Using neo4j-admin Tool for Import
About this module
You have just learned how import data into the graph using Cypher together with APOC.
APOC provides you with more capabilities for import.
Another way that you can import data into the graph is with the administrative tool, neo4j-admin.
Next, you will learn how to use neo4j-admin to create a graph from CSV files.
You will be working with data for a much larger dataset representing crimes.
At the end of this module, you will be able to:
-
Import data from a set of CSV files using the
neo4j-admintool.
What is neo4j-admin?
neo4j-admin is a tool that can only be used if you are using Neo4j Desktop or Neo4j Server on a system that you manage. You cannot use neo4j-admin in a cloud-based Neo4j DBMS such as a Neo4j Sandbox or Neo4j Aura.
|
A Neo4j installation includes a bin folder that contains some useful utilities that can be used by both developers and administrators. These include:
-
neo4j, used for starting, stopping, and checking the status of the Neo4j instance.
-
cypher-shell, a command-line version of a Cypher interface that enables you to execute Cypher statements.
-
neo4j-admin, used for a number of administrative activities including creating a database from CSV files.
In this lesson, you will learn how to use the import feature of neo4j-admin.
You use neo4j-admin for import when you have extremely large amounts of data to import, for example greater than 10M nodes.
You will load data into a crimes database that is much larger than the databases you have been working with.
Preparing for import
Just as you became familiar with the content of CSV files when you imported them with Cypher, you must do the same with the CSV data you will be importing with neo4j-admin.
You must understand how headers relate to the data, what the field separator is, and make sure that the data is property formatted.
Unlike using Cypher to import the data, you don’t have the flexibility to transform the data during the import.
You must ensure that the data in the CSV files is clean and ready for import.
When using neo4j-admin for import, there are differences from importing with Cypher:
-
The database to be imported into must not exist as it will be created as part of the import.
-
The header information has additional information used for creating the nodes and relationships.
-
Node CSV files are structured differently from relationship CSV files.
-
All CSV files must use the same field separator.
-
You create the constraints (and indexes) after the import.
CSV files
The format of the CSV files is important:
-
For both nodes and relationships, header information must be associated with the data.
-
Header information contains an ID to uniquely identify the record, optional node labels or relationship types, and names for the properties representing the imported data.
-
A CSV can have a header row, or you can place the header information in a separate file.
CSV file for nodes: Beat
Here is portion of the beats.csv file with embedded header information for loading nodes of type Beat:
id:ID(beat-ref),:LABEL
1132,Beat
0813,Beat
0513,BeatThe beats.csv records represent data that will be loaded into a node with the label Beat. The id value is used to create the id property for the node. The ID(beat-ref) is used to store a reference to the node that is created so that it can be used later in the import.
CSV files for nodes: Crime
Here is an example of the crimes_header.csv header file for loading nodes of type Crime:
id:ID(crime-ref),:LABEL,date,descriptionAnd here is a portion of the associated crimes.csv file for loading nodes of type Crime:
8920441,Crime,12/07/2012 07:50:00 AM,AUTOMOBILE
4730813,Crime,05/09/2006 08:20:00 AM,POCKET-PICKING
7150780,Crime,09/28/2009 01:00:00 AM,CHILD ABANDONMENT
4556970,Crime,12/16/2005 08:39:24 PM,POSS: CANNABIS 30GMS OR LESS
9442492,Crime,12/28/2013 12:15:00 PM,OVER $500The id value is used to create the id property for the node. The label for the node will be Crime. The date and description values are used to create the respective properties for each node. The ID(crime-ref) is used to store a reference to the node that is created so that it can be used later in the import.
CSV file for nodes: PrimaryType
Here is a portion of the primaryTypes.csv file for loading these nodes:
id:ID(primarytype-ref)
ARSON
OBSCENITY
ROBBERY
THEFT
CRIM SEXUAL ASSAULT
BURGLARYThe id value is used to create the id property for the node. The label to be used for creating the node is not specified in the header or the data so it will need to be specified in our argument to perform the import.
CSV files for relationships
CSV files for loading relationships contain a row for every relationship where the ID for the starting and ending node is specified, as well as the relationship type.
Here is a portion of the crimesBeats.csv file that will be used to create the :ON_BEAT relationships between Crime and Beat nodes:
:START_ID(crime-ref),:END_ID(beat-ref),:TYPE
6978096,0911,ON_BEAT
3170923,2511,ON_BEAT
3073515,1012,ON_BEAT
8157905,0113,ON_BEATWhen the import tool processes this file, it has already saved references to the Crime and Beat nodes previously created. We specify the relationship to be created between the Crime and Beat nodes using the :TYPE column, in this case, ON_BEAT.
Here is a portion of a portion of the crimesPrimaryTypes.csv file that will be used to create the relationships between the Crime nodes and the nodes that contain the CrimeType data:
:START_ID(crime-ref),:END_ID(primarytype-ref)
5221115,NARCOTICS
4522835,DECEPTIVE PRACTICE
3432518,BATTERY
6439993,CRIMINAL TRESPASSWhen the import tool processes this file, it has already saved references to the Crime and PrimaryType nodes previously created. There is no relationship specified in the data so we need to specify it in our argument when we import the data.
The relationship, :TYPE is not specified in this file so it will be specified in the arguments when you load the data from this file.
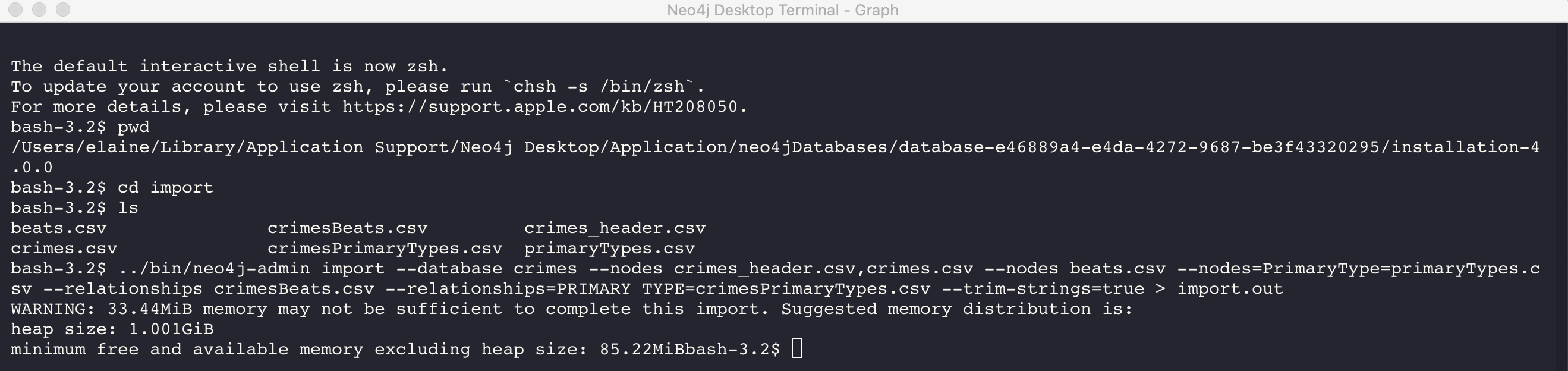
Importing the data
After you have created or obtained the CSV files for the data, you import the data. The data import creates a database so the database you specify must either be empty or will not exist.
Here is the simplified syntax for creating a database from CSV files:
neo4j-admin import
--database <database-name>
--nodes [<rheader-csv-file-1>,]<csv-file-1>
--nodes=<Label>=[<rheader-csv-file-2>,]<csv-file-2>
--relationships [<jheader-csv-file-1>,]<join-csv-file-1>
--relationships=<REL_TYPE>=[<jheader-csv-file-2>,]<join-csv-file-2>
--trim-strings=true
> import.outThis simplified syntax shows examples of specifying the Label for a node CSV file as well as a relationship type for a relationship CSV file In most cases, you will want to use the trim-strings argument to ensure that leading or trailing spaces are not included in the data imported.
| You must not have a space after the "," when specifying a header file with the CSV file. |
You can refer to the documentation for details for using the import tool. Note that it is possible to specify regular expressions for the files specified when you import.
Exercise: Importing data with the import command of neo4j-admin
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 18.
| This exercise has 5 steps. Estimated time to complete: 15 minutes. |
Check your understanding
Question 1
Before you will import data using neo4j-admin, what is one thing you must do?
Select the correct answer.
-
Create the database.
-
Ensure the database does not exist.
-
Create the constraints in the database.
-
Create the indexes in the database.
Question 2
Suppose that part of the import command that you issue to neo4j-admin looks like this:
--nodes products_header.csv,products.csv
For this part of the import, where does the import process get information about the node labels?
Select the correct answers.
-
The products_header.csv file must have a field, USE_LABEL.
-
The products_header.csv file must have a field, :LABEL.
-
The products.csv file must have the label name in the corresponding USE_LABEL column.
-
The products.csv file must have the label name in corresponding the :LABEL column.
Need help? Ask in the Neo4j Community