Sink: Consume Records from Kafka
|
The Kafka Connect Neo4j Connector is the recommended method to integrate Kafka with Neo4j, as Neo4j Streams is no longer under active development and will not be supported after version 4.4 of Neo4j. The most recent version of the Kafka Connect Neo4j Connector can be found here. |
This chapter describes the different ingest strategies, when to use them, and when to avoid them.
Important Information About Batch Imports Into Neo4j
Because writing relationships requires taking a lock on both incident nodes, in general when we are doing high-performance batch inserts into Neo4j, we want a single-threaded batch, and we do not want parallelized load processes. If you parallelize the loads without careful design, mostly you will get some combination of thread waiting, and lock exceptions / errors.
As a result, the general approach should be to serialize batches of records into a stream of "one-after-the-other" transactions to maximize throughput.
Overview
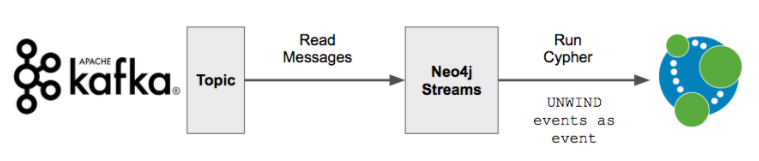
This shows the cypher ingest strategy. This is a high level view though - we take messages from Kafka and write them to Neo4j, but it isn’t the whole story.
General Principles
Before you get fancy with import methods!
-
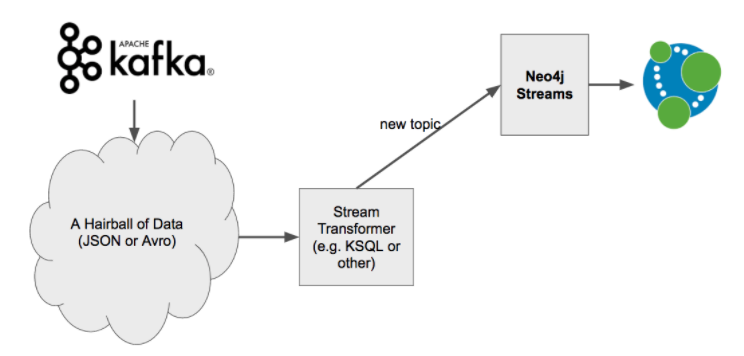
Use Kafka! Don’t Use Neo4j for Everything: In general, it is better to use Kafka and things like KSQL to re-shape, transform, and manipulate a stream before it gets to Neo4j. At this stage, you have more flexible options and overall better performance. Look back at that "Graph ETL" bit. Try to make neo4j-streams only do the transform and load parts, as they are inevitable for graph.
-
Don’t Do Complex ETL in Cypher: Seek to avoid situations where you are doing complex transformations of inbound messages to Neo4j. It is possible to do with pure Cypher, but basically you will be pushing a "Kafka message cleanup" task and delegating that to Neo4j to perform, which is not a good strategy if you can avoid it.
-
KISS Principle: The simpler the input format, the better / cleaner more evolvable the architecture, and the less work Neo4j has to do.
-
Keep Topics Consistent: Topics which contain a variety of differently formatted messages should be avoided whenever possible. They will be very difficult to deal with, and you shouldn’t attempt it unless you absolutely have to.
This can get challenging in constrained customer environments where you have no control over the topics or their contents, so this is just presented as a set of principles, not hard rules.
Change Data Capture - CDC
-
Requires a specific debezium JSON format that specifies what changed in a transaction from another system
-
Extremely important: for CDC usages, message ordering matters, and so a single Kafka topic partition is advised — but because of this, throughput can be impacted because parallelization isn’t an option.
-
Contains two sub-strategies: SourceID and Schema strategies, which apply to particular CDC cases, and allow you to merge data in particular ways. These sub-strategies are only interesting if you have Debezium format data.
-
Use When:
-
Trying to mirror changes from another database that knows how to publish in Debezium format
-
-
Avoid When:
-
Custom message formats over topics, or messages coming from other applications and not databases.
-
-
Other considerations & constraints:
-
SourceId may be vulnerable to internal ID reuse, which can result from deletes or backup restores. Use caution when using this approach unless you have hard constraints on ID uniqueness.
-
The Schema strategy relies on unicity constraints, which can’t be used on relationship properties. That means relationship keys are effectively the source node + the destination node + the relationship type, which in turn means that the model may not have multiple edges of the same type between 2 nodes.
-
The Pattern Strategy
-
This contains two sub-strategies: The Node and the Relationship strategy.
-
The pattern strategy always assumes that the inbound message represents 1 and only 1 node or relationship.
-
All of the specifics of the sub-strategies (Node & Relationship) deal with which parts to import, and to what node label or relationship type.
-
Use When:
-
Best for high volume, very granular import, where you want to extract particular attributes out of the message.
-
-
Avoid When:
-
You have big complicated JSON documents that you don’t control that represent a mixture of nodes & edges.
-
The CUD Strategy
-
This is similar to the Debezium CDC format. CUD stands for "Create, Update, Delete". It is a method of "sending commands" to Neo4j through Kafka to create, update, or delete a node or a relationship
-
Use When:
-
This is a good option when you can take a complex upstream message and reform it (within Kafka) to a bunch of simple commands. It’s a good technique for "taking something complicated and making it simple"
-
You need to stream back changes from a read replica to a core. For example, if you run a GDS algo on a read replica and then want to update a property to set a community identifier, you can’t do that on a read replica. But you can publish CUD messages from the read replica from Kafka, and then have the cores set to ingest that on a particular topic. In other words — this is a method for inter-Neo4j cluster communication.
-
-
Avoid When:
-
This strategy requires a tightly constrained data format, so it is not appropriate when you don’t control the topic.
-
The Cypher Template Strategy
-
This is the generic catch-all strategy for processing any inbound message with any cypher statement.
-
It is the most powerful and also the hardest to configure because it requires that you code cypher in a configuration file.
-
Use When:
-
It is best when you can’t control the input topic, and when you need to transform the input data as opposed to just loading it into a structure.
-
-
Avoid When:
-
Cypher queries grow to be long and complex, or need to change frequently. This is a sign that too much extraction & transformation work is being pushed to Neo4j, and a stream transformer is needed.
-
Parallelism
The plugin always operates in sequential batch transactions, connected to individual polls of the Kafka client.
An individual kafka client thread proceeds like this:
* Grab records from Kafka
* Formulate a batch of "events"
* Write those to Neo4j, generally of the form UNWIND events AS event
See information in the Kafka documentation on how the poll() operation works for full details.
Loading Many Kinds of Data At Scale
If we want to load 8 types of nodes & relationships in a performant manner, how do we do that?
General advice
-
Break the data you’re loading into multiple different topics of 1 partition each, rather than having 1 big topic of mixed / large content
-
Use stream transformers and KSQL techniques to craft messages into a format where you can use one of the other ingest strategies other than Cypher templates, to simplify the code you need to write, and to avoid needing to cycle the cluster due to cypher query changes.
-
Experiment with batch sizing & memory sizing until you get good throughput