Export to Cypher Script
The export to Cypher procedures export data as Cypher statements that can then be used to import the data into another Neo4j instance.
|
When exporting nodes, if a node label does not contain a unique constraint the exporter will add a If a node label does have a unique constraint, the property on which the unique constraint is defined will be used to ensure uniqueness. |
Available Procedures
The table below describes the available procedures:
The labels exported are ordered alphabetically.
The output of labels() function is not sorted, use it in combination with apoc.coll.sort().
|
Configuration parameters
The procedures support the following config parameters:
| name | type | default | description |
|---|---|---|---|
format |
String |
cypher-shell |
Export format. The following values are supported:
|
cypherFormat |
String |
create |
Cypher update operation type. The following values are supported:
|
separateFiles |
boolean |
false |
Export to separate files? This is useful for later use with the |
useOptimizations |
Map |
|
Optimizations to use for Cypher statement generation.
|
awaitForIndexes |
Long |
300 |
Timeout to use for |
Exporting to a file
By default exporting to the file system is disabled.
We can enable it by setting the following property in apoc.conf:
apoc.export.file.enabled=trueIf we try to use any of the export procedures without having first set this property, we’ll get the following error message:
Failed to invoke procedure: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your neo4j.conf |
Export files are written to the import directory, which is defined by the dbms.directories.import property.
This means that any file path that we provide is relative to this directory.
If we try to write to an absolute path, such as /tmp/filename, we’ll get an error message similar to the following one:
Failed to invoke procedure: Caused by: java.io.FileNotFoundException: /path/to/neo4j/import/tmp/fileName (No such file or directory) |
We can enable writing to anywhere on the file system by setting the following property in apoc.conf:
apoc.import.file.use_neo4j_config=false|
Neo4j will now be able to write anywhere on the file system, so be sure that this is your intention before setting this property. |
Exporting to S3
By default exporting to S3 is disabled.
We can enable it by setting the following property in apoc.conf:
apoc.export.file.enabled=trueIf we try to use any of the export procedures without having first set this property, we’ll get the following error message:
Failed to invoke procedure: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your neo4j.conf |
Using S3 protocol
When using the S3 protocol we need to download and copy the following jars into the plugins directory:
-
aws-java-sdk-core-1.11.250.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-core/1.11.250)
-
aws-java-sdk-s3-1.11.250.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3/1.11.250)
-
httpclient-4.4.8.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient/4.5.4)
-
httpcore-4.5.4.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore/4.4.8)
-
joda-time-2.9.9.jar (https://mvnrepository.com/artifact/joda-time/joda-time/2.9.9)
Once those files have been copied we’ll need to restart the database.
Exporting to S3 can be done by simply replacing the file output with an S3 endpoint. The S3 URL must be in the following format:
-
s3://accessKey:secretKey[:sessionToken]@endpoint:port/bucket/key(where the sessionToken is optional) or -
s3://endpoint:port/bucket/key?accessKey=accessKey&secretKey=secretKey[&sessionToken=sessionToken](where the sessionToken is optional) or -
s3://endpoint:port/bucket/keyif the accessKey, secretKey, and the optional sessionToken are provided in the environment variables
Memory Requirements
To support large uploads, the S3 uploading utility may use up to 2.25 GB of memory at a time. The actual usage will depend on the size of the upload, but will use a maximum of 2.25 GB.
Exporting a stream
If we don’t want to export to a file, we can stream results back by providing a file name of null.
By default all Cypher statements will be returned in a single row in the cypherStatements column.
CALL apoc.export.cypher.all(null);If we’re exporting a large database, we can batch these statements across multiple rows by providing the streamStatements:true config and configuring the batchSize config.
CALL apoc.export.cypher.all(null, {
streamStatements: true,
batchSize: 100
});Examples
This section includes examples showing how to use the export to Cypher procedures. These examples are based on a movies dataset, which can be imported by running the following Cypher query:
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);The Neo4j Browser visualization below shows the imported graph:
Export to Cypher Shell format
By default, the Cypher statements generated by the export to Cypher procedures are in the Cypher Shell format.
all.cypher in the default cypher-shell format using the default UNWIND_BATCH optimization// default config populated for illustration
CALL apoc.export.cypher.all("all.cypher", {
format: "cypher-shell",
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 20}
})
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"all.cypher" |
1 |
"database: nodes(8), rels(7)" |
"cypher" |
8 |
7 |
21 |
10 |
15 |
20000 |
The contents of all.cypher, with extra lines added for readability, are shown below:
:begin
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
:commit
:begin
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:1, properties:{born:1964, name:"Keanu Reeves"}}, {_id:2, properties:{born:1967, name:"Carrie-Anne Moss"}}, {_id:3, properties:{born:1961, name:"Laurence Fishburne"}}, {_id:4, properties:{born:1960, name:"Hugo Weaving"}}, {_id:5, properties:{born:1967, name:"Lilly Wachowski"}}, {_id:6, properties:{born:1965, name:"Lana Wachowski"}}, {_id:7, properties:{born:1952, name:"Joel Silver"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
:commit
:begin
UNWIND [{start: {_id:1}, end: {_id:0}, properties:{roles:["Neo"]}}, {start: {_id:2}, end: {_id:0}, properties:{roles:["Trinity"]}}, {start: {_id:3}, end: {_id:0}, properties:{roles:["Morpheus"]}}, {start: {_id:4}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
UNWIND [{start: {_id:7}, end: {_id:0}, properties:{}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:PRODUCED]->(end) SET r += row.properties;
UNWIND [{start: {_id:5}, end: {_id:0}, properties:{}}, {start: {_id:6}, end: {_id:0}, properties:{}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:DIRECTED]->(end) SET r += row.properties;
:commit
:begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
:commit
:begin
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
:commitThis Cypher script executes 5 transactions, each surrounded by :begin and :commit commands.
The transactions do the following:
-
Create a unique constraint on the
UNIQUE IMPORT LABELlabel andUNIQUE IMPORT IDproperty -
Import the
PersonandMovienodes -
Create
ACTED_IN,PRODUCED, andDIRECTEDrelationships between these nodes -
Remove the
UNIQUE IMPORT LABELlabel andUNIQUE IMPORT IDproperty from the nodes -
Drop the unique constraint on the
UNIQUE IMPORT LABELlabel andUNIQUE IMPORT IDproperty
This script can be executed using the Cypher Shell command line tool.
For example, we could import the contents of all.cypher into a Neo4j Aura database by running the following command:
cat all.cypher | ./bin/cypher-shell -a <bolt-url> -u neo4j -p <password> --format verbose|
Don’t forget to replace <bolt-url> and <password> with the appropriate credentials. |
If we run this command against an empty database, we’ll see the following output:
0 rows available after 70 ms, consumed after another 0 ms
Added 1 constraints
0 rows available after 16 ms, consumed after another 0 ms
Added 2 nodes, Set 8 properties, Added 4 labels
0 rows available after 40 ms, consumed after another 0 ms
Added 14 nodes, Set 42 properties, Added 28 labels
0 rows available after 51 ms, consumed after another 0 ms
Created 8 relationships, Set 8 properties
0 rows available after 38 ms, consumed after another 0 ms
Created 2 relationships
0 rows available after 38 ms, consumed after another 0 ms
Created 4 relationships
0 rows available after 20 ms, consumed after another 0 ms
Set 16 properties, Removed 16 labels
0 rows available after 3 ms, consumed after another 0 ms
Removed 1 constraints|
Troubleshooting
If you are experimenting with imports that are failing you can add the Also check the memory configuration of your Neo4j instance, you might want to increase the HEAP size to 2–4GB using the We can also provide more memory to cypher-shell itself by prefixing the command with: |
If we don’t have file system access, or don’t want to write to a file for another reason, we can stream back the export statements.
cypherStatements columnCALL apoc.export.cypher.all(null, {
batchSize: 5,
streamStatements: true,
format: "cypher-shell",
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 5}
})
YIELD nodes, relationships, properties, cypherStatements
RETURN nodes, relationships, properties, cypherStatements;| nodes | relationships | properties | cypherStatements |
|---|---|---|---|
|
|
|
":begin
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node. |
|
|
|
":begin
UNWIND [{start: {_id:35}, end: {_id:0}, properties:{roles:[\"Trinity\"]}}, {start: {_id:36}, end: {_id:0}, properties:{roles:[\"Morpheus\"]}}, {start: {_id:50}, end: {_id:1}, properties:{roles:[\"Agent Smith\"]}}, {start: {_id:40}, end: {_id:0}, properties:{roles:[\"Agent Smith\"]}}, {start: {_id:51}, end: {_id:1}, properties:{roles:[\"Neo\"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{ |
|
|
|
":begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 5 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n. |
We can then copy/paste the content of the cypherStatements column (excluding the double quotes) into a Cypher Shell session, or into a local file that we stream into a Cypher Shell session.
Export to Neo4j Browser friendly format
The export to Cypher procedures support the config format: "plain", which is useful for later import using the Neo4j Browser.
all-plain.cypherCALL apoc.export.cypher.all("all-plain.cypher", {
format: "plain",
useOptimizations: {type: "UNWIND_BATCH", unwindBatchSize: 20}
})
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"all-plain.cypher" |
1 |
"database: nodes(8), rels(7)" |
"cypher" |
8 |
7 |
21 |
9 |
15 |
20000 |
The contents of all-plain.cypher, with extra lines added for readability, are shown below:
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:1, properties:{born:1964, name:"Keanu Reeves"}}, {_id:2, properties:{born:1967, name:"Carrie-Anne Moss"}}, {_id:3, properties:{born:1961, name:"Laurence Fishburne"}}, {_id:4, properties:{born:1960, name:"Hugo Weaving"}}, {_id:5, properties:{born:1967, name:"Lilly Wachowski"}}, {_id:6, properties:{born:1965, name:"Lana Wachowski"}}, {_id:7, properties:{born:1952, name:"Joel Silver"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:1}, end: {_id:0}, properties:{roles:["Neo"]}}, {start: {_id:2}, end: {_id:0}, properties:{roles:["Trinity"]}}, {start: {_id:3}, end: {_id:0}, properties:{roles:["Morpheus"]}}, {start: {_id:4}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
UNWIND [{start: {_id:7}, end: {_id:0}, properties:{}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:PRODUCED]->(end) SET r += row.properties;
UNWIND [{start: {_id:5}, end: {_id:0}, properties:{}}, {start: {_id:6}, end: {_id:0}, properties:{}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:DIRECTED]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;We can then take the all-plain.cypher file and drag it onto the Neo4j Browser window.
We should then see the following prompt:

And if we click Paste in editor, the contents of the file will appear in the query editor:
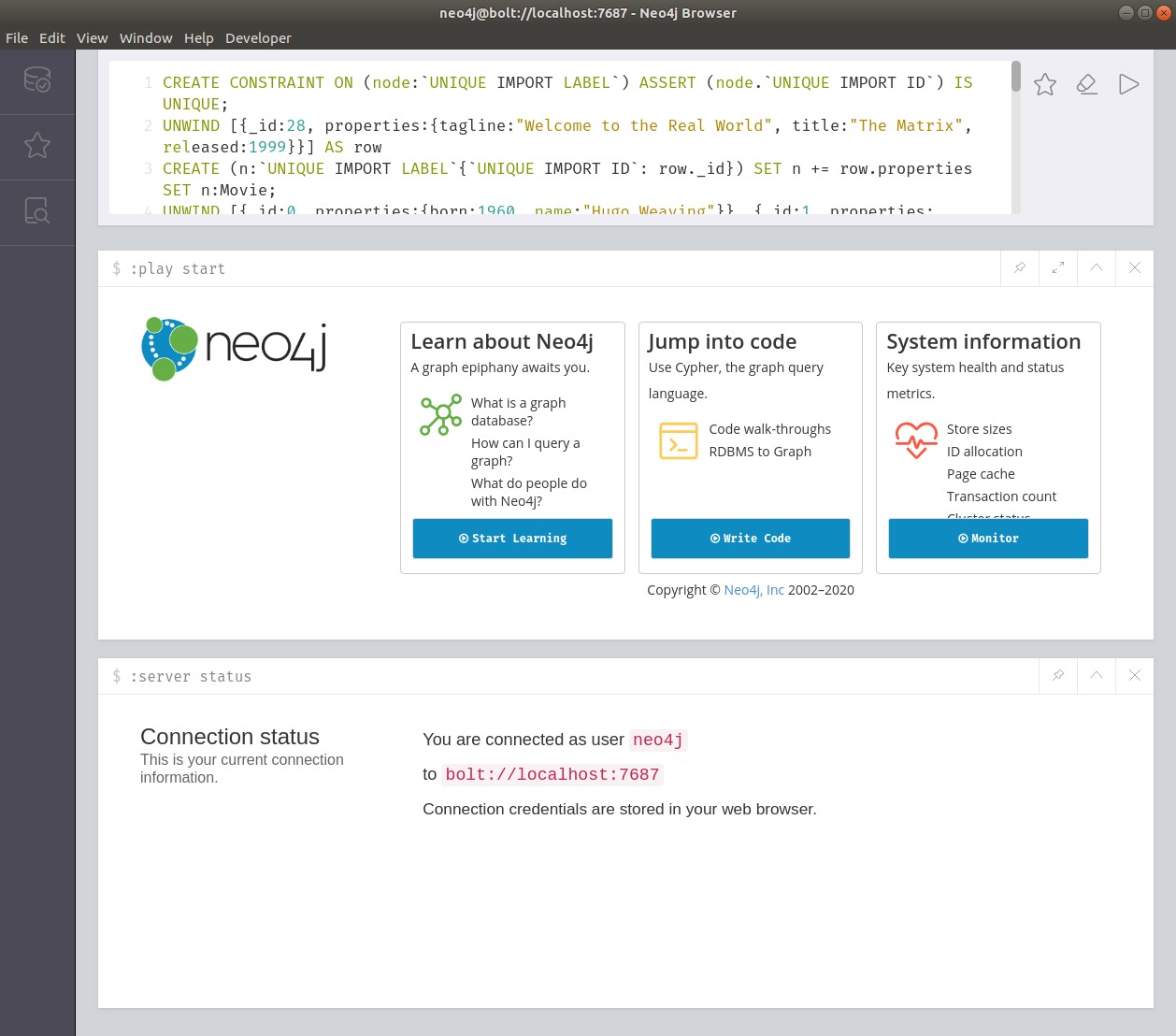
all-plain.cypherWe can then press the play button next in the editor and the data will be imported.
Export using different Cypher update formats
The export to Cypher procedures generate Cypher statements using the CREATE, MATCH and MERGE clauses.
The format is configured by the cypherFormat parameter.
The following values are supported:
-
create- only uses theCREATEclause (default) -
updateAll- usesMERGEinstead ofCREATE -
addStructure- usesMATCHfor nodes andMERGEfor relationships -
updateStructure- usesMERGEandMATCHfor nodes and relationships
If we’re exporting a database for the first time we should use the default create format, but for subsequent exports the other formats may be more suitable.
ACTED_IN relationships and surrounding nodes to export-cypher-format-create.cypher using the create formatMATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-create.cypher",
{ format: "plain", cypherFormat: "create" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-create.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
2 |
9 |
20000 |
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;The creation of all graph entities uses the Cypher CREATE clause.
If those entities may already exist in the destination database, we may choose to use another format.
Using cypherFormat: "updateAll" means that the MERGE clause will be used instead of CREATE when creating entities.
ACTED_IN relationships and surrounding nodes to export-cypher-format-create.cypher using the updateAll formatMATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateAll.cypher",
{ format: "plain", cypherFormat: "updateAll" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateAll.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
8 |
9 |
20000 |
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;If we already have the nodes in our destination database, we can use cypherFormat: "addStructure" to create Cypher CREATE statements for just the relationships.
ACTED_IN relationships and surrounding nodes to export-cypher-format-addStructure.cypher using the addStructure formatMATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-addStructure.cypher",
{ format: "plain", cypherFormat: "addStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-addStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
4 |
9 |
20000 |
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;In this example we’re using the MERGE clause to create a node if it doesn’t already exist, and are only creating properties if the node doesn’t already exist.
In this example, relationships don’t exist in the destination database and need to be created.
If those relationships do exist but have properties that need to be updated, we can use cypherFormat: "updateStructure" to create our import script.
ACTED_IN relationships and surrounding nodes to export-cypher-format-updateStructure.cypher using the updateStructure formatMATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateStructure.cypher",
{ format: "plain", cypherFormat: "updateStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
0 |
4 |
4 |
2 |
4 |
20000 |
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;Export to multiple files or columns
The export to Cypher procedures all support writing to multiple files or multiple columns.
We can enable this mode by passing in the config separateFiles: true
ACTED_IN relationships and corresponding nodes into files with an actedIn prefixCALL apoc.export.cypher.query(
"MATCH ()-[r:ACTED_IN]->()
RETURN *",
"actedIn.cypher",
{ format: "cypher-shell", separateFiles: true })
YIELD file, batches, source, format, nodes, relationships, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, time, rows, batchSize;| file | batches | source | format | nodes | relationships | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|
"actedIn.cypher" |
1 |
"statement: nodes(10), rels(8)" |
"cypher" |
10 |
8 |
3 |
18 |
20000 |
This will result in the following files being created:
| Name | Size in bytes | Number of lines |
|---|---|---|
actedIn.cleanup.cypher |
234 |
6 |
actedIn.nodes.cypher |
893 |
6 |
actedIn.relationships.cypher |
757 |
6 |
actedIn.schema.cypher |
109 |
3 |
Each of those files contains one particular part of the graph. Let’s have a look at their content:
:begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
:commit
:begin
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
:commit:begin
UNWIND [{_id:28, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}, {_id:37, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:31, properties:{born:1961, name:"Laurence Fishburne"}}, {_id:30, properties:{born:1967, name:"Carrie-Anne Moss"}}, {_id:42, properties:{born:1964, name:"Keanu Reeves"}}, {_id:0, properties:{born:1960, name:"Hugo Weaving"}}, {_id:29, properties:{born:1964, name:"Keanu Reeves"}}, {_id:38, properties:{born:1960, name:"Hugo Weaving"}}, {_id:43, properties:{born:1967, name:"Carrie-Anne Moss"}}, {_id:57, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
:commit:begin
UNWIND [{start: {_id:31}, end: {_id:28}, properties:{roles:["Morpheus"]}}, {start: {_id:42}, end: {_id:37}, properties:{roles:["Neo"]}}, {start: {_id:38}, end: {_id:37}, properties:{roles:["Agent Smith"]}}, {start: {_id:0}, end: {_id:28}, properties:{roles:["Agent Smith"]}}, {start: {_id:29}, end: {_id:28}, properties:{roles:["Neo"]}}, {start: {_id:43}, end: {_id:37}, properties:{roles:["Trinity"]}}, {start: {_id:30}, end: {_id:28}, properties:{roles:["Trinity"]}}, {start: {_id:57}, end: {_id:37}, properties:{roles:["Morpheus"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
:commit:begin
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
:commitWe can then apply these files to our destination Neo4j instance, either by streaming their contents into Cypher Shell or by using the procedures described in Running Cypher fragments.
We can also use the separateFiles when returning a stream of export statements.
The results will appear in columns named nodeStatements, relationshipStatements, cleanupStatements, and schemaStatements rather than cypherStatements.
ACTED_IN relationships and corresponding nodesCALL apoc.export.cypher.query(
"MATCH ()-[r:ACTED_IN]->()
RETURN *",
null,
{ format: "cypher-shell", separateFiles: true })
YIELD nodes, relationships, properties, nodeStatements, relationshipStatements, cleanupStatements, schemaStatements
RETURN nodes, relationships, properties, nodeStatements, relationshipStatements, cleanupStatements, schemaStatements;| nodes | relationships | properties | nodeStatements | relationshipStatements | cleanupStatements | schemaStatements |
|---|---|---|---|---|---|---|
10 |
8 |
30 |
":begin
UNWIND [{_id:28, properties:{tagline:\"Welcome to the Real World\", title:\"The Matrix\", released:1999}}, {_id:37, properties:{tagline:\"Welcome to the Real World\", title:\"The Matrix\", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{ |
":begin
UNWIND [{start: {_id:31}, end: {_id:28}, properties:{roles:[\"Morpheus\"]}}, {start: {_id:38}, end: {_id:37}, properties:{roles:[\"Agent Smith\"]}}, {start: {_id:0}, end: {_id:28}, properties:{roles:[\"Agent Smith\"]}}, {start: {_id:30}, end: {_id:28}, properties:{roles:[\"Trinity\"]}}, {start: {_id:29}, end: {_id:28}, properties:{roles:[\"Neo\"]}}, {start: {_id:43}, end: {_id:37}, properties:{roles:[\"Trinity\"]}}, {start: {_id:42}, end: {_id:37}, properties:{roles:[\"Neo\"]}}, {start: {_id:57}, end: {_id:37}, properties:{roles:[\"Morpheus\"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{ |
":begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n. |
":begin
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node. |
We can then copy/paste the content of each of these columns (excluding the double quotes) into a Cypher Shell session, or into a local file that we stream into a Cypher Shell session.
If we want to export Cypher statements that can be pasted into the Neo4j Browser query editor, we need to use the config format: "plain", as described in Export to Neo4j Browser friendly format.
Round trip
This example shows how to export data from one Neo4j instance (the source database) and import it into another one (the destination database).
plain format into multiple filesCALL apoc.export.cypher.query(
"match (n)-[r]->(n2) return * limit 100",
"/tmp/mysubset.cypher",
{format:'plain',separateFiles:true}
)
YIELD file, batches, source, format, nodes, relationships, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, time, rows, batchSize;| file | batches | source | format | nodes | relationships | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|
"/tmp/mysubset.cypher" |
1 |
"statement: nodes(16), rels(14)" |
"cypher" |
16 |
14 |
9 |
30 |
20000 |
This should result in 4 files in your directory.
ls -1 /tmp/mysubset.*
/tmp/mysubset.cleanup.cypher
/tmp/mysubset.nodes.cypher
/tmp/mysubset.relationships.cypher
/tmp/mysubset.schema.cypherNow let’s copy those files so they’re accessible from our destination database.
We’ll need to first add the following property to apoc.conf:
apoc.import.file.enabled=trueAnd now we’re going to use procedures from Running Cypher fragments to import the data.
CALL apoc.cypher.runSchemaFile('/tmp/mysubset.schema.cypher');| row | result |
|---|---|
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 0, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, r elationshipsCreated: 0, time: 0} |
CALL apoc.cypher.runFiles(['/tmp/mysubset.nodes.cypher','/tmp/mysubset.relationships.cypher']);| row | result |
|---|---|
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 2, rows: 0, propertiesSet: 8, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 4, r elationshipsCreated: 0, time: 0} |
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 14, rows: 0, propertiesSet: 42, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 28 , relationshipsCreated: 0, time: 0} |
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 8, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, r elationshipsCreated: 8, time: 0} |
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 0, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, r elationshipsCreated: 2, time: 0} |
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 0, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, r elationshipsCreated: 4, time: 0} |
CALL apoc.cypher.runFile('/tmp/mysubset.cleanup.cypher');| row | result |
|---|---|
|
{constraintsRemoved: 0, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 16, labelsRemoved: 16, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, relationshipsCreated: 0, time: 0} |
CALL apoc.cypher.runSchemaFile('/tmp/mysubset.cleanup.cypher');| row | result |
|---|---|
|
{constraintsRemoved: 1, indexesRemoved: 0, nodesCreated: 0, rows: 0, propertiesSet: 0, labelsRemoved: 0, relationshipsDeleted: 0, constraintsAdded: 0, nodesDeleted: 0, indexesAdded: 0, labelsAdded: 0, r elationshipsCreated: 0, time: 0} |
The apoc.cypher.run* procedures have some optional config:
-
{statistics:true/false}to output a row of update-stats per statement, default is true -
{timeout:1 or 10}for how long the stream waits for new data, default is 10
Make sure to set the config options in your neo4j.conf