Architectural Guidance
|
The Kafka Connect Neo4j Connector is the recommended method to integrate Kafka with Neo4j, as Neo4j Streams is no longer under active development and will not be supported after version 4.4 of Neo4j. The most recent version of the Kafka Connect Neo4j Connector can be found here. |
The purpose of this section is to:
-
Describe how this integration works
-
Discuss the architectural issues that are at play
-
Provide a basis for advice on how to build systems with Neo4j & Kafka
| Customers should use the information in this document to design the best possible pipelines to connect graphs and streams. |
The Challenge: Graph ETL
Data coming from Kafka isn’t a graph. When we load JSON documents or Avro into a Graph, what we’re actually doing is extracting relevant bits of data from some input message. We’re then transforming those relevant bits into a "Graph Snippet" and then loading it into Neo4j.
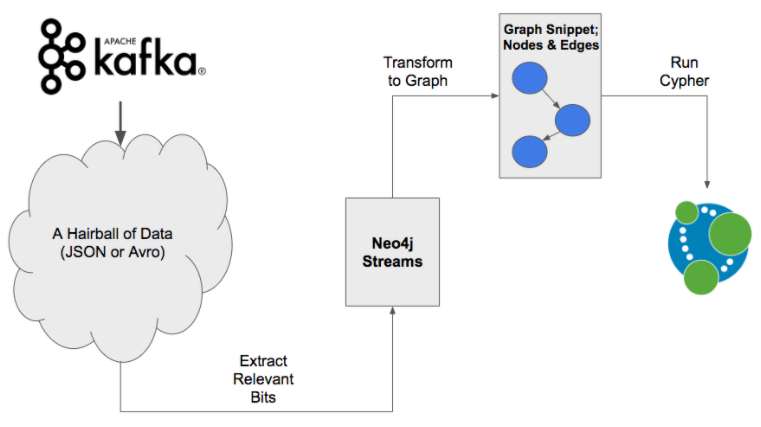
Using neo4j-streams is a form of graph ETL. And it pays to separate out these two pieces (the extraction and the transformation) and handle them separately if we want to do this in a performant and easy to maintain manner. If we are producing records from Neo4j back out to Kafka, it’s still the same challenge, just in the opposite direction.
Streaming ETL is nothing new for Kafka — it is one of the platform’s core use cases. A big complicating factor for Neo4j-streams is that not many people have done it for graph before neo4j-streams.