Neo4j Python driver 10x faster with Rust

Senior Software Engineer, Neo4j
7 min read

TL;DR
Neo4j is going GA with Rust extensions for the Neo4j Python driver.
🎉🎉🎉
It offers major performance improvements and is up to 10 times faster. It’s available on GitHub and PyPI. To install, adjust your dependencies (requirements.txt, pyproject.toml, or similar) like so:
# remove:
# neo4j == X.Y.Z # needs to be at least 5.14.1 for a matching Rust extensions to exist
# add:
neo4j-rust-ext == X.Y.Z.*
# no need to change your code - assuming you're only using public driver APIsTo learn more, read on and check out the README of the GitHub repository linked above.
Where things stand right now
It’s no secret that the CPython interpreter isn’t the fastest out there. It’s much easier to get better performance with other languages like Java, C, C++, Go, etc.
That’s why beloved Python frameworks for number-crunching — like NumPy, TensorFlow, and more — are written in low-level languages (C, C++, and Fortran in this case) to provide a faster experience. Others, like pandas, use tools like Cython to achieve the same.
But recently, a new contestant arrived on the scene. With its great C interop story, Rust has the potential to be used for writing native Python extensions as well. Better yet, the community did a fantastic job building tooling around this opportunity to make this process a breeze.
First, there is PyO3, which is a Rust wrapper around CPython’s (and PyPy’s) C APIs so you don’t have to take care of the foreign function interface (FFI) calls yourself, making the interaction with the interpreter feel much more idiomatic in Rust with all the benefits its strong type system brings. Second, there’s Maturin, which makes compiling, packaging, and shipping a piece of Python software backed by Rust about as easy as it gets.
To improve our Python driver’s performance, which was suboptimal in some cases, we conducted some profiling and quickly identified a hot path in the driver: The encoding and decoding between Python types to the binary protocol called PackStream takes up much of the time spent in the driver code.
So we set out to rewrite precisely this part in Rust. As a matter of fact, I’d played around with Rust before and wrote a Neo4j driver with it:
GitHub – robsdedude/neo4j-rust-driver: Hobby project: bolt driver for Neo4j written in Rust
Note: This is NOT an officially supported Neo4j driver — just a hobby project of mine.
A Rust implementation of PackStream was already available; it just needed adjustment to work the same way the implementation in the Python driver does (accepting and producing different types, including errors).
The result:
GitHub – neo4j/neo4j-python-driver-rust-ext: Optional Rust Extensions to Speed Up the Python Driver
Benchmarking
Right, but how much faster is it really?
Benchmarking this in an absolutely generic way is impossible. There’s a plethora of factors affecting, for better or for worse, how much performance the extensions gain.
Among them:
- Time spent upstream of the driver (network latency, DBMS compute time, etc.)
- Write vs. read heavy work (i.e., more encoding or more decoding)
- What exact types are being sent over the wire
- How much time is spent in the driver doing other things than PackStream en-/decoding, which varies depending on the workload (think routing, connection pool management, result cursor management, and much more)
To still get a feeling for the performance difference, we’ve conceived the best and worst-case scenarios while trying to minimize the parts of the equation that will not be affected (in either direction) by the extensions: time spent for networking and computing query results on the DBMS side by running trivial queries and running against a locally hosted DBMS.
We’ve crafted the following workloads:
- Sending much data, receiving little data. We checked both flat and large, as well as deeply nested and large amounts of data.
- Sending little data, receiving much data. Here, we checked much data in a single record (flat), as well as many small records (nested).
The code for the benchmarks can be found here: github.com/neo4j-drivers/neo4j-python-driver-rust-ext-bench
In this blog post, we’ll focus on presenting and analyzing the results. All benchmarks were run using version 5.24.0 of the Neo4j Python driver, 5.24.0.0 of the Rust extensions, version 5.23 of Neo4j (community edition) running inside a Docker container.
It’s all on my local machine — a Lenovo P1 Gen 3, Intel i9–10885H, 64GB DDR4 RAM@3200 MHz, and CPython 3.12.0 for Linux.
Serialization
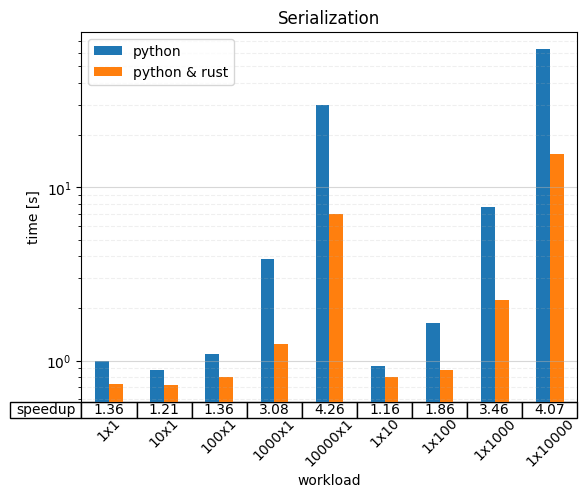
On the x-axis, you can see the workload has been parametrized along two dimensions. NxM stands for a query submitted with a single parameter that’s an N long list of lists with M elements in each.
We observe a speedup anywhere between 1.16 (16 percent faster) and 4.26 (326 percent faster). The more data there is to be transmitted, the bigger the speedup. This aligns with our expectations as there’s less time spent with the other tasks the driver has to take care of, which have not been re-written in Rust, as well as relatively little time spent on the network and inside the DBMS.
Moreover, we see that shallow lists (large N, small M) are generally a little faster than nested lists. This is likely because it’s less recursion and, thus, fewer function calls to handle. The relative speedup seems to be rather unaffected, however.
Deserialization
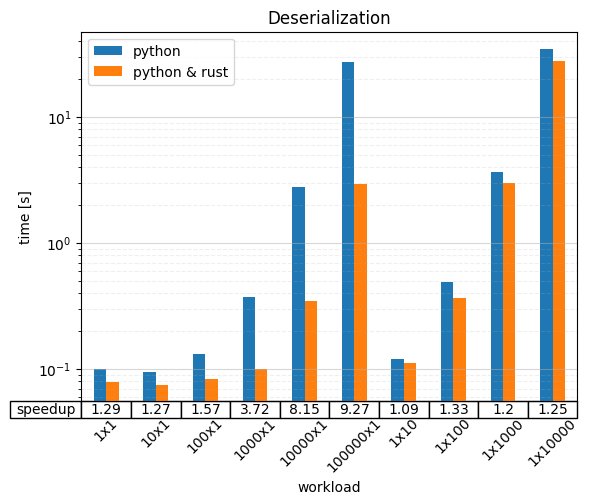
On the x-axis, you can see the workload has been parametrized along two dimensions again. However, here NxM stands for a query submitted that returns M records with a single column containing a list with N elements each.
We’re seeing a speedup of anywhere between 1.09 (9 percent) and 9.27 (827 percent — almost a magnitude). It’s plain to see that wide but few records (big N, small M) fare much better (speedup 1.29–9.27) than many narrow records (speedup 1.09–1.25). This is due to the handling of records not being part of the Rust extensions (it’s fairly involved, even though it might seem simple on the surface).
Internals
Where exactly the border between Rust and Python lies is an implementation detail.
It’s not likely to be moved very high up in the driver’s abstraction hierarchy because it means we’ll have to maintain more functionality in two languages, but never say never.
For users, this means that when relying on driver internals, they might (just as they would with pure Python) be broken in minor or patch releases. Further, the stack trace could change as the stack is not tracked by the Python interpreter while executing native code.
Final remarks
We’re happy to support the Neo4j Python driver Rust extensions for our users and customers. We hope it speeds up your workloads a good bit. Please let us know what kind of workloads are affected in which ways. You can share on Discord or in the comments.
If you run into any problems or questions, please open a GitHub issue or a support ticket for commercial customers.
Happy coding!
Neo4j Python Driver 10x Faster With Rust was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles



SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


