Creating an intelligent recommendation framework


10 min read

It is very likely that you are reading this blog post because a recommendation algorithm decided that it belonged on your feed. It’s also likely that your decision to read this is now being fed back into the very same algorithm that brought you here.
This, along with the rest of your data, is used to populate the ads decorating the sides of your feed and generating the revenue that keeps the servers running.
In simple terms, a recommender system is an algorithm that suggests items or decisions to a user or another system, scoring them based on predicted relevance.
While recommender systems are most commonly thought of in the context of product or content recommendations, many organizations have found innovative ways to apply these concepts to all aspects of their business.
Such examples are found everywhere. For instance, a manufacturer may leverage recommendations for alternate parts and materials when a vendor goes out of business. Or, an HR firm may recommend employees with a high potential for flight risk and then perform subsequent succession planning.
Contextual recommendations
Neo4j is a native graph database built and designed for connected data. Especially considering recommendations’ increasing prevalence, many have found the underlying graph model helpful in supporting rich contextual recommendations that are understood intuitively and developed rapidly.
There are several reasons why graphs lend themselves so well to recommendations:
-
- Explainability: Graph models are easy to understand and visualize for non-technical users. Using graph traversals and pattern matching with Cypher make graph-based recommendations easier to understand and dissect than black-box statistical approaches.
- Rapid Development: Requirements change rapidly, and models need to adapt to fit these requirements. Neo4j is schemaless, and you can refactor your graph to easily consider new data or different access patterns.
- Personalization & Contextualization: Neo4j is often used as a storage layer that connects data from multiple silos. Having quick access to everything you know about a user or product allows you to make more relevant recommendations.
- Performance: Recommender systems typically need to analyze a large amount of data to produce meaningful results. Neo4j’s native graph engine uses index-free adjacency to eliminate the need for complex joins and enable real-time traversals.
- Graph Algorithms: Neo4j’s graph algorithms library lets you run similarity, community detection, and centrality algorithms directly on the database to enrich your graph and enhance your recommendations.
This blog post aims to reach both technical and nontechnical audiences alike. Luckily, Neo4j’s whiteboard-friendly data model and visual, pattern-based query language Cypher are both easy to understand.
Explainability
Neo4j is a native graph database, meaning the graph is not simply an abstraction or a layer on top of a relational database. The data is actually stored as a graph.
The graph data model is “whiteboard-friendly.” When designing a data model, it’s quite intuitive to draw out your data in the form of connected entities.
In the relational world, the whiteboard model is then reformatted to fit the tables of a relational model. With Neo4j, however, no restructuring is necessary because the data is stored in the form of labeled nodes and relationships.
Take the following data model for a movie streaming service:
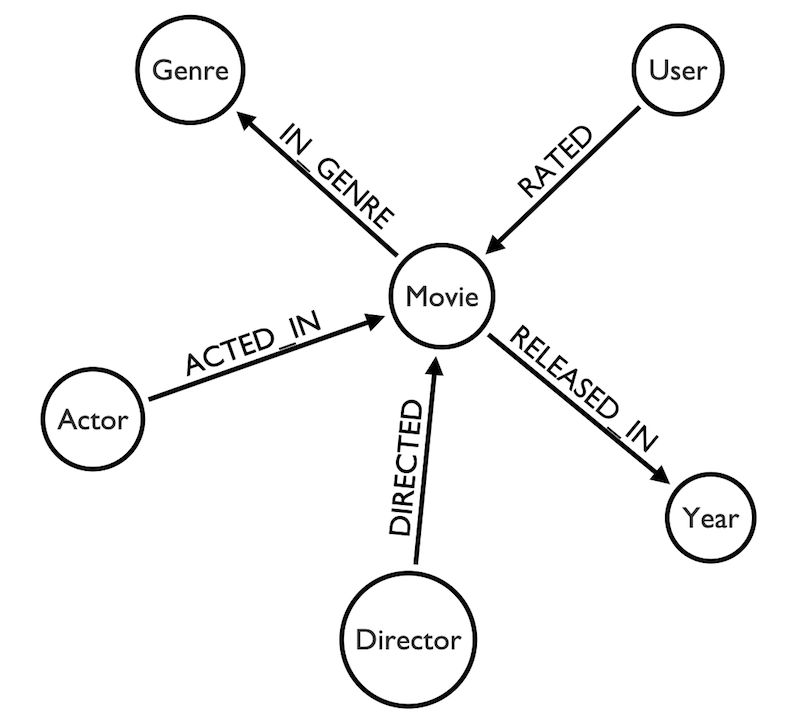
There are a few entities (or “nodes,” in common graph nomenclature) in our graph: user, movie, genre, year, actor and director.
Based on this data model, it’s fairly easy to see how our entities interact with one another. Movies have genres, users rate movies, etc. This model is simple and easy to understand, and in turn, easy to query. There is no need for any join tables or views, and our queries can be understood by anyone.
Neo4j has developed and now open-sourced the popular query language: Cypher. Cypher is a declarative language, meaning you specify what results you want back, not what you want it to do.
More concretely, Cypher is centered around the concept of pattern matching. When using Cypher, the user specifies the graph pattern they would like to retrieve from the database, and Neo4j handles the rest.
For example, let’s take the data model from before. Perhaps we would like to find all of the movies in a particular genre. The pattern we’re looking for looks like this:

Or in Cypher, it’ll look like this:
MATCH (genre:Genre{name:"Comedy"})<-[:IN_GENRE]-(movie:Movie)
RETURN movie
Even without knowing what the MATCH and RETURN key phrases do, it is pretty clear what is going on. This holds true for even more advanced use cases. Say we are building a recommendation engine to recommend the most popular movies in a specific genre.
We can drive the entire recommendation in two lines of Cypher:
MATCH (genre:Genre{name:"Comedy"})<-[:IN_GENRE]-(movie:Movie)<-[rating:RATED]-(user:User)
RETURN movie, avg(rating.rating) AS score ORDER BY score DESC
Rapid development
Many recommender systems rely heavily on statistical approaches. In order to adapt to changing requirements, models may need to be tweaked and retrained, which can be time intensive. In contrast, Cypher patterns and graph algorithms can be edited and adapted quickly without retraining.
Furthermore, graph databases are schemaless and thus more flexible than their relational counterparts. Graph models can grow and change along with requirements, unlike relational models where tables need to be dropped and rebuilt.
Let’s look at adding an additional data point, like IMDb ratings to our movies graph. The recommendation query can be quickly extended to account for this new data, resulting in:
MATCH (genre:Genre{name:"Comedy"})<-[:IN_GENRE]-(movie:Movie)<-[rating:RATED]-(user:User)
MATCH (movie)-[:HAS_IMDB_RATING]->(imdbRating:ImdbRating)
RETURN movie, avg(rating.rating)+avg(imdbRating.rating) AS score ORDER BY score
We have now improved the accuracy of our recommendation score with the addition of a single line of Cypher. What would normally take multiple joins using SQL is accomplished by traversing a couple of relationships. This makes our system easier to manage and maintain, and helps us avoid costly mistakes.
Personalization & contextualization
The graph model inherently supports rich, contextualized information. If a graph is modeled well, then each node should have neighbors that provide valuable context about that node.
For example, a user in our movies graph is connected to the movies they rated. From those movies, we can infer their favorite genre and actors, and even predict other users with similar movie preferences.
Using the same data model from before, we can learn a user’s favorite genres using the following query:
MATCH (:User {id: "1"})-[r:RATED]->(m)-[:IN_GENRE]->(g)
WHERE toInteger(r.rating) = 5.0
RETURN g.name AS genre, count(m) AS score
ORDER BY score DESC
The value of personalized context when curating recommendations is extremely high. Different users likely have varying tastes, and our recommendation systems need to take that into account in order to maximize its success.
Performance
Recommendations are often only useful in real time.
A classic example is online retail. Online shoppers often browse through items extremely quickly, so recommendations need to be computed within milliseconds.
A less obvious example is situational planning for manufacturers. If a part or product is recalled or contaminated, everything related to that part or product must be immediately recalled, and alternatives must be identified as well. Time is money.
Neo4j’s native graph engine makes it an exceptional tool for producing real-time recommendations. Neo4j makes use of index-free adjacency to traverse the graph in constant time, avoiding computationally expensive joins in a relational database. This allows us to anchor onto a single node in the graph (ideally with an index lookup) and then traverse outwards, analyzing relationship patterns in constant time to generate recommendations.
In our previous movie recommendation query, we’re traversing three different relationships, which would likely equate to three joins in a relational database.
Perhaps a better example to illustrate the usefulness of index-free adjacency is identifying fraud rings.
We can use Neo4j to identify accounts that are linked through various data points, like their SSN, email or phone number. Often, these chains can be dozens of hops long, making this kind of analysis not only slow but actually impossible using relational databases (where graphs can provide sub-second results).
Graph algorithms
Graphs are not new; in fact, the concept dates back almost 300 years. So it comes as no surprise that graphs have a rich ecosystem of valuable proven algorithms.
Leveraging a graph pattern known as a triadic closure is a simple yet powerful way to generate recommendations using Neo4j. A triadic closure is the inference of a weak connection between two nodes not directly connected, but are instead indirectly connected by an arbitrary number of intermediary nodes.
For example, two movies that share a common genre have a weak connection and thus some degree of similarity. In practice, this might look something like this:
MATCH (m1:Movie{name:"Iron Man"})-[:IN_GENRE]->(g)<-[:IN_GENRE]-(m2)
RETURN m2 AS recommendation, count(g) AS score ORDER BY score
Here, the weaker connections between two nodes, the higher their implied similarity. Furthermore, because index-free adjacency allows us to traverse relationships in constant time, we can traverse paths of arbitrary length to infer connections between nodes.
Triadic closures are a great way to develop a simple recommendation system extremely quickly, but only scratch the surface of what can be done leveraging graph algorithms.
Without going into too much detail, here are some other algorithmic paradigms which could also be used:
-
- Centrality: Centrality algorithms identify important nodes within a graph, discovering nodes which are popular or influential.
- Community Detection: Community detection algorithms evaluate how a group is clustered or partitioned, as well as its tendency to strengthen or break apart. This might reveal things like user cohorts or clusters of content.
- Path Finding: Path finding algorithms help find the shortest path or evaluate the availability and quality of routes from, to or between nodes.
Neo4j’s intelligent recommendation framework
Keymaker, Neo4j’s Intelligent Recommendations Framework, is a data model agnostic tool designed to help organizations design and manage their graph based recommender systems.
Keymaker includes an admin console where users can build out their recommendation pipelines, and exposes a GraphQL API where recommendations can be accessed. By focusing on the five qualities discussed above, Keymaker aims to minimize development efforts while helping users maximize the value of graphs.
For additional information on Keymaker, Neo4j’s Intelligent Recommendations Framework, reach out to [email protected] or tune in to our next blog post where we’ll use Keymaker to build out a real-world recommender system.
Learn about the power of graph algorithms in the O’Reilly book,
Graph Algorithms: Practical Examples in Apache Spark and Neo4j by the authors of this article. Click below to get your free ebook copy.Get the O’Reilly Ebook
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

POLE+O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph

1 of 3: The difference between a graph, a knowledge graph, and a context graph
