Graph data models for RAG applications

Senior AI Solutions Architect, Neo4j
6 min read

When to use graph data models, such as parent-child, question-based, and topic-summary, for RAG applications powered by knowledge graphs.

When building a retrieval augmented generation (RAG) application, it can be tempting to just dump your documents in either a vector or graph database, generate some embeddings, and start running cosine similarity.
In this article, we will discuss a few alternative graph data models that can be used to enhance these applications as well as the unique benefits each model provides. For this discussion we assume that you already have some familiarity with graph databases and RAG.
Here is a GitHub repository containing code to generate and explore these data models via arrows.app or in Neo4j browser. This will allow you to modify the data models for your own applications.
Neo4j

Neo4j provides a graph database with vector indexing which allows us to perform vector search. You can experiment with Neo4j locally with the desktop version or in a cloud-hosted environment on Neo4j AuraDB for free. When initializing your database, ensure you are running Neo4j version ≥ 5.13 to have vector indexing capabilities.
Vector embeddings
A vector embedding is a sequence of numbers that represent media mathematically. This traditionally has been done with words and sentences, though now it is possible to encode audio, images, and videos into vector embeddings as well. The length of a vector is referred to as its dimensionality.
Neo4j supports vectors up to 4096 dimensions, with some typical values being 768 and 1536.
[0.123, -0.423, 0.519, ..., -0.942]
My colleague Adam Cowley has created a great course on Neo4j GraphAcademy detailing how to use vector embeddings in a graph. You can find it here.
Context retrieval
The returned context is determined by the calculated similarity scores between the user question embedding and the text embeddings present in the graph.
It is good practice to decouple the retrieved text from the matched embeddings. This is because raw chunks likely contain filler words and extra/conflicting information that can dilute the encoded information in the embedding.
By embedding smaller and/or processed text chunks, we can make our similarity matches more accurate, and by traversing graph relationships, we can control which text is returned to the LLM for response generation.
Basic graph data model
This graph data model stores text chunks in Document nodes and doesn’t decouple matched embeddings from returned text. We can run vector search against the embedding properties of Document nodes to find the most relevant text to return as context to the LLM. If we’d like we can also traverse the relationships to find each text chunk’s source to provide citations.
This model will work just fine for a proof-of-concept, but it can be greatly improved upon, and there are better options for production applications.
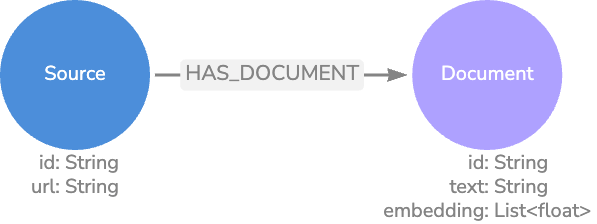
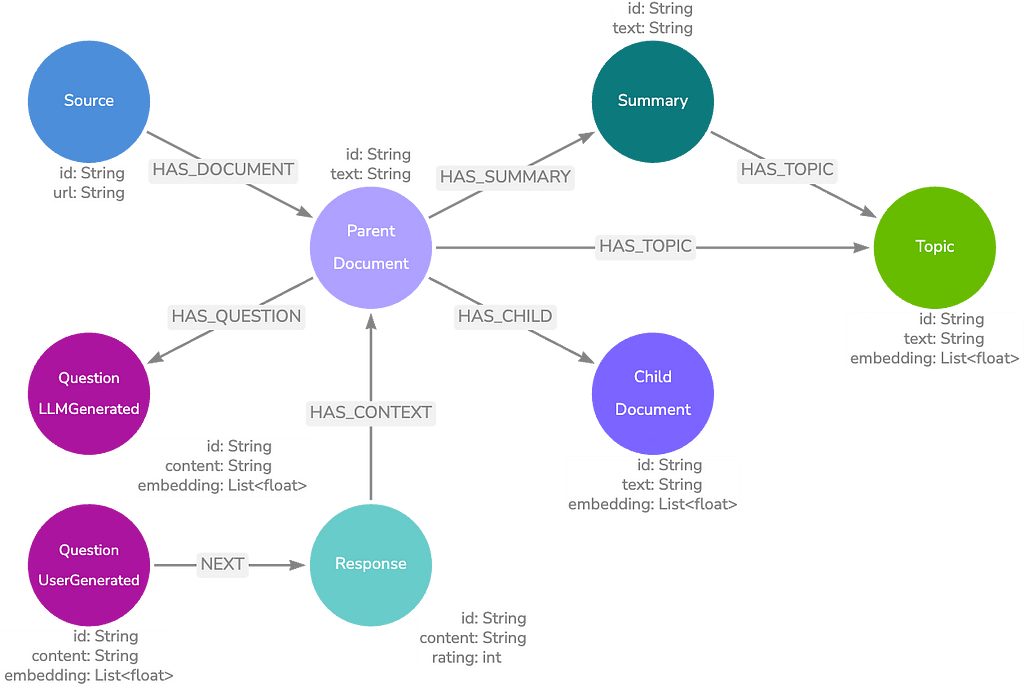
Parent-child
A Parent-Child model is similar to our basic model, but we further break down the text chunks so they are closer in length to our expected questions. This maintains the information granularity between the question and matched text, so we aren’t matching a couple of words against a paragraph.
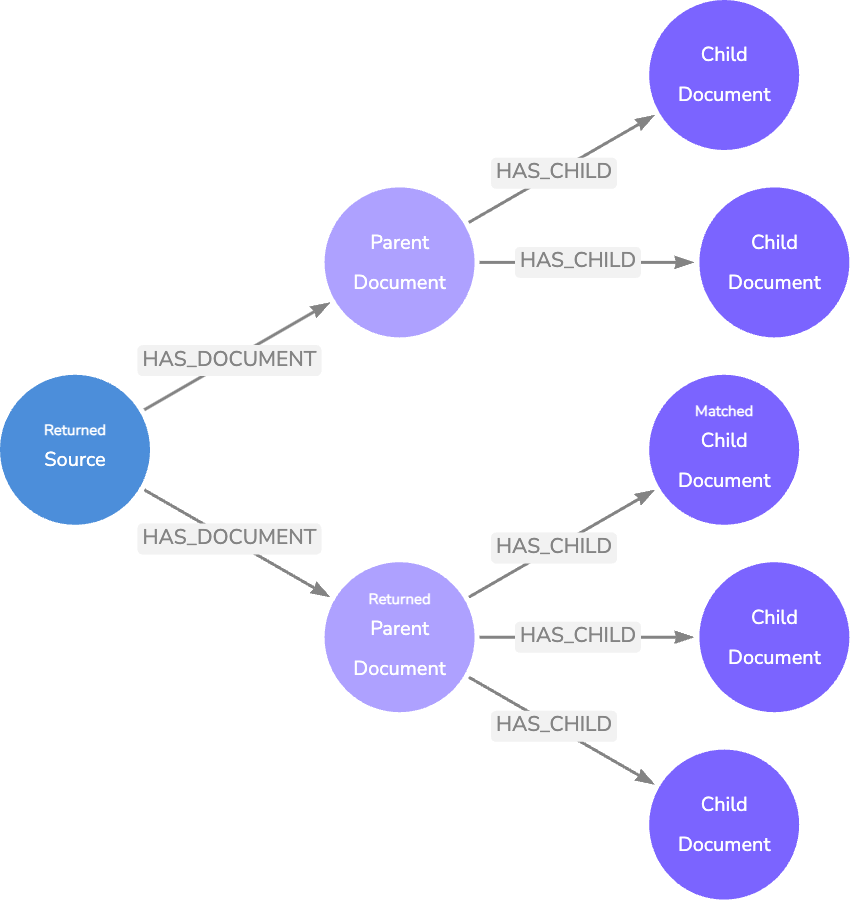
Once we have a Child node embedding match, we can traverse the relationships to retrieve the Parent node text, which contains the Child text plus the surrounding text. This method provides more exact vector search matches, while also returning context-rich results.
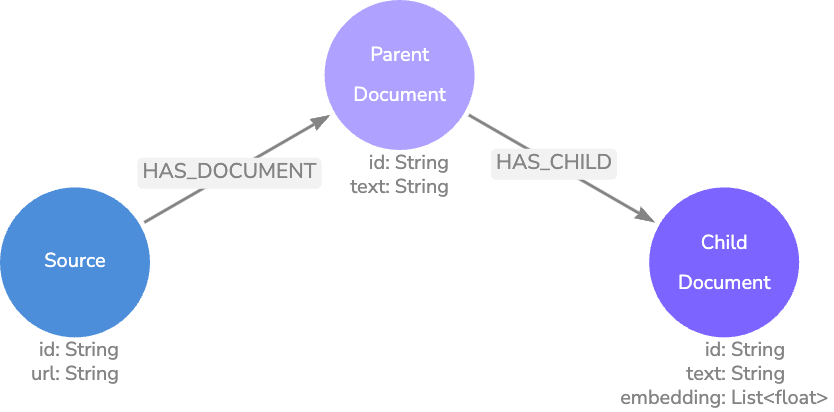
Finding the length of a typical question in your application will require experimentation, but we found that 140 characters were a standard length in our documentation chat application.
Questions
This next data model further expands on the basic model by linking Question nodes to the Documents that contain useful context for an answer.
We can generate questions by passing the Document text to an LLM and asking it to return possible questions the text answers. We can also provide real user questions by logging application activity in our knowledge graph.
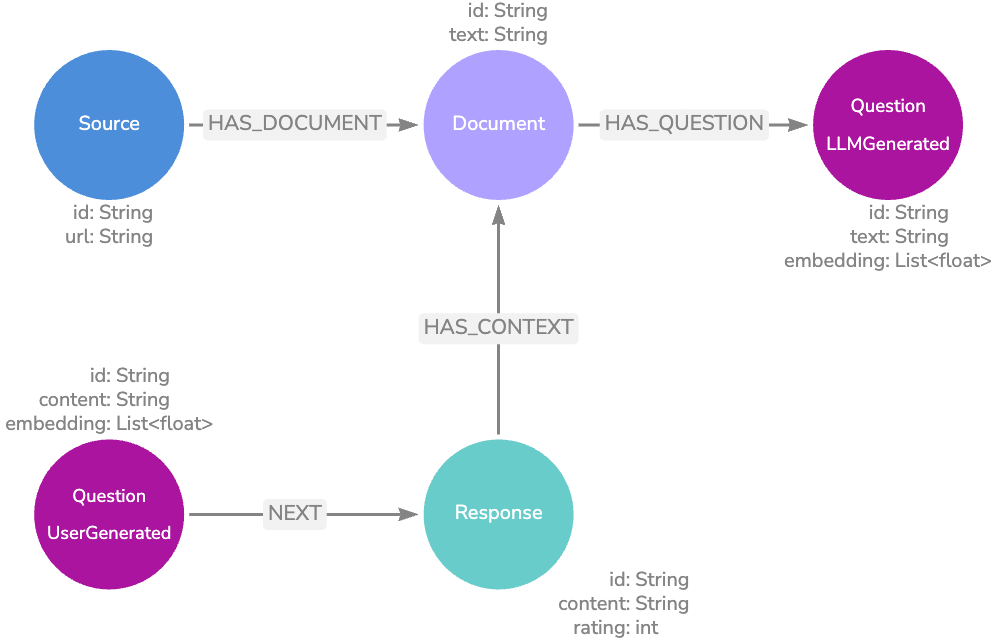
Here, we have two retrieval options.
Our first option is to conduct a vector search against the LLM-generated questions and return the associated Document node texts as context for response generation.
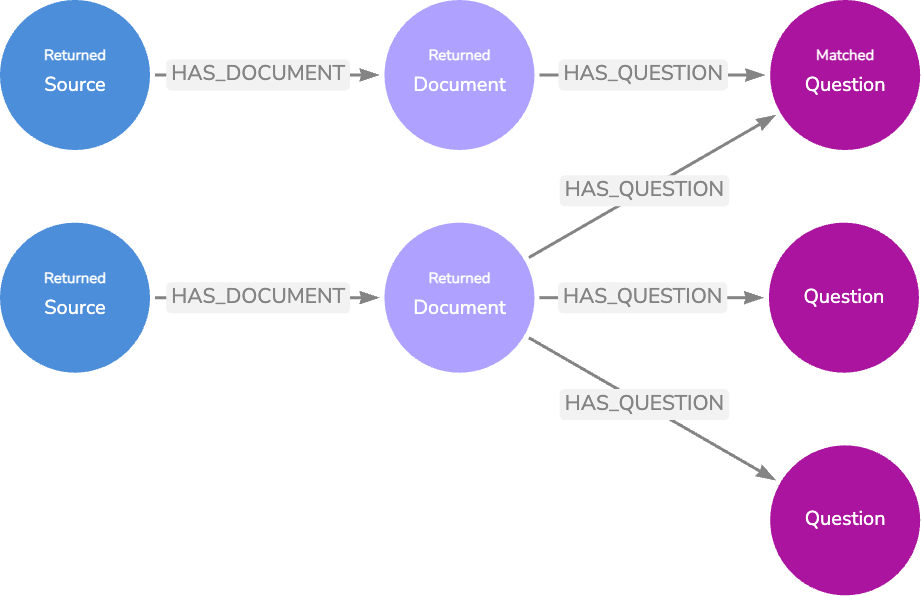
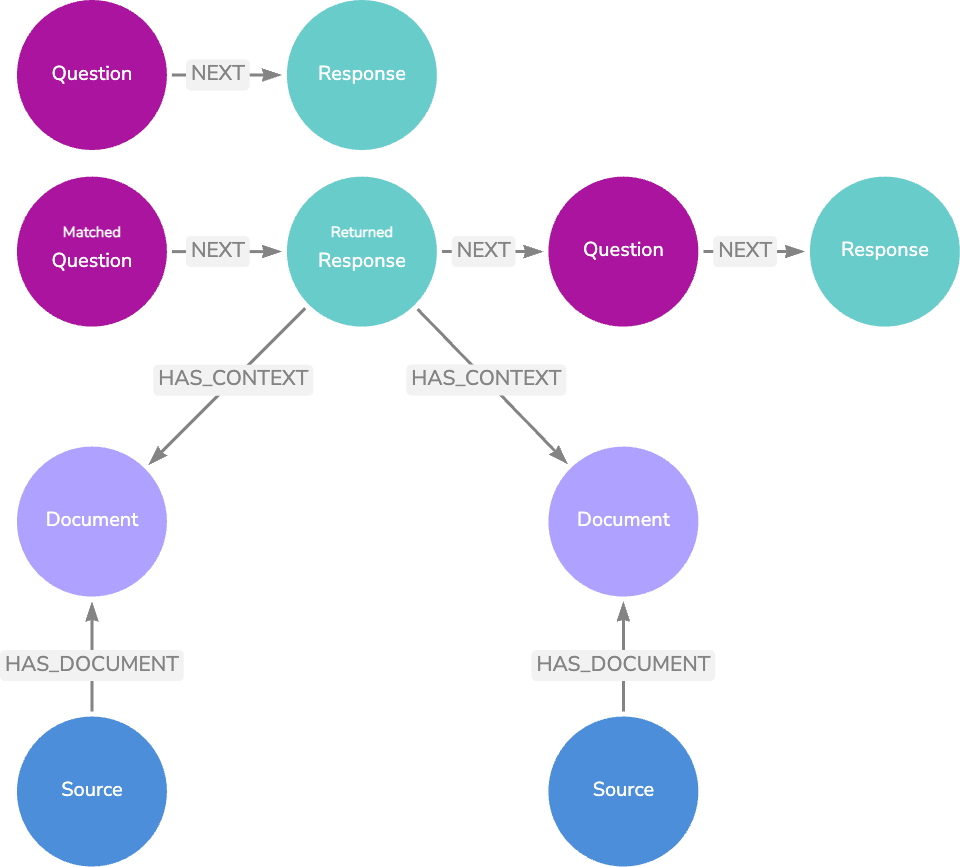
Our second option is to match the real user questions from our logging, and if the question has a relationship with a highly rated LLM Response node, we can return that node’s text — completely bypassing the LLM response generation step. There is no need to return the associated Document or Source nodes since the relevant information from these nodes will already be present in the Response text.
Topics & summaries
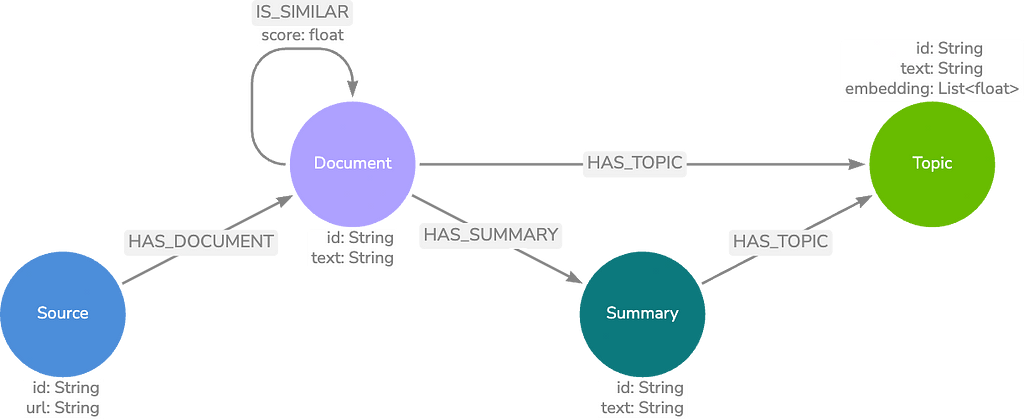
Our next model type will require the use of the Neo4j Graph Data Science (GDS) library. We build on the basic data model by finding communities of Document nodes with GDS and generating summaries for each of these communities.
The communities are based on the text embedding KNN similarity score between Document nodes on the IS_SIMILAR relationship. We store these summaries in Summary nodes and perform entity extraction on the summary text to find topics. By storing these entities in Topic nodes, we can perform a keyword search in addition to our vector search.
A possible retrieval process may be the following:
- Vector index search on Topic node text embeddings,
- Graph traversal from top k found Topic nodes to connected Document nodes,
- Vector index search on found Document pool, and
- Return top k Document node texts and associated URLs to LLM for response generation.
Combining the data models
These models can perform individually or in combination to enhance your application’s capabilities.
Perhaps you’d like to match on user generated questions, but if none are close matches, then match on Child nodes in a Parent-Child architecture.
The Topic and Summary nodes may also provide valuable information beyond enhancing retrieval. They can be used in meta-analysis to validate that your knowledge graph is capable of providing answers to particular questions.
Conclusion
Graph data modeling for RAG applications is an ongoing development and is constantly evolving. The models we discussed above can be modified as needed to fit your use cases and hopefully will serve as inspiration for your own projects. Here is a GitHub repository containing code to generate and explore these data models via arrows.app or in Neo4j Browser.
Some models work best when logging application activity directly in the knowledge graph. Dan Bukowski and I detail the benefits of the knowledge graph logging style in the blog series Context Is Everything.
Graph Data Models for RAG Applications was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



