
Overview of the Neo4j Graph Data Platform


18 min read
GraphStuff.FM Episode #3
In this episode of the GraphStuff.FM podcast, Lju Lazarevic and Will Lyon break down how the different pieces of the Neo4j Graph Data Platform fit together.
They discuss the individual components of the graph platform, how developers and data scientists can get started, and why the value delivered by the platform is greater than just the sum of the individual components.
Introduction
In this episode, we are discussing the Neo4j graph data platform. To provide some context, we’re going to be covering:
- The backstory of Neo4j
- Neo4j use cases
- How the platform has evolved over time and the amazing tools that are available today
History of Neo4j & the Evolution from Graph Database to Graph Platform
Neo4j is fundamentally a graph database. Let’s start off by talking about why Neo4j was created, and how it’s evolved from those early days.
Neo4j was first created as an embedded Java database; this is where that “4j” in the name comes from. It has since evolved beyond that, so the “4j” Java aspect is no longer really relevant today, but is a nod to its history.
Neo4j was created to address some problems that the founders were having in building a Content Management System (CMS), specifically for some of the rights and metadata around the usage of photos. They found it very difficult to represent in a relational database because of all of the different connections and relationships, and the richness of the data. So that’s why Neo4j was first created.
The founders quickly realized that there were lots of other interesting use cases beyond just this embedded database in the CMS application. So Neo4j quickly evolved into a more generalized system. There was rapid uptake of Neo4j, where it was being used for generating personalized recommendations, as well as handling logistics and routing. It was also popular for dealing with the complex access patterns, inherent in things like identity and access management and fraud detection, where you’re interested in the connections between actors and a payment network.
Another example is Customer 360, where an enterprise wants to understand the different components and interactions that they’ve had with a customer throughout their journey with the organization. Also use cases like monitoring network operations — if you’re responsible for a data center, being able to understand all the connections from the hardware — what rack is a server deployed on, to the different interfaces, right down to the software applications deployed, and all associated dependencies.
These are some of the first core use cases where Neo4j really started to shine. Being able to understand the connections in your data, and why those connections are important to you, highlighted this idea of a “graph-shaped problem’’ (previous webinar video: Are you looking at a graph shaped problem?).
The real power of Neo4j is that not only can you examine those relationships, but you can do this on transactions, and apply it to real-time events as they’re happening. For example, somebody requests a new financial product. You want to be able to identify any potential fraud associated with the request. Being able to apply graph analytics on your existing data whilst incorporating new data coming in enables you to understand in real-time whether to approve or reject the request.
There are many different types of users working with the database: developers, administrators, data scientists, analysts, and so forth. When the ICIJ was looking at the Panama Papers, we saw this idea of many different users being involved — the idea of the citizen scientist going off and looking at the data, the technologists building the solution, and the journalists getting involved using their domain knowledge to research people of interest.
Another fun thing about working with Neo4j and exploring some data is the flexibility you have with the data model. You still need to think about how your data elements are related to each other, but it doesn’t have to be perfect. You don’t have to declare your schema intentions ahead of loading data, which allows you to get your data in as quickly as possible and then test that hypothesis straight away.
So from a proof of concept perspective, the graph database model allows us to test ideas out rapidly and iterate at pace.
It’s also important to understand the context of larger trends going on in the developer and data science ecosystem as well. For example, realizing that we live now in a cloud-first world. Developers have expectations around tooling and ease of use and what they can accomplish within a certain amount of time.
As a developer, when I’m using a new tool, I have greater expectations for what I can accomplish in that first hour, and that first week, by using the tool. Nowadays, I expect to be able to build and deploy an application within just a couple of days of the first contact with a new technology. So we want to be able to address those emerging trends and really enable developers and data scientists to be more productive.
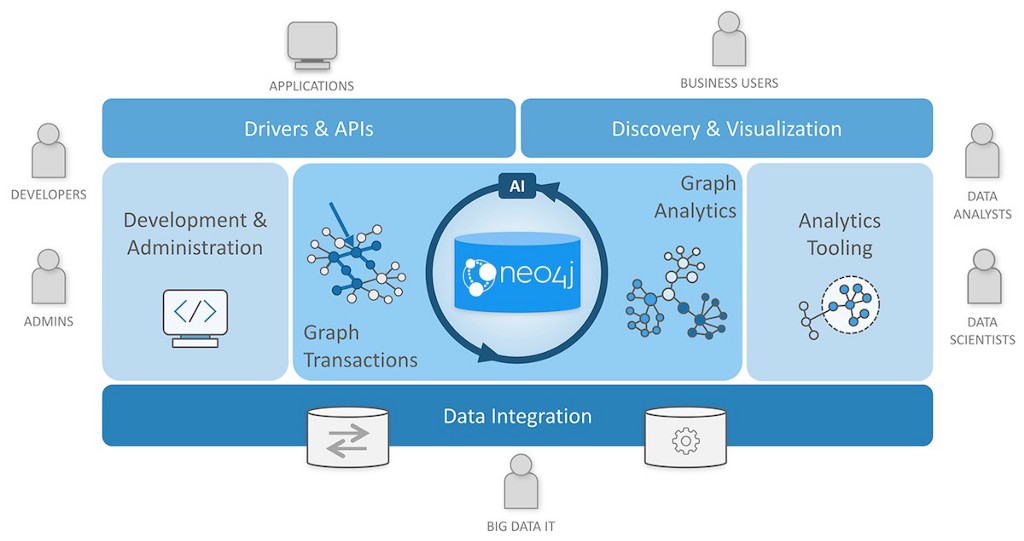
Components of the Neo4j Graph Data Platform, Neo4j Database, & Graph Native
So let’s look at the graph database platform. At the core is the Neo4j graph database, and surrounding it are some of the tooling, use cases, and audiences.
First, let’s have a look at how graph databases, and specifically Neo4j, are different from other databases such as relational, document, and so forth. One of the core differences, and advantages, of Neo4j is the property graph data model. All of the contact points are graph-based: the thinking, the modeling, the querying, and the storying. A graph database consists of entities called nodes, and the connections that join them together are called relationships. Importantly, the relationships are first-class citizen of the data model, and this is represented in how we store and query them in the database.
So speaking of storing and querying, we use a query language called Cypher to work with Neo4j. If you’re familiar with relational databases and SQL, you can think of Cypher as SQL for graphs, focused on pattern matching. It is a declarative query language that features ASCII art patterns. As Neo4j is optimized for traversing the graph, the query reflects this traveling from node to node by following relationships. You’ll often see queries describing patterns traversing many relationships, maybe 10–12 or even unspecified variable-length patterns. Neo4j does this through a concept called index-free adjacency. When moving from one node to the next, rather than doing an index lookup operation to do that traversal, the database will look up the pointer for the next hop, which computers are very good at.
The implication of this is that performance of traversals are not dependent on the overall size of the data. A local graph traversal going from one node following a chain of relationships is not dependent on the overall size of the graph, be it small or very large. Now, Compare this concept to a relational database, where the equivalent would be table joins. Indexes are used to see where two tables overlap to join them. This index-backed operation performance is based on the size of these two tables. As the tables grow, the performance is going to be impacted.
You’ll often hear the term “graph native,” and this is fundamentally what it means. It’s about optimizing all the way through the stack from the data model to the query language, and then exploring how that data is stored on disk and how the database processes it is optimized for graph and graph workload. So that’s what graph native means when you hear that term. The Neo4j database is also very extensible. You have the ability to write user-defined procedures, functions, and plugins to define a custom logic beyond Cypher. This also forms the basis for other interesting components within the graph platform, which we will cover later.
Neo4j Desktop, Using Neo4j in the Cloud, & On-Prem
We’ve briefly covered the Neo4j database, how it works, and the differences between it and more traditional databases. The next question is: how do we get the database up and running? How do we interact with it?
For many of you, your first touchpoint with Neo4j has probably came from a google search, and most likely you will have encountered the download Neo4j Desktop button. So what is Neo4j Desktop? It is mission control for your Neo4j projects — a developer tool that allows you to manage your Neo4j instances in a nice way. It allows you to manage remote and local database instances, as well as run graph apps. If you’re trying out Neo4j, you’re pulling together a proof of concept or just learning and having a play, then it also allows you to very easily get started without worrying too much about configuration, setting up Java, and so forth.
You can also set up the database up through a console window or as a service, with tools such as Neo4j Admin and other utilities to manage the product. You also have ways of getting different formats of your database, so if you’d like to use Docker, you can go and get a Docker container of Neo4j. We have got a Helm Chart as well, if you are looking at the Kubernetes route. You can also get Neo4j in various flavors and other packages, for example Linux and Windows. There are also monitoring tools such as Halin, which is one of our Neo4j Labs applications, which we’ll cover later.
Now, if that sounds like too much of a headache, we do have a cloud option available to you as well. Neo4j Aura is a scalable, resilient database as a service with three different flavors available. The professional tier is your more traditional cloud service — you sign up with a credit card, spin up a database, and away you go. If you need something that is a bit more dedicated to your enterprise, e.g. you want SLAs and other guarantees, there is an enterprise offering as well. Last but not least, Neo4j Aura Free tier is coming shortly, targeted at developers who are looking to learn, or have small projects they’d like to run in the cloud. Do sign up on the wait list!
Neo4j Browser & Low-Code Graph Apps
Regardless of how you have deployed a Neo4j, one of the first tools you’ll use to interact with Neo4j is called Neo4j Browser. Neo4j Browser runs in your web browser, and can be thought of as a query workbench for Neo4j. It allows you to execute Cypher queries against the database and then visualize and interprets the results. There are also various administration commands that can be executed within the Browser, but you can think of it as the starting point for writing CSV scripts for importing data and getting started.
Neo4j Browser is one of the tools that we call a graph app. Graph apps are single page applications that run in Neo4j Desktop. They have an additional API injected into the application that gives them access to the database currently running in Neo4j Desktop. Anyone can build a graph app to do similar operations against the database, and from this it is interesting to see what’s possible from a low-code tooling perspective. There are options to run these graph apps independently from Neo4j Desktop in a web browser, and still be able to connect to a database.
A great example of a low-code graph app is NEuler, the graph algorithms playground. NEuler gives you a no-code environment to explore, compose, and execute graph data science and graph algorithms on Neo4j. Using the Graph Data Science library, it allows you to try out the algorithms without being overwhelmed by pulling together the specific queries and necessary configuration.
Another graph app is GraphQL Architect. GraphQL Architect allows you to construct, develop, run, and query a GraphQL API locally or within the context of Neo4j Desktop. It allows you to export work once you’ve built out and tested your GraphQL API.
The Charts graph app allows you to do exactly as the name implies — create charts. Often the answer to our question, even when working with graph data, is a tabular result, and charts help us with the visual interpretation of that.
These are some of the graph apps that have been built by the Neo4j team, mostly from the Neo4j Labs program, which will be covered in more detail shortly. There are also great community-built graph apps, which you can check out from the graph apps gallery. Let’s highlight two of them.
GraphXR allows you to render 3D data visualizations, which allows you to explore your data in an almost VR-type environment. Neomaps allows you to visualize spatial data stored in Neo4j. For example, you may have spatial and geometric data in your database, and you can use Neomaps to represent them as points, line segments, or a polygon. You also have the option to build layers, where you can define what geometrics to represent on the map.
Neo4j Language Drivers & Building APIs
So we’ve reached the stage where we’ve got the database downloaded, installed, and running, and now we’re able to explore our data using either the Neo4j browser or one of the graph apps. Now it’s time to think about other ways to connect to and interact with the database. There are a number of ways to achieve this.
Neo4j Drivers
These are language drivers that allow you to communicate with the database. The official Neo4j drivers are available for JavaScript, Java, .NET, Python, and Go. They all work on the idea of a common abstraction — all of the drivers have similar phrasing around how to connect to the database. They all follow very similar patterns across all of them. The syntax you would use for the JavaScript driver would look very similar to the Java one, and so forth. They also operate on the idea of sessions — you create a session, run all the transactions you need against the database, and then close that session off.
There are also a large number of drivers that have been created by the wonderful Neo4j community. They are available in other languages such as R, PHP, Ruby, Julia, and you’ll also find community drivers for some of the officially supported languages as well, such as .NET. Most of these drivers run under the ‘Bolt Protocol’ — a system that manages how you connect to the database, and takes away the concern of figuring out which database to connect to if, for example, you’re running a cluster. For instance, the Bolt Protocol will deal with where to send your query if it’s a write query over a read query. There are also object graph mappers for Java, as well as Spring Data Neo4j, which is hugely popular and used in a lot of large companies.
GraphQL API
Another key option available to query the database is via the GraphQL API. This is an option that allows us to rapidly build an API layer between the database and a client. GraphQL is very interesting in the context of graph databases, because there’s a lot of symbiosis between it and the property graph database. One is that GraphQL makes the observation that your application data is a graph. So you can think of a GraphQL query as a traversal through this data graph, and specifying exactly the data from that traversal that should be returned. Also with GraphQL, we often build these very nested queries that are again a traversal through the data graph. Being able to have a graph database back-end like Neo4j that’s actually responsible for executing those traversals on a property graph means that those queries are going to be very efficient and optimized by the database engine.
Graph Data Science, Analytics, & Visualization
We’ve already talked about building applications, where as developers we need to build that API layer. But another key part of the graph data platform is more of the analytics use cases, where the users are more likely to be data scientists, analysts, or even maybe business users. Let’s explore the tooling in that space of the Neo4j platform.
One of the most interesting pieces of the platform is the Graph Data Science Library. The Graph Data Science Library allows you to run graph algorithms in Neo4j, such as centrality, page rank, and community detection algorithms to find communities or clusters in the group. And these also form the basis for more advanced techniques that feed into machine learning in our artificial intelligence pipelines.
Another really exciting element that we have sitting in this quadrant is Neo4j Bloom. Neo4j Bloom is another graph app which allows you to visualize and explore your data using near-natural language. What does this mean? If you have a good understanding of your data model and your domain, you don’t really need to know any Cypher to be able to go off and investigate your data. Bloom will investigate the data in your database, do some sampling, and build out a view based on elements such as labels and relationship types.
It has lots of flexibility around how it is interpreted — you can enter an approximation of the label or property that you’re looking for, and Bloom will find it for you, along with patterns, allowing you to visually explore your data. You can further customize your Bloom environment with icons, colors, and sizing. With common phrases, you can turn these into “search phrases,” which enables you to use the full power of Cypher for repeatable searches, with a friendly, parameterized command. All of these features together allow you to share the same perspective within a team or department, making it easy to discuss and explore discoveries and so forth.
What makes Bloom even more powerful is that it weds really well with graph data science, and you have the option to further tailor your perspective. So you can do things such as page rank, where you’re looking for influential nodes, and then dynamically size them based on their range of influence. You can display hierarchies — all these factors make Bloom a fantastic visual aid for the data scientist.
Neo4j Connectors & Neo4j Labs
Neo4j is part of a larger architecture that enables it to work with other technologies. This is where the Neo4j Connectors can be really helpful and come into play here.
The Neo4j Connector for Business Intelligence. This feature is designed to enable Neo4j to be used with business intelligence tooling, such as Tableau, Looker, etc. It works by generating SQL statements. So in Tableau you can go and configure a bar or line chart, and Tableau will generate SQL statements to fetch the data, which the connector then handles, rendering a chart.
The Neo4j Connector for Apache Spark. Apache Spark is the framework for distributed data processing. The Neo4j connector for Apache Spark allows us to read and write data to Neo4j from Spark jobs. This is especially useful where we have very, very large data sets that we’re performing some processing or some ETL process on, and we can do that in a distributed fashion to transform and then load that data into Neo4j.
The Neo4j Connector for Apache Kafka. Apache Kafka is a distributed event streaming platform. It has publishers that send events into channels, called topics. Systems looking to receive these events, called consumers, will subscribe to topics, and consume the events as they are published, performing some action as required — a common real-time based architecture pattern. The Neo4j connector for Apache Kafka allows the database to subscribe to topics and consume events, as well as publish events to a topic when changes happen to the database.
Let’s look at some Apache Kafka use cases. It can be really powerful when you combine graph data science with Kafka. Take fraud detection, for example. As data is coming into the system, an algorithm can inspect the data and flag suspicious transactions as fraudulent. You can then publish an event that goes out into Kafka, alerting the analytics team that can then dive into more detail. Real-time root cause analysis is also interesting, as well as real-time recommendations based on buying behaviors, current stock, etc. So any sort of streaming real-time process can take advantage of the Neo4j database + Apache Kafka combination.
Kafka has this concept of the stream table duality, which is a way of thinking about how streaming data and databases work together. Essentially any stream can be transformed into a table, and vice-versa. What the Neo4j connector for Apache Kafka does is extend this stream table duality into a trinity where graphs come into play. You can now also compose that stream as a graph, right? This helps thinking about streams as graphs as well as tables.
As well as connectors, there are other ways to interact with the database. All these components being discussed are sourced from Neo4j Labs. Neo4j Labs is where we explore experimental integrations, based on the latest and upcoming trends, what’s new in technology, and what is the associated graph story. Let’s have a look at some of the Neo4j Labs projects.
The APOC library (Awesome Procedures On Cypher) is the most popularly and widely used project in Labs. It has 400+ functions and procedures and does everything from data import, manipulation, text cleaning, and it even allows you to build your own custom Cypher procedures and functions.
Another very popular Labs project is the Neosemantics library. This allows you to convert all RDF (Resource Descriptive Framework) into property graphs and back again. RDFs are extraordinarily popular for ontologies. If you’re looking to validate your data against a model, or serialize your data, it’s a very powerful mechanism. There will be reasons why you want to keep it in that format, as well as reasons for wanting that data as a property graph. Neosemantics allows you to transfer back and forth as required.
The final Labs project we’ll cover is GRANDstack, which consists of GraphQL, React, Apollo, and the Neo4j database. It is for full stack developers who have a lot of different technologies to consider as they’re building their application. GRANDstack is a series of technologies that work well together. It’s helpful for full stack developers to understand how the pieces fit together and then also leverage some of the integrations between technologies into a powerful, full stack starting kit.
GRANDstack is for building applications leveraging the Neo4j GraphQL integration. React has some great tooling for using GraphQL as a data source. It made a lot of sense that Apollo is tooling both on the server and the client for building graphical APIs, as well as working with GraphQL data on the client. GRANDstack is the best in show of combination of these technologies with an opinionated way of how to get started with them together. The easiest way to get started with GRANDstack is to use the create-grandstack-app command line tool, which will generate a skeleton of a full stack application using all of these components together.
Closing Remarks
This has been a whirlwind tour of the history of Neo4j, as well as the platform itself. Hopefully it wasn’t too overwhelming, and you found this technology relevant or interesting to you.
If you want to get started in a gentle, guided environment, the Neo4j Sandbox is a great way to dip your toes in the water of the larger Neo4j Graph Data Platform. Sandbox allows you to spin up a Neo4j instance, preloaded with some data and guided Cypher queries to start working with and exploring data. There are different use cases to choose from, and you can also bring in your own personalized data, such as your Twitter network. Sandboxes also includes libraries like the Graph Data Science Library and some of those graph apps that we mentioned earlier as well.
If you get stuck during your learning journey, do check out our community forum. We have an amazing community of members who come and talk about their experiences, and you’ll find many of them eager to guide you as well. It’s also a great place to let us know if you’re working on something fun — we want to hear your graph story. What projects are you working on, what are you experimenting on, what fun thing have you learned? Please post it there, we’d love to hear about it!
Be sure to subscribe to GraphStuff.FM in your podcast app and give us a review on Apple Podcasts!
Overview of the Neo4j Graph Data Platform was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles





How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs
