Building an educational chatbot for GraphAcademy with Neo4j

Developer Experience Engineer at Neo4j
15 min read

Building an educational chatbot for GraphAcademy with Neo4j using LLMs and vector search
As part of the Developer Relations team, I’ve had some really interesting times using Neo4j as a database to tackle challenges. I have always found it invigorating to discuss these experiences with others, passing on what I’ve learned.

For example, I have recently published an article where I went into depth on how I built an educational platform on top of Neo4j. GraphAcademy is our free, self-paced learning platform where users can learn everything they need to know to be successful with Neo4j.
Building an Educational Platform on Neo4j
Now, here’s a fun fact — GraphAcademy is maintained by just two people. There are only so many hours in the day, and we have a lot of content to cover, which means we’ve got to be sharp about our priorities.
We’re victims of our own success in a way — the sheer amount of questions and feedback on the content we receive is overwhelming. We’d love to respond to every one of them, but it’s just not possible.
One thing that keeps me up at night is the experience of our users. For anyone learning a new language or technology, it can be frustrating when you get stuck and don’t know where to turn. Worse yet, this could lead to them abandoning Neo4j altogether.

So I’m constantly thinking, how can we better support our users? Or better yet, how can we use Neo4j to support our users?
Can we use LLM?
This is where Language Models (LLMs) come into the picture. They present a real opportunity for us to scale our support, providing timely feedback to our users.
Harnessing Large Language Models with Neo4j
Imagine using the content from GraphAcademy and the Neo4j Documentation to train an educational chatbot for user support. That’s an opportunity I couldn’t resist.
To avoid hallucinations, we don’t want to use the training data of the LLM; we just want to utilize its language skills that we want to answer the user by summarising the relevant parts of our documentation. This technique is also called RAG (Retrieval Augmented Generation).
Knowledge Graphs & LLMs: Fine-Tuning Vs. Retrieval-Augmented Generation
So we need to:
- Turn our docs into vector embeddings for similarity search.
- Store and index them in Neo4j.
- Embed the user question as a vector too and find the most relevant bits of documentation.
- Have the LLM answer and summarise the information for the user.
Graphs and vectors
It seems like Vector databases are springing up everywhere, and every database vendor seems to be in an arms race to provide either own. Their role in Generative AI is to store high-dimensional vectors that can be used to later find items by similarity in that conceptual space.
In the case of the GraphAcademy chatbot, we need a vector representation of chunks (parts) of our documentation to compare with a user’s question. The more similar the two vectors are, the more likely the corresponding content will be to answer the question. The key, then, is to break the documentation into chunks that contain enough information to answer an as-yet-undefined question, while being small enough to not exceed the context limits of the LLM.
Chunking the Neo4j Documentation
The Neo4j Documentation, written in Asciidoc and converted to HTML using Antora, is split into subheadings.
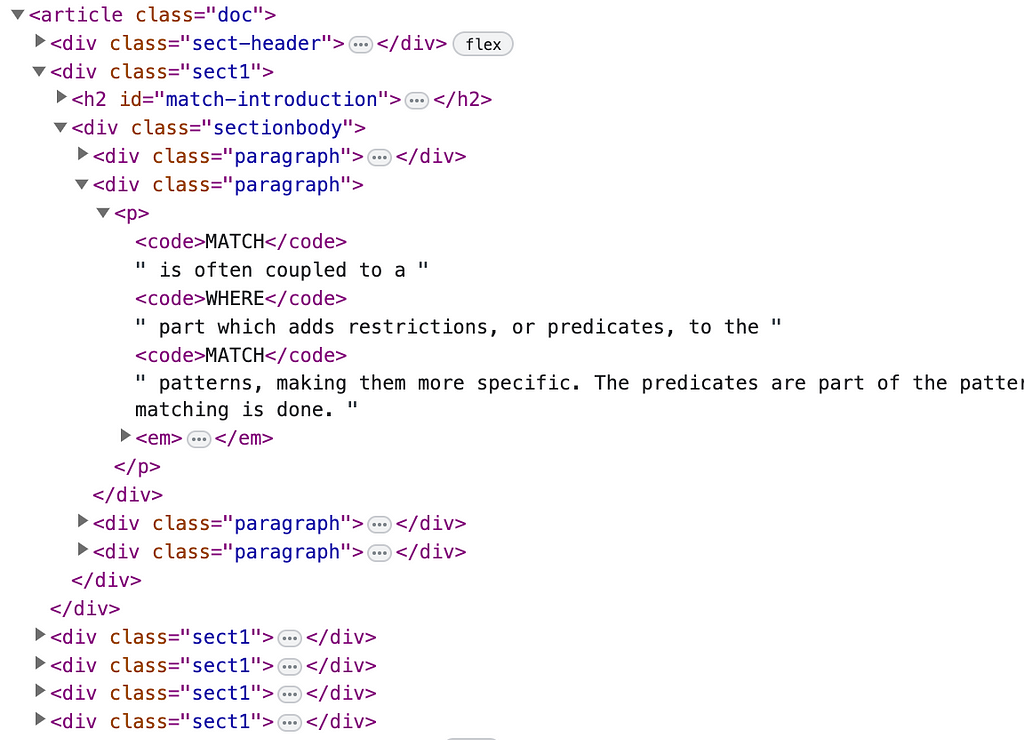
After some experimentation, I settled on using the .sect1 CSS selector, which seemed to work well. I generated a copy of the documentation, and then with the help of BeautifulSoup and the Neo4j Python Driver, I iterated over each manual to create a hierarchy of pages and sections in the Neo4j Graph Database using the following code.
def extract_docs(url, html):
soup = bs4.BeautifulSoup(html)
text = None
title= soup.find("h1", class_="page").text.strip()
parsed = urlparse(url)
article = soup.find('article', class_='doc')
links = article.find_all('a')
cleaned_links = []
for link in links:
if link.get('href') != None and not link.get('href').startswith('#'):
cleaned_links.append(cleaned_link(url, link))
sections = []
for section in soup.select('#preamble, .sect1'):
header = section.find('h2')
section_links = [ cleaned_link(url, link) for link in section.find_all('a') if link.text != "" ]
anchor = section.find('a', class_='anchor')
section_url = urlunparse((parsed.scheme, parsed.netloc, parsed.path, parsed.params, parsed.query, anchor.get('href').replace('#', '') if anchor else 'preamble'))
code_blocks = []
for pre in section.find_all('pre'):
language = pre.find('div', class_="code-inset")
title = pre.find('div', class_='code-title')
code = pre.find('code')
if code:
code_blocks.append({
"language": language.text.strip() if language is not None else None,
"title": title.text.strip() if title is not None else None,
"code": code.text
})
sections.append({
"url": section_url,
"title": header.text.strip() if header is not None else None,
"text": section.text.strip(),
"anchor": anchor.get('href') if anchor else None,
"links": section_links,
"images": [ cleaned_image(url, img) for img in section.find_all('img') ],
"code": code_blocks
})
return {
"url": url,
"title": title,
"links": cleaned_links,
"sections": sections
}
Naturally, this hierarchy fits well into a graph.
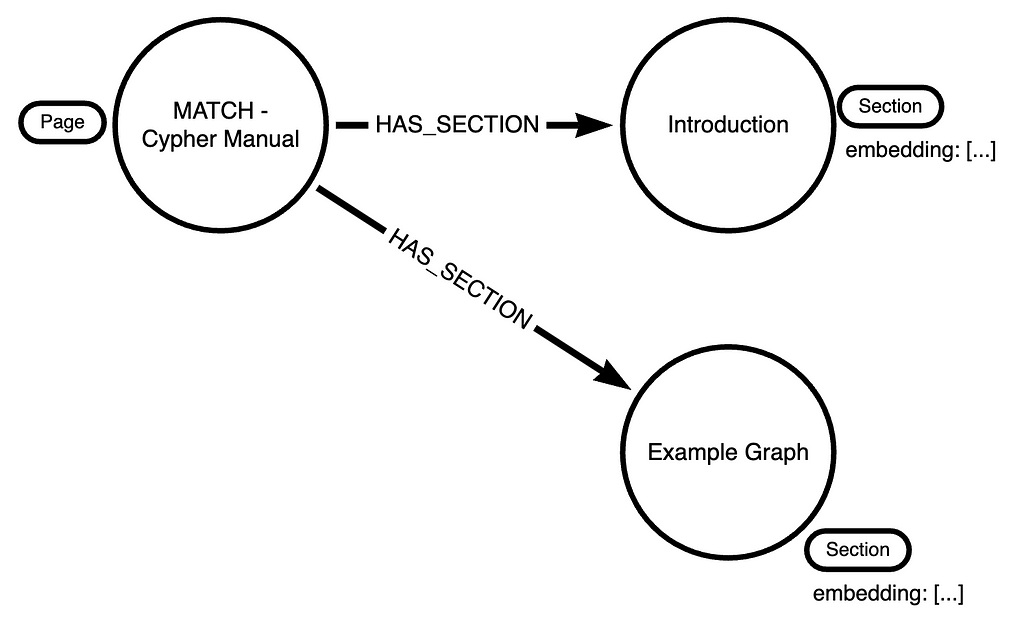
The old me would have added a full-text index to text property and left the rest to fate. But the release of OpenAI’s GPT-APIs has opened up a new set of possibilities. The OpenAI API /embeddings endpoint provides a way to convert text into a vector.
// Set the API Key
openai.api_key = os.getenv('OPENAI_API_KEY')
// Get sections without an embedding
records, _, __ = driver.execute_query("""
MATCH (s:Section) WHERE s.embedding IS NULL
and not s.url contains 'upgrade-migration-guide'
RETURN s
""")
for record in tqdm_notebook(records):
url = record['s']['url']
// Convert the text property into an embedding
embeddings = [
el['embedding']
for el in openai.Embedding.create(input=record['s']['text'], model='text-embedding-ada-002')['data']
]
// Add the embedding and a new :Chunk label
driver.execute_query("""
MATCH (s:Section {url: $url})
SET s:Chunk, s.embedding = $embedding
""", url=url, embedding=embeddings[0])
The whole embedding process cost a few cents, which I was pleasantly surprised about.
chunks = openai.Embedding.create(
input=question,
model='text-embedding-ada-002'
)
The same embedding method can be used to create an embedding for a user’s question. The result is an array of floats between 10.0 and -10.0. Because both embeddings have been created by the same service. it’s a simple task of performing a similarity search.
If you’ve read a few articles on Chatbots and LLMs already, this may be where you may be tempted to reach for a dedicated vector database. Stop right there!
Vector Indexes are now supported in Neo4j! You can now use Vector Indexes in Neo4j Aura.
You can find technical documentation for the Vector Index and Vector Search here.
Vector search index – Cypher Manual
In the code sample above, the update query also sets a :Chunk label on each (:Section) node. We can take advantage of the label and property to create a vector index on the :Chunk / .embedding label/property pairing.
CALL db.index.vector.createNodeIndex(
'chatbot-embeddings', // The name of the index
'Chunk', // The label
'embedding', // The property
1536, // The dimensions of the embedding, OpenAI uses 1536
'cosine' // Function to calculate similarity
)
All that is needed now is a function to:
- Create an embedding of the user’s input
- Query the chatbot-embeddings vector index to find sections on the website that have similar content
- Further search the graph for related information like pages
- Create a prompt to pass to instruct the LLM to answer the user’s question based on the chunks of content provided.
The db.index.vector.queryNodes() procedure allows you to query the index with an embedding. The procedure takes three arguments; the name of the index, the number of results to return, and the question as an embedding.
def get_similar_chunks(question):
chunks = openai.Embedding.create(
input=question,
model='text-embedding-ada-002'
)
with driver.session() as session:
# Create a Unit of work to run a read statement in a read transaction
def query_index(tx, embedding):
res = tx.run("""
CALL db.index.vector.queryNodes('chatbot-embeddings', $limit, $embedding)
YIELD node, score
MATCH (node)<-[:HAS_SECTION]-(p)
RETURN
p.title AS pageTitle,
p.url AS pageUrl,
node.title AS sectionTitle,
node.url AS sectionUrl,
node.text AS sectionText,
score
ORDER BY score DESC
""", embedding = chunks.data[0]["embedding"], limit=10)
# Get the results as a dict
return [dict(record) for record in res]
res = session.execute_read(query_index, chunks=chunks)
How are these results useful?
Providing hints as part of the context reduces the amount of hallucination that an LLM may do. Depending on your use case, you may want the LLM to fall back on its pre-trained knowledge, but that comes with many challenges.
In this case, I found that relying on the original LLM training data wasn’t a reliable method, so I added an instruction to the prompt to ask for clarification.
Engineering a prompt
Prompt engineering is an art in itself, and it took me a few iterations to get it right. Let’s take a look at the prompt in more detail.
You are a chatbot teaching users how to use Neo4j GraphAcademy.
Attempt to answer the user's question with the context provided.
Do not attempt to ask the question if it is not related to Neo4j.
Respond in a short, but friendly way.
Use your knowledge to fill in any gaps.
If you cannot answer the question, ask for more clarification.
Provide a code sample if possible.
Also include a link to the sectionUrl.
- You are a chatbot teaching users how to use Neo4j GraphAcademy. Attempt to answer the user’s question with the context provided.
Define the role that the LLM has to play. - Do not attempt to ask the question if it is not related to Neo4j.
Some users may ask questions like “What color is the sky?” or “What is the meaning of life?” If the question is unrelated to Neo4j, don’t attempt to answer it. - Respond in a short, but friendly way.
This is a pet peeve of mine, but if I don’t tell the LLM to be succinct it goes into salesman mode and overuses superlatives like “market-leading”, and “powerful”. - Use your knowledge to fill in any gaps.
If the answer isn’t provided in the context, refer to pre-trained knowledge. - If you cannot answer the question, ask for more clarification.
If the answer isn’t provided in the context, don’t hallucinate. Just ask for more clarification. - Provide a code sample if possible.
The audience is developers and data scientists. Where possible, provide a code example to back up the information provided. - Also include a link to the sectionUrl.
Each section provided in the context also has a URL associated with it — provide a link to it so the user can read more information if required.
If we take the page on the Cypher Match Clause page mentioned above, the provided context may look something like this:
---
Page URL: https://neo4j.com/docs/cypher-manual/current/clauses/match/
Page Title: MATCH - Cypher Manual
Section URL: https://neo4j.com/docs/cypher-manual/current/clauses/match/#match-introduction
Section Title: Introduction
The MATCH clause allows you to specify the patterns Neo4j will search for in the database....
---
---
Page URL: https://neo4j.com/docs/cypher-manual/current/clauses/match/
Page Title: MATCH - Cypher Manual
Section URL: https://neo4j.com/docs/cypher-manual/current/clauses/match/#example-graph
Section Title: Example graph
The following graph is used for the examples below...
---
I have found in the vast majority of cases, providing the top 3 results to the LLM is good enough to answer 99% of cases.
For the remaining 1% of questions, I am currently experimenting with taking the top 10 most similar pages from the vector index and using the Rerank API endpoint from Cohere to determine the relevance.
Testing the LLM
To test, I tied everything together in anask_question function:
def ask_question(question):
with driver.session() as session:
# Use the get_similar_chunks method to
results = session.execute_read(get_similar_chunks, question=question)
# Define the LLM's role with system messages
messages = [
{
"role": "system",
"content": """
You are a chatbot teaching users to how use Neo4j GraphAcademy.
Attempt to answer the users question with the context provided.
Respond in a short, but friendly way.
Use your knowledge to fill in any gaps.
If you cannot answer the question, ask for more clarification.
Provide a code sample if possible.
Also include a link to the sectionUrl.
"""
},
{
"role": "assistant",
"content": """
Your Context:
{}
""".format(json.dumps(reranked))
},
]
# Append a message detailing what the user has asked.
messages.append(
{
"role": "user",
"content": """
Answer the users question, wrapped in three backticks:
```
{}
```
""".format(question)
}
)
# Send the message to OpenAI
chat_completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
return chat_completion.choices[0].message.content
Can it answer an intermediate question about the gds.similarity.cosine() function in the GDS library?
ask_question(
"What are the arguments for gds.similarity.cosine?"
)
The LLM answers in markdown:
The `gds.similarity.cosine` function in Neo4j Graph Data Science calculates similarity between two arrays of numbers using the cosine similarity metric. It takes two arguments: `ps` and `pt`, which represent the two arrays of numbers you want to compare. The function returns a numerical similarity score within the range of [-1, 1]. For more details, you can refer to the documentation [here](https://neo4j.com/docs/graph-data-science/current/algorithms/similarity-functions/#_definitions).
Success! The function has converted the question to an embedding, found the most relevant pages in the documentation, and provided a succinct and helpful answer based on the content in the function table in the Definitions section of the Similarity Functions page in the GDS manual.
How about an abstract question about the MATCH clause?
ask_question("I don't understand the MATCH clause")
The MATCH clause in Cypher allows you to specify patterns to search for in the database. It is similar to the FROM clause in SQL. You can use it to retrieve data from the graph. Here’s an example of how to use the MATCH clause to find all Person nodes in the graph:
MATCH (p:Person)
RETURN p
This query retrieves all nodes with the Person label from the graph and returns them. You can learn more about the MATCH clause in the [Neo4j documentation](https://neo4j.com/docs/cypher-manual/5/clauses/match/).
What about a question unrelated to Neo4j?
ask_question("What is the meaning of life?")
I’m sorry, but I am unable to determine the meaning of life. Is there anything else I can assist you with?
😎👌
Improving similarity searches with graphs
Of course, this relies heavily on the index itself to provide similarity. The structure of the graph can also be used to improve recommendations. You may have noticed that in the extract_docs() function above, each section has an array of links associated with it. These are stored in a graph as a relationship to the corresponding page and section.
The fact that two pages link to each other may infer that they share common content, or that one page can answer a question raised by another.
By taking the user’s current page into account, you may also want to exclude the page that they are on or examine the user’s journey to either highlight a section of a page that they have already visited or discount the page entirely.
In summary
Graphs can help prevent hallucinations in LLMs by providing structured, verifiable knowledge graphs that act as an external memory or reference source for the LLM. Providing this information up-front as part of a prompt can rein in the LLMs’ tendency to provide inventive answers.
Providing your data is already stored in Neo4j, the new Vector Index provides a convenient way to find similar documents using vector embeddings without using any external services.
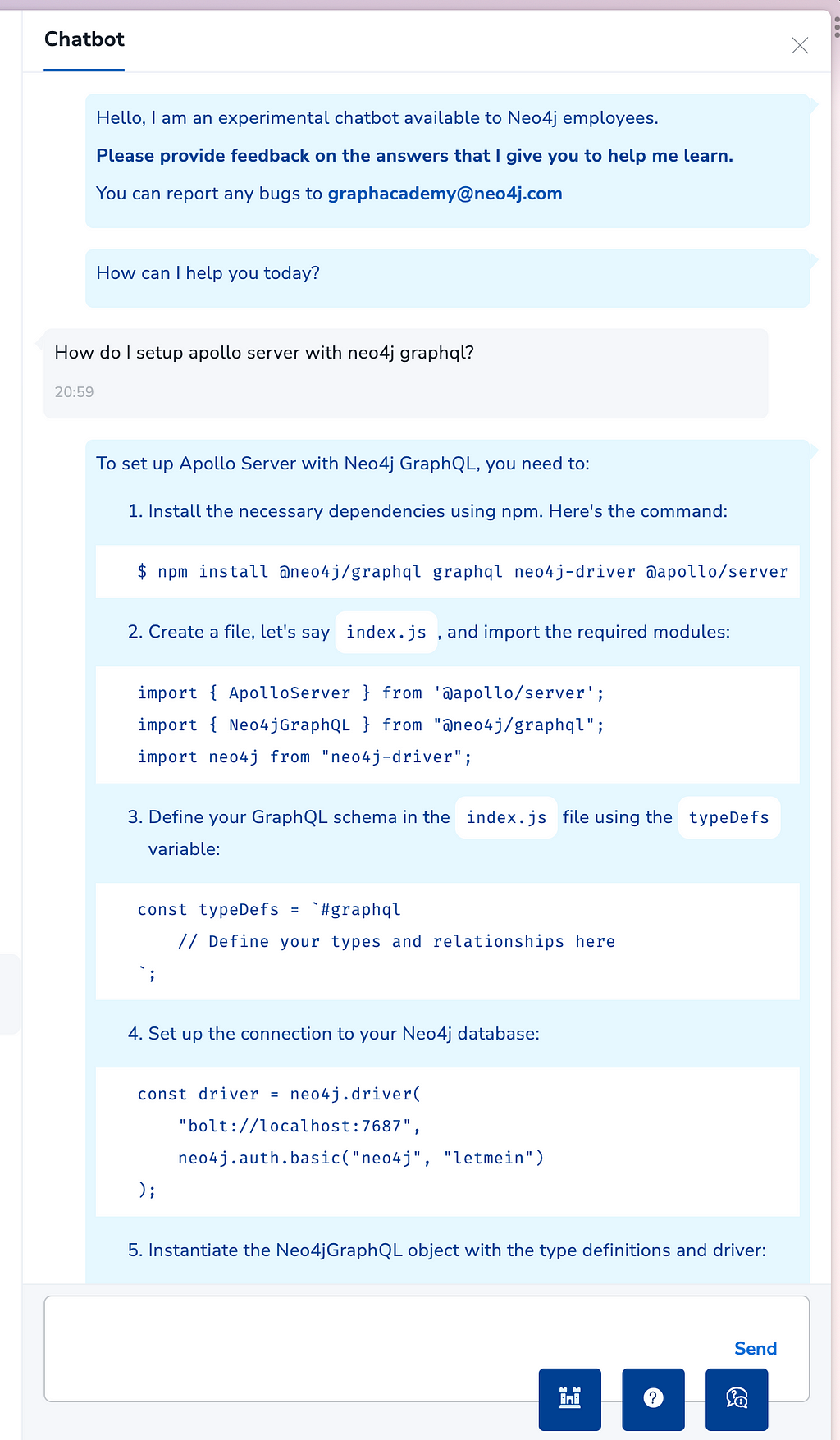
You can check out the chatbot by visiting GraphAcademy and enrolling in a course. The chatbot is available to use in every lesson.
Free, Self-Paced, Hands-on Online Training
You can see it in action below.
Building an Educational Chatbot for GraphAcademy with Neo4j was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


