
Building a Recommendation Engine Using Neo4j Hands-On — Part 2

Neo4j Certified Professional
12 min read

From Data Model to Loading Data to Making Recommendations
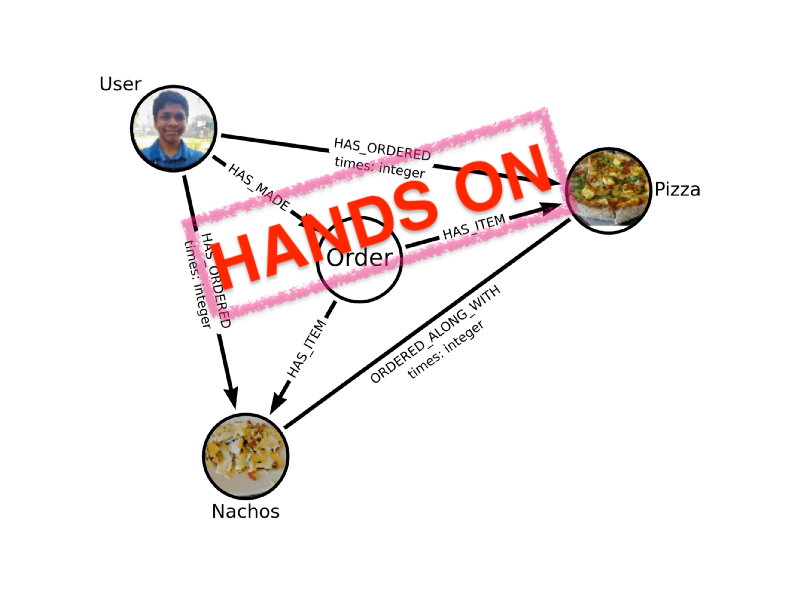
You can find part 1 of this series here, in which we decided on the strategy for making recommendations and designed our data model incrementally. In this article, we will be writing Cypher queries for loading the data, tracking new orders, and implementing the recommender system practically. We will also discuss, in brief, different deployment options as well as ways to serve our recommendations.
Cypher Query Language
Cypher is Neo4j’s graph query language that lets you retrieve data from the graph. It is like SQL for graphs, and was inspired by SQL so it lets you focus on what data you want out of the graph (not how to go get it). Source: https://neo4j.com/developer/cypher
Following Along
The raw data is stored in a GitHub gist. You can follow along with this article by either executing the Cypher queries on a local setup Neo4j database, or you can take benefit of the sandbox environment available at https://neo4j.com/sandbox/.
URLs to be used in import statements:
1. Load Items: https://gist.githubusercontent.com/susmitpy/83d7157f4006c461e88717eed17df9d4/raw/92a7c87089292c48b119e00c3f63ba656f38d128/items.csv
2. Load Order — Item Mapping: https://gist.githubusercontent.com/susmitpy/83d7157f4006c461e88717eed17df9d4/raw/92a7c87089292c48b119e00c3f63ba656f38d128/orders_items.csv
3. Load User — Order Mapping: https://gist.githubusercontent.com/susmitpy/83d7157f4006c461e88717eed17df9d4/raw/92a7c87089292c48b119e00c3f63ba656f38d128/users_orders.csv
Getting Familiar With Raw Data
The data we will be dealing with is in tabular format in CSV files spread across 3 files. First of all, we have all the food items’ IDs along with their names so that it is easier for us to make sense of the data and follow along.
Then we have order data, in which we have information as to which all items were included in a single order. Finally, we have the mapping of a user to order, which is which user made which order.
Loading Data
Let’s start by loading the data into our Neo4j database. We can directly ingest the data by parsing the CSV files via Cypher queries.
Items

Let’s dissect the above query to insert the items in the database. We are loading the CSV and specifying that the first row is a header row. We are referring to each individual data row as a row. Then for each row, by using the MERGE clause, we are creating the item. It is recommended that the node’s internal IDs should not be stored and used elsewhere. Hence, we are creating the node item and assigning the db_id property to the id of the item used in the data store which holds the information related to items. We are also specifying the name, for the sake of the readability of the results. In actuality, the recommendation will solely work based on the IDs.
Order — Items
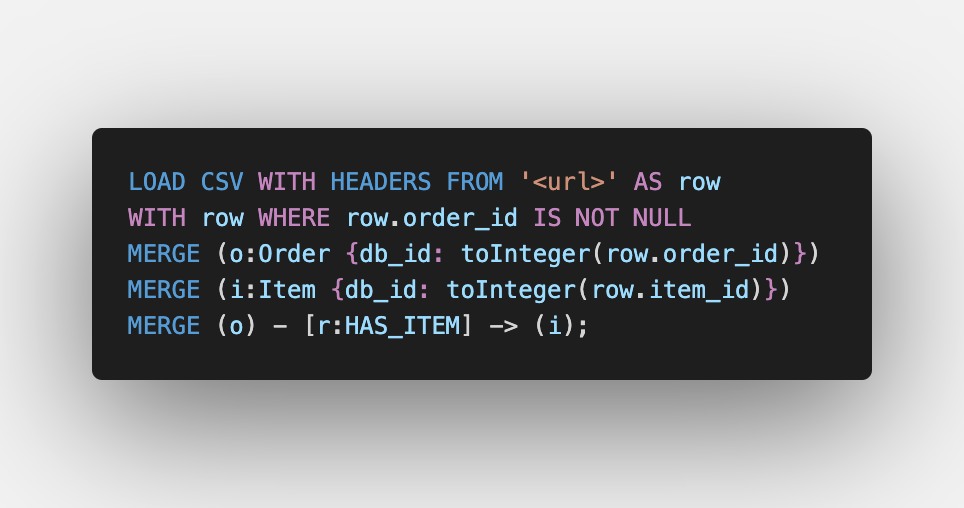
Next up, we have to create unique orders, as well as link them with the items that were part of the order. It is important to stress the word “unique” since the data is a kind of one-to-many relationship when it is represented in tabular format the order IDs repeat. By using the MERGE clause, we are either creating the order if it does not exist or selecting the node as variable o. Then we are selecting the item node based on the value of the db_id property. Finally, we are creating a HAS_ITEM relationship between the order and the item. Since an Order has an Item, and not the other way around, we specify the direction accordingly.
User — Order
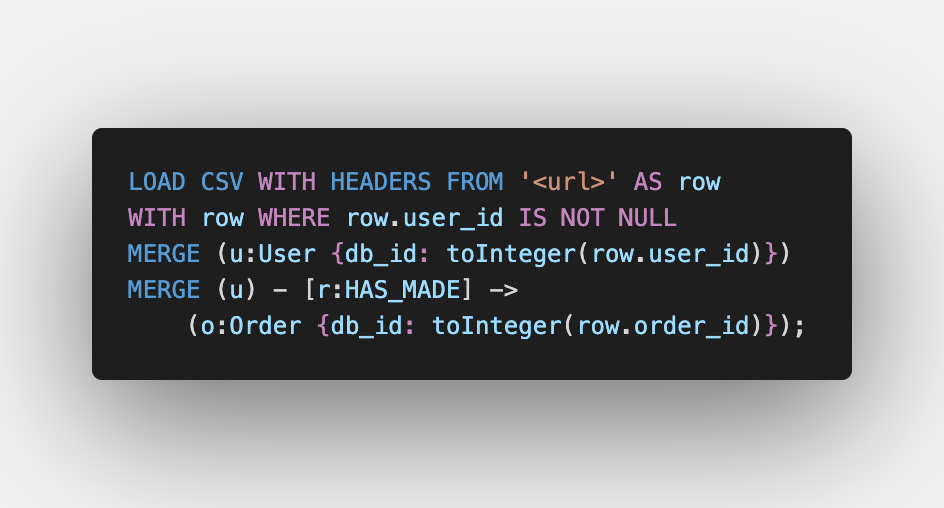
Next up, we link the user with the orders which have been made by the user. We select the user and then create a relationship with the order. Notice how we are selecting the order within the query which creates a relationship, unlike the query for mapping order to items wherein we selected the item separately. This shows how the same query can be written in different ways.
I recommend the approach taken in the query of mapping order to items, that is selecting / creating nodes in separate statements and not doing it inline when creating relationship. It is more clearer, readable and understandable.
Adding Relationships for Recommendation
We have already added simple relationships such as HAS_MADE and HAS_ITEM to model our data. In order to power our recommendation system, we will be adding relationships such as HAS_ORDERED and ORDERED_ALONG_WITH. Also, in order to rank the items to be recommended, we will be setting properties to the relationships. Since we have loaded the data, we need to compute the values and set them. Afterwards, whenever we perform any operations, we will mutate the properties.
Adding HAS_ORDERED relationship
As per our data model, we are creating an Order node for each unique order made by a user and keeping track of the items in that order by linking the Order node with the Item node via the HAS_ITEM relationship. Now, this implicitly means that the User has ordered the Item. Instead of traversing the graph every time a recommendation is to be made, in order to derive this implicit relationship, we will be making this implicit relationship explicit by adding a HAS_ORDERED relationship between the User and the Item. We also will be keeping track of the count of a particular Item that has been ordered by a particular User by adding a times property to the relationship.

In the first statement, we are querying for all sub-graphs / paths which are defined by the pattern: User makes an Order. Then we are matching to the Items that were ordered in an Order. In order to create the HAS_ORDERED relationship, we use the MERGE clause. Now since a User will be making multiple Orders and the same Item can be part of different Orders, the relationship of HAS_ORDERED from User to Item will be encountered multiple times. In order to keep track of the count, we set the value of the times property to 1 when the relationship is created using the ON CREATE clause. Henceforth, whenever it is matched during the execution of MERGE the clause, we increment the value of the times property by specifying the same in the ON MATCH clause.
Adding ORDERED_ALONG_WITH Relationship
All the Items ordered together in a single Order have one thing in common, the Order itself. Now there is a possibility that some of the Items that have been ordered along with each other may be complementary dishes that make up good combinations. Now, traversing the whole graph and computing which other Items are frequently ordered with one particular Item in real-time, every time a recommendation is to be made is very costly. Hence we will precompute and store this information via the ORDERED_ALONG_WITH relationship. We will also keep track of the number of times two Items are ordered along with each other via the times property.
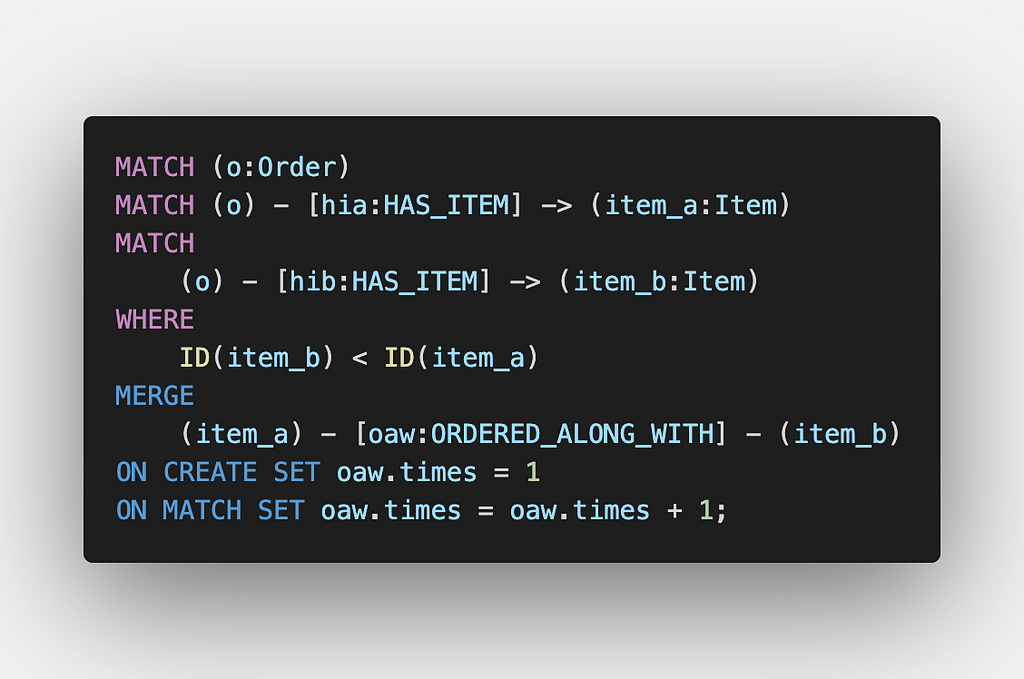
Now, this was a little bit tricky for me to figure out, so pay attention. First, we match all the Orders. Then we match two Items within that order and reference them as item_a and item_b, respectively. Similar to the way we computed HAS_ORDERED above, we use the MERGE clause to create the relationship along with ON CREATE and ON MATCH clauses to keep track of the count of co-occurrence based on a simple condition (the tricky part). We do this only if the ID of the second Item is less than the ID of the first Item. Why? Well, we do this because, for two Items that are part of the same order, one time, the first Item will be referenced as item_a, and the second Item will be referenced as item_b. Both of them will be matched again. Just this time, it will be inverse. That is, the first Item will be referenced as item_b, and the second Item will be referenced as item_a. This will give rise to the issue of recounting / double counting. Also, the same Item will be matched as both item_a and item_b, and a relationship to itself will be created if no condition is specified. By performing the operation(s) for two Items A and B if and only if ID(B) < ID(A) we ensure that not only a relationship to self is not created (which could have also been done using ID(B) != ID(A)), we also avoid the issue of double counting.
Tracking New Orders
Above, we loaded existing data. However, as users make new orders, we need to keep on updating our Neo4j database so that our recommender system stays up to date and keeps on improving. Along with adding the nodes and the simple relationships, we will also need to update the pre-aggregated counts in the HAS_ORDERED and ORDERED_ALONG_WITH relationships.
So let’s write a Cypher query to track a new order made by an existing user.
Scenario: User id 1 creates an order having id 12 in which items with ids 8 and 10 are ordered.
We have to create a new Order, increment the times property of the HAS_ORDERED relationship between the User and each Item, as well as increment the times property of the ORDERED_ALONG_WITH relationship between the two Items. Also, the query should account for the case wherein the User has never ordered the Item or the Items have never been ordered together by setting the property to 1 while creating the relationship.
Let’s take a look at existing data involving all the players.
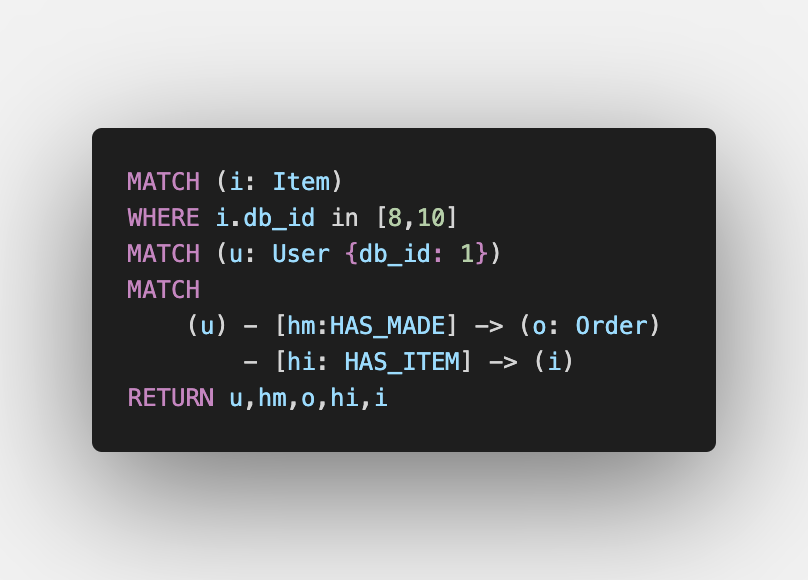
If we check existing data, we will find out that there already exists an Order made by the same User in which the same two Items were ordered. Also, the User had also ordered the Item Medu Vada (db_id 8) in another Order as well.
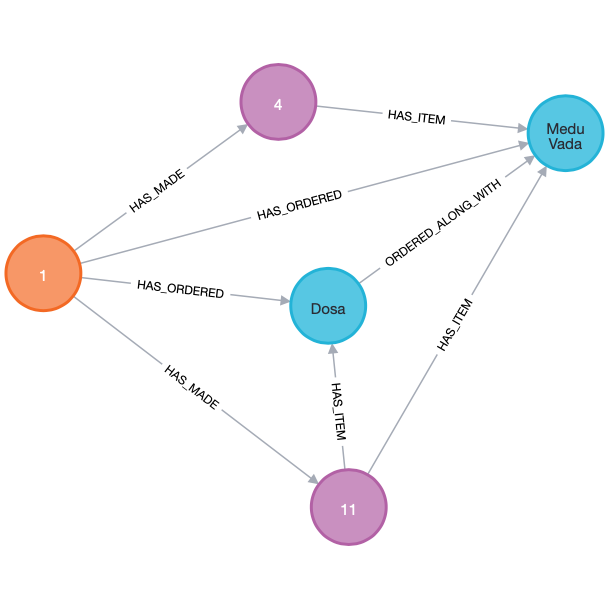
If we inspect the properties, we can see that as expected the User has ordered the Item Medu Vada 2 times and Dosa 1 time. Also, these two Items have been ordered along with each other 1 time.

Creating an Order Node
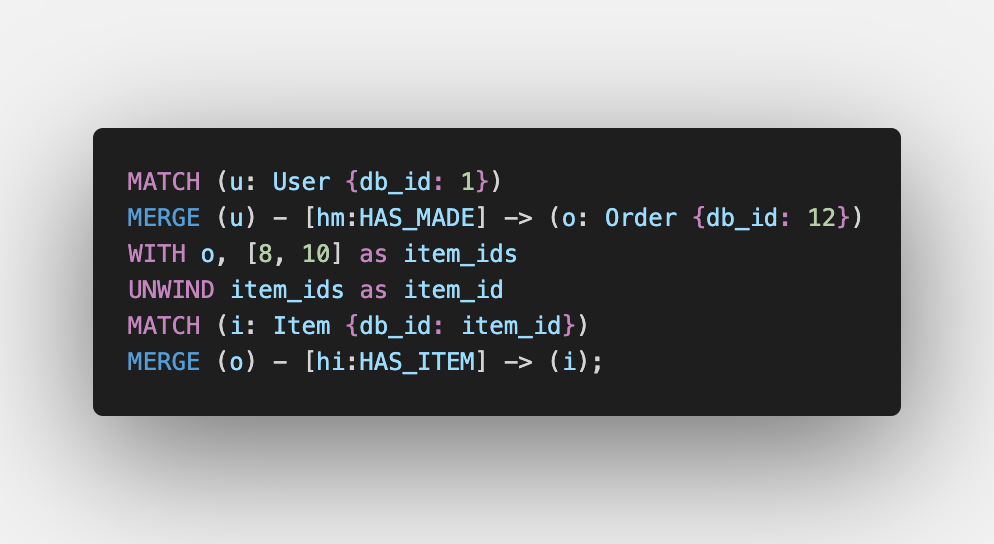
We first match the User node and then create a new Order along with the HAS_MADE relationship. Then we UNWIND that is iterate over item_ids, and for each item_id, we first match the Item and then link it with the Order.
Creating/Updating HAS_ORDERED Relationship
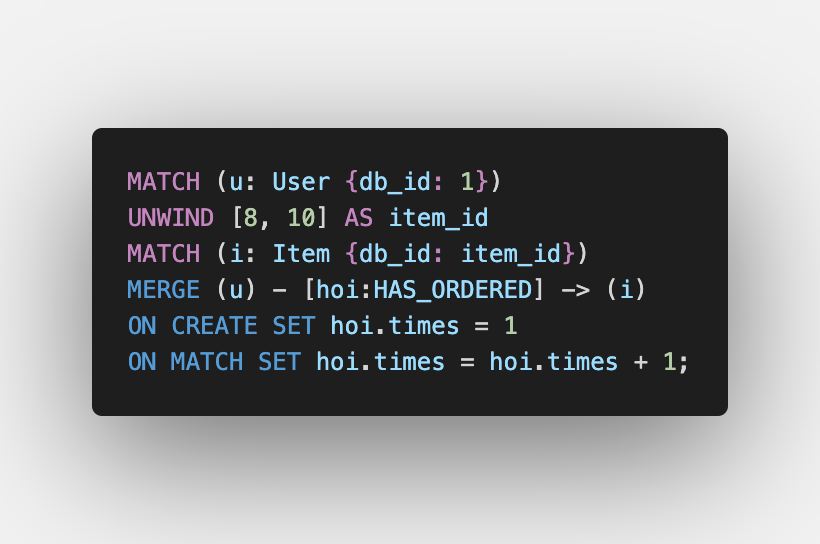
We first match the User, and then for each item_id, we use the MERGE clause to match/create the relationship HAS_ORDERED. Just like we did while loading data, if the relationship did not exist before, the ON CREATE part of the clause sets the value of the times property to 1, and if the relationship did exist before, then the ON MATCH clause increments the property by 1.
Creating/Updating ORDERED_ALONG_WITH Relationship
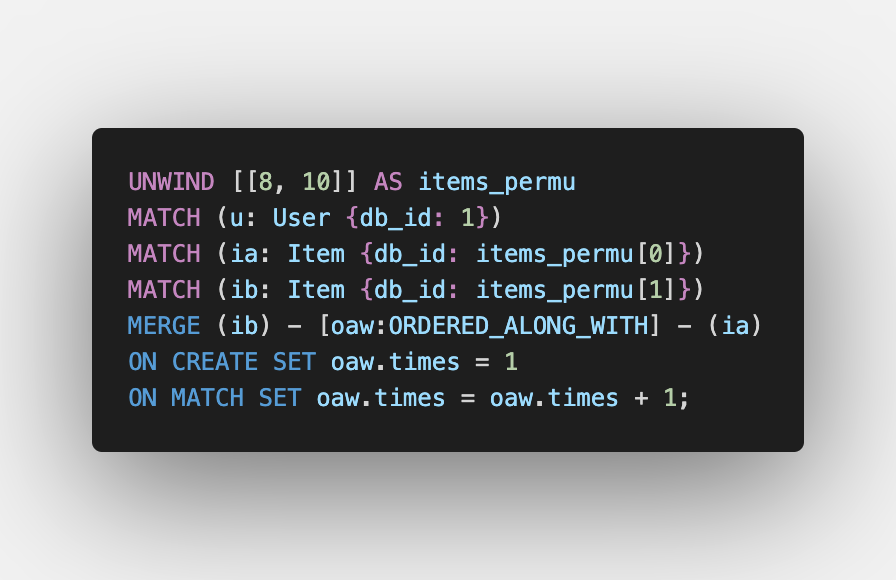
We will find out all the permutations among all the item IDs in the programming language via which we will be executing this Cypher query. Then in the Cypher query, we will iterate over the permutations, and for each permutation, we match/create the necessary relationship and set the times property just like we tackled HAS_ORDERED relationship.
Let’s inspect the properties after running the above queries.

As expected, now the data reflects that Medu Vada was ordered 3 times, and Dosa was ordered 2 times by the User. Also, it reflects the fact that both of them have now been ordered 2 times along with each other.
Enough data insertion, time to recommend some food. Let’s Go!
Implementing Recommendation System
As we had decided in part 1 of this blog series, we will be answering 3 questions and using the answers as the recommendation.
Tackling Question 1
What does a user generally order most frequently ?
In order to find the most frequently ordered Items by a User, all we have to do is to match the pattern wherein a User HAS_ORDERED an Item. Then we can find the top 2 most frequently ordered items by sorting all the Items ordered by a User by the times property of the HAS_ORDERED relationship.
The value of the db_id property will then be used to fetch the data of the item from some other data store in order to show the recommendation to the user.
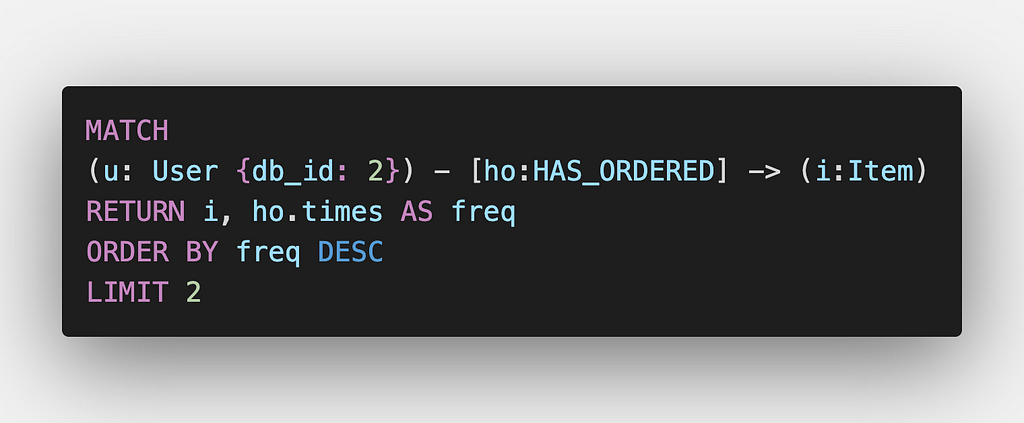
In the above example, we are querying for the top 2 ordered items for the User identified by db_id 2.
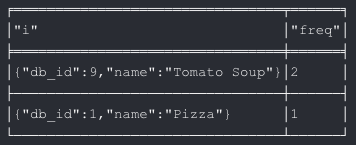
As shown in the above output image, “Tomato Soup” is the most frequently ordered item.
Tackling Question 2
Once a particular item (denoted as X) has been added into the cart, which other items have been previously ordered by the user with item X ?
In order to find the Items which a User has previously ordered along with the Item which the User has added to the cart (Item X), we can hop through the graph to find other Items that were part of the Orders in which Item X was also part. We can count the number of times each item appeared along with Item X to perform ranking for recommendation purposes.
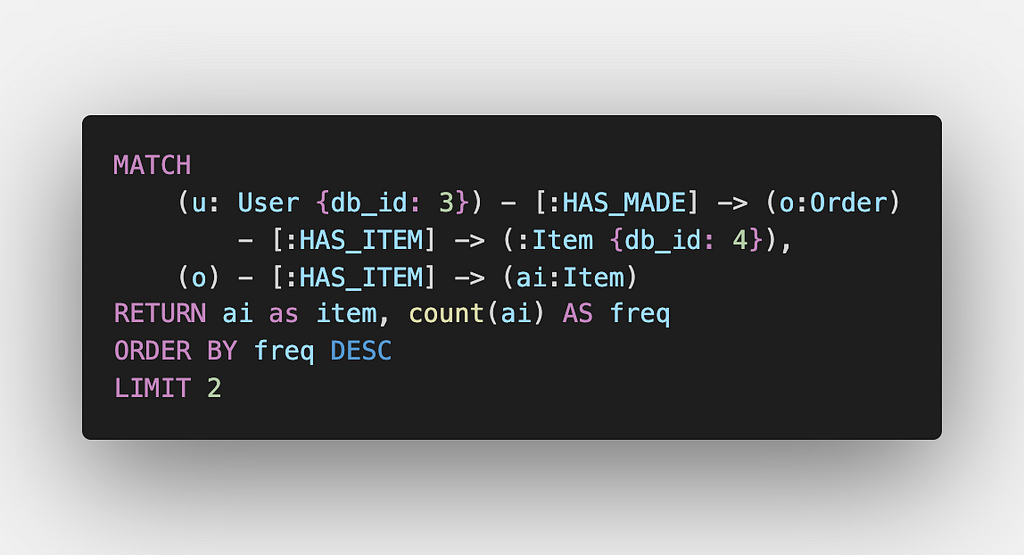
In the above example, once the User identified by db_id 3 adds the Item identified by db_id 4 into the cart, we find the top 2 most frequent items ordered by the User among all the Orders.
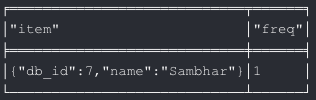
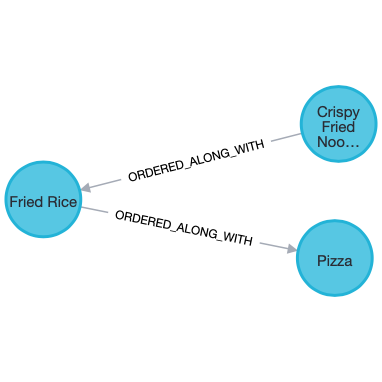
The below image will help you to understand what’s going on in a better way.
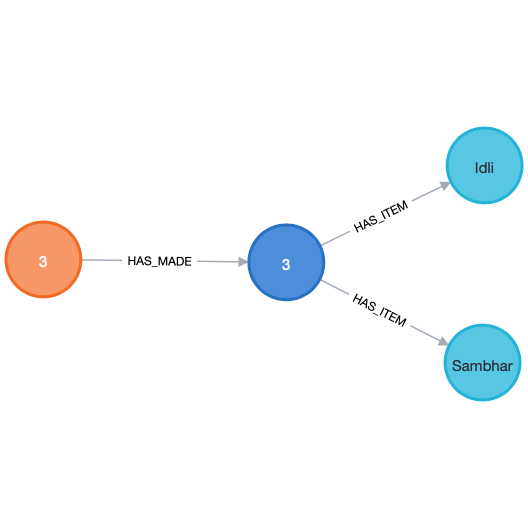
Here, the item associated with db_id 4 is “Idli.” As visible in the above image, the Item “Sambhar” was also ordered along with Item “Idli” in the same Order. Below is the order history of the User associated with db_id 3. As you can see, there was only a single order in which the Item “Idli” was ordered.
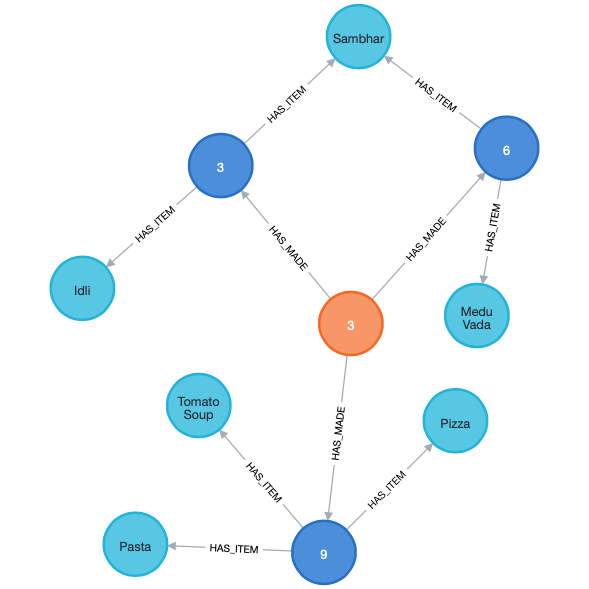
Tackling Question 3
Once a particular item (denoted as X) has been added into the cart, which items are frequently ordered along with X amongst all the users ?
This is similar to the second question, but here instead of keeping the search space restricted to the Orders of the User, we consider the data of all the Users. To answer this question, all we have to do is to make use of the ORDERED_ALONG_WITH relationship to find the Items ordered along with Item X and use the times property to find the top 2 most frequently ordered Items along with the item added to the cart.
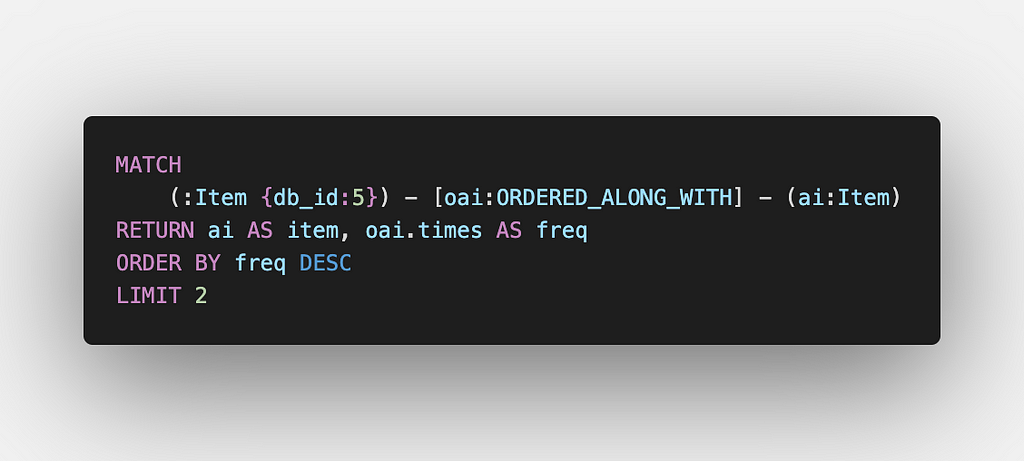
In the above example, once the Item identified by db_id 5 is added to the cart, we find the top 2 most frequent items ordered along with the Item. We use the ORDERED_ALONG_WITH relationship for this purpose.
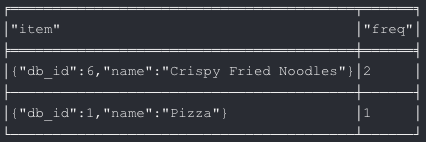
The Item “Crispy Fried Noodles” is the top most Item which has been ordered along with Item “Fried Rice” till now.
Deployment and Serving Recommendations
Let’s discuss deploying the Neo4j database first. Either we can go for a self-managed solution wherein we deploy the Neo4j database in machines hosted in the cloud, e.g., in AWS EC2 (Elastic Compute Cloud) within AWS ECS (Elastic Container Service). But if we need to deploy a Neo4j cluster, we might consider services like AWS EKS (Elastic Kubernetes Service). The second option is to opt for a database as a managed service, such as Neo4j Aura DB.
Once the database is up and running, we will need to create API endpoints to serve recommendations. For this, either you can include them in your current application server or go for a serverless approach by deploying the standalone functions using services like AWS Lambda. Either way, you would accept the user id and the current cart in the request, make a Cypher query to the Neo4j database to get the item IDs to be recommended, and then query your primary database, which holds the details of the items such as name, price, image, etc. before returning the response to the client.
Conclusion
That’s it for now, folks. If you enjoyed reading and at the same time learned something, do give clap(s), it helps Medium’s recommendation system to recommend such blogs to other users as well who might benefit from it.
Building a Recommendation Engine Using Neo4j Hands-On — Part 2 was originally published in Neo4j Developer Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



