apoc.export.csv.all
Procedure APOC Core
apoc.export.csv.all(file,config) - exports whole database as csv to the provided file
Signature
apoc.export.csv.all(file :: STRING?, config :: MAP?) :: (file :: STRING?, source :: STRING?, format :: STRING?, nodes :: INTEGER?, relationships :: INTEGER?, properties :: INTEGER?, time :: INTEGER?, rows :: INTEGER?, batchSize :: INTEGER?, batches :: INTEGER?, done :: BOOLEAN?, data :: STRING?)Output parameters
| Name | Type |
|---|---|
file |
STRING? |
source |
STRING? |
format |
STRING? |
nodes |
INTEGER? |
relationships |
INTEGER? |
properties |
INTEGER? |
time |
INTEGER? |
rows |
INTEGER? |
batchSize |
INTEGER? |
batches |
INTEGER? |
done |
BOOLEAN? |
data |
STRING? |
Usage Examples
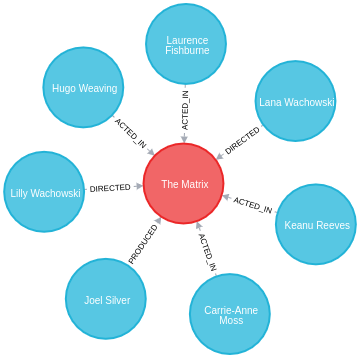
The examples in this section are based on the following sample graph:
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
(JoelS)-[:PRODUCED]->(TheMatrix);The Neo4j Browser visualization below shows the imported graph:
The apoc.export.csv.all procedure exports the whole database to a CSV file or as a stream.
The following query exports the whole database to the file movies.csv:
CALL apoc.export.csv.all("movies.csv", {})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies.csv" |
"database: nodes(8), rels(7)" |
"csv" |
8 |
7 |
21 |
39 |
15 |
20000 |
1 |
TRUE |
NULL |
The contents of movies.csv are shown below:
"_id","_labels","born","name","released","tagline","title","_start","_end","_type","roles"
"188",":Movie","","","1999","Welcome to the Real World","The Matrix",,,,
"189",":Person","1964","Keanu Reeves","","","",,,,
"190",":Person","1967","Carrie-Anne Moss","","","",,,,
"191",":Person","1961","Laurence Fishburne","","","",,,,
"192",":Person","1960","Hugo Weaving","","","",,,,
"193",":Person","1967","Lilly Wachowski","","","",,,,
"194",":Person","1965","Lana Wachowski","","","",,,,
"195",":Person","1952","Joel Silver","","","",,,,
,,,,,,,"189","188","ACTED_IN","[""Neo""]"
,,,,,,,"190","188","ACTED_IN","[""Trinity""]"
,,,,,,,"191","188","ACTED_IN","[""Morpheus""]"
,,,,,,,"192","188","ACTED_IN","[""Agent Smith""]"
,,,,,,,"193","188","DIRECTED",""
,,,,,,,"194","188","DIRECTED",""
,,,,,,,"195","188","PRODUCED",""The following query returns a stream of the whole database in the data column:
CALL apoc.export.csv.all(null, {stream:true})
YIELD file, nodes, relationships, properties, data
RETURN file, nodes, relationships, properties, data| file | nodes | relationships | properties | data |
|---|---|---|---|---|
NULL |
8 |
7 |
21 |
"\"_id\",\"_labels\",\"born\",\"name\",\"released\",\"tagline\",\"title\",\"_start\",\"_end\",\"_type\",\"roles\" \"188\",\":Movie\",\"\",\"\",\"1999\",\"Welcome to the Real World\",\"The Matrix\",,,, \"189\",\":Person\",\"1964\",\"Keanu Reeves\",\"\",\"\",\"\",,,, \"190\",\":Person\",\"1967\",\"Carrie-Anne Moss\",\"\",\"\",\"\",,,, \"191\",\":Person\",\"1961\",\"Laurence Fishburne\",\"\",\"\",\"\",,,, \"192\",\":Person\",\"1960\",\"Hugo Weaving\",\"\",\"\",\"\",,,, \"193\",\":Person\",\"1967\",\"Lilly Wachowski\",\"\",\"\",\"\",,,, \"194\",\":Person\",\"1965\",\"Lana Wachowski\",\"\",\"\",\"\",,,, \"195\",\":Person\",\"1952\",\"Joel Silver\",\"\",\"\",\"\",,,, ,,,,,,,\"189\",\"188\",\"ACTED_IN\",\"[\"\"Neo\"\"]\" ,,,,,,,\"190\",\"188\",\"ACTED_IN\",\"[\"\"Trinity\"\"]\" ,,,,,,,\"191\",\"188\",\"ACTED_IN\",\"[\"\"Morpheus\"\"]\" ,,,,,,,\"192\",\"188\",\"ACTED_IN\",\"[\"\"Agent Smith\"\"]\" ,,,,,,,\"193\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"194\",\"188\",\"DIRECTED\",\"\" ,,,,,,,\"195\",\"188\",\"PRODUCED\",\"\" " |
You can use the configuration sampling (default: false).
With this config, the apoc.export.csv.all procedure uses
the apoc.meta.nodeTypeProperties and the apoc.meta.relTypeProperties procedures under the hood to get the property types.
You can customize the configuration of these 2 apoc.meta.* procedure, using the samplingConfig: MAP configuration,
to limit the number of nodes/rels to analyze.
So you can execute with the following data set:
CREATE (:User:Sample {`last:Name`:'Galilei'}), (:User:Sample {address:'Universe'}),
(:User:Sample {foo:'bar'})-[:KNOWS {one: 'two', three: 'four'}]->(:User:Sample {baz:'baa', foo: true})Combined with the following query:
CALL apoc.export.csv.all('movies.csv', {sampling: true, samplingConfig: {sample: 1}})| file | source | format | nodes | relationships | properties | time | rows | batchSize | batches | done | data |
|---|---|---|---|---|---|---|---|---|---|---|---|
"movies.csv" |
"database: nodes(4), rels(1)" |
"csv" |
4 |
1 |
3 |
4 |
5 |
20000 |
1 |
TRUE |
NULL |
Execution of the above query would output content similar to that below (result could change depending on the sample):
"_id","_labels","baz","foo","_start","_end","_type"
"0",":Sample:User","","",,,
"1",":Sample:User","","",,,
"2",":Sample:User","","bar",,,
"3",":Sample:User","baa","true",,,
,,,,"2","3","KNOWS"