Factors which Affect Throughput
|
The Kafka Connect Neo4j Connector is the recommended method to integrate Kafka with Neo4j, as Neo4j Streams is no longer under active development and will not be supported after version 4.4 of Neo4j. The most recent version of the Kafka Connect Neo4j Connector can be found here. |
This is primarily around sinking records from Kafka → Neo4j, but many of the same principles apply to production of records to Kafka.
Neo4j Settings
In general, Neo4j-Streams is writing to Neo4j with a strategy of:
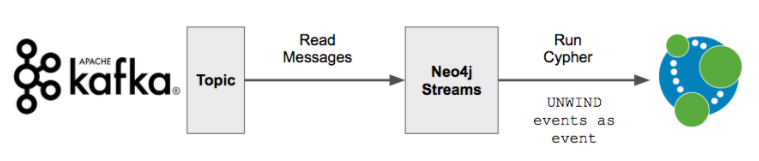
UNWIND events AS event
(your cypher here)And so a critical factor is how many items are in the "events" array, per-transaction.
-
Heap sizing affects how big transactions coming from Kafka can be without starving other queries that are running
-
Page cache sizing affects how much data is hot and has a major impact on the cypher queries that neo4j-streams runs.
Kafka Consumer Settings
A major factor is how much data you pull from Kafka at a time, and how that turns into a batch of records. How this works is that Neo4j-Streams uses the official Java client for Kafka to talk to the message queue, and runs a poll() operation in Kafka. Settings that start with kafka.* in the config apply to this client, and control how it polls, how much memory it uses, how big the batches are, and so forth. Misconfiguration of this can cause major performance problems, for example if you get 1 record per polling operation, then you will write to Neo4j in batches of 1, maximizing the overall time you spend in transactional overhead.
More information in this excellent documentation on how Kafka consumers work. In particular, check "The Poll Loop" section, which is what Neo4j-Streams is doing internally.
Some generalities for Neo4j:
-
Batch size (
neo4j.batch.size) - the number of messages to include in a single transactional batch. -
Max Poll Records (
kafka.max.poll.records) - the number of records to use per transaction in Neo4j. There is a tradeoff between memory usage and total transactional overhead.-
Fewer larger batches is faster to import data into Neo4j overall, but requires more memory.
-
The smaller the payload the larger the batch in general (via unwind). A default to start with is 1000 and work your way up. If you are only creating nodes via unwind you can go much higher (20k as a start). Then go for a lower number for the relationship merges (back to 1000-5000). Each batch represents a transaction in memory, and consider that the message size * the batch size is an important factor in determining how much heap you need for your transactions.
-
-
Fetch bytes (
kafka.max.partition.fetch.bytes) The maximum amount of data per-partition the server will return. Records are fetched in batches by the consumer. If the first record batch in the first non-empty partition of the fetch is larger than this limit, the batch will still be returned to ensure that the consumer can make progress.
Every time the kafka client calls the poll() operation, it’s limited by these factors. The first is the maximum number of bytes you can pull, so as to constrain your memory overhead. The second is how many records you might want in a batch. Note that at this layer you have no idea how many bytes/record. The default for the batch size is 1mb. So say you have 200kb records (big json files). If you leave batch size at 1mb default, then you’ll never have more than 5 records/tx. The max poll records constrains the other aspect. Finally, you may wish to read into or adjust kafka.max.poll.interval.ms to constrain the amount of time spent polling in advanced scenarios. See this documentation for more information on that setting.
A logical setting might be to set max poll records = your desired transactional batch size, set neo4j.batch.size to the same number. In general you can leave kafka.max.partition.fetch.bytes the same, but if you need to adjust it for memory reasons, it should be equal to max poll records * number of bytes/record on average, + 10% or so.
(Use these with neo4j-streams by prepending with "kafka." in the config)
Kafka Partitioning Strategy
A big factor can be how the Kafka topic is set up. See how to choose the number of topics/partitions in a Kafka Cluster.
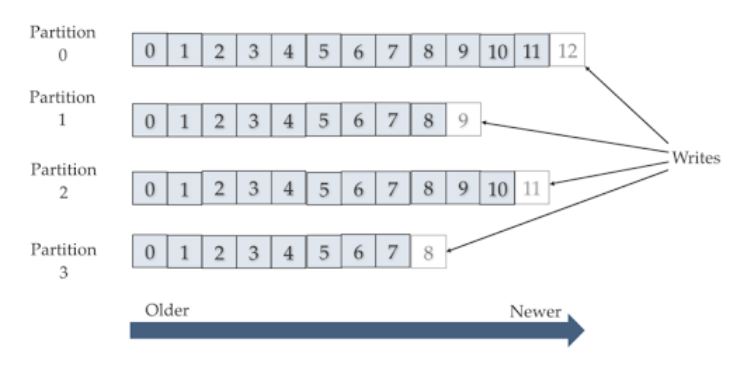
Here are some key observations:
-
More partitions in a Kafka topic means better overall throughput
-
A single partition is absolutely necessary if end-to-end message ordering is critical (for example in CDC setups)
-
More partitions requires more memory & concurrency