Mapping
Mapping is the process of associating a table or file with an element in your data model. This is what allows Import to construct the Cypher statements needed to load your data.
When you generate a data model, the mapping is largely done for you. However, as you add elements to your model, whether you create a model manually or if you are adding to a generated model, the new elements need to be mapped to their corresponding tables or files.
Your data source may contain data that is not relevant to your data model, and when you build your model, you can select what data to use. Only data that is mapped correctly to the elements in your model is imported, so it is important to get the mapping right.
|
If you need to change the mapping, it is possible to run the import again. Affected elements already imported are updated and not duplicated. |
Nodes
To map a node to a file/table, the node needs to have a label, which you can type directly on the node or in the mapping details panel. After naming the label, you can select the file/table to map to the node. If you are streaming local files, you can add the file at any time before running the import, but it is convenient to do it at this stage.
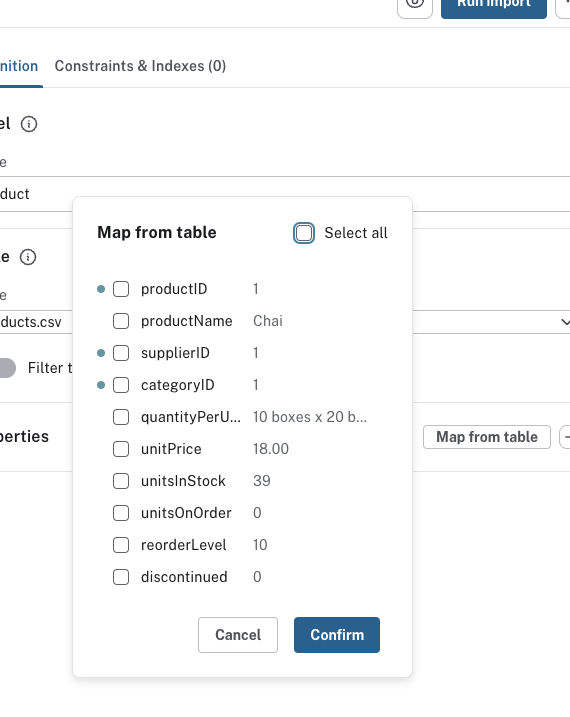
Additionally, the node needs to have at least one property and an ID.
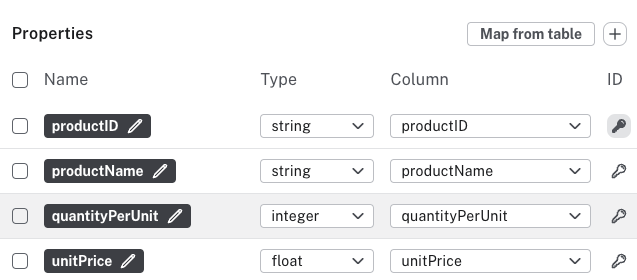
The properties are key-value pairs that describe the node.
The ID is used to uniquely identify nodes and when connecting nodes to each other in relationships. If a node with the same ID is seen more than once, it is only created for the first instance observed in the flat file. If a node with the same ID is seen again, any properties are updated, resulting in the most recently read properties being kept. As mentioned, the node ID is crucial when creating relationships and this is explained in further detail in the section on mapping relationships.
If you added the file already, you can choose to map properties from that file. Import derives the properties from the columns in the file and guesses the data type. With this option, you can select which properties to use. Once selected, you can rename the properties, change the data type, if needed, and select which property should serve as the node ID.
By default, Import uses the property with id in its name as the ID, but if none of the columns in the mapped file meet this condition, or if more than one does, you have to manually select which property to use as the node ID.
Whether you let Import select the ID or you do it manually, every node needs to have an ID in order to complete the mapping.
The property used as node ID is marked with a key icon.
Relationships
Much like how a node needs to have a label, a relationship needs to have a type. This can be typed directly on the relationship or in the details panel. The file to map the relationship to is selected in the same way as for nodes. Depending on your data, this file could be:
-
The same file as used for the nodes at both ends of the relationship. In this case, Import automatically maps the file and appropriate columns. It is easy for it to indentify the file columns to use in the From and To mapping, as they have already been mapped as ID properties to the nodes at each end.
-
A file that is used to define the node at only one end of the relationship, but also contains a column that contains the ID of the other node. In this case, you need to manually select the file and specify the From and To mapping manually. This is similar to a table in a relational database the contains a Foreign Key to link to another table, but here that key is used to link to another node rather than a table.
-
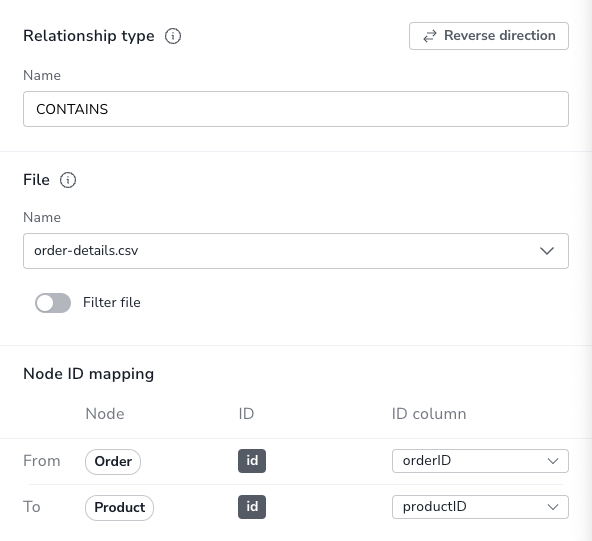
A completely separate file that is used solely to define the relationship. In this case, you need to select the relevant file and then map the columns in the file that correspond to the From and To node ID properties. This is similar to a link table in relational database terms.
This part is crucial to ensuring the relationships link nodes as indended. It is defined in the Node ID mapping section of the details panel.
File filtering
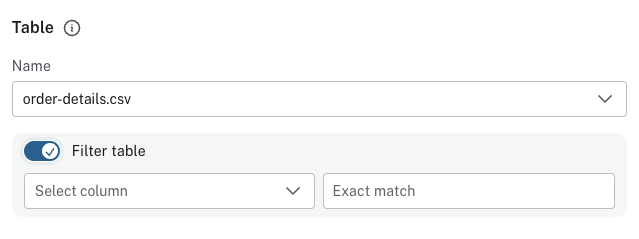
When mapping a file, both to nodes and relationships, you can use a toggle to filter the file. This is useful when using aggregate node lists and relationship lists as source files. Aggregate node lists contain all the nodes in the same file and they can be separated/grouped together by having the same value in a specific column. Aggregate relationship lists contain corresponding information about relationships in one file and the relationships can be grouped together in the same fashion. The file filtering allows you to select a column and an exact value to match and only the elements that match are used as a source for that element in your data model.
Node exclude list
Sometimes a source file may contain a column where multiple rows have the same string as the value, such as [empty] or null.
If this column is used as node ID, and you run the import, this results in the creation of "super nodes".
Every row in the mapped file that has such a value end up being connected to the same node, the "super node".
To avoid this, you can specify strings that should cause Import to exclude the rows they appear in.
By default, Import excludes any rows where the value of the node ID column is empty.
The node exclude list is available from the more menu (…) in the data model panel, under Settings.
Complete the mapping
If the mapping is not complete, ie. if any element in the model is missing the green checkmark, the import can’t be run. If you try, Import sends an error message and highlights which element(s) in the model is missing information and also which fields in the details panel need to be filled out.
For nodes, the following information is required:
-
Label - to identify the type of a node
-
File - the source file for the node from which the properties are derived
-
Properties - at least one property needs to be selected and if more than one, one needs to be selected as the node ID
For relationships:
-
Type - a name that describes the relationship it represents
-
File - the source file that contains information on which nodes are connected by the relationship
-
Node ID mapping - which nodes in the model are connected by the relationship; their labels, IDs and ID columns.
If the mapping is not complete, you can run a preview of the import, but it does not contain incompletely mapped elements.
Once every element in the model has a green checkmark to indicate complete mapping, the import can be run.