Run Cypher to analyze Neo4j graph database inconsistencies

Solutions Engineer, Neo4j
13 min read

Have you ever wanted to check for data inconsistencies in your Neo4j graph database?
Perhaps you are merging data from different sources, or over the course of a project have changed your data model without reloading data. Or alternatively, you are asked to review someone else’s Neo4j graph database and look for issues. This blog post will look into one approach to check for data inconsistencies.
Neo4j is very flexible and forgiving when it comes to entering data. The property graph model Neo4j uses enables nodes with the same label to have different sets of properties. Let me use a short example to further explain.
Let’s say you were given a project to document the history of famous actors and actresses. You immediately think to yourself – I can just run :play movies in my Neo4j Browser and load the Cypher to get a quick start.
Here is a snippet from the movies Cypher:
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
CREATE (Carrie:Person {name:'Carrie-Anne Moss', born:1967})
CREATE (Laurence:Person {name:'Laurence Fishburne', born:1961})
CREATE (Hugo:Person {name:'Hugo Weaving', born:1960})
CREATE (LillyW:Person {name:'Lilly Wachowski', born:1967})
CREATE (LanaW:Person {name:'Lana Wachowski', born:1965})
CREATE (JoelS:Person {name:'Joel Silver', born:1952})
CREATE
(Keanu)-[:ACTED_IN {roles:['Neo']}]-> (TheMatrix),
(Carrie)-[:ACTED_IN {roles:['Trinity']}]-> (TheMatrix),
(Laurence)-[:ACTED_IN {roles:['Morpheus']}]-> (TheMatrix),
(Hugo)-[:ACTED_IN {roles:['Agent Smith']}]-> (TheMatrix),
(LillyW)-[:DIRECTED]-> (TheMatrix),
(LanaW)-[:DIRECTED]-> (TheMatrix),
(JoelS)-[:PRODUCED]-> (TheMatrix)
You can see from the statements that the current data model is this:
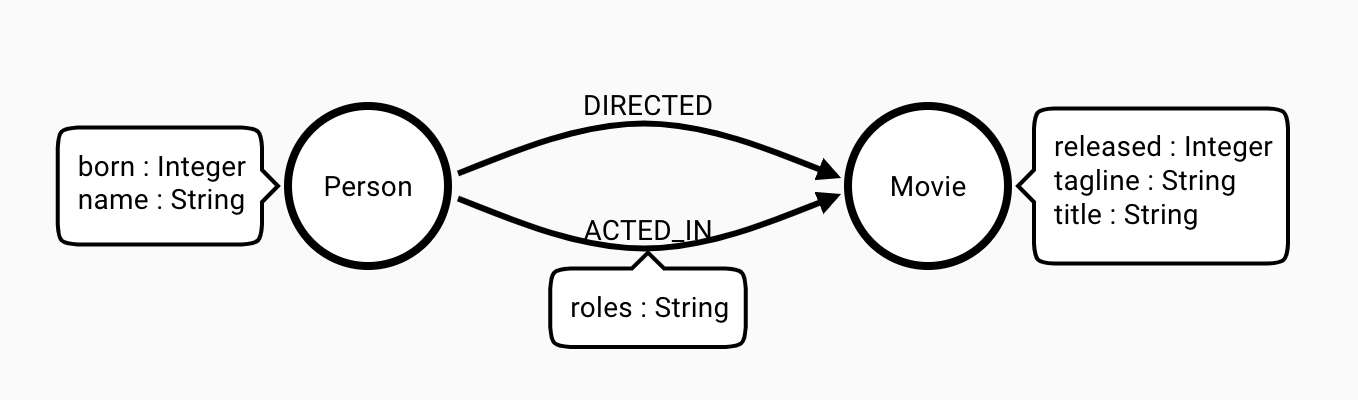
Your data model has two Node Labels: Person and Movie. There are two relationships between Person and Movie, DIRECTED and ACTED_IN, but for the purpose of this blog post we will only focus on Node Labels.
For the Person node label, there are two properties: born and name. For the Movie node label there are three properties: released,tagline,title.
Now your team lead comes to you and says that people are also interested when actors and actresses got their first starring role. Also, the client has requested to know if a given Person has won an Oscar. And finally, you are told to drop the tagline from Movie.
To implement these requests, you modify your Cypher for new films:
CREATE (ToyStory4:Movie {title:'Toy Story 4', released:2019})
MERGE (Keanu:Person {name:'Keanu Reeves', born:1964})
SET Keanu.wonOscar = false, Keanu.filmDebut = 1985
MERGE (TomH:Person {name:'Tom Hanks', born:1956})
SET TomH.wonOscar = true, TomH.filmDebut = 1980
MERGE (TimA:Person {name:'Tim Allen', born:1953})
SET TimA.wonOscar = false, TimA.filmDebut = '1988 maybe?'
MERGE (AnnieP:Person {name:'Annie Potts', born:1952})
SET AnnieP.wonOscar = false, AnnieP.filmDebut = 1978
CREATE
(Keanu)-[:ACTED_IN {roles:['Duke Caboom (voice)']}]-> (ToyStory4),
(TomH)-[:ACTED_IN {roles:['Woody (voice)']}]-> (ToyStory4),
(TimA)-[:ACTED_IN {roles:['Buzz Lightyear (voice)']}]-> (ToyStory4),
(AnnieP)-[:ACTED_IN {roles:['Bo Peep (voice)']}]-> (ToyStory4)
In the new Cypher, the ‘tagline’ on Movie has been dropped and two new properties on Person have been added: wonOscar, filmDebut.
Additionally, note that we have used MERGE here instead of CREATE to match and update existing data instead of creating duplicate nodes.
Our new model now looks like this:

By comparing pictures of the old and new data models you can see the differences in the data model. But what you cannot see is what data loaded in your database conforms to which model, and how many nodes may need to be updated.
Cypher to look for property key variations
We can actually write Cypher to examine our data for inconsistencies.
Here is one query that will look through nodes by Node Label in a Neo4j graph database and print out Node Labels having different property key sets.
/* Looks for Node Labels that have different sets of property keys */
WITH "MATCH (n:`$nodeLabel`)
WITH n LIMIT 10000
UNWIND keys(n) as key
WITH n, key
ORDER BY key
WITH n, collect(key) as keys
RETURN '$nodeLabel' as nodeLabel, count(n) as nodeCount, length(keys) as keyLen, keys
ORDER BY keyLen" as cypherQuery
CALL db.labels() YIELD label AS nodeLabel
WITH replace(cypherQuery, '$nodeLabel', nodeLabel) as newCypherQuery
CALL apoc.cypher.run(newCypherQuery, {}) YIELD value
WITH value.nodeLabel as nodeLabel, collect({
nodeCount: value.nodeCount,
keyLen: value.keyLen,
keys: value.keys}) as nodeInfoList
WHERE size(nodeInfoList) > 1
UNWIND nodeInfoList as nodeInfo
RETURN nodeLabel, nodeInfo.nodeCount as nodeCount, nodeInfo.keyLen as keyLen, nodeInfo.keys as keys
ORDER BY nodeLabel, keyLen
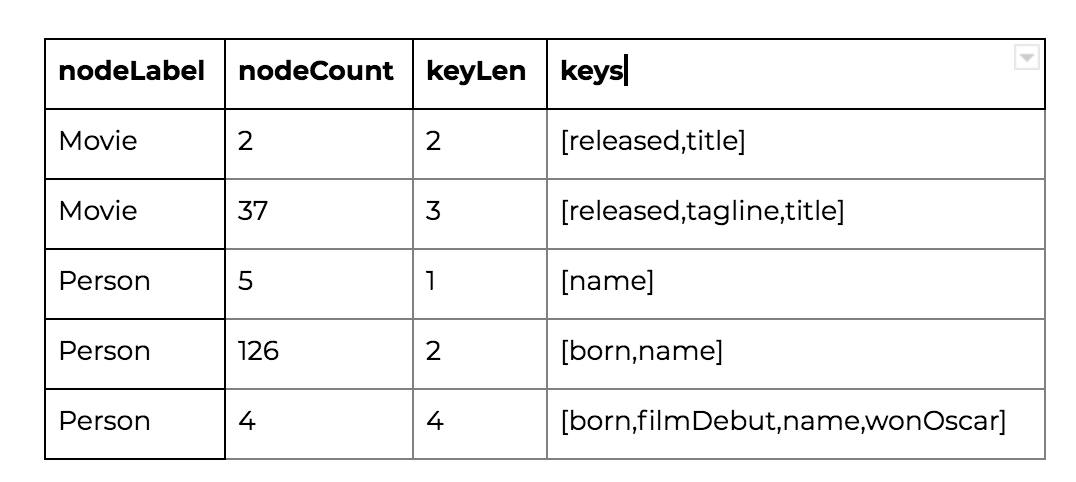
If you had loaded the Movie data from the Neo4j sample dataset in :play movies, then ran the ToyStory4 Cypher statement, running the Cypher statement above will produce the following result:

You will see that for both Movie and Person nodes, the property keys are not the same for all instances. It is up to you to determine whether the difference in property keys is okay or not.
Sometimes it means that some nodes just didn’t have data for that property so the property wasn’t created. This is usually okay. Other times, it might mean old data is loaded that does not conform to newer changes in the data model. Running this script will at least indicate to you that there may be a problem.
Building the query
The Cypher statement used is fairly complex. The best way to explain how it works is to recreate the Cypher statement, one step at a time, so you can see what is going on.
To start, let’s focus only on nodes with the Movie label.
We want to look in the database at all Movie nodes, and list the property keys that they have:
MATCH (n:Movie) RETURN keys(n)
This will return something like this:

We use the keys() function to examine the property keys for each node. Notice that some nodes have different sets of keys, but the property names are unordered within each set. We first need to order the keys to ensure that [title,tagline,released] is the same as [released,tagline,title]:
MATCH (n:Movie) UNWIND keys(n) as key RETURN key ORDER BY key
We use UNWIND keys(n) to take each member of the set and return it as its own row. We use ORDER BY to order the keys alphabetically. A snippet of the output is below. Examining the output shows us we must figure out a way to eliminate the duplicate key names.

To eliminate the duplicate keys, we use a couple of WITH statements. The first WITH enables us to perform an ORDER BY in the middle of the statement, so we can pass an ordered set of keys to the second WITH. The second WITH uses collect(key) to collect the keys back into a list.
MATCH (n:Movie) UNWIND keys(n) as key WITH n, key // need this to run ORDER BY ORDER BY key WITH n, collect(key) as keys RETURN keys
Note that we must include WITH n in each of the WITH statements. In Cypher, WITH is used to perform intermediate results processing, and when used, it creates a new variable scope. Any variables you wish to preserve must be declared in the WITH so later statements can use them.
The first WITH n is just used to pass n through to the next part, to ensure the variable is still in scope.
The second WITH n is used as grouping criteria, so for each node n the keys are collected back into a list. This results in a single row for n, you will get a single row with all of the keys on one big list.
Some results from running this new statement are:

Now we can see that the keys are in order and we are getting a set of keys for every Movie node. The last thing we must do, is count up how many nodes there are for each unique key set.
The following query does this in the RETURN clause. We implicitly group on keys and keyLen (since this is just a metric derived from keys), and use count(n) to count the nodes for each unique key set.
MATCH (n:Movie) UNWIND keys(n) as key WITH n, key ORDER BY key WITH n, collect(key) as keys RETURN count(n) as nodeCount, length(keys) as keyLen, keys ORDER BY keyLen
Finally, we have our results and can see two nodes with [‘released’,’title’] and 37 nodes with [‘released’,’tagline’,’title’].

Running the query for all node labels
Now we have a query that works for a single Node Label Movie. But the goal is to have it work for all Node Labels present in a database, and to do it without knowing what Node Labels are already present.
The first step towards this goal is to run:
CALL db.labels() YIELD label AS nodeLabel RETURN nodeLabel
This will list every Node Label in the database.

The next step is to use the Node Labels to create individual Cypher statements for each Node Label. We can use the nodeLabel returned from db.labels() to create a Node Label specific Cypher statement.
WITH "some cypher statement" as cypherQuery CALL db.labels() YIELD label AS nodeLabel RETURN cypherQuery + " for " + nodeLabel
Now we must substitute in our Movie Cypher for “some cypher statement” and make the following changes:
- Replace
Movieto$nodeLabel - Add
$nodeLabelasnodeLabel to RETURN - Add
WITH replace(cypherQuery, '$nodeLabel', nodeLabel)asnewCypherQueryafter we calldb.labels()
Making these substitutions produces the query below.
Running the query produces individual Cypher statements for each NodeLabel. Note that even though I am using $nodeLabel, this is not an actual parameterized Cypher call, because currently you can not parameterize Node Labels.
Instead, $nodeLabel is being used as a placeholder for a string substitution. Calling replace(…) changes our $nodeLabel placeholder with the actual nodeLabel value returned from db.labels().
WITH "MATCH (n:`$nodeLabel`) UNWIND keys(n) as key WITH n, key ORDER BY key WITH n, collect(key) as keys RETURN '$nodeLabel' as nodeLabel, count(n) as nodeCount, length(keys) as keyLen, keys ORDER BY keyLen" as cypherQuery CALL db.labels() YIELD label AS nodeLabel WITH replace(cypherQuery, '$nodeLabel', nodeLabel) as newCypherQuery RETURN newCypherQuery
Running this produces the following result:

Now that we have a Cypher query for each Node Label, we can use apoc.cypher.run() to run each query. This will require APOC to be installed in your database. Please read these instructions to install APOC if it is not already configured to run in your database.
CALL apoc.cypher.run(newCypherQuery, {}) YIELD value
The value that is returned by apoc.cypher.run contains the results of the query that was executed.
For each row returned in your Cypher query, value will produce a map where the map keys are the return variables names, and the map values are the return values. Here is an example return:
{
"nodeCount": 2,
"keyLen": 2,
"nodeLabel": "Movie",
"keys": [
"released",
"title"
]
}
To complete our query, we must process these results to determine which Node Labels may have different property keys.
First, we use nodeLabel as our grouping key and collect() up the other returned values. By using collect() on nodeLabel, we end up returning a single row for each Cypher query at this point. The nodeInfoList variable contains all of the other rows returned from the Cypher query.
WITH value.nodeLabel as nodeLabel, collect({
nodeCount: value.nodeCount,
keyLen: value.keyLen,
keys: value.keys}) as nodeInfoList
WHERE size(nodeInfoList) > 1
Next, we use size (nodeInfoList) > 1 in the WHERE clause to check and see if there is more than 1 row from each Cypher query. If there is only 1 row, we don’t want to return. A single row means for every node with that node label, all nodes have the same set of property keys. This indicates good data, and we only want to return node labels where there are different sets of property keys.
The very last piece of the query converts the nodeInfoList collection back into individual rows using UNWIND. We also ORDER BY nodeLabel, and keyLen to sort alphabetically on node labels and to show smaller key sets first.
UNWIND nodeInfoList as nodeInfo RETURN nodeLabel, nodeInfo.nodeCount as nodeCount, nodeInfo.keyLen as keyLen, nodeInfo.keys as keys ORDER BY nodeLabel, keyLen
Running the completed query, produces these results (as shown previously):
The very last piece I put in the overall query is a small addition to our embedded Cypher query. On the second line I added this:
WITH n LIMIT 10000
This provides a safeguard when running this query against large databases.
For a given Node Label, it will only look at the first 10,000 rows. Without this safeguard, for large databases it could easily run out of memory. Feel free to adjust this limit, add a SKIP, or try some different sampling techniques if you don’t want to look at only the first 10,000 rows.
Conclusion
We were able to run a Cypher query to check for data inconsistencies in the Neo4j database. We looked only at differences in property keys for the same Node Label. Depending on your specific data and data model, this may or may not be okay. You will have to make that determination based on your project requirements.
You can create a few other variants of this query: one variant can also pull back the specific rows that may have inconsistent data, and another can check for inconsistent data values within a specific property key. Try to see if you can produce the variants on your own using the power of Neo4j stored procedures, plus the execution of dynamically generated Cypher queries. These variants use the exact same techniques described in the blog post with only a little extra logic.
In future blog posts, I’ll be visiting other queries used to check different data health aspects of your Neo4j database.
Show off your graph database skills to the community and employers with the official Neo4j Certification. Click below to get started and you could be done in less than an hour.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.

