apoc.export.cypher.data
Procedure APOC Core
apoc.export.cypher.data(nodes,rels,file,config) - exports given nodes and relationships incl. indexes as cypher statements to the provided file
Signature
apoc.export.cypher.data(nodes :: LIST? OF NODE?, rels :: LIST? OF RELATIONSHIP?, file = :: STRING?, config = {} :: MAP?) :: (file :: STRING?, batches :: INTEGER?, source :: STRING?, format :: STRING?, nodes :: INTEGER?, relationships :: INTEGER?, properties :: INTEGER?, time :: INTEGER?, rows :: INTEGER?, batchSize :: INTEGER?, cypherStatements :: STRING?, nodeStatements :: STRING?, relationshipStatements :: STRING?, schemaStatements :: STRING?, cleanupStatements :: STRING?)Input parameters
| Name | Type | Default |
|---|---|---|
nodes |
LIST? OF NODE? |
null |
rels |
LIST? OF RELATIONSHIP? |
null |
file |
STRING? |
|
config |
MAP? |
{} |
Config parameters
The procedure support the following config parameters:
| name | type | default | description |
|---|---|---|---|
writeNodeProperties |
boolean |
false |
if true export properties too. |
stream |
boolean |
false |
stream the json directly to the client into the |
format |
String |
cypher-shell |
Export format. The following values are supported:
|
cypherFormat |
String |
create |
Cypher update operation type. The following values are supported:
|
separateFiles |
boolean |
false |
Export to separate files? This is useful for later use with the |
useOptimizations |
Map |
|
Optimizations to use for Cypher statement generation.
|
awaitForIndexes |
Long |
300 |
Timeout to use for |
ifNotExists |
boolean |
false |
If true adds the keyword |
Output parameters
| Name | Type |
|---|---|
file |
STRING? |
batches |
INTEGER? |
source |
STRING? |
format |
STRING? |
nodes |
INTEGER? |
relationships |
INTEGER? |
properties |
INTEGER? |
time |
INTEGER? |
rows |
INTEGER? |
batchSize |
INTEGER? |
cypherStatements |
STRING? |
nodeStatements |
STRING? |
relationshipStatements |
STRING? |
schemaStatements |
STRING? |
cleanupStatements |
STRING? |
Exporting to a file
By default exporting to the file system is disabled.
We can enable it by setting the following property in apoc.conf:
apoc.export.file.enabled=trueIf we try to use any of the export procedures without having first set this property, we’ll get the following error message:
Failed to invoke procedure: Caused by: java.lang.RuntimeException: Export to files not enabled, please set apoc.export.file.enabled=true in your apoc.conf.
Otherwise, if you are running in a cloud environment without filesystem access, use the |
Export files are written to the import directory, which is defined by the dbms.directories.import property.
This means that any file path that we provide is relative to this directory.
If we try to write to an absolute path, such as /tmp/filename, we’ll get an error message similar to the following one:
Failed to invoke procedure: Caused by: java.io.FileNotFoundException: /path/to/neo4j/import/tmp/fileName (No such file or directory) |
We can enable writing to anywhere on the file system by setting the following property in apoc.conf:
apoc.import.file.use_neo4j_config=false|
Neo4j will now be able to write anywhere on the file system, so be sure that this is your intention before setting this property. |
Exporting a stream
If we don’t want to export to a file, we can stream results back in the data column instead by passing a file name of null and providing the stream:true config.
Usage Examples
The examples in this section are based on the following sample graph:
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]->(TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]->(TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]->(TheMatrix),
(LillyW)-[:DIRECTED]->(TheMatrix),
(LanaW)-[:DIRECTED]->(TheMatrix),
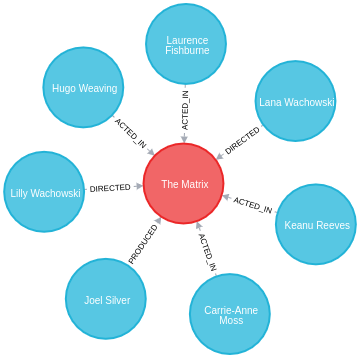
(JoelS)-[:PRODUCED]->(TheMatrix);The Neo4j Browser visualization below shows the imported graph:
The export to Cypher procedures generate Cypher statements using the CREATE, MATCH and MERGE clauses.
The format is configured by the cypherFormat parameter.
The following values are supported:
-
create- only uses theCREATEclause (default) -
updateAll- usesMERGEinstead ofCREATE -
addStructure- usesMATCHfor nodes andMERGEfor relationships -
updateStructure- usesMERGEandMATCHfor nodes and relationships
If we’re exporting a database for the first time we should use the default create format, but for subsequent exports the other formats may be more suitable.
The following exports the ACTED_IN relationships and surrounding nodes to export-cypher-format-create.cypher using the create format
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-create.cypher",
{ format: "plain", cypherFormat: "create" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-create.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
2 |
9 |
20000 |
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
CREATE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;The creation of all graph entities uses the Cypher CREATE clause.
If those entities may already exist in the destination database, we may choose to use another format.
Using cypherFormat: "updateAll" means that the MERGE clause will be used instead of CREATE when creating entities.
The following exports the ACTED_IN relationships and surrounding nodes to export-cypher-format-create.cypher using the updateAll format
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateAll.cypher",
{ format: "plain", cypherFormat: "updateAll" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateAll.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
8 |
9 |
20000 |
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Movie;
UNWIND [{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT (node.`UNIQUE IMPORT ID`) IS UNIQUE;If we already have the nodes in our destination database, we can use cypherFormat: "addStructure" to create Cypher CREATE statements for just the relationships.
The following exports the ACTED_IN relationships and surrounding nodes to export-cypher-format-addStructure.cypher using the addStructure format
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-addStructure.cypher",
{ format: "plain", cypherFormat: "addStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-addStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
5 |
4 |
15 |
4 |
9 |
20000 |
UNWIND [{_id:0, properties:{tagline:"Welcome to the Real World", title:"The Matrix", released:1999}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Movie;
UNWIND [{_id:7, properties:{born:1967, name:"Carrie-Anne Moss"}},
{_id:27, properties:{born:1964, name:"Keanu Reeves"}},
{_id:80, properties:{born:1960, name:"Hugo Weaving"}},
{_id:44, properties:{born:1961, name:"Laurence Fishburne"}}] AS row
MERGE (n:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row._id}) ON CREATE SET n += row.properties SET n:Person;
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
CREATE (start)-[r:ACTED_IN]->(end) SET r += row.properties;In this example we’re using the MERGE clause to create a node if it doesn’t already exist, and are only creating properties if the node doesn’t already exist.
In this example, relationships don’t exist in the destination database and need to be created.
If those relationships do exist but have properties that need to be updated, we can use cypherFormat: "updateStructure" to create our import script.
The following exports the ACTED_IN relationships and surrounding nodes to export-cypher-format-updateStructure.cypher using the updateStructure format
MATCH (person)-[r:ACTED_IN]->(movie)
WITH collect(DISTINCT person) + collect(DISTINCT movie) AS importNodes, collect(r) AS importRels
CALL apoc.export.cypher.data(importNodes, importRels,
"export-cypher-format-updateStructure.cypher",
{ format: "plain", cypherFormat: "updateStructure" })
YIELD file, batches, source, format, nodes, relationships, properties, time, rows, batchSize
RETURN file, batches, source, format, nodes, relationships, properties, time, rows, batchSize;| file | batches | source | format | nodes | relationships | properties | time | rows | batchSize |
|---|---|---|---|---|---|---|---|---|---|
"export-cypher-format-updateStructure.cypher" |
1 |
"data: nodes(5), rels(4)" |
"cypher" |
0 |
4 |
4 |
2 |
4 |
20000 |
UNWIND [{start: {_id:27}, end: {_id:0}, properties:{roles:["Neo"]}},
{start: {_id:7}, end: {_id:0}, properties:{roles:["Trinity"]}},
{start: {_id:44}, end: {_id:0}, properties:{roles:["Morpheus"]}},
{start: {_id:80}, end: {_id:0}, properties:{roles:["Agent Smith"]}}] AS row
MATCH (start:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.start._id})
MATCH (end:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`: row.end._id})
MERGE (start)-[r:ACTED_IN]->(end) SET r += row.properties;