Using APOC for Import
About this module
You have just learned how import data into the graph using Cypher’s LOAD CSV clause.
This is one of the easiest ways to import data, but it has its limitations.
Next, you will learn how you can use some of the APOC procedures to help you import data into the graph.
At the end of this module, you will be able to:
-
Ensure the APOC library is available.
-
Clear a graph of constraints, indexes, nodes, and relationships using APOC.
-
Perform conditional processing with APOC during import.
-
Use APOC for importing a CSV file.
-
Use APOC for importing a JSON file.
| Because the code examples in this lesson modify the database, it is recommended that you do not execute them against your database as you will be doing so in the hands-on exercises. |
Installing APOC for use with your graph(s)
If you are using a Neo4j Sandbox or Neo4j Aura, your database already has access to the APOC library. If you are using Neo4j Desktop, you must add the APOC library to your database server you are using.
Here are the steps for adding the APOC library to your database server in Neo4j Desktop:
-
Open the details for DBMS you are working with, by clicking the DBMS.
-
Select the Plugins tab.
-
Select APOC to install.
-
The DBMS will automatically restart.
Using APOC to clear the graph
When you are developing code to import data, you may have several attempts to perform the import correctly. Rather than creating a new database for each attempt, you can completely clear the database of all constraints, indexes, nodes, and relationships.
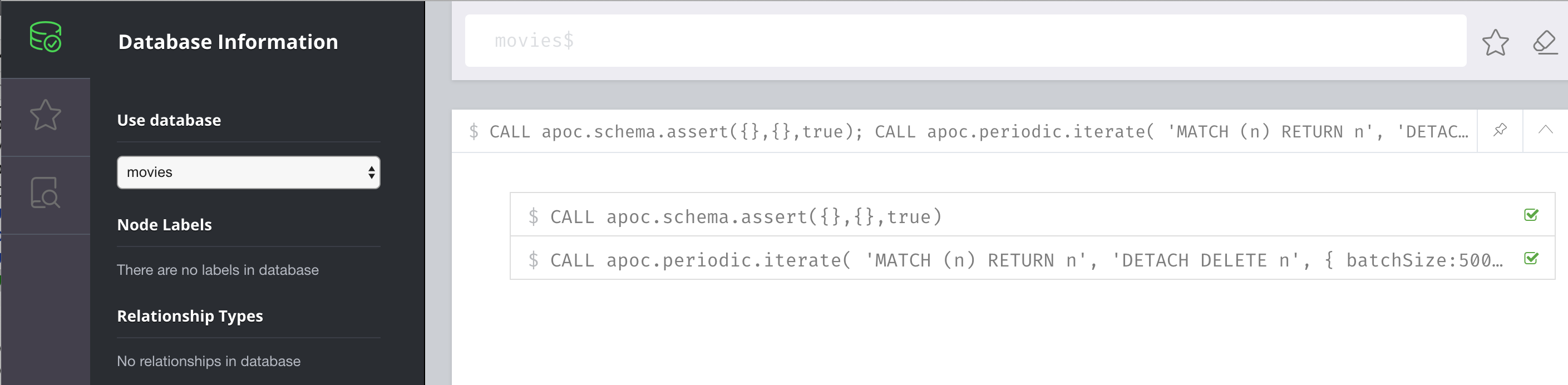
Here is one way that you can clear the database:
// Delete all constraints and indexes
CALL apoc.schema.assert({},{},true);
// Delete all nodes and relationships
CALL apoc.periodic.iterate(
'MATCH (n) RETURN n',
'DETACH DELETE n',
{ batchSize:500 }
)
In Neo4j 4.x, another way that you can clear the graph in Neo4j Browser is to use the system database and then type CREATE OR REPLACE DATABASE <database-name>.
|
Using APOC during import
One benefit of using APOC for loading data into the graph is that it can sometimes be faster than LOAD CSV.
In addition, APOC has some procedures that are helpful during the load, one of which is to control conditional processing.
And as you have already learned, with APOC, you can load large datasets that will fail if using LOAD CSV or even :auto USING PERIODIC COMMIT LOAD CSV.
Just as you inspect the data, determine if data needs to be transformed, and create uniqueness constraints before the import with LOAD CSV,
you must do the same when using APOC for the import.
Here is an example of the various types of loading procedures you can use in APOC:
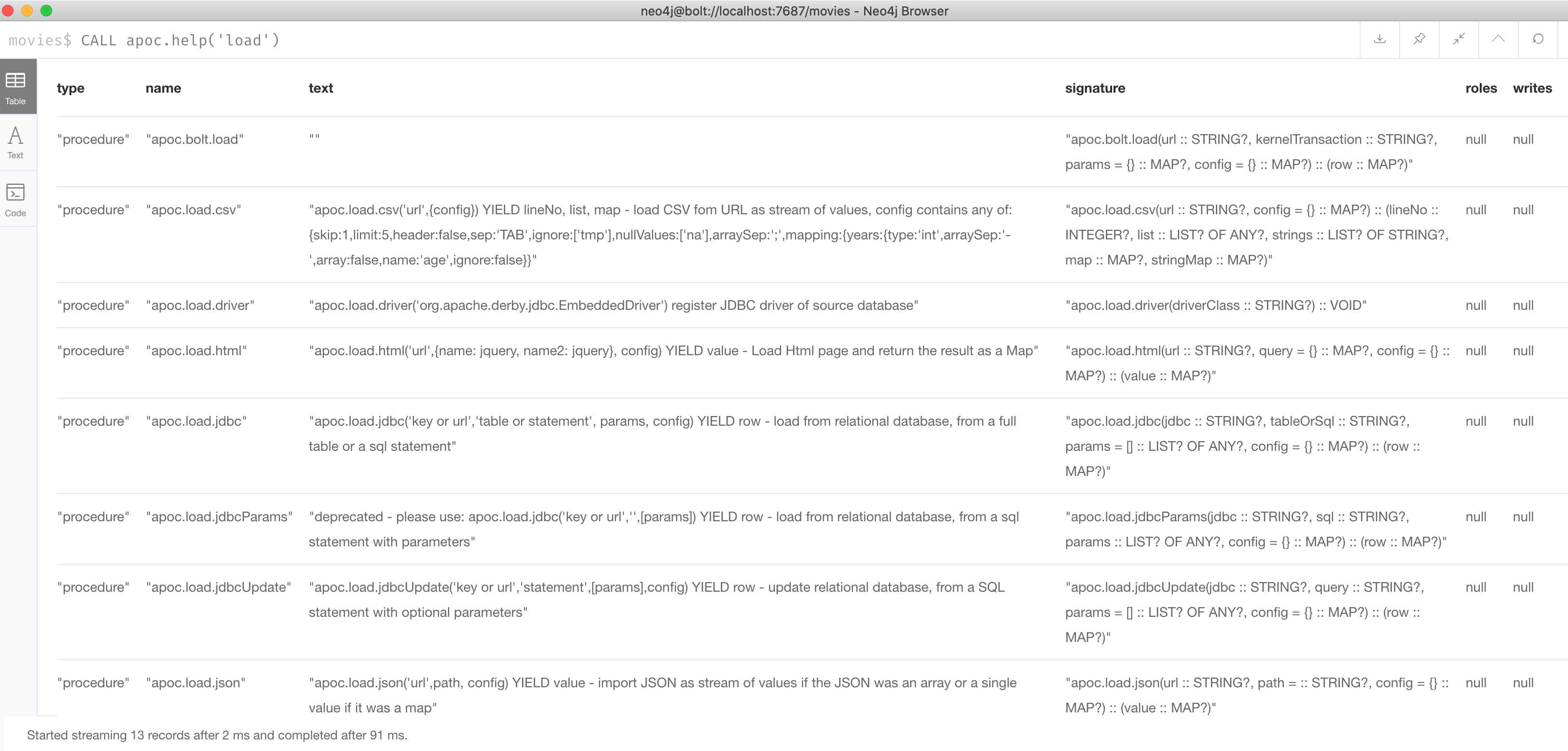
Using APOC for conditional processing
In the previous lesson, we used LOAD CSV to load Movie and Person data into the graph and then use the additional CSV files to create the relationships between the nodes.
Those files represented normalized data where each file basically represents a relational table.
If you want to load denormalized data from a CSV file, you face a couple of challenges. Just as a reminder, here is a snippet of a denormalized CSV file:

To load this data into the graph you could:
// Make a pass through the file to load the Movie nodes.
// Make a pass through the file to load the Person nodes.
// Make a pass through the file to create relationships based upon the personType field.Better alternative for conditional processing with APOC
If the CSV files are large, making multiple passes might not be ideal if you have load time constraints. A better option might be to:
-
Make a pass through the file to load the Movie nodes, collect the person data and then add the Person nodes from the collection.
-
Use the person data to create relationships based upon the personType field.
Import nodes, then create relationships
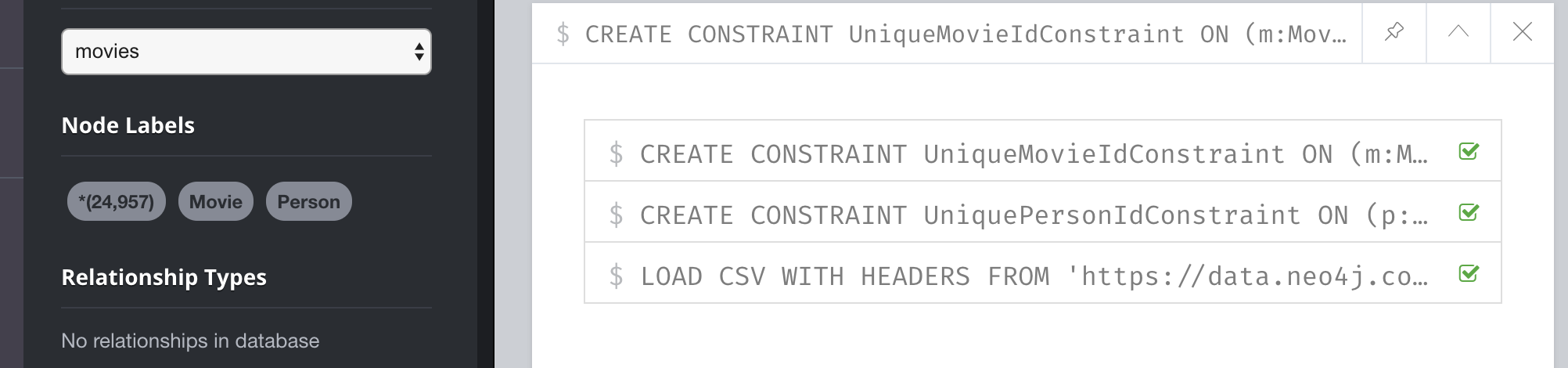
Assuming that we will use the second option for importing the data and we have created the uniqueness constraints as before, here is the Cypher code to create the Person and Movie nodes:
CREATE CONSTRAINT UniqueMovieIdConstraint ON (m:Movie) ASSERT m.id IS UNIQUE;
CREATE CONSTRAINT UniquePersonIdConstraint ON (p:Person) ASSERT p.id IS UNIQUE;
// import the people and movie data (partial; no relationships)
LOAD CSV WITH HEADERS FROM
'https://data.neo4j.com/v4.0-intro-neo4j/movies2.csv' AS row
WITH row.movieId as movieId, row.title AS title, row.genres AS genres,
toInteger(row.releaseYear) AS releaseYear, toFloat(row.avgVote) AS avgVote,
collect({id: row.personId, name:row.name, born: toInteger(row.birthYear),
died: toInteger(row.deathYear),personType: row.personType,
roles: split(coalesce(row.characters,""),':')}) AS personData
MERGE (m:Movie {id:movieId})
ON CREATE SET m.title=title, m.avgVote=avgVote,
m.releaseYear=releaseYear, m.genres=split(genres,":")
WITH *
UNWIND personData AS person
MERGE (p:Person {id: person.id})
ON CREATE SET p.name = person.name, p.born = person.born, p.died = person.diedThis code reads the data from a row and creates the personData collection that holds the data for a person.
It creates the Movie nodes based upon the row data.
With the WITH * clause, all variables are carried forward in the query.
Then the personData collection is unwound so that each element in a row can be used to create the Person nodes.
Everything is in the graph, except for the relationships.
This is not quite what we want because we have not created the relationships. That is, the type of relationship created depends on the value of the personType field in each row of the CSV file. This is where APOC can help you. APOC has a procedure that will allow you to perform conditional execution, based upon a value.
Example: Using APOC for conditional processing
Here is the complete code that utilizes the apoc.do.when() procedure, assuming that we have cleared the data from the graph first, but the constraints are still defined.:
LOAD CSV WITH HEADERS FROM
'https://data.neo4j.com/v4.0-intro-neo4j/movies2.csv' AS row
WITH row.movieId as movieId, row.title AS title, row.genres AS genres,
toInteger(row.releaseYear) AS releaseYear, toFloat(row.avgVote) AS avgVote,
collect({id: row.personId, name:row.name, born: toInteger(row.birthYear),
died: toInteger(row.deathYear),personType: row.personType,
roles: split(coalesce(row.characters,""),':')}) AS people
MERGE (m:Movie {id:movieId})
ON CREATE SET m.title=title, m.avgVote=avgVote,
m.releaseYear=releaseYear, m.genres=split(genres,":")
WITH *
UNWIND people AS person
MERGE (p:Person {id: person.id})
ON CREATE SET p.name = person.name, p.born = person.born, p.died = person.died
// continue processing and use the personType to create the relationships
WITH m, person, p
CALL apoc.do.when(person.personType = 'ACTOR',
"MERGE (p)-[:ACTED_IN {roles: person.roles}]->(m)
ON CREATE SET p:Actor",
"MERGE (p)-[:DIRECTED]->(m)
ON CREATE SET p:Director",
{m:m, p:p, person:person}) YIELD value
RETURN count(*) // cannot end query with this type of APOC callAfter the Movie and Person nodes are created, we use the reference to them to create the relationships between them.
The first argument to apoc.do.when() is the data that is tested.
The second argument is the Cypher code to execute if the test returns true.
The third argument is the Cypher code to execute if the test returns false.
The last argument is the object that describes the mapping of variables both outside of the call and inside the call.
For simplicity, we specify the same values.
Certain apoc calls cannot end a Cypher query so we place a RETURN count(*) at the end.
Here is the result:
Using APOC to import from CSV
If you cannot load the CSV file with LOAD CSV or :auto USING PERIODIC COMMIT LOAD CSV, another option is to use APOC for the import.
Previously, you learned how to clear the data from the graph using apoc.periodic.iterate().
You use this procedure to load large datasets.
Here is an example with an empty database, but with the constraints defined for the Person.id and Movie.id properties:
CALL apoc.periodic.iterate(
"CALL apoc.load.csv('https://data.neo4j.com/v4.0-intro-neo4j/movies2.csv' )
YIELD map AS row RETURN row",
"WITH row.movieId as movieId, row.title AS title, row.genres AS genres,
toInteger(row.releaseYear) AS releaseYear, toFloat(row.avgVote) AS avgVote,
collect({id: row.personId, name:row.name, born: toInteger(row.birthYear),
died: toInteger(row.deathYear),personType: row.personType,
roles: split(coalesce(row.characters,''),':')}) AS people
MERGE (m:Movie {id:movieId})
ON CREATE SET m.title=title, m.avgVote=avgVote,
m.releaseYear=releaseYear, m.genres=split(genres,':')
WITH *
UNWIND people AS person
MERGE (p:Person {id: person.id})
ON CREATE SET p.name = person.name, p.born = person.born, p.died = person.died
WITH m, person, p
CALL apoc.do.when(person.personType = 'ACTOR',
'MERGE (p)-[:ACTED_IN {roles: person.roles}]->(m)
ON CREATE SET p:Actor',
'MERGE (p)-[:DIRECTED]->(m)
ON CREATE SET p:Director',
{m:m, p:p, person:person}) YIELD value AS value
RETURN count(*) ",
{batchSize: 500}
)The first argument to apoc.periodic.iterate() is the call to apoc.load.csv() where we provide the file name and it returns a row.
The second argument is the same Cypher code you saw earlier.
The only thing that is different is that you must ensure that the code is in double quotes and the Cypher code does not use double-quotes (or visa versa).
The final argument is the size of the batch, 500.
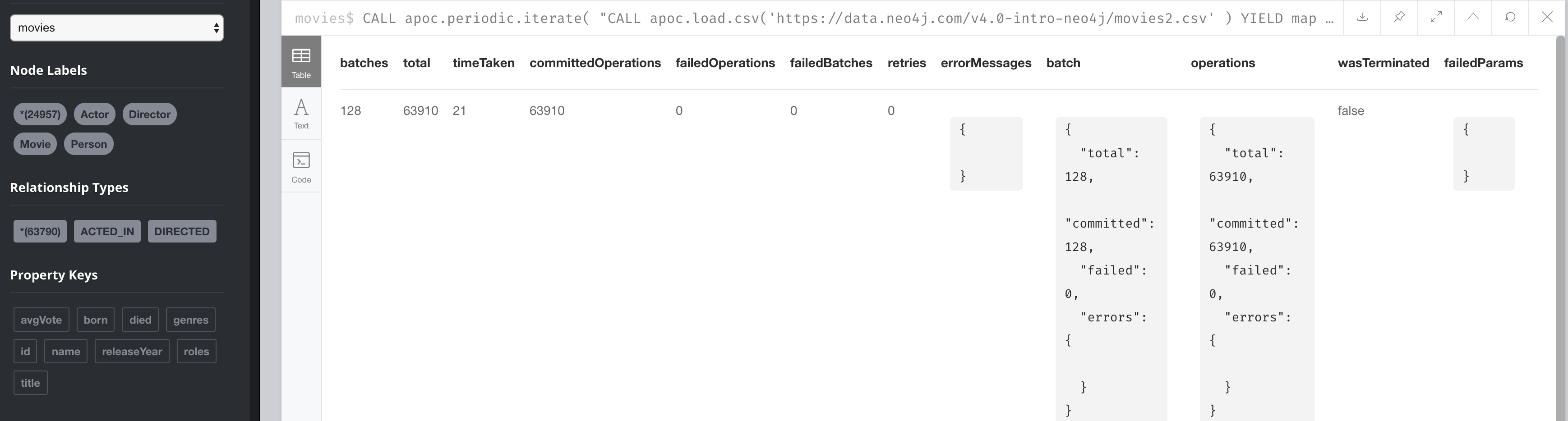
Using APOC to load JSON
JSON is another data format you might need to import into a graph. There are many data sources out there that can provide data in JSON format. For this course, we will use the StackOverflow data. Your first step is to become familiar with the data that you want to load into the graph.
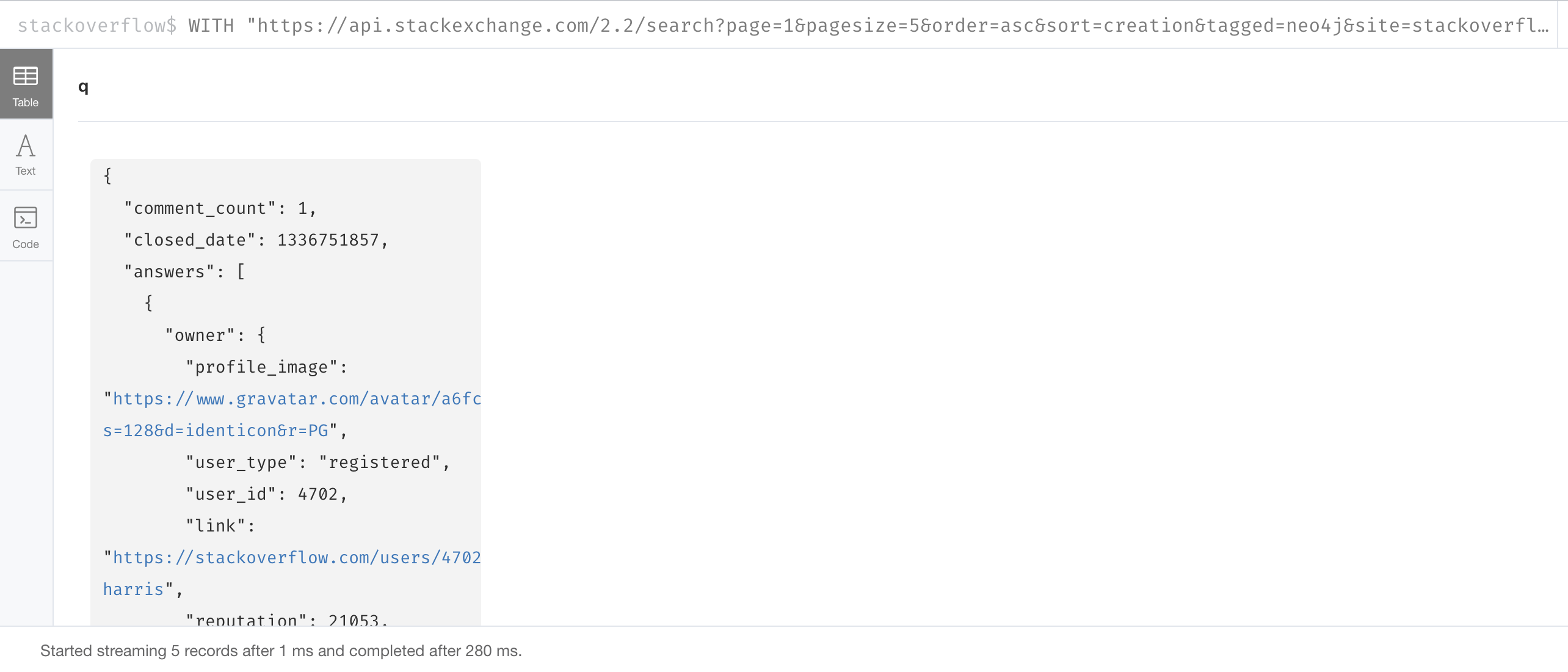
In this example we call apoc.load.json to return 10 questions from StackOverflow so we can view them:
WITH "https://api.stackexchange.com/2.2/search?page=1&pagesize=5&order=asc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS uri
CALL apoc.load.json(uri)
YIELD value AS data
UNWIND data.items as q
RETURN qWe specify pagesize, 5 in the URI. This retrieves 5 questions.
We then UNWIND the data and return each question, q.
Here is the result:
Viewing keys in the JSON data
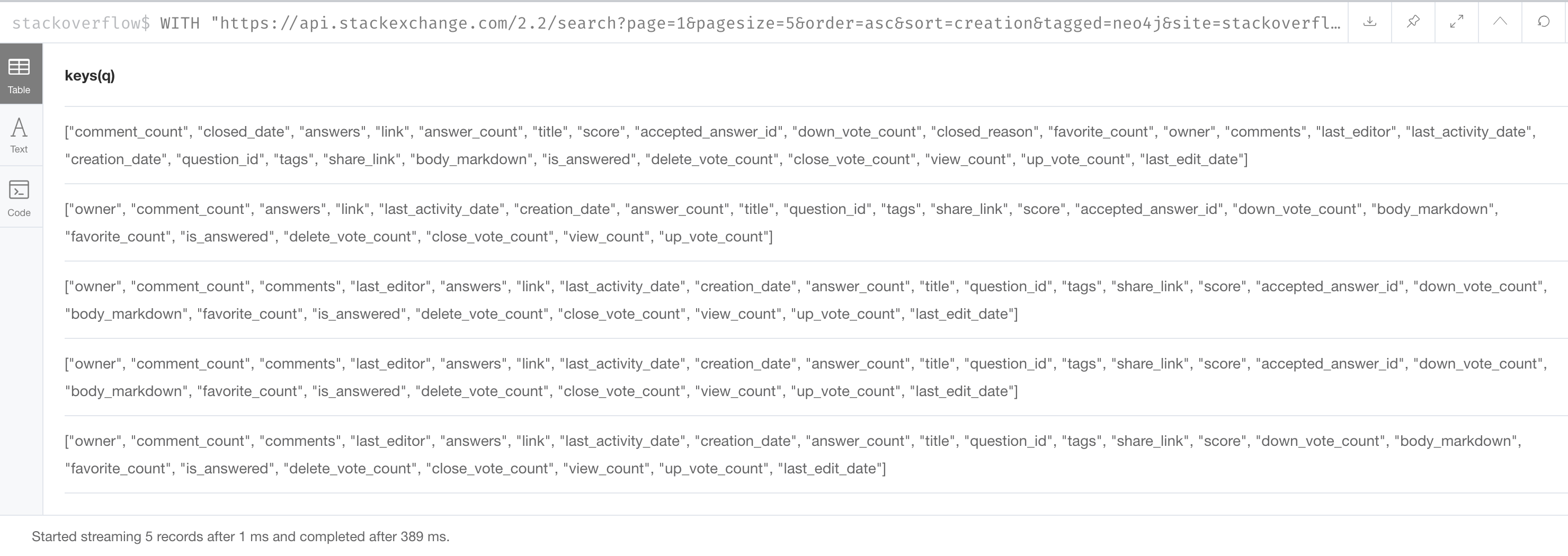
To help you understand the types of data available for each question, you can return the keys for each row:
WITH "https://api.stackexchange.com/2.2/search?page=1&pagesize=5&order=asc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS uri
CALL apoc.load.json(uri)
YIELD value AS data
UNWIND data.items as q
RETURN keys(q)We specify pagesize, 5 in the URI. This retrieves 5 questions.
We then UNWIND the data and return each question, q.
Here is the result:
Viewing data that will be loaded
Next, you must determine what data from the JSON file you will use to create the graph.
Here we have made a selection for the data we want to create in the graph and we write the code to return it:
WITH "https://api.stackexchange.com/2.2/search?page=1&pagesize=5&order=asc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS uri
CALL apoc.load.json(uri)
YIELD value AS data
UNWIND data.items as q
RETURN q.question_id, q.title, q.tags, q.is_answered, q.owner.display_nameHere is the result:
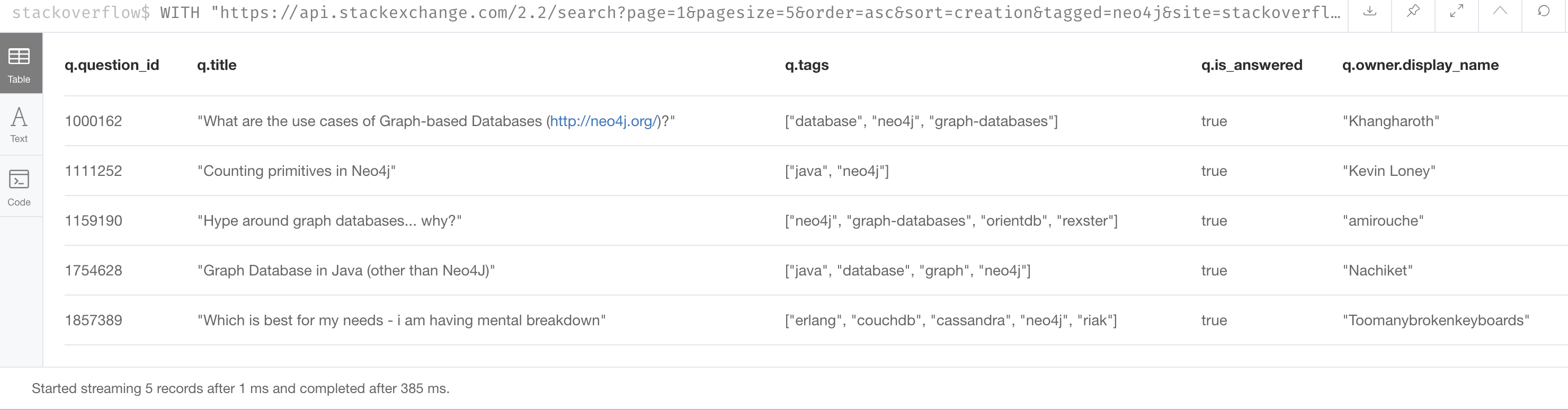
Creating the graph from JSON
We will use all values, except owner.display_name to create a Question node. We will use owner.display_name to create the User nodes. Here is the code to create the graph:
WITH "https://api.stackexchange.com/2.2/search?page=1&pagesize=5&order=asc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS uri
CALL apoc.load.json(uri)
YIELD value AS data
UNWIND data.items as q
MERGE (question:Question {id: q.question_id})
ON CREATE SET question.title = q.title,
question.tags = q.tags,
question.is_answered = q.is_answered
MERGE (user:User {name: q.owner.display_name})
MERGE (user)-[:POSTED]->(question)Here is the result of querying the nodes in the graph after the load:
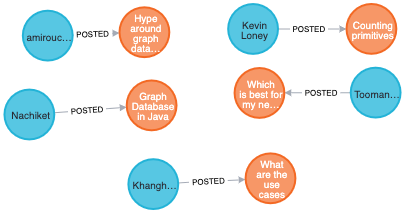
If you were to load thousands or more questions, you must ensure that you have created uniqueness constraints on Question.question_id and User.name before you attempt the load.
Exercise: Using APOC for importing data
In the query edit pane of Neo4j Browser, execute the browser command:
:play 4.0-intro-neo4j-exercises
and follow the instructions for Exercise 17.
| This exercise has 6 steps. Estimated time to complete: 15 minutes. |
Check your understanding
Question 1
What APOC procedure can you use to batch transactions when a lot of data needs to be processed?
Select the correct answer.
-
apoc.batch() -
apoc.transaction.batch() -
apoc.iterate() -
apoc.periodic.iterate()
Question 2
The procedure apoc.do.when() is used for:
Select the correct answers.
-
Scheduling when a load will occur.
-
Executing Cypher code when a condition is true and alternate Cypher code when the condition is false.
-
An alternative to the
MERGEclause. -
Understanding how many operations occurred during the execution.
Summary
You can now:
-
Ensure the APOC library is available.
-
Clear a graph of constraints, indexes, nodes, and relationships using APOC.
-
Perform conditional processing with APOC during import.
-
Use APOC for importing a CSV file.
-
Use APOC for importing a JSON file.
Need help? Ask in the Neo4j Community