Source: Producing Records to Kafka
|
The Kafka Connect Neo4j Connector is the recommended method to integrate Kafka with Neo4j, as Neo4j Streams is no longer under active development and will not be supported after version 4.4 of Neo4j. The most recent version of the Kafka Connect Neo4j Connector can be found here. |
This chapter describes principles about how to produce data from Neo4j out to Kafka in a performant manner.
General Principles
-
Don’t publish everything, be thoughtful about just which bits to publish to spend little time in the plugin code
-
Think twice if you regularly do very large transactions about what other strategies you might have available to you to publish (for example, APOC triggers + custom cypher code + neo4j-streams procedures to "custom publish" to Kafka)
TransactionEventHandlers
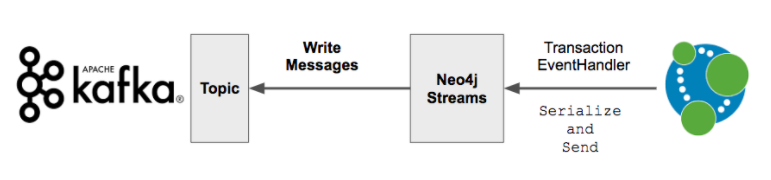
The way we produce records to Kafka is with a transaction event handler. This comes with several important caveats:
-
In Neo4j, a transaction cannot finish committing for the client until all TransactionEventHandlers have finished (or delegated their work to separate threads). This means that because work is necessary to serialize transactions and send them out on the wire, using a producer can slow the commit speed of the underlying transaction
-
Very large transactions may be problematic, because they have to be serialized into a very large amount of data (for example, a single JSON document) and so it is important to configure the plugin in a way with memory management settings to keep this in mind
-
TransactionEventHandlers only fire on the leader. So if you configure Neo4j-Streams for a Causal Cluster, you must do so for all CORE members in the cluster. As the LEADER rotates around the cluster, transactions will always be published, but this requires consistent configuration on all 3 CORE nodes. When transaction replication happens from LEADER → FOLLOWER, the transaction commit will not fire, and there will not be duplicate publishes.
Custom Publish
The source plugin is intended to publish in the Debezium format, which is as close as the Kafka ecosystem has to a data standard for this sort of thing. But sometimes you will find this constraining, and you may need to publish in a custom format.
As of this writing, the best option is to write a combination of Cypher + APOC Triggers. The APOC trigger can selectively fire when key updates are made to the system, using the same TransactionEventHandler approach as above. And the "triggered code" can be Cypher which you can use to process the resulting data and format any message you like to be sent to Kafka with CALL streams.publish().