



Presentation Summary
Prepr is a multi-channel engagement platform that streamlines content workflows and powers valuable audience interactions.
They were using the MySQL relational database to manage their data, but it was becoming increasingly slow — and they had millions of data points and properties to manage.
By switching from MySQL to Neo4j, they were able to provide powerful, real-time recommendations on both the back and front-end of the user experience. For one of the largest events companies in the Netherlands, Prepr created a dynamic queueing tool that could identify customers in a queue that would be most beneficial for that company to sell tickets to. These recommendations were based on the real-time analysis of information such as the number of social media followers of a customer, or the amount of money they spent at the festival in prior years.
On the customer-facing side, Prepr was able to provide users of the website I amsterdam, one of the largest tourism websites in the city, with a chatbot that provided real-time event recommendations based on things like the user’s location, the time of day and the weather.
The fast, scalable and highly-performant Neo4j graph database provided Prepr with exactly what they needed to create these highly effective tools, while requiring less storage and hardware than their previous database.
Full Presentation: Large-Scale Real-Time Recommendations with Neo4j
What we’re going to be talking about today is how we used Neo4j to provide real-time recommendations in the context of events and ticket sales, both on the front-end for customers and on the back-end for ticket queueing:
I’m Tim Hanssen, the CTO of Prepr, a multi-channel engagement platform that streamlines content workflows and powers valuable audience interactions. We founded the company in 2014 in Utrecht in the Netherlands, and currently have a team of 17. We’re a niche player in the media, publishing and events sector, and I’m going to show you how we use Neo4j.
First and foremost, our goal is to create high engagement. Our clients want valuable relationships with their audiences through as much interaction as possible. More customer interactions result in a bigger impact, which in turn leads to more conversions.
The Prepr Software Architecture
Below is a summary of the different iterations of our data architecture:
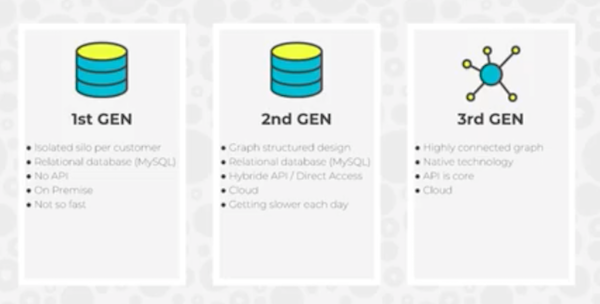
We started with a simple MySQL relational database, which had simple storage for each customer. Then we moved to a sort of tabular design that included a graph within MySQL, but that became so slow over time that it really didn’t work for us anymore.
About three-and-a-half years later we moved to Neo4j, which we piloted for about six months next to our existing database before moving into production.
As of yesterday, we had more than 48 million nodes, 353 million node properties and 164 million relationships. Each day we remove and add half a million nodes in temporary storage, while the rest lives permanently in our database.
Case Study 1: Ticket Sales
Most of our clients are from the media sector, and include the majority of media companies in the Netherlands:

Let’s dive into a case study with ID&T, a Dutch entertainment company that is known for organizing the world’s biggest electronic music festivals such as Mysteryland, Sensation and Thunderdome, which can draw as many as 60,000 to 200,000 people.
We needed to know: Who are the people coming to the website, and how can we sell them more tickets?
We started doing data collection, which I’ll walk through in a minute. The second focus point was getting those tickets into personalization so people couldn’t resell them. And finally, we had to create a dynamic queue before ticketing sales began in order to maximize ID&T’s revenue.

We would ask our database to give us all the events coming up in the next 90 days and then compare ticket sales from the last three years to determine how we were performing against historical data. In our SQL database we had to calculate this each night, but with a graph database we could do it in real time.
We collected data related to ticket sales, and started requiring pre-registration before buying a ticket with apps like Facebook or Spotify so we could see what types of people were interested in going to the festivals:
We also collected data to see how people were interacting with the website, including what content they’re looking at. This allowed us to build a simple profile:
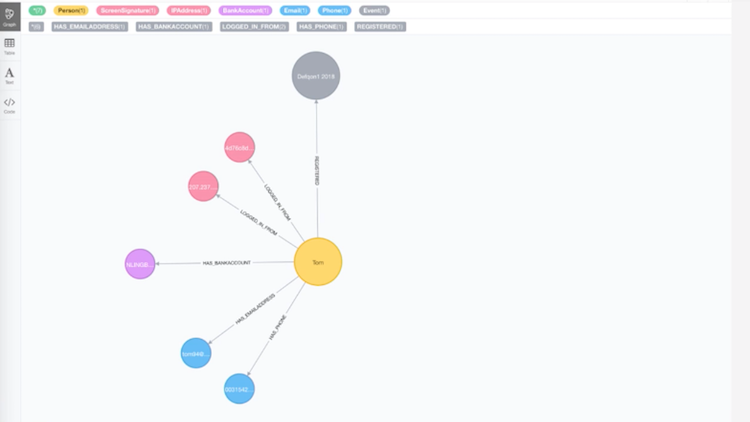
In this example, we have a user named Tom – represented by the yellow node – who has a linked bank account, logged in from a device or a screen, bought a ticket for Defqon.1 and registered with an email address and a phone number. Nothing too complicated.
The next slide shows information about the tickets he bought:

He bought one ticket for fit access on Sunday, and two for Saturday.
On our next slide, you start to see something strange happening:
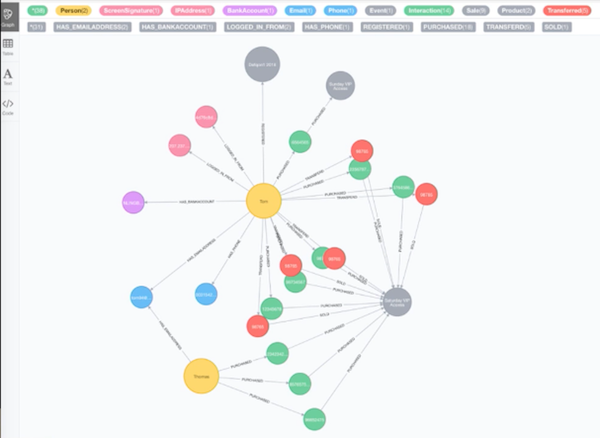
Another user named Thomas is using the same email address as our first user (Tom). And they are both buying and transferring a lot of tickets, which indicates that they are probably trying to resell their tickets for a profit. We want to know this information so that we can filter them out.
We also collect data from users to provide dynamic queues:
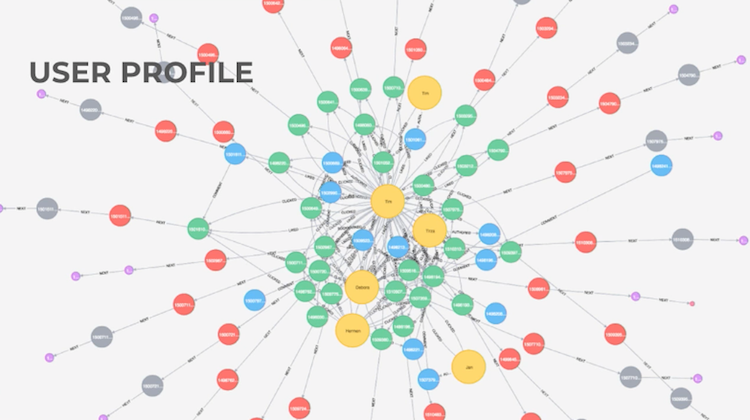
This includes data related to ticket sales, Facebook views, interactions and how many friends they have on Facebook to determine the size of their influence, etc. – all of which are things that are sent back to our database in real time. We use all of this data to create a dynamic queuing score, which allows us to sell tickets to high-spending fans and top influencers to maximize revenue.
Take an example in which a festival is selling 200,000 tickets, but 500,000 people want to buy tickets. We use dynamic queueing so that the people who we really want at the festival can buy tickets. People who would get preference include top social media influencers and people who bought a lot of food and beer at the prior year’s festival. Based on the real-time collection of this data, we can make a background recommendation for who the company should sell their ticket to – which the customer doesn’t see.
Case Study 2: Event Recommendations
As mentioned earlier, we also work with I amsterdam, a marketing organization in Amsterdam that promotes the biggest events for three main target audiences: residents, visitors and businesses. They have around one million website visitors each month, and list hundreds of happenings in an event calendar.
We use the clickstream data for our recommendation tool, Goochem. This is a chatbot that asks the user their mood, and then based on information like location, time of day, day of the week or weather, it provides real-time recommendations for events the user might be interested in.
Database Requirements
We had several requirements for our new database:

Our new database had to be faster and have high availability, because as many as 200,000 people could be in a queue at any given time.
We wanted everything available in real-time so that we wouldn’t have to continually recalculate and run data like we did with the MySQL store. We now run more than 34 million requests each day, and in any given minute there could be 55,000 people trying to preregister for an event. All of these users need to be placed in a queue, which you can easily do by just inserting them into the database, something that works fine in our new store.
With MySQL we could only handle 5,000 people in the store, and it required five times the hardware. And because these operations are business critical, everything has to be up and running smoothly 24/7.
Architecture Overview
Below is an overview of our database architecture:
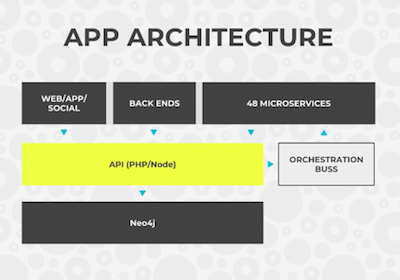
We have a REST API on a PHP/node along with a microservices platform, and we store everything in the Neo4j database. And this really means everything, from login information to user linking, since we no longer use any additional data stores.
This is done by a three causal clustering server with 6 CPU and 60GB of RAM, compared to our old MySQL systems which required six times the storage and hardware, but could only handle half the number of peak moments. We use HAProxy to handle the load balancing and High Availability.
Why We Chose Neo4j
There are a number of reasons we chose Neo4j.
We wanted to use native graph technology because our database already included a graph model. Neo4j is a proven technology used by a lot of people, and it’s extremely performant – our average response time is about 128 milliseconds. Additional benefits include its availability, scalability and query language – Cypher – which we love.
One of our biggest challenges was finding a hosting solution that had experience with Neo4j at this scale. It took about a year with our hosting partner to really get it right. It was also challenging to find developers who knew Cypher, so we had to train them ourselves – but we think Cypher is the best thing that’s happened to us.
Level up your recommendation engine:
Learn why a recommender system built on graph technology is more powerful and efficient with this white paper, Powering Recommendations with Graph Databases – get your copy today.
Read the White Paper
Learn why a recommender system built on graph technology is more powerful and efficient with this white paper, Powering Recommendations with Graph Databases – get your copy today.
Read the White Paper





