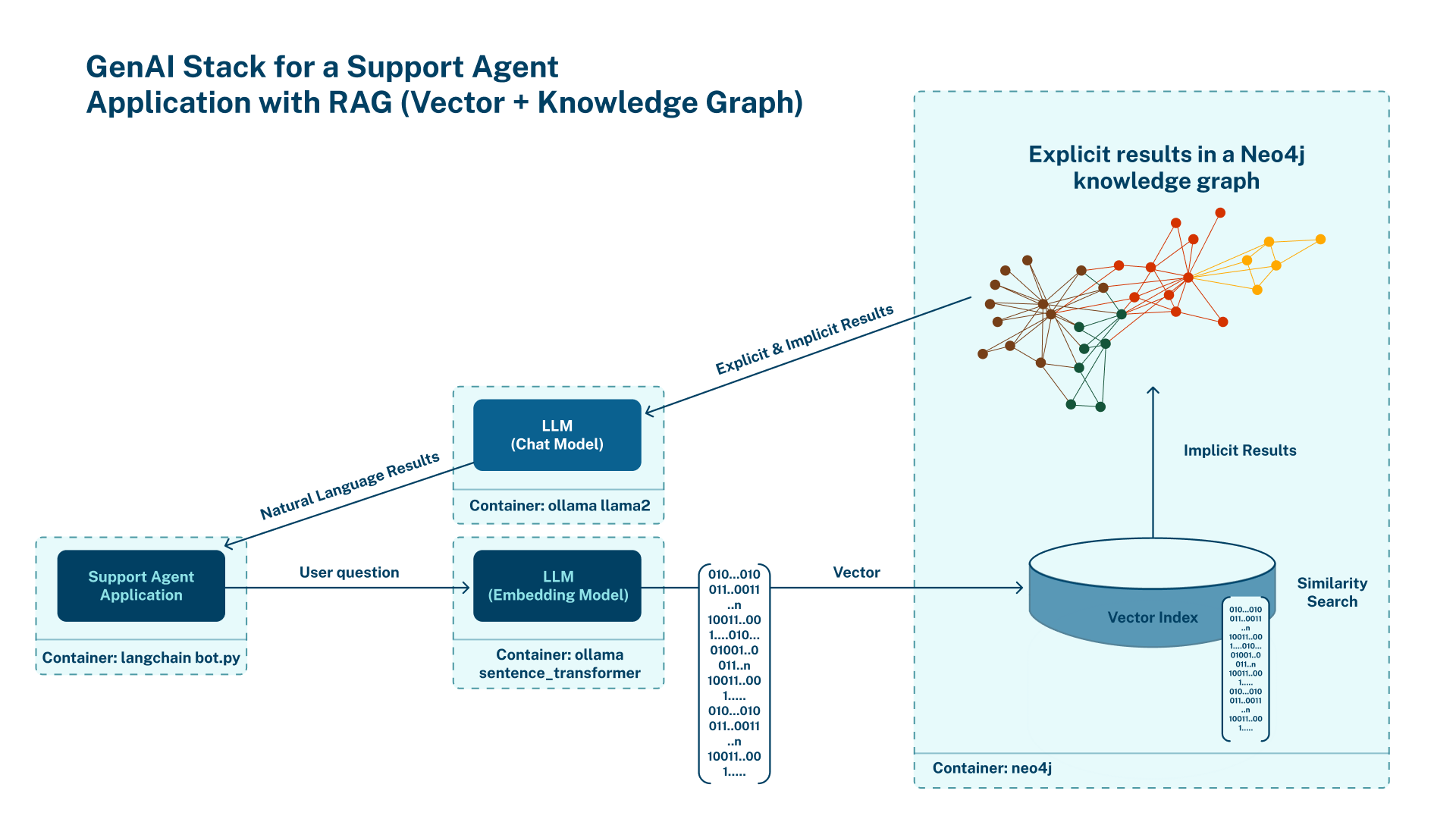
In our previous posts (Hybrid Retrieval for GraphRAG Applications Using the GraphRAG Python Package and Enhancing Hybrid Retrieval With Graph Traversal Using the GraphRAG Python Package), we explored various retrieval strategies to enhance the performance of generative AI models using Neo4j. We also dug into using vector and hybrid retrieval methods, where retrievers used either vector embeddings or full-text embeddings to identify the most relevant data entries. While these approaches have proven effective, they often require intricate setups and a deep understanding of the underlying systems.
Today, we’re excited to introduce the Text2CypherRetriever, an advanced retriever that simplifies this process. By leveraging natural language to generate precise Cypher queries, it offers a more intuitive and accessible way to integrate Neo4j into your retrieval-augmented generation (RAG) applications.
Developers previously had to navigate the complexities of creating embedding indexes and using specific models to achieve effective data retrieval. The Text2CypherRetriever improves this by using a large language model (LLM) to translate user inputs directly into Cypher queries. This approach eliminates the need for complex setups, making data retrieval simpler and more accessible to a wider range of developers. Whether you’re a seasoned Neo4j user or just getting started, the Text2CypherRetriever can significantly streamline your development process.
What Is Text2Cypher?
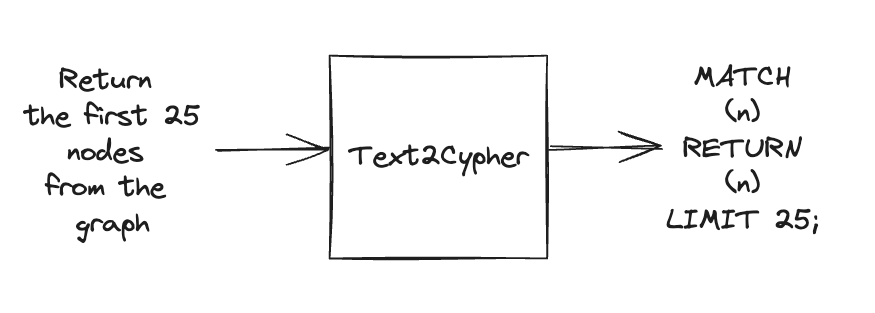
Text2Cypher is a translation method that converts natural language into Cypher queries. The Text2CypherRetriever employs this method by first asking an LLM to generate a Cypher query based on the user’s question. This generated query is then executed against the Neo4j database to fetch the required information. The resulting records are added to the context for the LLM to compose the final answer to the user’s query. This approach allows for a more intuitive interaction with the database, enabling users to input queries in natural language while the LLM handles query generation and answer formulation.
Our internal studies reveal that using Text2Cypher as a retrieval method is relatively the most consistent approach for different question variations and performed better than other strategies for different complexity levels.
Setup
Like in previous posts, start by connecting to a preconfigured Neo4j demo database that simulates a movie recommendations knowledge graph. Access it at https://demo.neo4jlabs.com:7473/browser/ using “recommendations” as both the username and password. This setup provides a realistic scenario where your vector embedding data is already part of a Neo4j database ready to be used.
In your Python environment, install the neo4j-graphrag package, along with these other packages:
pip install neo4j-graphrag neo4j openai
Proceed by establishing a connection to your Neo4j database using the Neo4j Python driver:
from neo4j import GraphDatabase
# Demo database credentials
URI = "neo4j+s://demo.neo4jlabs.com"
AUTH = ("recommendations", "recommendations")
# Connect to Neo4j database
driver = GraphDatabase.driver(URI, auth=AUTH)
Retrieval
from neo4j_graphrag.retrievers import Text2CypherRetriever
from neo4j_graphrag.llm import OpenAILLM
# Create LLM object
t2c_llm = OpenAILLM(model_name="gpt-3.5-turbo")
# (Optional) Specify your own Neo4j schema
neo4j_schema = """
Node properties:
Person {name: STRING, born: INTEGER}
Movie {tagline: STRING, title: STRING, released: INTEGER}
Relationship properties:
ACTED_IN {roles: LIST}
REVIEWED {summary: STRING, rating: INTEGER}
The relationships:
(:Person)-[:ACTED_IN]->(:Movie)
(:Person)-[:DIRECTED]->(:Movie)
(:Person)-[:PRODUCED]->(:Movie)
(:Person)-[:WROTE]->(:Movie)
(:Person)-[:FOLLOWS]->(:Person)
(:Person)-[:REVIEWED]->(:Movie)
"""
# (Optional) Provide user input/query pairs for the LLM to use as examples
examples = [
"USER INPUT: 'Which actors starred in the Matrix?' QUERY: MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE m.title = 'The Matrix' RETURN p.name"
]
# Initialize the retriever
retriever = Text2CypherRetriever(
driver=driver,
llm=t2c_llm,
neo4j_schema=neo4j_schema,
examples=examples,
)
Using the Text2CypherRetriever, we can easily generate and execute queries to retrieve information from the database:
query_text = "Which movies did Hugo Weaving star in?" print(retriever.search(query_text=query_text))
That results in this:
items=[RetrieverResultItem(content="<Record m.title='Cloud Atlas'>", metadata=None),
RetrieverResultItem(content="<Record m.title='The Dressmaker'>", metadata=None),
RetrieverResultItem(content="<Record m.title='Babe'>", metadata=None),
RetrieverResultItem(content="<Record m.title='V for Vendetta'>", metadata=None),
RetrieverResultItem(content="<Record m.title='Matrix, The'>", metadata=None),
RetrieverResultItem(content="<Record m.title='Interview, The'>", metadata=None),
RetrieverResultItem(content="<Record m.title='Adventures of Priscilla, Queen of the Desert, The'>", metadata=None),
RetrieverResultItem(content="<Record m.title='Proof'>", metadata=None)]
metadata={'cypher': "MATCH (p:Person {name: 'Hugo Weaving'})-[:ACTED_IN]->(m:Movie) RETURN m.title", '__retriever': 'Text2CypherRetriever'}
We can now add this retriever to the GraphRAG pipeline:
from neo4j_graphrag.generation import GraphRAG
llm = OpenAILLM(model_name="gpt-4o", model_params={"temperature": 0})
# Initialize the RAG pipeline
rag = GraphRAG(retriever=retriever, llm=llm)
# Query the graph
query_text = "Which movies did Hugo Weaving star in?"
response = rag.search(query_text=query_text)
print(response.answer)
That returns:
Hugo Weaving starred in the following movies: - The Dressmaker - V for Vendetta - The Matrix - The Adventures of Priscilla, Queen of the Desert - Proof
Compared to traditional vector retrieval methods, Text2CypherRetriever offers several advantages:
- Simplicity — No need for users to manually write Cypher queries or create complex embedding setups and vector indexes.
- Flexibility — Directly handle natural language inputs.
- Accessibility — Enable developers of all skill levels to easily retrieve data without a deep understanding of Cypher.
It’s important to note that the LLM-generated query is not guaranteed to be syntactically correct or return correct results, given that LLMs are non-deterministic. If it can’t be executed, a Text2CypherRetrievalError is raised.
Summary
The Text2CypherRetriever is a significant step forward for integrating Neo4j with GenAI. It simplifies the retrieval process by using natural language processing to generate Cypher queries, making it easier for developers to use. This tool is particularly useful when you need precise, context-specific information without managing vector embeddings.
We invite you to integrate the Text2CypherRetriever into your projects and share your insights via comments or on our GraphRAG Discord channel. The package code is open source, and you can find it on GitHub. Feel free to open issues there.
Effortless RAG With Text2CypherRetriever was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.