Export to CSV
The export CSV procedures export data into a format more supported by Data Science libraries in the Python and R ecosystems. We may also want to export data into JSON format for importing into other tools or for general sharing of query results. The procedures described in this section support exporting to a file or as a stream.
For apoc.export.csv.all, apoc.export.csv.data and apoc.export.csv.graph, nodes and relationships properties are ordered alphabetically, using the following structure:
_id,_labels,<list_nodes_properties_naturally_sorted>,_start,_end,_type,<list_rel_properties_naturally_sorted>.
For a graph containing node properties age, city, kids, male, name, and street and containing relationship propeties bar and foo, we’d have the following:
_id,_labels,age,city,kids,male,name,street,_start,_end,_type,bar,foo
Labels exported are ordered alphabetically.
The output of labels() function is not sorted, use it in combination with apoc.coll.sort().
Note that, to perform a correct Point serialization, it is not recommended to export a point with coordinates x,y and crs: 'wgs-84',
for example point({x: 56.7, y: 12.78, crs: 'wgs-84'}). Otherwise, the point will be exported with longitude and latitude (and height) instead of x and y (and z)
Available Procedures
The table below describes the available procedures:
| Qualified Name | Type | Release |
|---|---|---|
|
- exports whole database as csv to the provided file |
|
|
|
- exports given nodes and relationships as csv to the provided file |
|
|
|
- exports given graph object as csv to the provided file |
|
|
|
- exports results from the cypher statement as csv to the provided file |
|
|
Exporting to a file
By default exporting to the file system is disabled.
We can enable it by setting the following property in apoc.conf:
apoc.export.file.enabled=trueIf we try to use any of the export procedures without having first set this property, we’ll get the following error message:
Failed to invoke procedure: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your apoc.conf.
Otherwise, if you are running in a cloud environment without filesystem access, use the |
Export files are written to the import directory, which is defined by the dbms.directories.import property.
This means that any file path that we provide is relative to this directory.
If we try to write to an absolute path, such as /tmp/filename, we’ll get an error message similar to the following one:
Failed to invoke procedure: Caused by: java.io.FileNotFoundException: /path/to/neo4j/import/tmp/fileName (No such file or directory) |
We can enable writing to anywhere on the file system by setting the following property in apoc.conf:
apoc.import.file.use_neo4j_config=false|
Neo4j will now be able to write anywhere on the file system, so be sure that this is your intention before setting this property. |
Exporting to S3
By default exporting to S3 is disabled.
We can enable it by setting the following property in apoc.conf:
apoc.export.file.enabled=trueIf we try to use any of the export procedures without having first set this property, we’ll get the following error message:
Failed to invoke procedure: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your apoc.conf.
Otherwise, if you are running in a cloud environment without filesystem access, you can use the |
Using S3 protocol
When using the S3 protocol we need to download and copy the following jars into the plugins directory:
-
aws-java-sdk-core-1.12.136.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-core/1.12.136)
-
aws-java-sdk-s3-1.12.136.jar (https://mvnrepository.com/artifact/com.amazonaws/aws-java-sdk-s3/1.12.136)
-
httpclient-4.5.13.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient/4.5.13)
-
httpcore-4.4.15.jar (https://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore/4.4.15)
-
joda-time-2.10.13.jar (https://mvnrepository.com/artifact/joda-time/joda-time/2.10.13)
Once those files have been copied we’ll need to restart the database.
The S3 URL must be in the following format:
-
s3://accessKey:secretKey[:sessionToken]@endpoint:port/bucket/key(where the sessionToken is optional) or -
s3://endpoint:port/bucket/key?accessKey=accessKey&secretKey=secretKey[&sessionToken=sessionToken](where the sessionToken is optional) or -
s3://endpoint:port/bucket/keyif the accessKey, secretKey, and the optional sessionToken are provided in the environment variables
Memory Requirements
To support large uploads, the S3 uploading utility may use up to 2.25 GB of memory at a time. The actual usage will depend on the size of the upload, but will use a maximum of 2.25 GB.
Exporting a stream
If we don’t want to export to a file, we can stream results back in the data column instead by passing a file name of null and providing the stream:true config.
Examples
This section includes examples showing how to use the export to CSV procedures. These examples are based on a movies dataset, which can be imported by running the following Cypher query:
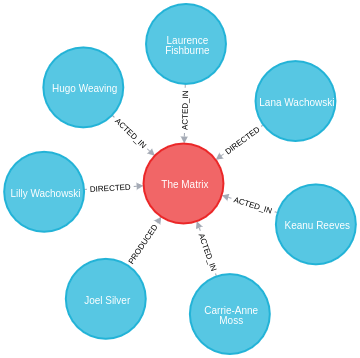
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);The Neo4j Browser visualization below shows the imported graph:
Export whole database to CSV
The apoc.export.csv.all procedure exports the whole database to a CSV file or as a stream.
movies.csvCALL apoc.export.csv.all("movies.csv", {})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies.csv" |
"database: nodes(8), rels(7)" |
"csv" |
8 |
7 |
21 |
39 |
15 |
20000 |
1 |
TRUE |
NULL |
The contents of movies.csv are shown below:
"_id","_labels","born","name","released","tagline","title","_start","_end","_type","roles"
"188",":Movie","","","1999","Welcome to the Real World","The Matrix",,,,
"189",":Person","1964","Keanu Reeves","","","",,,,
"190",":Person","1967","Carrie-Anne Moss","","","",,,,
"191",":Person","1961","Laurence Fishburne","","","",,,,
"192",":Person","1960","Hugo Weaving","","","",,,,
"193",":Person","1967","Lilly Wachowski","","","",,,,
"194",":Person","1965","Lana Wachowski","","","",,,,
"195",":Person","1952","Joel Silver","","","",,,,
,,,,,,,"189","188","ACTED_IN","[""Neo""]"
,,,,,,,"190","188","ACTED_IN","[""Trinity""]"
,,,,,,,"191","188","ACTED_IN","[""Morpheus""]"
,,,,,,,"192","188","ACTED_IN","[""Agent Smith""]"
,,,,,,,"193","188","DIRECTED",""
,,,,,,,"194","188","DIRECTED",""
,,,,,,,"195","188","PRODUCED",""data columnCALL apoc.export.csv.all(null, {stream:true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data| file | nodes | relationships | properties | data |
|---|---|---|---|---|
|
|
|
|
"\"_id\",\"_labels\",\"born\",\"name\",\"released\",\"tagline\",\"title\",\"_start\",\"_end\",\"_type\",\"roles\" \"188\",\":Movie\",\"\",\"\",\"1999\",\"Welcome to the Real World\",\"The Matrix\",,,, \"189\",\":Person\",\"1964\",\"Keanu Reeves\",\"\",\"\",\"\",,,, \"190\",\":Person\",\"1967\",\"Carrie-Anne Moss\",\"\",\"\",\"\",,,, \"191\",\":Person\",\"1961\",\"Laurence Fishburne\",\"\",\"\",\"\",,,, \"192\",\":Person\",\"1960\",\"Hugo Weaving\",\"\",\"\",\"\",,,, \"193\",\":Person\",\"1967\",\"Lilly Wachowski\",\"\",\"\",\"\",,,, \"194\",\":Person\",\"1965\",\"Lana Wachowski\",\"\",\"\",\"\",,,, \"195\",\":Person\",\"1952\",\"Joel Silver\",\"\",\"\",\"\",,,, ,,,,,,,\"189\",\"188\",\"ACTED_IN\",\"[\"\"Neo\"\"]\" ,,,,,,,\"190\",\"188\",\"ACTED_IN\",\"[\"\"Trinity\"\"]\" ,,,,,,,\"191\",\"188\",\"ACTED_IN\",\"[\"\"Morpheus\"\"]\" ,,,,,,,\"192\",\"188\",\"ACTED_IN\",\"[\"\"Agent Smith\"\"]\" ,,,,,,,\"193\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"194\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"195\",\"188\",\"PRODUCED\",\"\" " |
Export specified nodes and relationships to CSV
The apoc.export.csv.data procedure exports the specified nodes and relationships to a CSV file or as a stream.
:Person label with a name property that starts with L to the file movies-l.csvMATCH (person:Person)
WHERE person.name STARTS WITH "L"
WITH collect(person) AS people
CALL apoc.export.csv.data(people, [], "movies-l.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies-l.csv" |
"data: nodes(3), rels(0)" |
"csv" |
3 |
0 |
6 |
2 |
3 |
20000 |
1 |
TRUE |
NULL |
The contents of movies-l.csv are shown below:
"_id","_labels","born","name","_start","_end","_type"
"191",":Person","1961","Laurence Fishburne",,,
"193",":Person","1967","Lilly Wachowski",,,
"194",":Person","1965","Lana Wachowski",,,ACTED_IN relationships and the nodes with Person and Movie labels on either side of that relationship to the file movies-actedIn.csvMATCH (person:Person)-[actedIn:ACTED_IN]->(movie:Movie)
WITH collect(DISTINCT person) AS people, collect(DISTINCT movie) AS movies, collect(actedIn) AS actedInRels
CALL apoc.export.csv.data(people + movies, actedInRels, "movies-actedIn.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies-actedIn.csv" |
"data: nodes(5), rels(4)" |
"csv" |
5 |
4 |
15 |
2 |
9 |
20000 |
1 |
TRUE |
NULL |
The contents of movies-actedIn.csv are shown below:
"_id","_labels","born","name","released","tagline","title","_start","_end","_type","roles"
"189",":Person","1964","Keanu Reeves","","","",,,,
"190",":Person","1967","Carrie-Anne Moss","","","",,,,
"191",":Person","1961","Laurence Fishburne","","","",,,,
"192",":Person","1960","Hugo Weaving","","","",,,,
"188",":Movie","","","1999","Welcome to the Real World","The Matrix",,,,
,,,,,,,"189","188","ACTED_IN","[""Neo""]"
,,,,,,,"190","188","ACTED_IN","[""Trinity""]"
,,,,,,,"191","188","ACTED_IN","[""Morpheus""]"
,,,,,,,"192","188","ACTED_IN","[""Agent Smith""]"ACTED_IN relationships and the nodes with Person and Movie labels on either side of that relationship in the data columnMATCH (person:Person)-[actedIn:ACTED_IN]->(movie:Movie)
WITH collect(DISTINCT person) AS people, collect(DISTINCT movie) AS movies, collect(actedIn) AS actedInRels
CALL apoc.export.csv.data(people + movies, actedInRels, null, {stream: true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data| file | nodes | relationships | properties | data |
|---|---|---|---|---|
|
|
|
|
"\"_id\",\"_labels\",\"born\",\"name\",\"released\",\"tagline\",\"title\",\"_start\",\"_end\",\"_type\",\"roles\" \"190\",\":Person\",\"1967\",\"Carrie-Anne Moss\",\"\",\"\",\"\",,,, \"189\",\":Person\",\"1964\",\"Keanu Reeves\",\"\",\"\",\"\",,,, \"191\",\":Person\",\"1961\",\"Laurence Fishburne\",\"\",\"\",\"\",,,, \"192\",\":Person\",\"1960\",\"Hugo Weaving\",\"\",\"\",\"\",,,, \"188\",\":Movie\",\"\",\"\",\"1999\",\"Welcome to the Real World\",\"The Matrix\",,,, ,,,,,,,\"189\",\"188\",\"ACTED_IN\",\"[\"\"Neo\"\"]\" ,,,,,,,\"190\",\"188\",\"ACTED_IN\",\"[\"\"Trinity\"\"]\" ,,,,,,,\"191\",\"188\",\"ACTED_IN\",\"[\"\"Morpheus\"\"]\" ,,,,,,,\"192\",\"188\",\"ACTED_IN\",\"[\"\"Agent Smith\"\"]\" " |
Export virtual graph to CSV
The apoc.export.csv.graph procedure exports a virtual graph to a CSV file or as a stream.
The examples in this section are based on a virtual graph that contains all PRODUCED relationships and the nodes either side of that relationship.
The query below creates a virtual graph and stores it in memory with the name producers.cached using Static Value Storage.
MATCH path = (:Person)-[produced:PRODUCED]->(:Movie)
WITH collect(path) AS paths
CALL apoc.graph.fromPaths(paths, "producers", {})
YIELD graph AS g
CALL apoc.static.set("producers.cached", g)
YIELD value
RETURN value, gmovies-producers.csvCALL apoc.export.csv.graph(apoc.static.get("producers.cached"), "movies-producers.csv", {})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies-producers.csv" |
"graph: nodes(2), rels(1)" |
"csv" |
2 |
1 |
5 |
2 |
3 |
20000 |
1 |
TRUE |
NULL |
The contents of movies-producers.csv are shown below:
"_id","_labels","born","name","released","tagline","title","_start","_end","_type"
"195",":Person","1952","Joel Silver","","","",,,
"188",":Movie","","","1999","Welcome to the Real World","The Matrix",,,
,,,,,,,"195","188","PRODUCED"data columnCALL apoc.export.csv.graph(apoc.static.get("producers.cached"), null, {stream: true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data| file | nodes | relationships | properties | data |
|---|---|---|---|---|
|
|
|
|
"\"_id\",\"_labels\",\"born\",\"name\",\"released\",\"tagline\",\"title\",\"_start\",\"_end\",\"_type\" \"195\",\":Person\",\"1952\",\"Joel Silver\",\"\",\"\",\"\",,, \"188\",\":Movie\",\"\",\"\",\"1999\",\"Welcome to the Real World\",\"The Matrix\",,, ,,,,,,,\"195\",\"188\",\"PRODUCED\" " |
Export results of Cypher query to CSV
The apoc.export.csv.query procedure exports the results of a Cypher query to a CSV file or as a stream.
DIRECTED relationships and the nodes with Person and Movie labels on either side of that relationship to the file movies-directed.csvWITH "MATCH path = (person:Person)-[:DIRECTED]->(movie)
RETURN person.name AS name, person.born AS born,
movie.title AS title, movie.tagline AS tagline, movie.released AS released" AS query
CALL apoc.export.csv.query(query, "movies-directed.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data;| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies-directed.csv" |
"statement: cols(5)" |
"csv" |
0 |
0 |
10 |
3 |
2 |
20000 |
1 |
TRUE |
NULL |
The contents of movies-directed.csv are shown below:
"name","born","role","title","tagline","released"
"Lilly Wachowski","1967","","The Matrix","Welcome to the Real World","1999"
"Lana Wachowski","1965","","The Matrix","Welcome to the Real World","1999"DIRECTED relationships and the nodes with Person and Movie labels on either side of that relationshipWITH "MATCH path = (person:Person)-[:DIRECTED]->(movie)
RETURN person.name AS name, person.born AS born,
movie.title AS title, movie.tagline AS tagline, movie.released AS released" AS query
CALL apoc.export.csv.query(query, null, {stream: true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data;| file | nodes | relationships | properties | data |
|---|---|---|---|---|
|
|
|
|
"\"name\",\"born\",\"title\",\"tagline\",\"released\" \"Lilly Wachowski\",\"1967\",\"The Matrix\",\"Welcome to the Real World\",\"1999\" \"Lana Wachowski\",\"1965\",\"The Matrix\",\"Welcome to the Real World\",\"1999\" " |
|
You can also compress the files to export. See here for more information |
When the config bulkImport is enable it create a list of file that can be used for Neo4j Bulk Import.
This config can be used only with apoc.export.csv.all and apoc.export.csv.graph
All file create are named as follow:
-
Nodes file are construct with the name of the input file append with
.nodes.[LABEL_NAME].csv -
Rel file are construct with the name of the input file append with
.relationships.[TYPE_NAME].csv
If Node or Relationship have more than one Label/Type it will create one file for Label/Type.
Configuration parameters
The procedures support the following config parameters:
| param | default | description |
|---|---|---|
batchSize |
20000 |
The batch size. |
delim |
"," |
The delimiter character of the CSV file. |
arrayDelim |
";" |
The delimiter character used for arrays (used in the bulk import). |
quotes |
'always' |
Quote-characters used for CSV, possible values are: * |
useTypes |
false |
Add the types on to the file header. |
bulkImport |
true |
Create files for Neo4j Admin import. |
timeoutSeconds |
100 |
The maximum time in seconds the query should run before timing out. |
separateHeader |
false |
Create two files: one for the header and one for the data. |
streamStatements |
false |
Batch the results across multiple rows by configuring the |
stream |
false |
Equivalent to the |