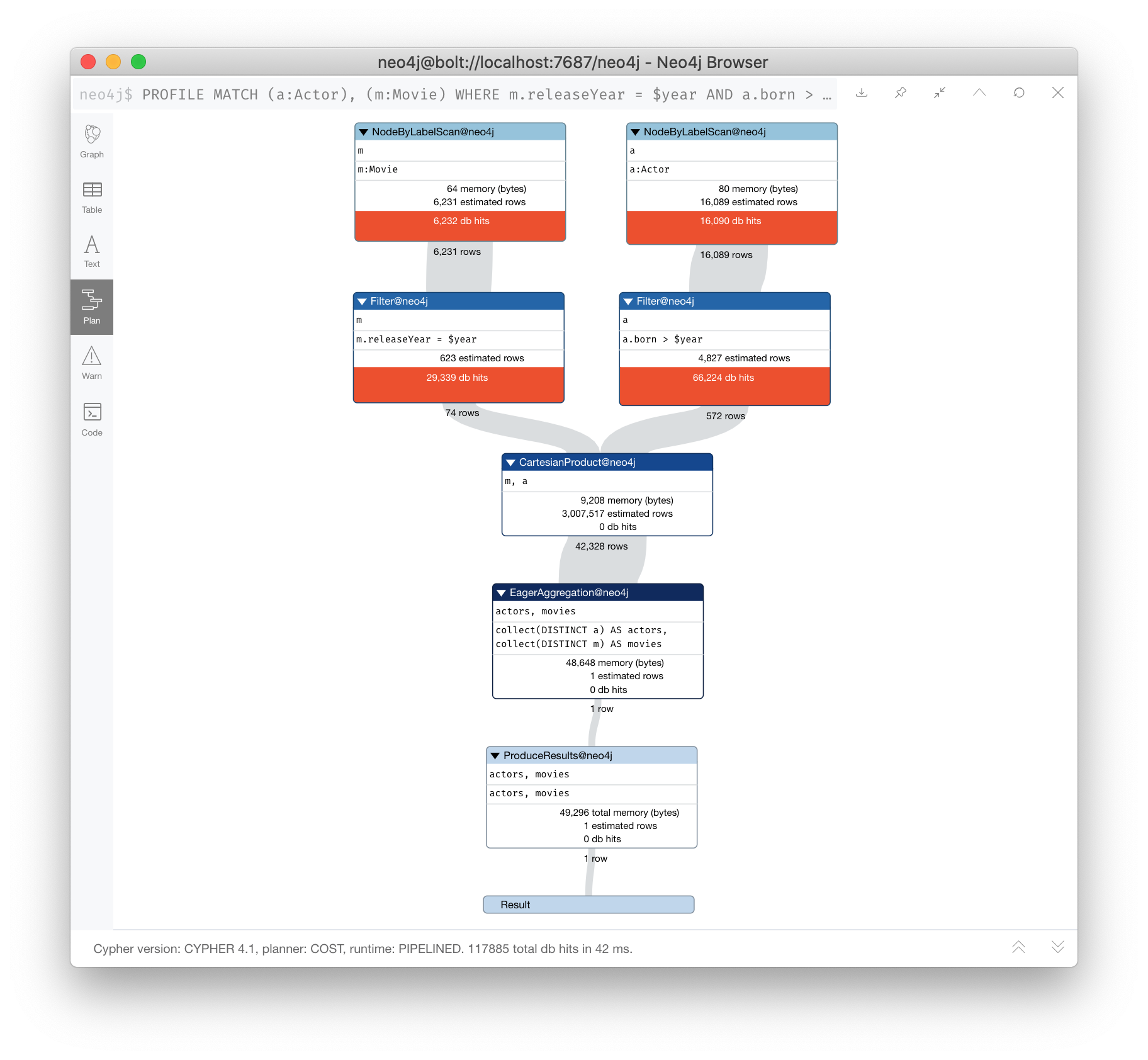
Solution 1: Eliminate cartesian products
Here is a better way to do the same query using subqueries:
PROFILE
CALL {
MATCH (m:Movie) WHERE m.releaseYear = $year RETURN collect(m) AS movies
}
CALL {
MATCH (a:Actor) WHERE a.born > $year RETURN collect(DISTINCT a) AS actors }
RETURN movies, actors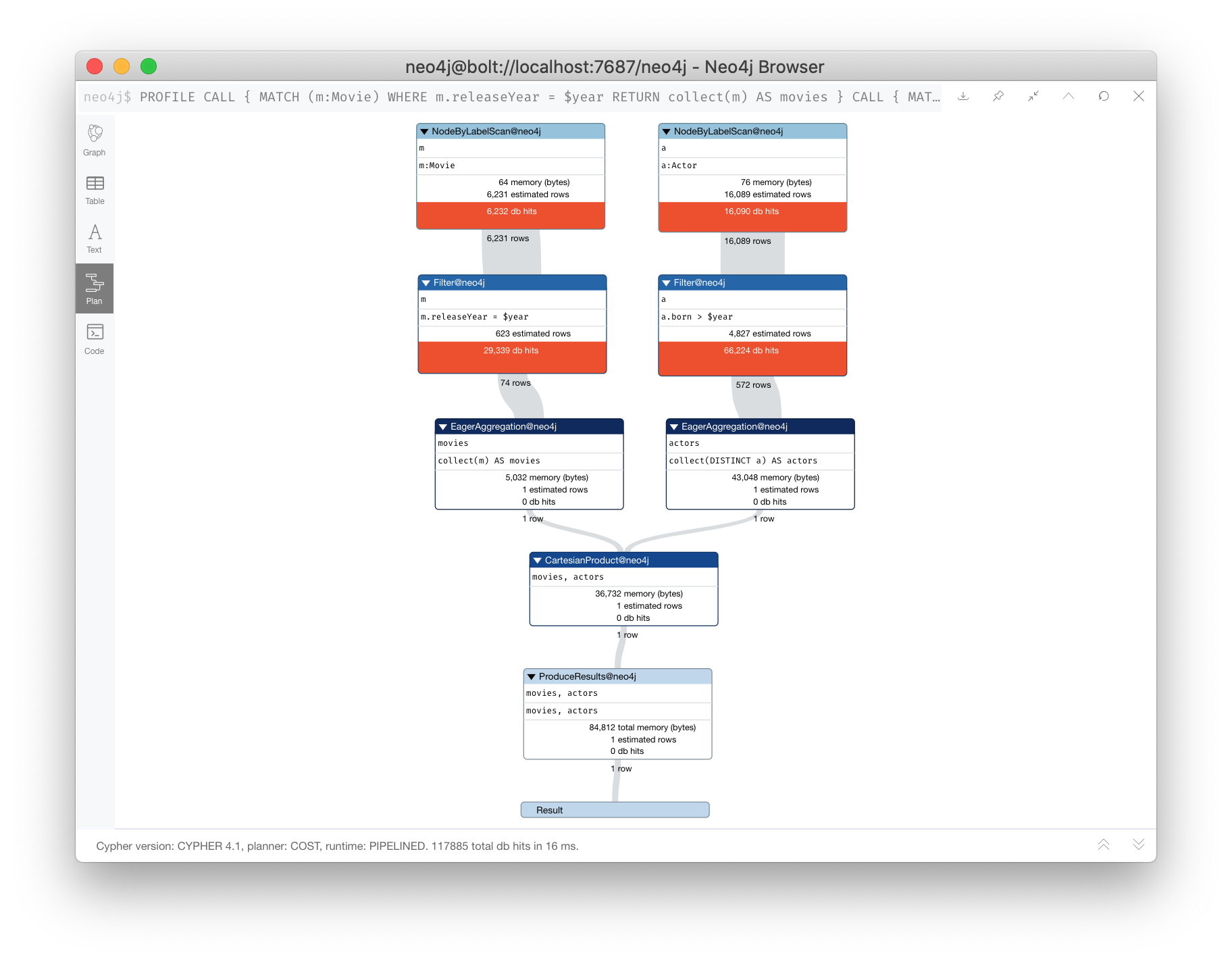
It is about the same number of db hits, but it performs much faster.
Solution 2: Eliminate cartesian products
Here is an even better way to do the same query using UNION:
PROFILE MATCH (m:Movie) WHERE m.releaseYear = $year
RETURN {type:"movies", movies: collect(m)} as data
union all
MATCH (a:Actor) WHERE a.born > $year
RETURN { type:"actors", count:collect(DISTINCT a)} AS data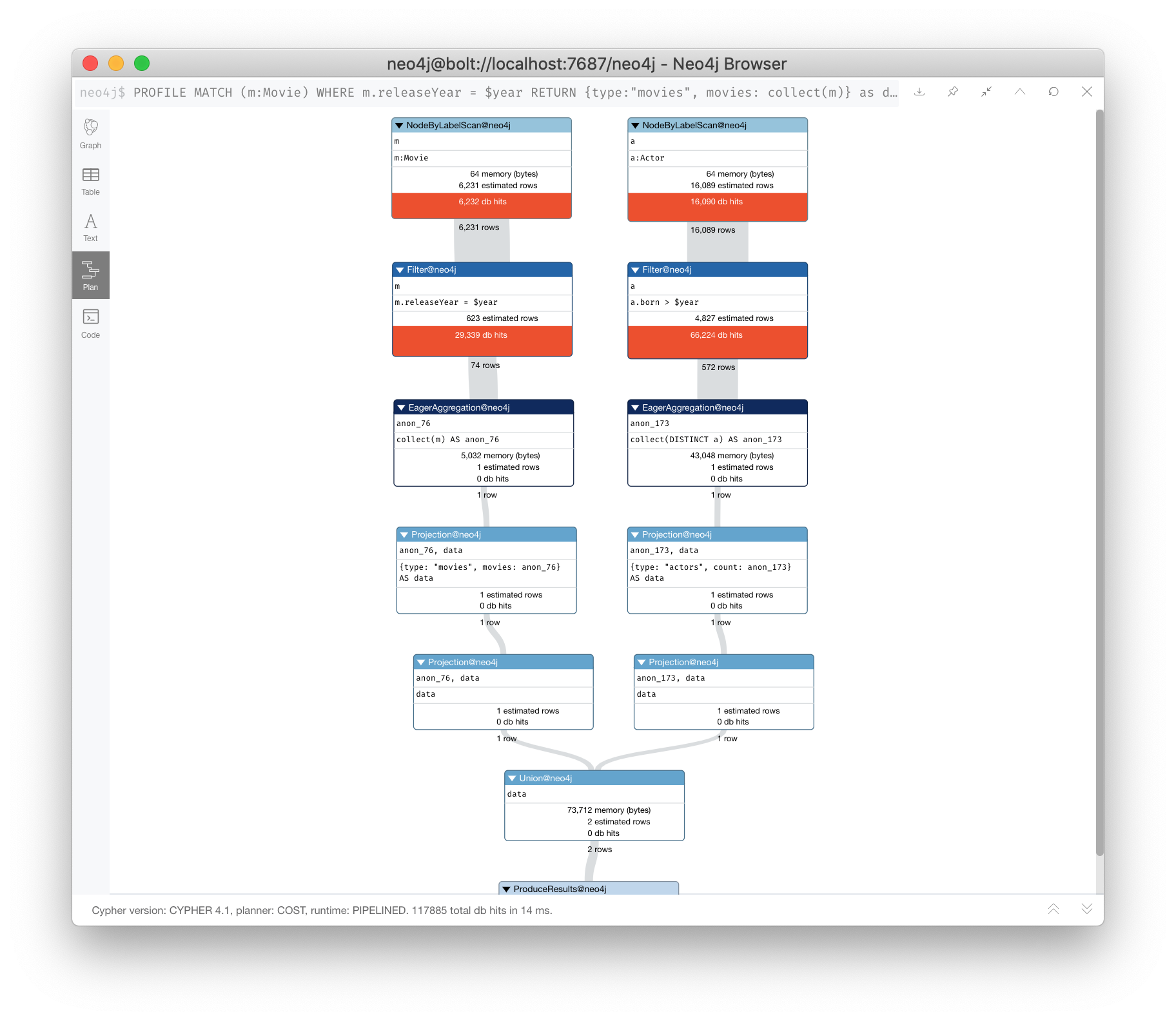
It is about the same number of db hits, but it performs slightly better than the use of subqueries.
Exercise 5: Reducing Cardinality with LIMIT, DISTINCT
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-query-tuning-exercises
and follow the instructions for Exercise 5.
| This exercise has 3 steps. Estimated time to complete: 20 minutes. |
Check your understanding
Question 1
Which of the following factors will impact the cardinality in the steps of an execution plan?
Select the correct answers.
-
Lack of selectivity for anchoring the query.
-
The number of nodes and relationships in the database.
-
Overuse of
UNWINDclauses -
Multiple back-to-back
MATCHstatements that return more than one row
Summary
You can now:
-
Describe cardinality in an execution plan.
-
Tune and rewrite queries to:
-
Aggregate early.
-
Use pattern comprehension.
-
Anchor node through selectivity by label.
-
Use indexes.
-
Use full-text schema indexes.
-
Use query hints for index usage.
-
Use
LIMITearly in the query. -
Use
DISTINCTearly in the query. -
Use
UNWINDto your advantage. -
Avoid cartesian products.
-
Need help? Ask in the Neo4j Community