







This Week in Neo4j – Speaker Identification meets graphs, Graph Technology Landscape, Why You Need Graph Technology on GKE, Revealing Malware relationships

Developer Relations Engineer
4 min read

Welcome to This Week in Neo4j, where this week we have a presentation explaining why you need graph technology on Google Kubernetes Engine, as well as a blog post explaining how to reveal malware relationships using Neo4j.
We also have the next part in the BBC GoodFood series, the graph technology landscape, and a novel approach for finding unique speakers from their voice print.
Featured Community Members: Arsames Qajar
This week’s featured community members is Arsames Qajar, an Entrepreneur, CTO, and Professor at USC.
Arsames Qajar – This Week’s Featured Community Member
Arsames specializes in educating graduate-level students around topics of ‘big data’, data warehousing, and databases. His entrepreneurial spirit stands out to us as he had a vision of helping educators around the world understand the value of graph databases and reached out to us directly to propose an idea.
He began this initiative in his own backyard by organizing a guest lecture with guests like Mark Quinsland, Field Engineer at Neo4j and Brian Kuang, Senior Performance Improvement Consultant at EY. He has some big visions for the future and we are looking forward to being involved in his exciting endeavors!
Oh, and he’s certified in Neo4j! If you’re not, you should be too!
Why You Need Graph Technology on GKE
Last week David Allen and Gabriela Ferrari presented Why You Need Graph Technology on GKE as part of the Google webinar series.
They start with an introduction to Google Cloud, GKE, and Neo4j, before showing how to deploy a Neo4j Causal Cluster on GKE. They also show how to do backup and restore, how to scale the cluster, and finish with a demo of Neo4j running on GKE.
Revealing Malware relationships with Neo4j
Tstillz has written the first in a series of posts showing how to analyse Malware with graphs.
Tstillz explains how to model this domain as a graph, loads some data from the WannaCry ransomware attack into Neo4j, and then shows how to write Cypher queries to explore the dataset.
Building a PowerBI Connector, Backing up to S3, Cypher Date Snippets
- Chris Skardon has written a blog post explaining how to build your own Neo4j PowerBI Data Connector.
- Sandip Shinde has been doing Customer Journey Analytics with Neo4j, and shares some useful Cypher snippets for interacting with the new date type introduced in Neo4j 3.4
- David R Bayer explains how to write a Neo4j backup script that takes a copy of the database and uploads the resulting archive to S3.
- I wrote part 2 of a series of posts on the BBC GoodFood graph. This week we learn how to find recipes that contain a set of ingredients that we have in our fridge, or alternatively find recipes that don’t contain a set of allergens.
- Our friends at Graphileon published a video showing how to edit nodes and relations in a grid, a much easier and faster experience than editing them in-graph.
Speaker Identification meets graphs
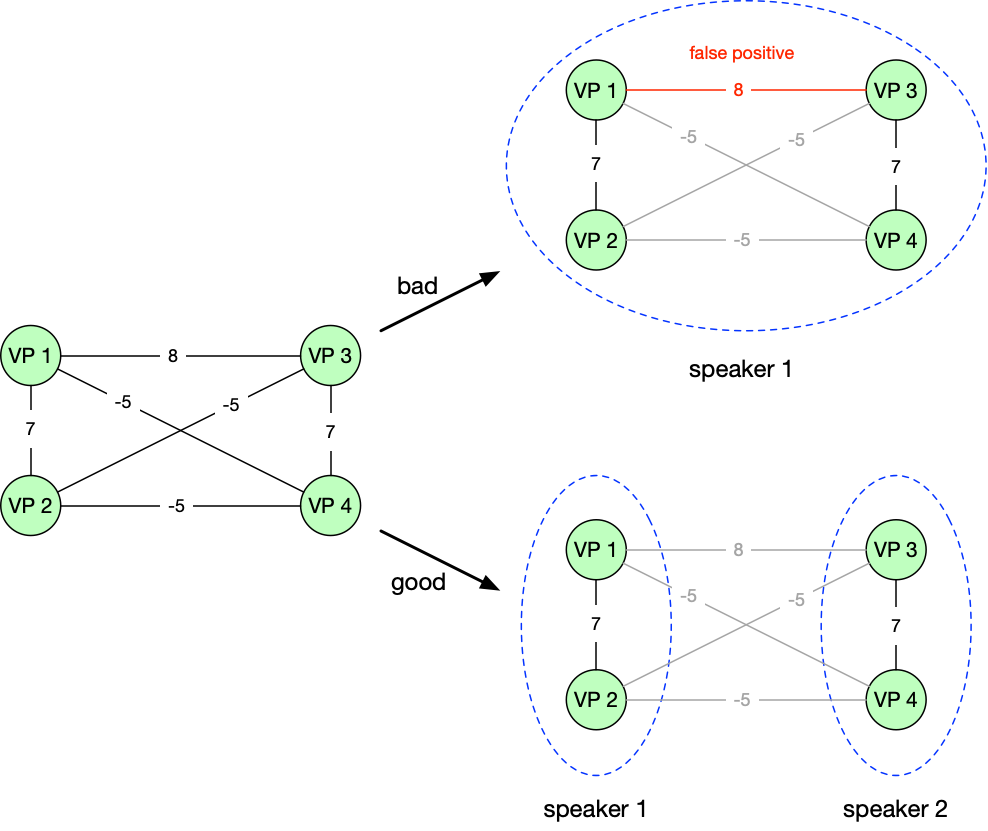
Jan Zak has written a blog post describing a novel approach to identify unique speakers from their voice print.
Jan describes an approach where we build a similarity graph based on voice prints, before running the Louvain community detection algorithm to find clusters containing the same speakers.
Graphing the Graph Technology Landscape

Last week Janos Szendi-Varga wrote a blog post launching the Graph Technology Landscape map. It’s like Matt Turck’s Big Data Landscape, but for graphs, and covers infrastructure, analytics, visualisation, application frameworks, graph query languages and more.
If you want to play with the data behind the map, Rik has created a Graph Gist, in which he loads the data and shows the type of queries you can run on this dataset.
On the podcast: Jess Mason and Jason Cox, Untitled Folder

This week on the Graphistania podcast, Rik interviewed Jess Mason and Jason Cox of Untitled Folder, our featured community members of 10th November 2018.
They talk about their introduction into the world of graph databases, the Cypher Philly initiative that they’ve been running for the last few years, as well as their predictions for the future of graph databases.
Tweet of the Week
My favourite tweet this week was by Marco Falcier:
Describing the evolution of a love relationship with the help of our @neo4j Versioner Core 2.0.0, now supporting relationship versioning. #LoveNeo4j @ziotob
More info here: https://t.co/ubCtjFPyrW pic.twitter.com/RqjmkVwstp— Marco Falcier (@mfalcier) February 5, 2019
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles


This Week in Neo4j: Community Edition, Aura Agents, Context Graph, Spring Data and more

This Week in Neo4j: AI in Production, Memory, GraphRAG, Architecture and more

This Week in Neo4j: Aura Agents, Persistence, Graph Algorithms, GraphRAG and more

This Week in Neo4j: NODES AI, Context, Text2Cypher, Fraud Detection and more
