Virtual Resource
|
There are situations where we would like to enrich/complement the results of a cypher query in a Neo4j graph with additional data coming from an external source that we can’t (or don’t want to) load and persist in the graph. Think for example in a Neo4j graph with a network topology: All the devices, the connections between them, the dependencies, etc. You want to query all the devices in a particular site and return the performance metrics for the last two hours. This is "time-series data" and you may not want to import it and persist it in the graph. apoc.dv gives you the option of accessing that information on-demand at query time and combining it seamlessly with the network topology data in your graph. |
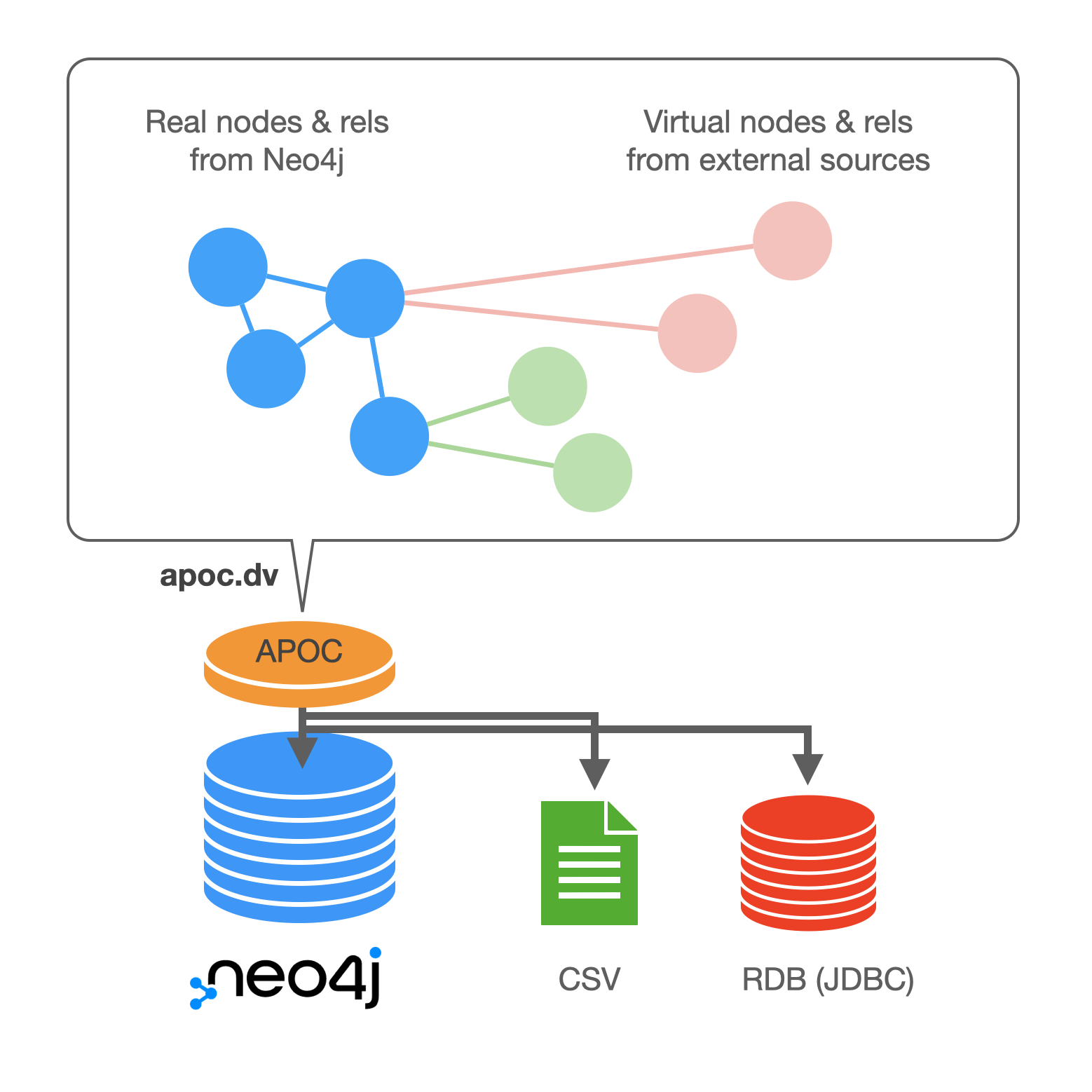
The APOC library supports the definition of a catalog of virtual resources. A virtual resource is an external data source that neo4j can use to query and retrieve data on demand presenting it as virtual nodes enriching the data stored in the graph. The Virtual Resource Catalog feature combines two APOC elements:
-
The apoc.load.* procedures that query data from external sources.
-
The virtual procedures that create transient graph structures which can be returned as the result of a query but are never persisted in the graph.
At a high level, the virtual resource catalog feature decouples the definition of the connection to an external data source and the actual querying. It offers procedures to manage the virtualized resource catalog (create/remove/modify virtualized resources) and also to query them. In the current version there is support for relational (RDB) data sources and CSV files.
Graph and RDB for the following example
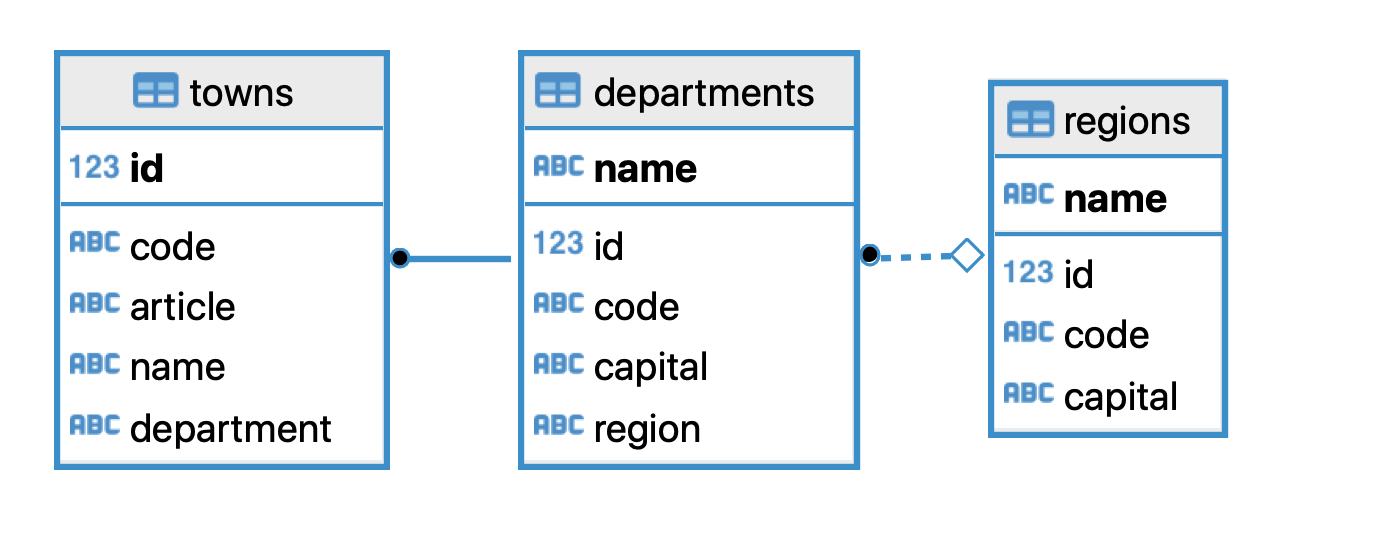
This example uses a database stored in Postgres. You can recreate it using this script. It contains just three tables:
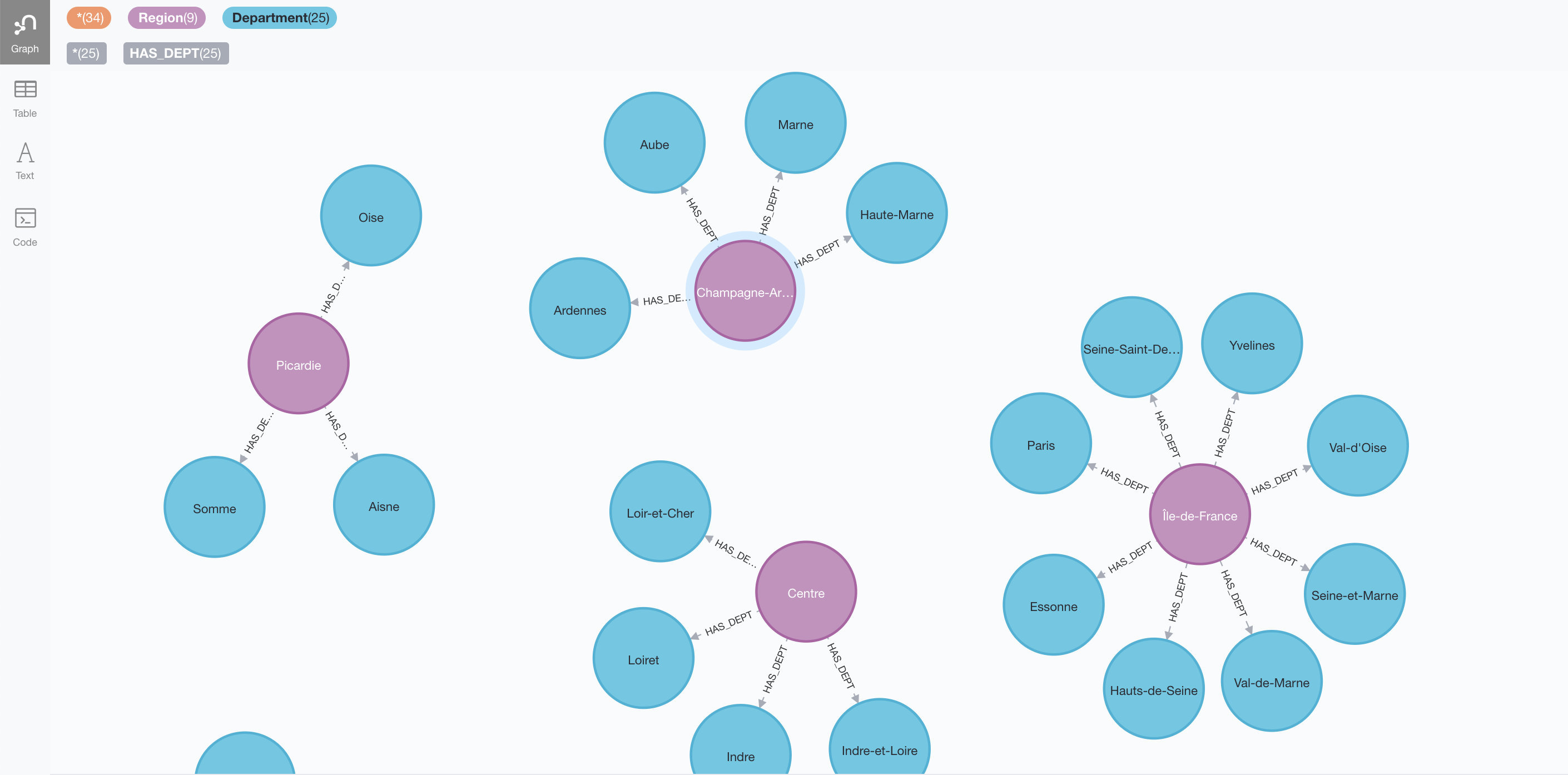
We have imported in Neo4j the regions and departments (script to import is provided as annex) but not the towns, which we will virtualize and only retrieve from the RDB on-demand. The graph looks like this (fragment):
Managing a Virtualized Resource via JDBC
Creating a Virtualized Resource (JDBC)
Before we can query a Virtualized Resource, we need to define it. We do this using the apoc.dv.catalog.add procedure.
The procedure takes two parameters:
-
a name that uniquely identifies the virtualized resource and can be used to query that resource
-
a set of parameters indicating the type of the resource (type), the access point (url), the parameterised query that will be run on the access point (query) and the labels that will be applied to the generated virtual nodes (labels).
We are defining a virtualized resource over a relational database (type: JDBC) accessible locally (url: "jdbc:postgresql://localhost/communes?user=jb&password=jb")
that will return nodes that we will type as Town and PopulatedPlace - the generated nodes will have two
labels (labels: ["Town","PopulatedPlace"]). We also provide the SQL query including the parameters that it requires
and that will be passed at query time.
Finally, we can include an informative description that will help users understanding what the Virtualized resource produces and how to use it.
Here is the cypher that creates such virtualized resource:
CALL apoc.dv.catalog.add("fr-towns-by-dept", {
type: "JDBC",
url: "jdbc:postgresql://localhost/communes?user=jb&password=jb",
labels: ["Town","PopulatedPlace"],
query: "SELECT code, name FROM towns where department = $dept_no",
desc: "french towns by department number"
})For more details on how to pass the credentials to access the RDB check the Load JDBC documentation.
Querying a Virtualized Resource (JDBC)
Once defined, we can query a virtualized resource by name passing only the required parameters. We use the apoc.dv.query procedure for this. It takes two parameters
-
the name of the virtualized resource
-
a map with the parameters required.
CALL apoc.dv.query("fr-towns-by-dept", { dept_no: "73" })The query returns a set of virtual nodes generated on demand by running the query defined in the virtualized resource
and with the parameters passed in the apoc.dv.query call.

Normally we will want to combine this procedure call with data from the graph in Neo4j. Here is an example:
WITH "Basse-Normandie" AS reg_name
MATCH (dep:Region { name: reg_name})-[:HAS_DEPT]->(d:Department)
CALL apoc.dv.query("fr-towns-by-dept",{dept_no: d.code}) YIELD node
RETURN nodeWe may even have the virtualized nodes returned by apoc.dv.query to be linked to the real nodes in the graph providing a richer query result. That’s the purpose of the apoc.dv.queryAndLink method. The apoc.dv.queryAndLink method takes two additional parameters: the node to link the virtual nodes to, and the relationship type to be used for the linkage:
MATCH (dep:Region { name: $regionName })-[hd:HAS_DEPT]->(d:Department)
CALL apoc.dv.queryAndLink(d,"HAS_TOWN", "fr-towns-by-dept",{ dept_no: d.code }) YIELD path
RETURN *The apoc.dv.queryAndLink method returns a path formed by the node passed as first parameter, and the virtual node and relationship returned from the virtualized resource.
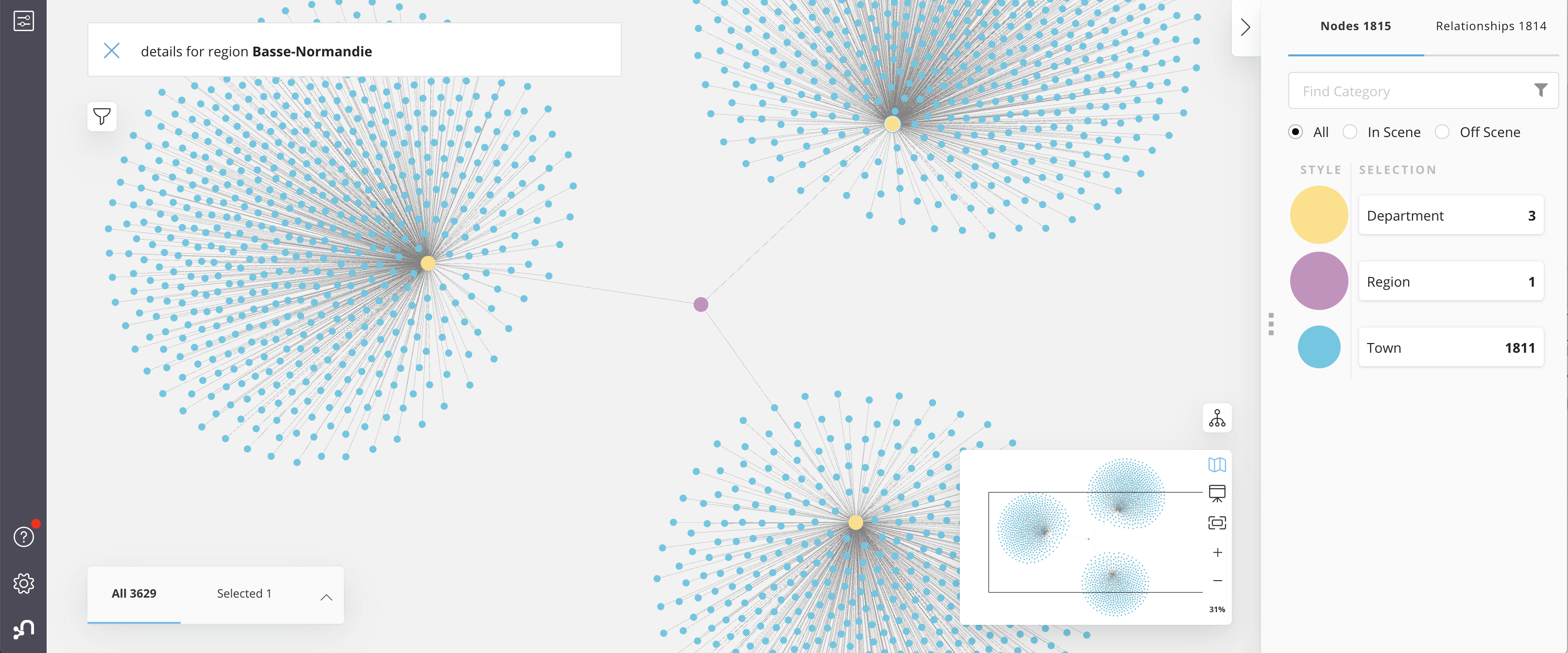
Below is an example of use of the previous query in Bloom. All the blue nodes representing the Towns in a given department are virtual ones retrieved on demand using a search phrase over the previous query.
Listing the Virtualized Resource Catalog
The apoc.dv.catalog.list procedure returns a list with all the existing Virtualized resources and their descriptions. It takes no parameters.
CALL apoc.dv.catalog.list()Removing Virtualized Resources from the Catalog
When a Virtualized Resource is no longer needed it can be removed from the catalog by using the apoc.dv.catalog.remove procedure passing as parameter the unique name of the VR.
CALL apoc.dv.catalog.remove("vr-name")Export metadata
|
To import dv catalogs in another database (for example after a |
Managing a Virtualized Resource via CSV files
Creating a Virtualized Resource (CSV)
The process to define a Virtualized Resource over a CSV file is identical to the one described for relational ones, with the exception of the query parameter.
Let’s think of an example where we have a product catalog in the graph but there is some additional information about the products like the current stock, the unit price, the reorder level that is for some reason maintained in a separate store outside the graph (a file in this case). We’ll show how to seamlessly combine the two bits of information using apoc.dv.
Let’s look at another example where we define a virtualized resource over a CSV file (type: CSV) accessible via HTTP
(url: "http://data.neo4j.com/northwind/products.csv") that will return nodes that we will type as ProductDetails (labels: ["ProductDetails"]).
When it comes to the query, there is not a standard query language like in the case of Relational DBs so we use a
cypher-like notation using the map prefix to refer to the records returned by parsing the CSV file (query: "map.productID = $prod_id").
Note that the file could be also accessed locally using the file:// protocol instead of http://.
Here is the cypher that creates such virtualized resource:
CALL apoc.dv.catalog.add("prod-details-by-id", {
type: "CSV",
url: "http://data.neo4j.com/northwind/products.csv",
labels: ["ProductDetails"],
query: "map.productID = $prod_id",
desc: "Product Details By ID"
})Querying a Virtualized Resource (CSV)
Identical to the JDBC case, we can query a virtualized CSV resource by name passing only the required parameters:
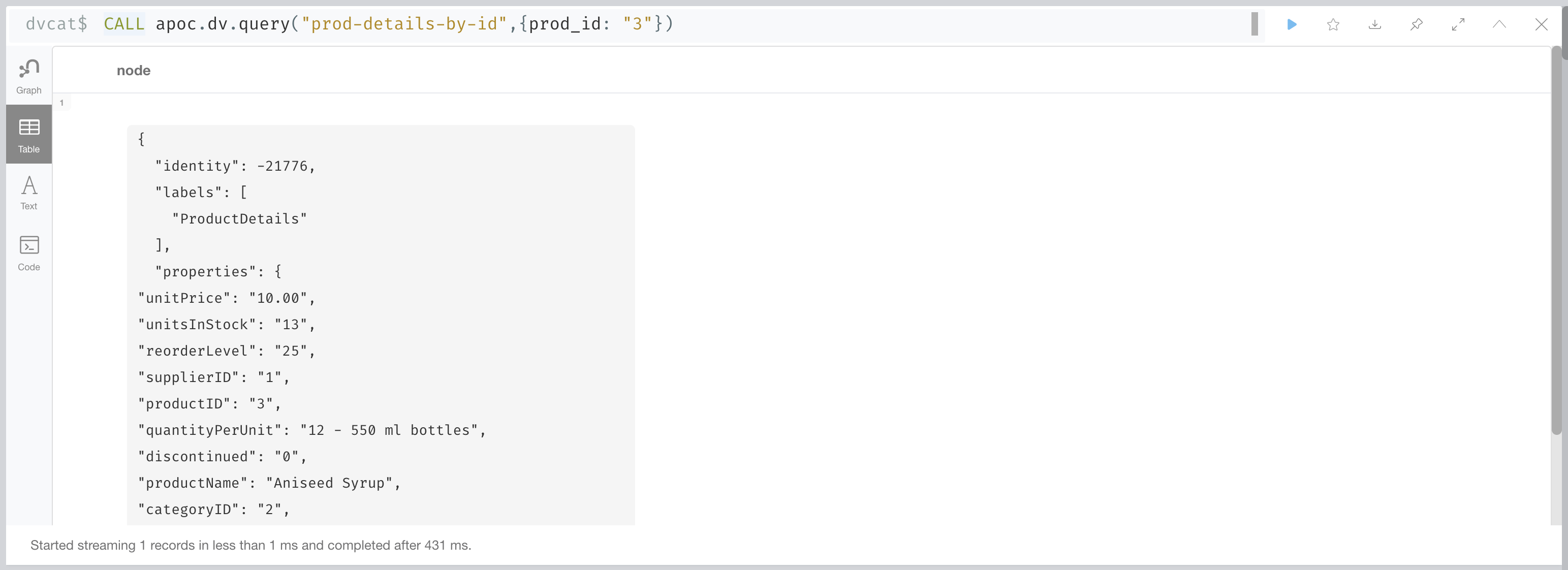
CALL apoc.dv.query("prod-details-by-id", { prod_id: "3" })The query returns one virtual nodes in this case generated on demand by parsing the CSV file defined as a virtualized resource and filtering the records by applying the expression in the query parameter with the parameters passed in the apoc.dv.query call (showing the table view of the virtual node returned).
An example of combining this procedure call with data from the graph in Neo4j:
MATCH (p:Product { productName: "Northwoods Cranberry Sauce"})
CALL apoc.dv.query("prod-details-by-id",{ prod_id: p.productId }) YIELD node as details
RETURN p.productName as prodName,
apoc.any.property(details, "unitsInStock") as unitsInStock,
apoc.any.property(details, "reorderLevel") as reorderLevel,
apoc.any.property(details, "quantityPerUnit") as quantityPerUnit,
apoc.any.property(details, "unitPrice") as unitPriceProducing the following output:
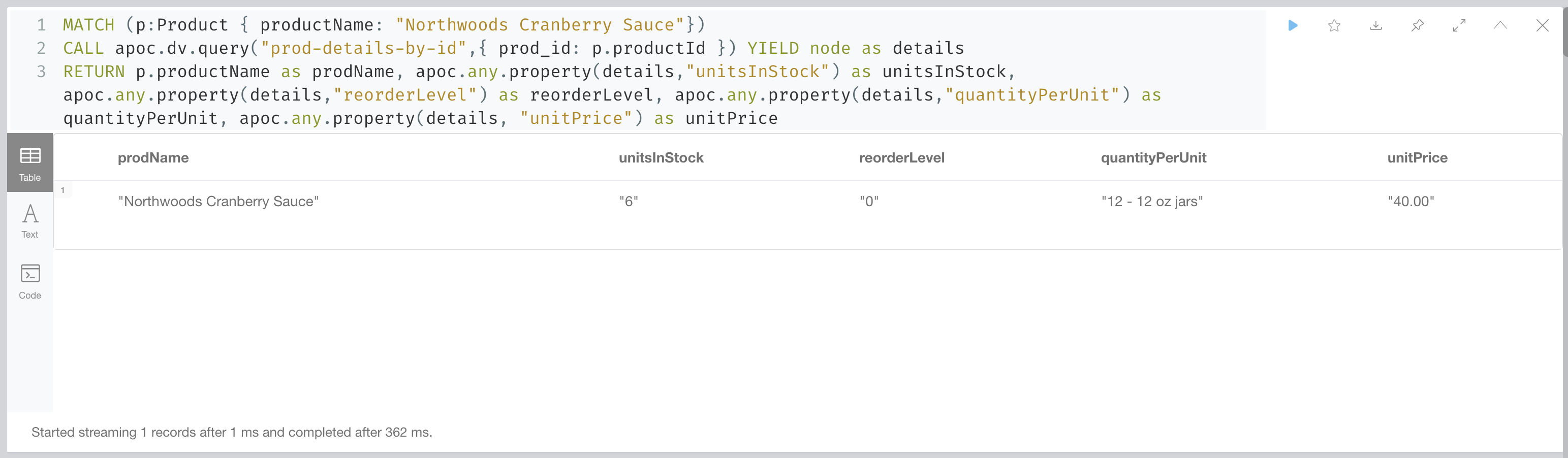
In this case we are producing a tabular result combining data from the graph with data retrieved on demand from the virtualized CSV resource. Notice that in order to access the values of properties in virtual nodes we need to use the apoc.any.property function.
If we wanted to have the virtualized nodes returned by the query linked to the real nodes in the graph, we would use the apoc.dv.queryAndLink method as follows:
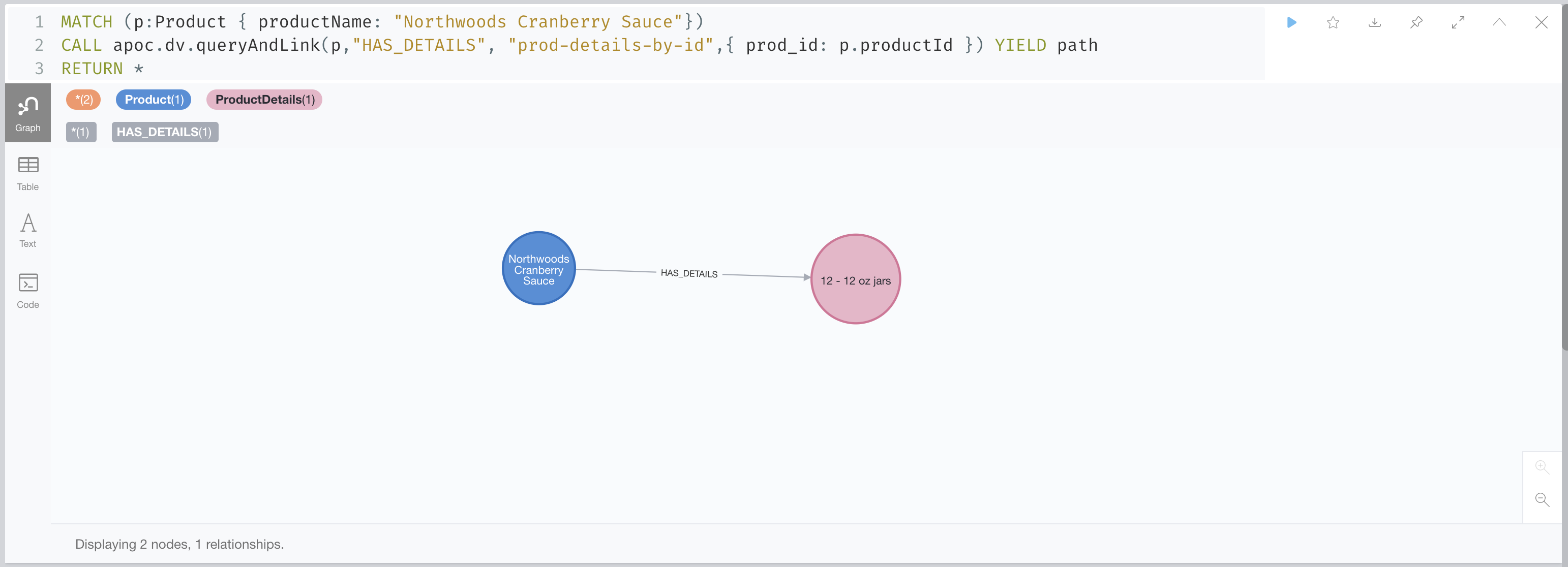
MATCH (p:Product { productName: "Northwoods Cranberry Sauce" })
CALL apoc.dv.queryAndLink(p, "HAS_DETAILS", "prod-details-by-id", { prod_id: p.productId }) YIELD path
RETURN *Producing this output in the Neo4j browser: