Overview of Importing Data into Neo4j
About this module
Assuming that you have gained experience with querying the graph, creating nodes and relationships, and creating indexes, you will learn about the various ways that you can import data into Neo4j.
At the end of this module, you will be able to:
-
Describe your options for importing data into Neo4j.
Overview
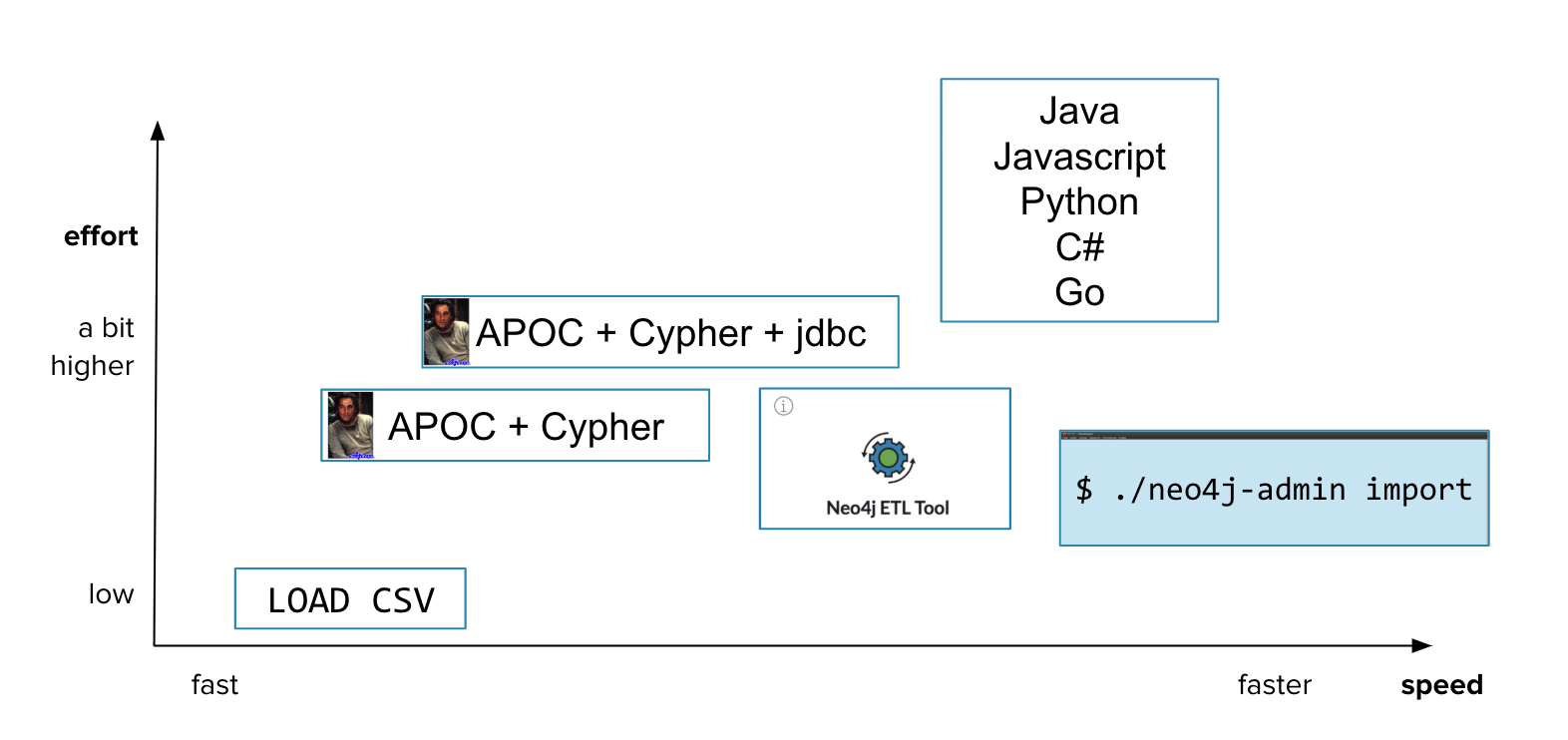
You have many options for importing data into Neo4j. Which option you choose depends on:
-
How much data you have.
-
What tools you are comfortable using.
-
How much time you have to perform the import.
Prepare for the import
Before you import data into the graph, you will have an idea of the target graph data model you want to achieve. You must work with the data architects for your application so that everybody agrees upon:
-
Names of entities (node labels).
-
Names of relationships.
-
Names of properties for nodes and relationships.
-
Constraints to be defined.
-
Indexes required.
-
The most important queries?
These graph data model components must be agreed upon before you import the data. You learn how to model your data in the course Graph Data Modeling for Neo4j
Using Cypher’s LOAD CSV for importing data
CSV is a common file type that an RDBMS can produce.
You extract the CSV data from the RDBMS, and using the graph data model, write Cypher code to perform the import.
Cypher has a LOAD CSV clause that you can use to read CSV data as rows and use the rows to create nodes and relationships in the graph.
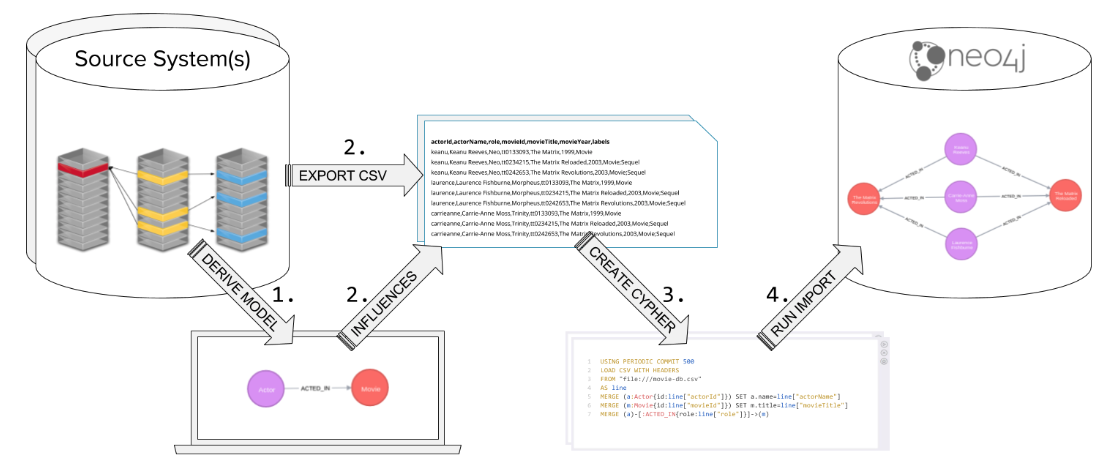
Using Cypher and LOAD CSV is one of the easiest methods for importing data.
It is commonly used for the initial import of data into the graph.
To perform this type of import, the Neo4j DBMS must be started.
With this type of import, the Cypher statement to load the data is a transaction.
If your database is part of a Cluster, all servers are automatically updated also.
Using APOC and Cypher for importing data
The APOC library is used by virtually all developers to reduce their programming effort. You can use many APOC procedures and functions for importing data into the graph. One thing that APOC handles very nicely is iteration and batching that may be required for importing complex and large amounts of data. In addition to CSV, APOC procedures can be used to read other formats such as XML, GraphML, and JSON.
Requirements for using APOC
-
CSV, XML, or JSON files that have been extracted from an RDBMS.
-
Neo4j Browser or Cypher-shell.
-
Neo4j DBMS running locally, in Neo4j Aura, in Neo4j Sandbox.
-
Optionally using a Neo4j Cluster.
-
No limit to size of data to import.
You can also use APOC’s jdbc connection features to access a live RDBMS. This type of connection is not covered in this course.
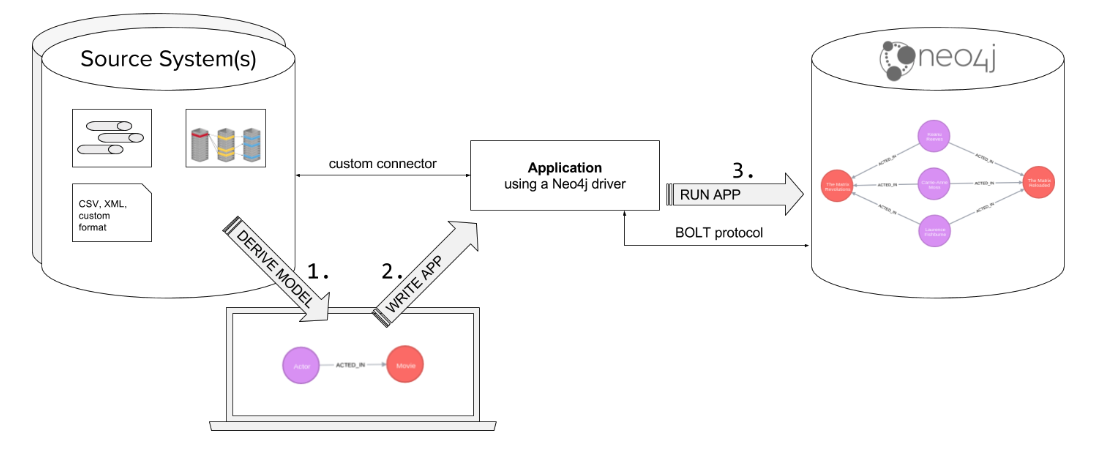
Using Drivers via Bolt
If you already have an application that accesses your RDBMS that is written in Java, Javascript, Python, C# or Go, you can use Neo4j’s supported drivers to add nodes and relationships to the graph. These languages enable you to write code that is transactional, supports batching, and even supports parallel operations. If you are comfortable with these languages, then you can use them to import the data into your graph.
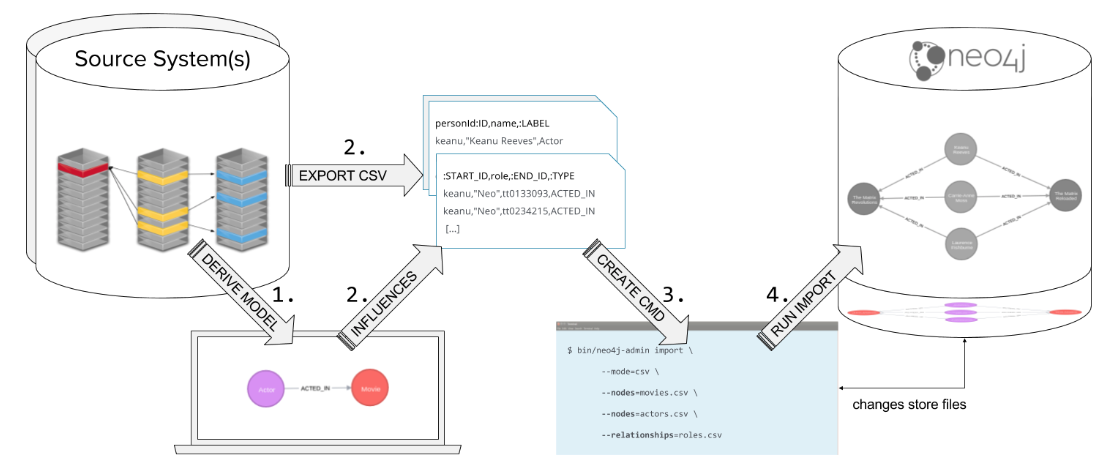
Using the neo4j-admin import tool
Another way that you can import data into a Neo4j Database is using the import tool that is part of the neo4j-admin tool.
With this type of import, the source data is in CSV format. The benefit of importing with this tool is that it is much faster than doing it with Cypher, APOC, or via a driver.
The database is created as part of the import and it is done "offline". That is, the database can only be started after the import has completed.
If your database will be part of a Cluster, then you will need to have each Cluster member "catch up" to the database that was newly imported.
Using the admin import tool is a very common way of performing an initial load of data into a graph. Then as the application evolves, the graph data model might change.
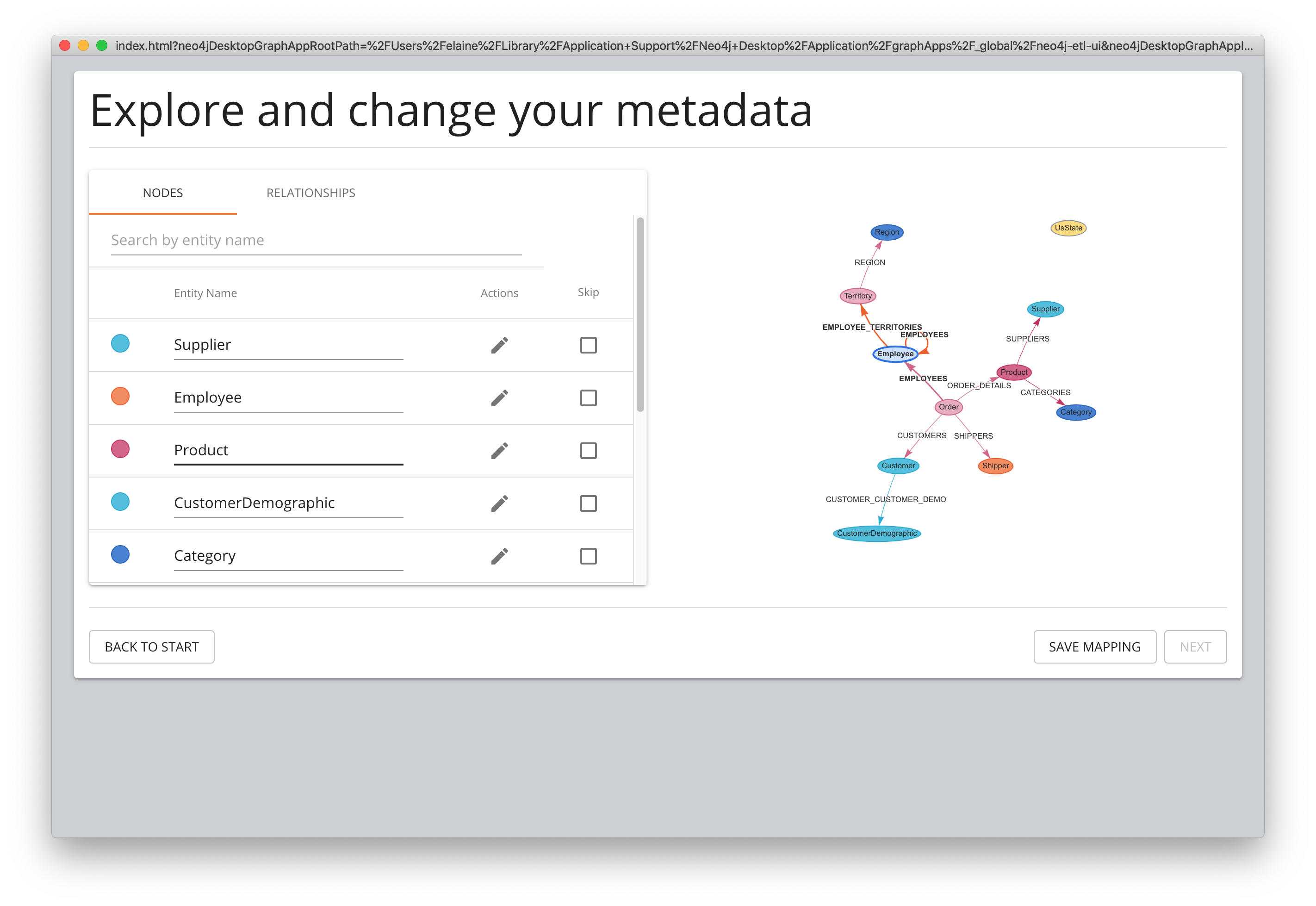
Using the ETL tool to import data
Neo4j Labs has created a tool (graph application) that you can use to import data using a live connection to an RDBMS. With this tool, you map tables/fields to nodes/properties to perform the import.
Using the ETL tool, although convenient, may not be suitable for all types of loading, especially if you want to implement a complex graph data model. That is, the ETL tool is a "generic" load tool.
Check your understanding
Question 1
Suppose you want to import data into a Neo4j Database from files that were created from an RDBMS. What format is required to load the data using existing Neo4j tooling?
Select the correct answers.
-
RDF
-
JSON
-
XML
-
CSV
Need help? Ask in the Neo4j Community