Merge Nodes
We can merge a list of nodes onto the first one in the list. All relationships are merged onto that node too. We can specify the merge behavior for properties globally and/or individually.
MATCH (p:Person)
WITH p ORDER BY p.created DESC // newest one first
WITH p.email AS email, collect(p) as nodes
CALL apoc.refactor.mergeNodes(nodes, {properties: {
name:'discard',
age:'overwrite',
kids:'combine',
`addr.*`: 'overwrite',
`.*`: 'discard'
}})
YIELD node
RETURN nodeBelow are the config options for this procedure:
These config option also works for apoc.refactor.mergeRelationships([rels],{config}).
| type | operations |
|---|---|
discard |
the property from the first node will remain if already set, otherwise the first property in list will be written |
overwrite / override |
last property in list wins |
combine |
if there is only one property in list, it will be set / kept as single property otherwise create an array, tries to coerce values |
In addition, mergeNodes supports the following config properties:
| type | operations |
|---|---|
mergeRels |
true/false: give the possibility to merge relationships with same type and direction. |
produceSelfRel |
true/false: if |
preserveExistingSelfRels |
true/false: is valid only with |
singleElementAsArray |
false/true: if is |
Relationships properties are managed with the same nodes' method, if properties parameter isn’t set relationships properties are combined.
Example Usage
The examples below will help us learn how to use these procedures.
Same start and end nodes
CREATE (n1:Person {name:'Tom'}),
(n2:Person {name:'John'}),
(n3:Company {name:'Company1'}),
(n5:Car {brand:'Ferrari'}),
(n6:Animal:Cat {name:'Derby'}),
(n7:City {name:'London'}),
(n1)-[:WORKS_FOR {since:2015}]->(n3),
(n2)-[:WORKS_FOR {since:2018}]->(n3),
(n3)-[:HAS_HQ {since:2004}]->(n7),
(n1)-[:DRIVE {since:2017}]->(n5),
(n2)-[:HAS {since:2013}]->(n6);
return *;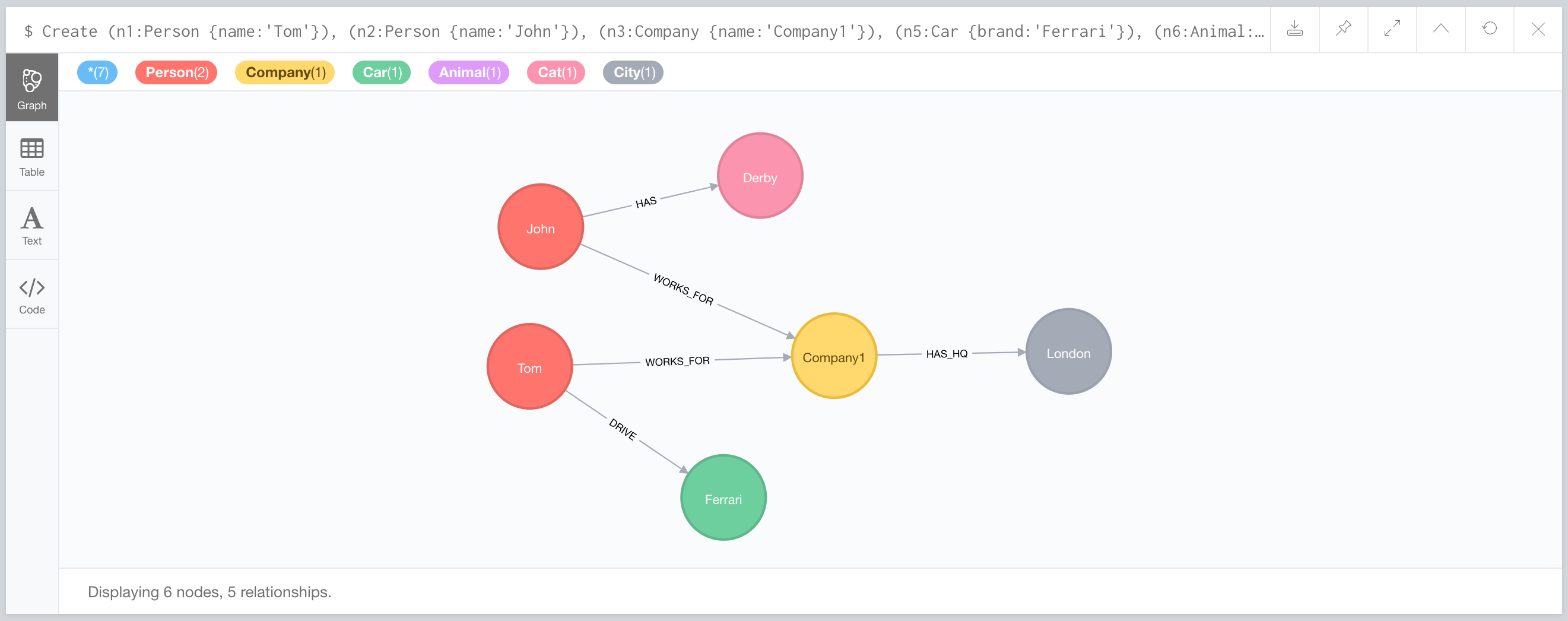
MATCH (a1:Person{name:'John'}), (a2:Person {name:'Tom'})
WITH head(collect([a1,a2])) as nodes
CALL apoc.refactor.mergeNodes(nodes,{properties:"combine", mergeRels:true})
YIELD node
RETURN count(*)If we execute this query, it will result in the following graph:
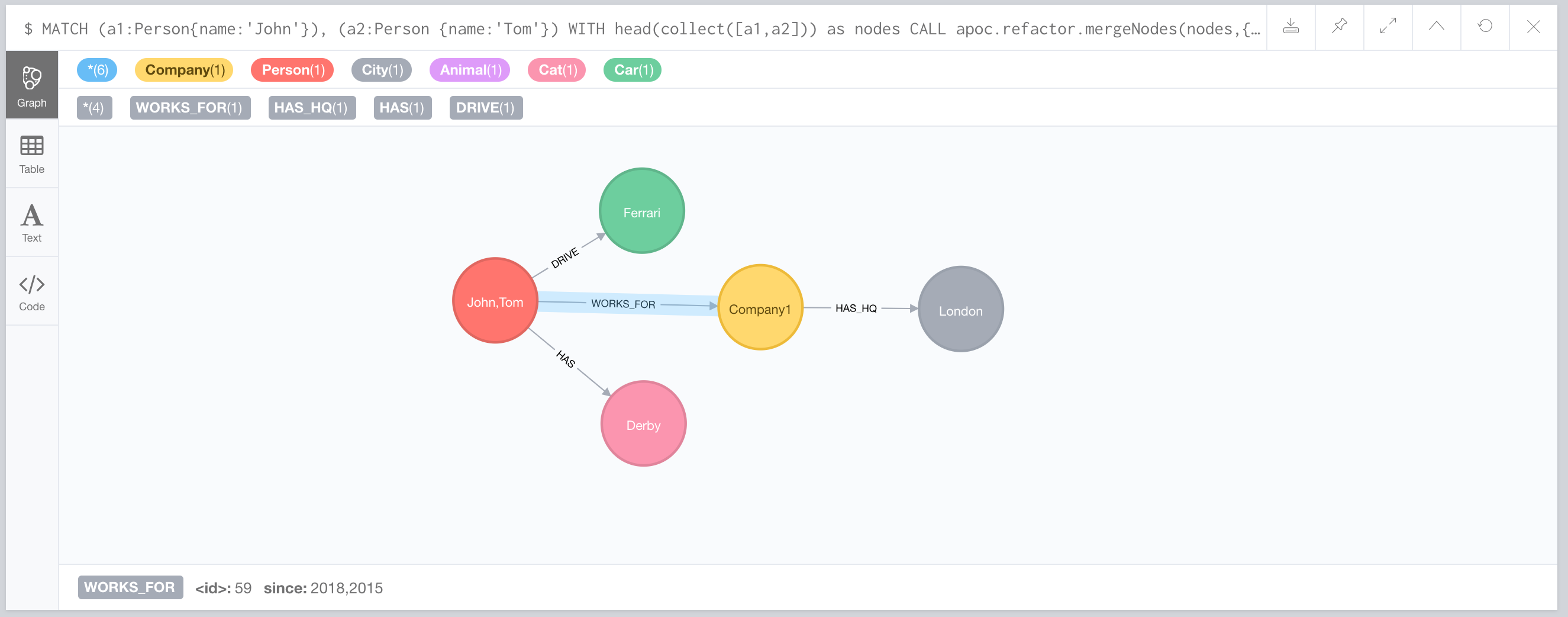
Since we have relationships with same start and end nodes, relationships are merged and properties are combined.
Different start and end nodes
Create (n1:Person {name:'Tom'}),
(n2:Person {name:'John'}),
(n3:Company {name:'Company1'}),
(n4:Company {name:'Company2'}),
(n5:Car {brand:'Ferrari'}),
(n6:Animal:Cat {name:'Derby'}),
(n7:City {name:'London'}),
(n8:City {name:'Liverpool'}),
(n1)-[:WORKS_FOR{since:2015}]->(n3),
(n2)-[:WORKS_FOR{since:2018}]->(n4),
(n3)-[:HAS_HQ{since:2004}]->(n7),
(n4)-[:HAS_HQ{since:2007}]->(n8),
(n1)-[:DRIVE{since:2017}]->(n5),
(n2)-[:HAS{since:2013}]->(n6)
return *;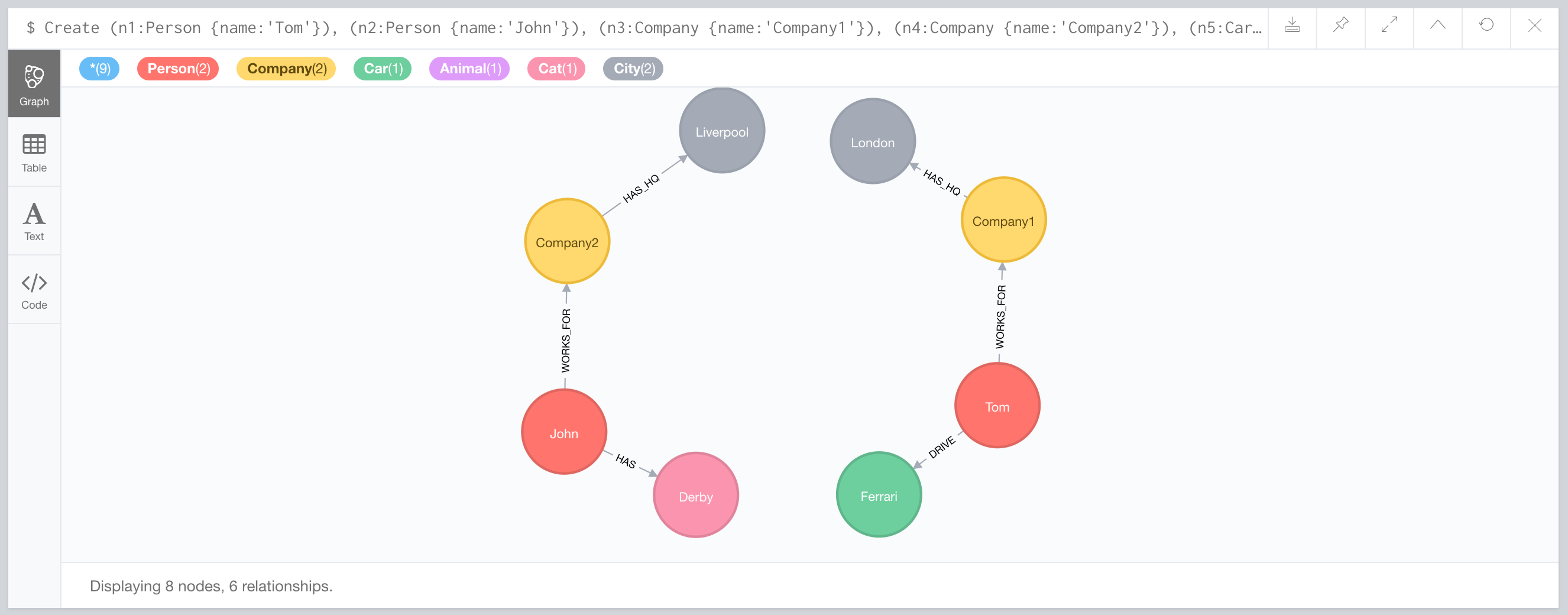
MATCH (a1:Person{name:'John'}), (a2:Person {name:'Tom'})
WITH head(collect([a1,a2])) as nodes
CALL apoc.refactor.mergeNodes(nodes,{
properties:"combine",
mergeRels:true
})
YIELD node
RETURN count(*)If we execute this query, it will result in the following graph:
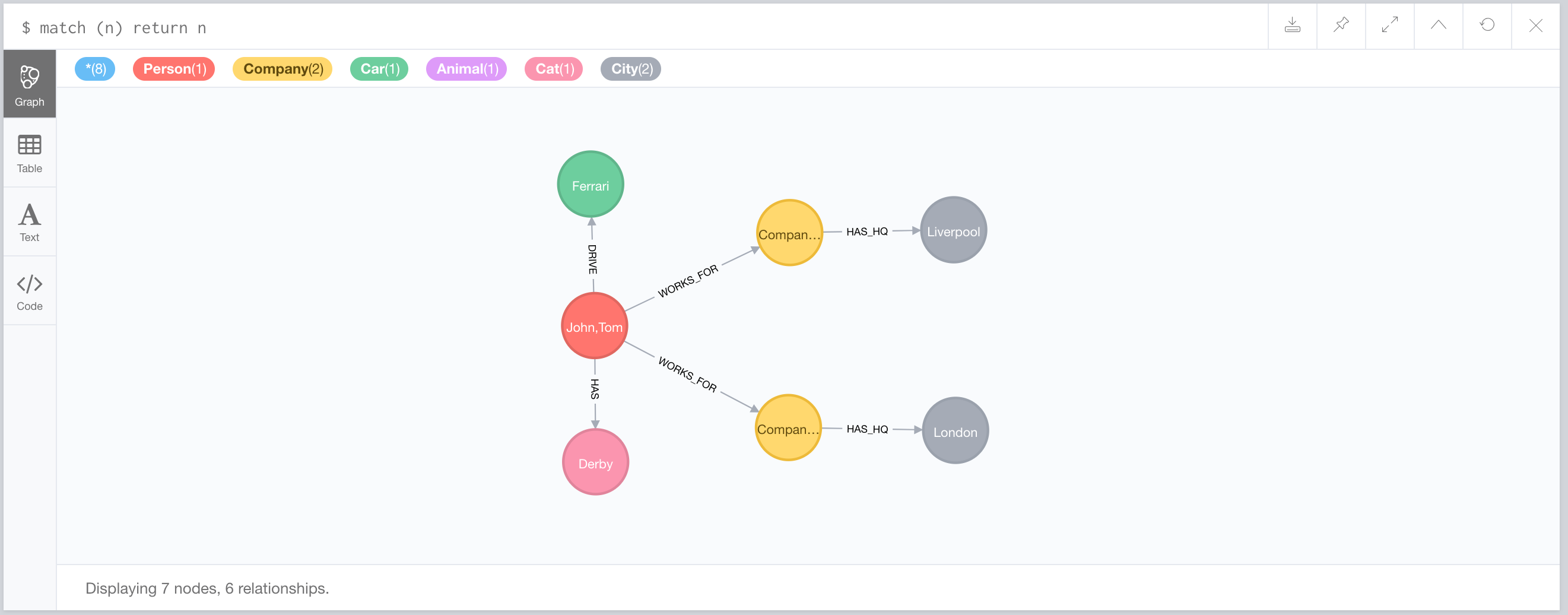
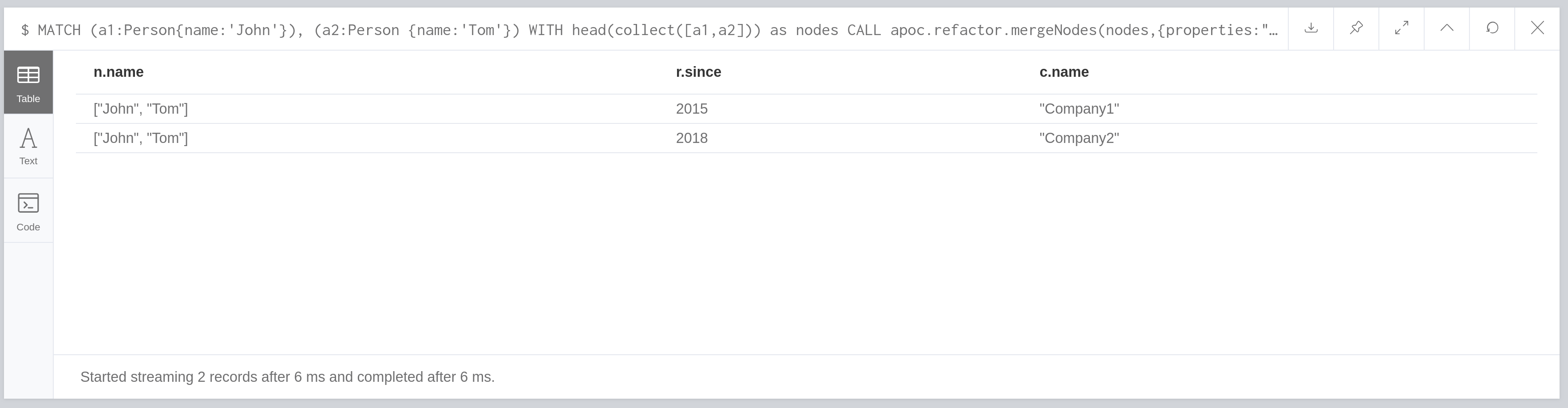
Since we have relationships with different end nodes, all relationships and properties are maintained.